

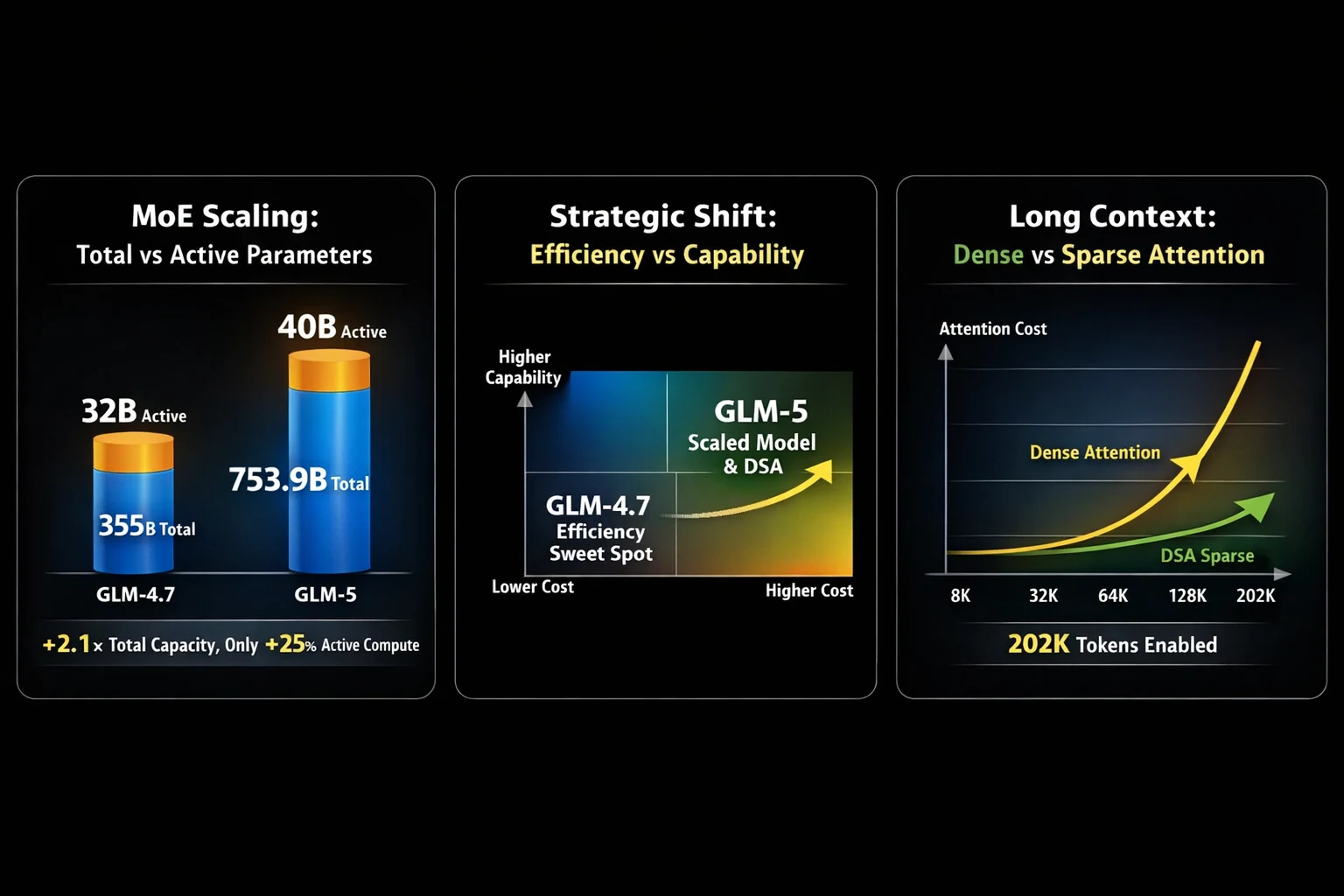
غالباً ما يتلخص الاختيار بين GLM-5 وGLM-4.7 في مفاضلة حرجة: القوة الوكيلية الهائلة مقابل البراعة المثبتة في البرمجة متعددة الاستخدامات. يرتقي GLM-5، الذي أصدرته Z.ai، بشكل كبير عن سابقه، قافزاً من 355 مليار معامل (32 مليار نشط) في GLM-4.7 إلى 753.9 مليار معامل (40 مليار نشط). هذا التوسع بمقدار 2.1 ضعف في المعاملات يحقق تحسينات جوهرية في هندسة الأنظمة المعقدة والمهام الوكيلية طويلة المدى، لكن GLM-4.7 لا يزال قوة هائلة في البرمجة متعددة اللغات، وأتمتة الطرفية، وسير عمل المطورين الواقعي.
مقارنة البنية المعمارية بين GLM-5 وGLM-4.7
| المواصفة | GLM-5 | GLM-4.7 |
|---|---|---|
| إجمالي المعاملات | 753.9 مليار | 355 مليار |
| المعاملات النشطة | 40 مليار | 32 مليار |
| طول السياق | 202,752 رمز | 202,752 رمز |
| بيانات ما قبل التدريب | 28.5 تريليون رمز | 23 تريليون رمز |
| الدقة | BF16 (FP8 متاح) | BF16 (FP8 متاح) |
| دعم الوسائط المتعددة | نص فقط | نص فقط |
| تاريخ الإصدار | يناير 2026 | ديسمبر 2025 |
من أبرز التحسينات العملية في GLM-5 هو دمج DeepSeek Sparse Attention (DSA)، مما يقلل بشكل كبير من تكلفة الانتباه طويل السياق مع الحفاظ على نوافذ سياق كبيرة تصل إلى 202 ألف رمز. وهذا يجعل GLM-5 أكثر قابلية للنشر في سير العمل الواقعي للاستدلال على المستندات الطويلة، والمساعدات متعددة الأدوار، وسير العمل الوكيلي.على جانب ما بعد التدريب، يستفيد GLM-5 من slime، وهي بنية تحتية جديدة للتعلم المعزز غير المتزامن تعزز إنتاجية تدريب RL وتتيح تكرارات محاذاة أكثر تكراراً ودقة.
مقارنة المعايير بين GLM-5 وGLM-4.7
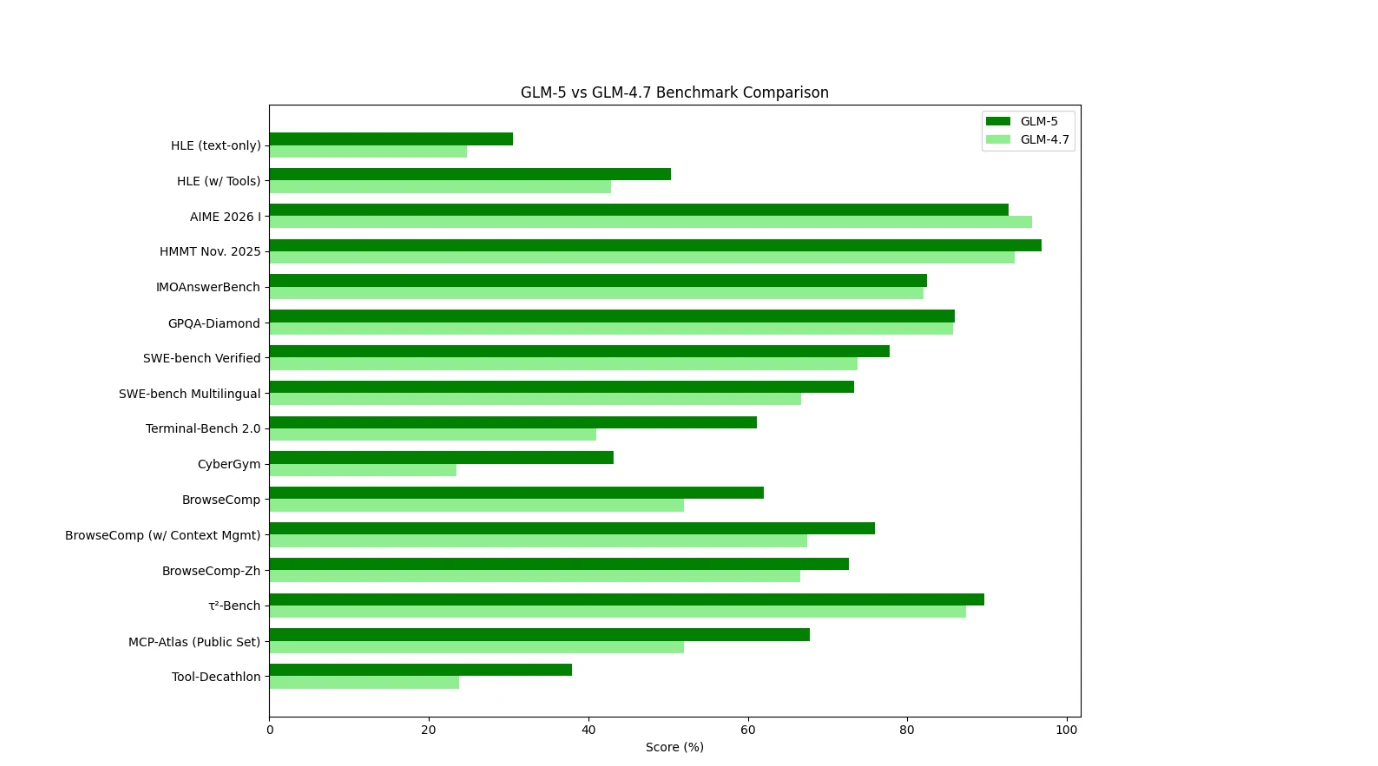
من منظور المعايير، يظهر GLM-5 تحسناً واسعاً ومتسقاً مقارنة بـ GLM-4.7، خاصة في استخدام الأدوات والتصفح والإعدادات الوكيلية. تظهر أكبر المكاسب في البيئات التي تتطلب تخطيطاً متعدد الخطوات، وإدارة السياق، والتنفيذ في العالم الحقيقي، مما يشير إلى أن GLM-5 محسّن لـ سير العمل الوكيلية بدلاً من مهام الاستدلال المعزولة.
GLM-4.7 يعمل كنموذج استدلال/برمجة محسّن للكفاءة، لا يزال قوياً جداً في تقييمات الرياضيات التقليدية، ولكنه أقل هيمنة في المهام التفاعلية القائمة على الأدوات.
متطلبات VRAM لـ GLM-5 وGLM-4.7
الزيادة بمقدار 2.1 ضعف في المعاملات من GLM-4.7 إلى GLM-5 تستلزم تبعيات كبيرة على الأجهزة. فيما يلي تفصيل متطلبات VRAM:
تكوين GPU الموصى به لـ GLM-5
| الدقة | VRAM المطلوبة | الإعداد الموصى به | حالة الاستخدام |
|---|---|---|---|
| BF16 | 1,508 جيجابايت | 19x NVIDIA H100 (80 جيجابايت) | أقصى جودة للبحث |
| FP8 | حوالي 800 جيجابايت | 10x NVIDIA H100 (80 جيجابايت) | نشر الإنتاج |
| INT4 | حوالي 400 جيجابايت | 5x H100 (80 جيجابايت) | استدلال فعال من حيث التكلفة |
تكوين GPU الموصى به لـ GLM-4.7
| الدقة | VRAM المطلوبة | الإعداد الموصى به | حالة الاستخدام |
|---|---|---|---|
| BF16 | 717 جيجابايت | 9x NVIDIA H100 (80 جيجابايت) | أقصى جودة |
| FP8 | 390 جيجابايت | 5x H100 (80 جيجابايت) | نشر الإنتاج |
| INT4 | 200 جيجابايت | 3x H100 (80 جيجابايت) | استدلال فعال من حيث التكلفة |
جرب GPU فعال من حيث التكلفة الآن!
في نشر FP8، عادةً ما يتطلب GLM-5 ضعف عدد وحدات GPU مقارنة بـ GLM-4.7.
للمطورين ذوي الميزانيات المحدودة، يقدم GLM-4.7 ملف أداء أفضل لكل دولار في أعباء العمل المركزة على البرمجة، محققاً 73.8% على SWE-bench Verified و84.9% على LiveCodeBench-v6.
للبحث الحدودي وتطوير الأنظمة الوكيلية، يمكن أن تبرر قدرات GLM-5 الأقوى في استخدام الأدوات والتنفيذ طويل المدى الاستثمار الإضافي في الأجهزة.
التسعير والوصول عبر API لـ GLM-5 وGLM-4.7
| النموذج | الإدخال ($ / مليون رمز) | قراءة ذاكرة التخزين المؤقت ($ / مليون رمز) | الإخراج ($ / مليون رمز) |
|---|---|---|---|
| GLM-4.7 | $0.60 | $0.11 | $2.20 |
| GLM-5 | $1.00 | $0.20 | $3.20 |
قراءة ذاكرة التخزين المؤقت تشير إلى تكلفة قراءة الرموز التي تم تخزينها مسبقاً في ذاكرة التخزين المؤقت للمطالبة. عند إعادة استخدام نفس محتوى المطالبة عبر الطلبات، يسترجع النموذج هذه الرموز مباشرة من ذاكرة التخزين المؤقت بدلاً من معالجتها من جديد. وهذا يقلل من زمن الانتقال والتكلفة في الاستدلال.
الخطوة 1: تسجيل الدخول والوصول إلى مكتبة النماذج
سجل الدخول إلى حسابك وانقر على زر مكتبة النماذج.

الخطوة 2: اختر نموذجك
تصفح الخيارات المتاحة واختر النموذج الذي يناسب احتياجاتك.

الخطوة 3: ابدأ نسختك التجريبية المجانية
ابدأ النسخة التجريبية المجانية لاستكشاف إمكانيات النموذج المحدد.
الخطوة 4: احصل على مفتاح API الخاص بك
لمصادقة الوصول إلى API، سنوفر لك مفتاح API جديد. بالدخول إلى صفحة “الإعدادات”، يمكنك نسخ مفتاح API كما هو موضح في الصورة.

الخطوة 5: تثبيت API
قم بتثبيت API باستخدام مدير الحزم الخاص بلغة البرمجة التي تستخدمها.
بعد التثبيت، قم باستيراد المكتبات اللازمة في بيئة التطوير الخاصة بك. قم بتهيئة API باستخدام مفتاح API الخاص بك لبدء التفاعل مع Novita AI LLM. هذا مثال على استخدام API لاستكمال المحادثة لمستخدمي Python.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="zai-org/glm-5 or zai-org/glm-4.7",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
ملخص إطار القرار لـ GLM-5 وGLM-4.7
| السيناريو | النموذج الموصى به | السبب الرئيسي |
|---|---|---|
| أنظمة متعددة الوكلاء مع تنسيق الأدوات | GLM-5 | +15.8pp على MCP-Atlas، +14.2pp على Tool-Decathlon |
| سير عمل SWE-bench الإنتاجي | GLM-4.7 | 73.8% بنصف تكلفة الأجهزة |
| الأمن السيبراني واختبار الاختراق | GLM-5 | 43.2% CyberGym |
| البرمجة في بيئة التطوير المتكاملة (Claude Code, Cline) | GLM-4.7 | الحفاظ على التفكير + زمن انتقال أقل |
| أبحاث الاستدلال الحدودي (HLE) | GLM-5 | 50.4% مع الأدوات (أفضل نموذج مفتوح المصدر) |
| البرمجة الموجهة بالواجهات / “vibe coding” | GLM-4.7 | تدريب متخصص لواجهات الويب الحديثة |
| أتمتة الطرفية (طويلة المدى) | GLM-5 | +28.3pp على Terminal-Bench 2.0 |
| مسابقات الرياضيات (AIME, HMMT) | GLM-4.7 | يساوي/يتجاوز GLM-5 بتكلفة أقل |
| الشركات الناشئة ذات الميزانية المحدودة | GLM-4.7 | برمجة قوية مع 4x H100 مقابل 8x H100 |
| مختبرات الأبحاث التي تدفع حدود AGI | GLM-5 | تدريب مسبق على 28.5 تريليون رمز، بنية تحتية للتعلم المعزز slime |
GLM-5 لا يلغي GLM-4.7—إنه يعالج مشاكل مختلفة. إذا كان عملك يتضمن مهام وكيلية طويلة المدى تتطلب استخداماً واسعاً للأدوات واستدلالاً متعدد الخطوات، فإن الاستثمار المضاعف في الأجهزة في GLM-5 يؤتي ثماره في معدلات إنجاز المهام. إذا كنت تقوم بتسليم مساعدي برمجة لآلاف المطورين أو تحتاج إلى دورات تكرار سريعة في بيئات IDE، فإن بنية GLM-4.7 الأنحف والتدريب المتخصص يجعله الخيار الأنسب. كلا النموذجين يمثلان إنجازات هامة في النمذجة اللغوية مفتوحة المصدر، مما يقلص الفجوة مع النماذج الخاصة الحدودية مع الحفاظ على الشفافية الكاملة ومرونة النشر المحلي.
الأسئلة الشائعة
ما الفرق المعماري الرئيسي بين GLM-5 وGLM-4.7؟
يرتقي GLM-5 من 355 مليار إلى 753.9 مليار معامل إجمالي (32 مليار إلى 40 مليار نشط) ويدمج DeepSeek Sparse Attention (DSA) لتقليل تكاليف النشر مع الحفاظ على طول سياق 202 ألف رمز.
هل يمكنني تشغيل GLM-5 على أجهزة المستهلك؟
لا. يتطلب GLM-5 ما لا يقل عن 10 وحدات GPU من نوع H100 بسعة 80 جيجابايت في وضع FP8 (800 جيجابايت VRAM)، وهو ما يتجاوز بكثير إمكانيات أجهزة المستهلك.
أي النموذجين أفضل لمهام البرمجة على SWE-bench؟
يتفوق GLM-5 على GLM-4.7 بنسبة 77.8% على SWE-bench Verified (+4 نقاط مئوية)، لكن تحقيق GLM-4.7 لنسبة 73.8% بنصف تكلفة الأجهزة يجعله أكثر عملية للإنتاج.
Novita AI هي منصة حوسبة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام API بسيط، مع توفير حوسبة GPU موثوقة وبأسعار معقولة للبناء والتوسع.
قراءات موصى بها



