

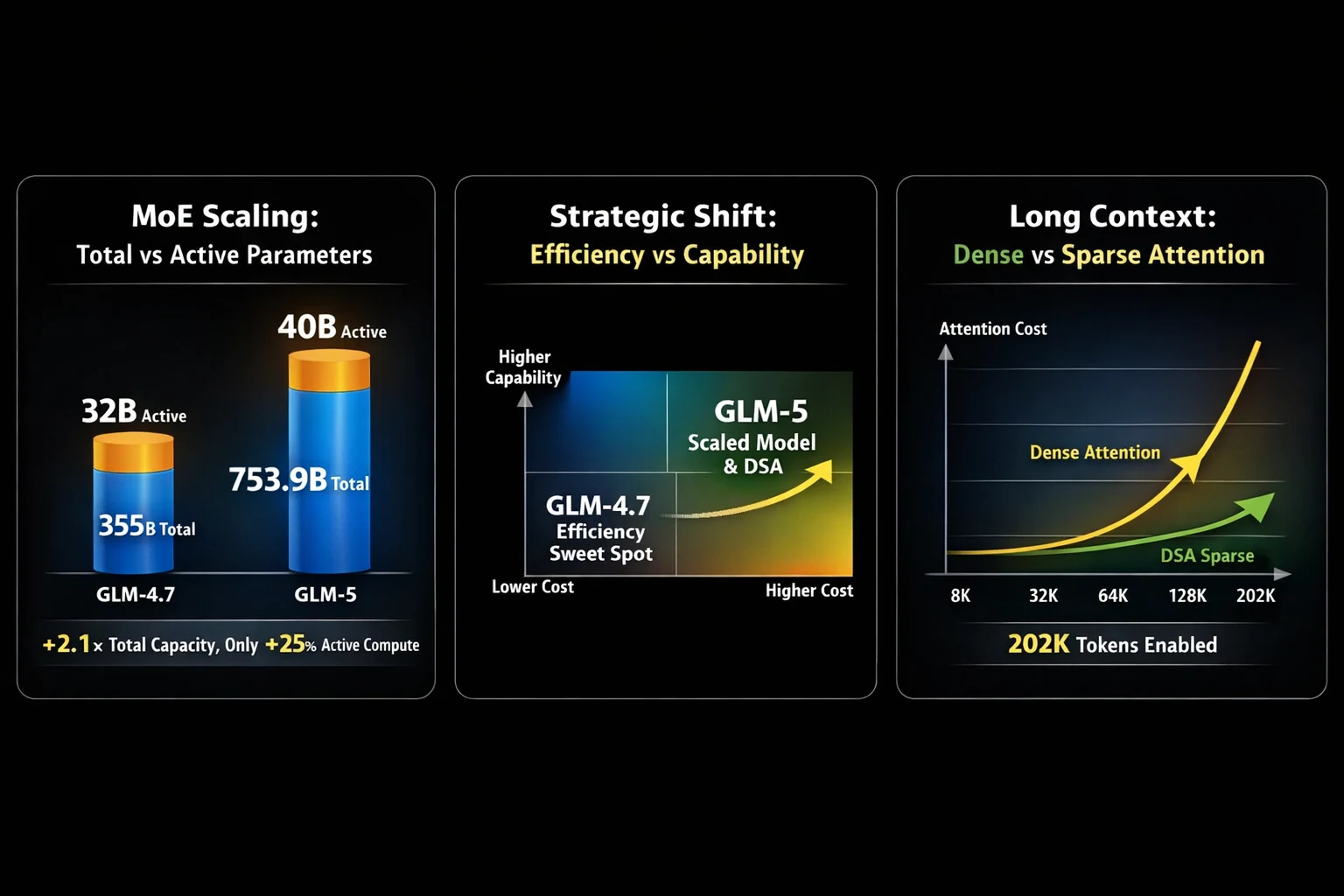
选择 GLM-5 还是 GLM-4.7,往往取决于一个关键权衡:大规模代理能力 vs 久经考验的编码通用性。由 Z.ai 发布的 GLM-5 相比前代大幅扩展——从 GLM-4.7 的 355B 参数(32B 激活)跃升至 753.9B 参数(40B 激活)。这一 2.1 倍的参数扩展带来了复杂系统工程和长周期代理任务的显著改进,但 GLM-4.7 在多语言编码、终端自动化和实际开发者工作流方面依然强劲。
GLM-5 与 GLM-4.7 架构对比
| 规格 | GLM-5 | GLM-4.7 |
|---|---|---|
| 总参数 | 753.9B | 355B |
| 激活参数 | 40B | 32B |
| 上下文长度 | 202,752 tokens | 202,752 tokens |
| 预训练数据 | 28.5T tokens | 23T tokens |
| 精度 | BF16(支持 FP8) | BF16(支持 FP8) |
| 多模态支持 | 仅文本 | 仅文本 |
| 发布日期 | 2026年1月 | 2025年12月 |
GLM-5 最实用的升级之一是其集成了 DeepSeek 稀疏注意力(DSA),这显著降低了长上下文注意力的成本,同时保留了高达 202K tokens 的大上下文窗口。这使得 GLM-5 在实际的长文档推理、多轮助手和代理型工作流中更易部署。在训练后阶段,GLM-5 受益于 slime——一种新的异步强化学习基础设施,提升了 RL 训练吞吐量,并实现了更频繁、更细粒度的对齐迭代。
GLM-5 与 GLM-4.7 基准测试对比
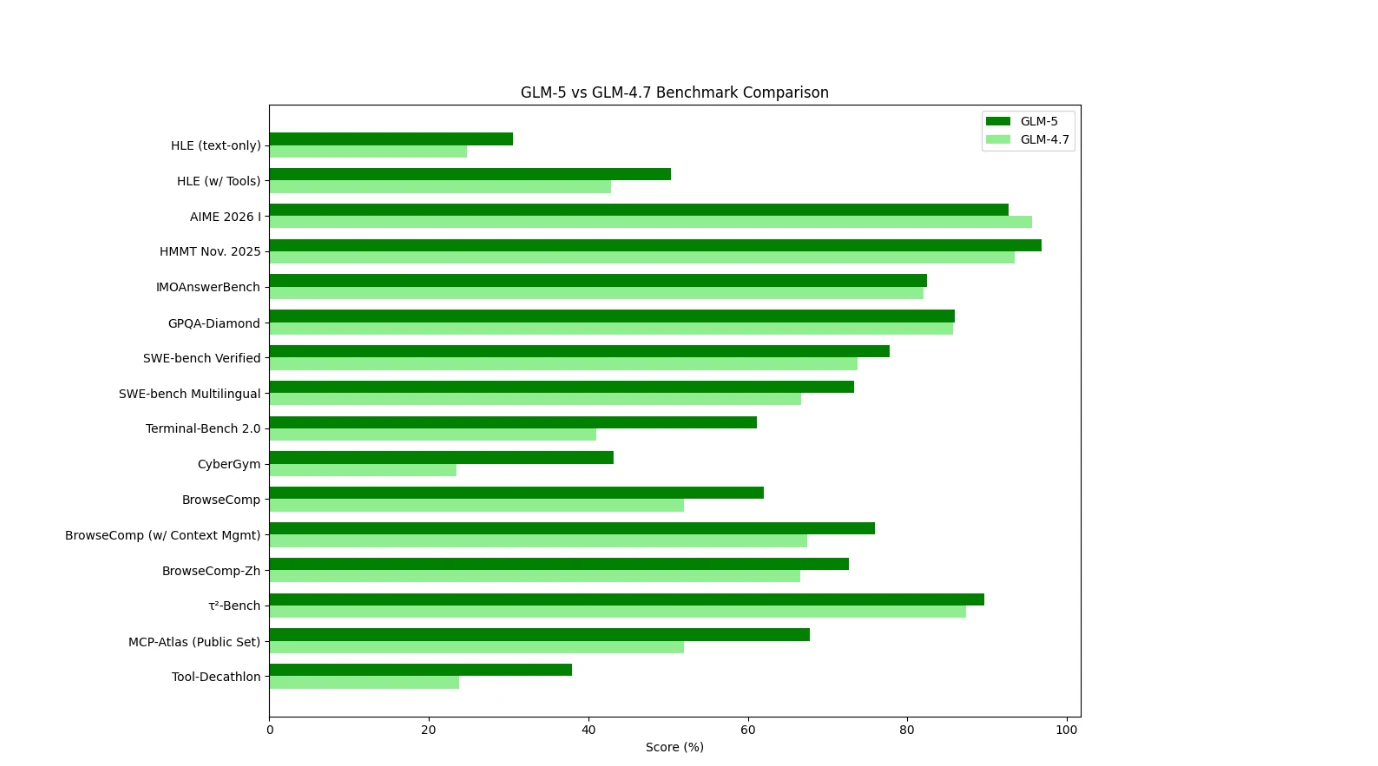
从基准测试来看,GLM-5 在工具使用、浏览和代理设置方面对 GLM-4.7 表现出广泛且一致的改进。最大的提升出现在需要多步规划、上下文管理和实际执行的场景中,这表明 GLM-5 针对代理型工作流而非孤立推理任务进行了优化。
GLM-4.7 的基准测试表现得更像一个效率优化的推理/编码模型,在经典的数学类评估中依然很强,但在交互式工具驱动的任务中不那么突出。
GLM-5 与 GLM-4.7 的 VRAM 需求
从 GLM-4.7 到 GLM-5 的 2.1 倍参数增长带来了显著的硬件影响。以下是 VRAM 细分:
GLM-5 推荐 GPU 配置
| 精度 | 所需 VRAM | 推荐配置 | 使用场景 |
|---|---|---|---|
| BF16 | 1,508 GB | 19x NVIDIA H100 (80GB) | 最高质量研究 |
| FP8 | 约 800GB | 10x NVIDIA H100 (80GB) | 生产部署 |
| INT4 | 约 400GB | 5x H100 (80GB) | 成本高效推理 |
GLM-4.7 推荐 GPU 配置
| 精度 | 所需 VRAM | 推荐配置 | 使用场景 |
|---|---|---|---|
| BF16 | 717 GB | 9x NVIDIA H100 (80GB) | 最高质量 |
| FP8 | 390 GB | 5x H100 (80GB) | 生产部署 |
| INT4 | 200 GB | 3x H100 (80GB) | 成本高效推理 |
在 FP8 部署下,GLM-5 通常需要比 GLM-4.7 多一倍的 GPU 数量。
对于预算有限的开发者,GLM-4.7 在编码密集型工作负载中提供了更强的每美元性能,SWE-bench Verified 上达到 73.8%,LiveCodeBench-v6 上达到 84.9%。
对于前沿研究和代理系统开发,GLM-5 更强的工具使用和长周期执行能力可以证明额外的硬件投资是值得的。
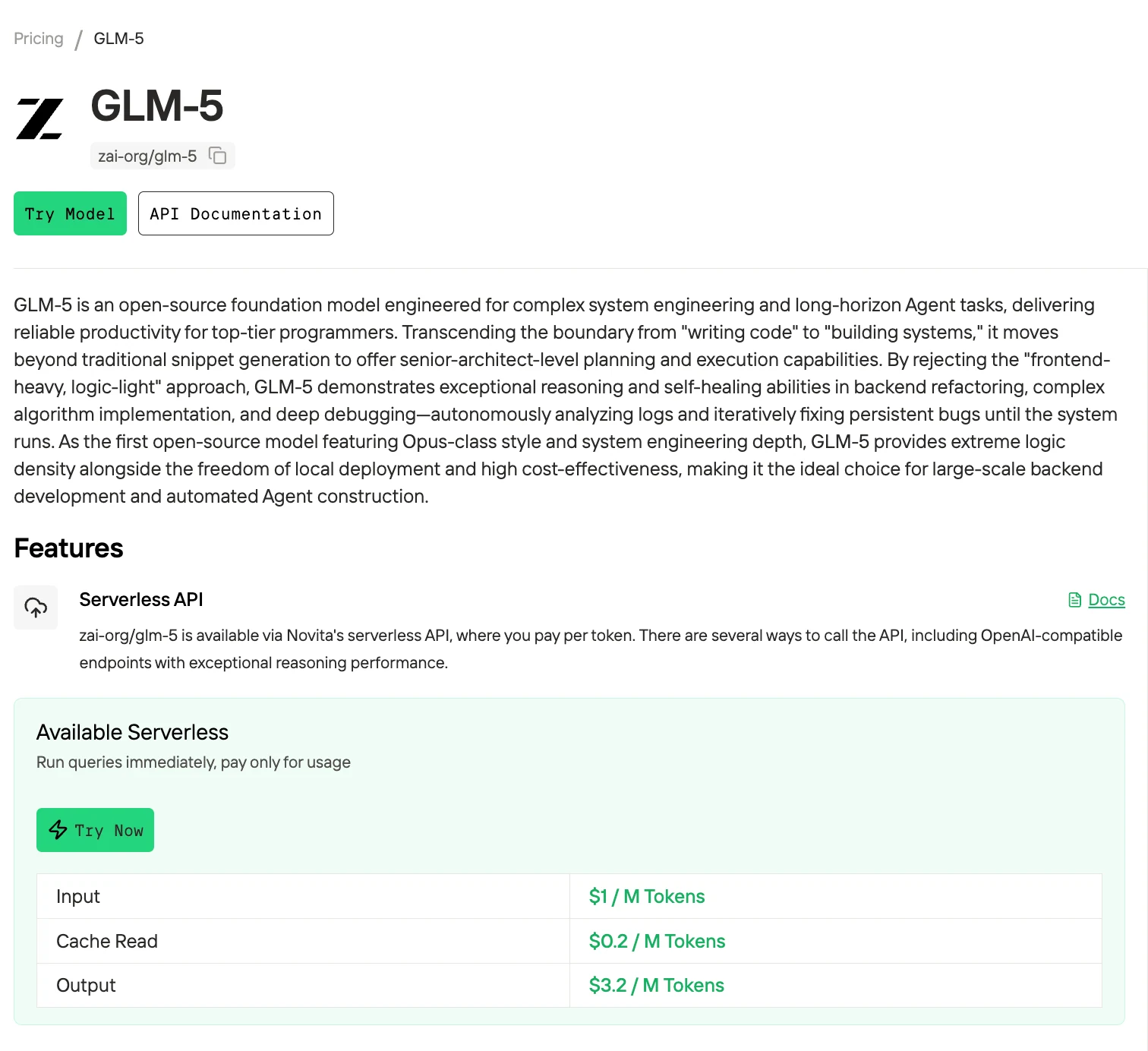
GLM-5 与 GLM-4.7 定价与 API 访问
| 模型 | 输入($ / M tokens) | 缓存读取($ / M tokens) | 输出($ / M tokens) |
|---|---|---|---|
| GLM-4.7 | $0.60 | $0.11 | $2.20 |
| GLM-5 | $1.00 | $0.20 | $3.20 |
缓存读取指的是读取之前存储在提示缓存中的 token 的成本。当相同的提示内容在多个请求中重用时,模型直接从缓存中检索这些 token,而不是从零开始重新处理。这既减少了推理延迟,也降低了成本。
第一步:登录并访问模型库
登录您的账户,点击模型库按钮。

第二步:选择您的模型
浏览可用的选项,选择适合您需求的模型。

第三步:开始免费试用
开始免费试用,探索所选模型的功能。
第四步:获取您的 API 密钥
为了通过 API 进行身份验证,我们将为您提供一个新的 API 密钥。进入“设置”页面,您可以按照图片所示复制 API 密钥。

第五步:安装 API
使用适合您编程语言的包管理器安装 API。
安装后,将必要的库导入您的开发环境。使用您的 API 密钥初始化 API,以开始与 Novita AI LLM 交互。以下是针对 Python 用户使用聊天补全 API 的示例。
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="zai-org/glm-5 或 zai-org/glm-4.7",
messages=[
{"role": "system", "content": "你是一个乐于助人的助手。"},
{"role": "user", "content": "你好,最近怎么样?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
GLM-5 与 GLM-4.7 决策框架总结
| 场景 | 推荐模型 | 主要原因 |
|---|---|---|
| 带有工具编排的多智能体系统 | GLM-5 | MCP-Atlas 提升 +15.8pp,Tool-Decathlon 提升 +14.2pp |
| 生产环境 SWE-bench 工作流 | GLM-4.7 | 73.8% 结果,硬件成本减半 |
| 网络安全与渗透测试 | GLM-5 | CyberGym 达 43.2% |
| 基于 IDE 的编码(Claude Code, Cline) | GLM-4.7 | 保留 Thinking + 更低延迟 |
| 前沿推理研究(HLE) | GLM-5 | 使用工具达 50.4%(最佳开源) |
| UI/前端“氛围编码” | GLM-4.7 | 针对现代 Web UI 的专用训练 |
| 终端自动化(长周期) | GLM-5 | Terminal-Bench 2.0 提升 +28.3pp |
| 数学竞赛(AIME, HMMT) | GLM-4.7 | 以更低成本持平/超越 GLM-5 |
| 预算受限的初创公司 | GLM-4.7 | 4x H100 vs 8x H100 的强编码能力 |
| 追求 AGI 极限的研究实验室 | GLM-5 | 28.5T token 预训练,slime RL 基础设施 |
GLM-5 并没有让 GLM-4.7 过时——它解决的是不同的问题。如果您的工作涉及需要大量工具使用和多步推理的长周期代理任务,那么在 GLM-5 上投入两倍的硬件成本会通过更高的任务完成率得到回报。如果您正在向成千上万的开发者交付编码助手,或者需要在 IDE 环境中快速迭代,那么 GLM-4.7 更精简的架构和专用训练使其成为更合适的选择。两款模型都代表了开源语言建模的重大成就,缩小了与前沿专有模型的差距,同时保持了完全的透明度和本地部署灵活性。
常见问题
GLM-5 和 GLM-4.7 之间主要的架构差异是什么?
GLM-5 将总参数从 355B 扩展到 753.9B(激活参数从 32B 到 40B),并集成了 DeepSeek 稀疏注意力(DSA)以降低部署成本,同时保留 202K 上下文长度。
我能在消费级硬件上运行 GLM-5 吗?
不能。GLM-5 在 FP8 模式下至少需要 10 块 H100 80GB GPU(800GB VRAM),远超消费级 GPU 的能力。
哪个模型在 SWE-bench 编码任务上表现更好?
GLM-5 在 SWE-bench Verified 上以 77.8% 的成绩略优于 GLM-4.7(+4pp),但 GLM-4.7 以一半的硬件成本取得 73.8% 的成绩,在生产环境中更实用。
Novita AI 是一个 AI 云平台,为开发者提供通过简单 API 部署 AI 模型的便捷途径,同时提供经济实惠且可靠的 GPU 云用于构建和扩展。
推荐阅读



