

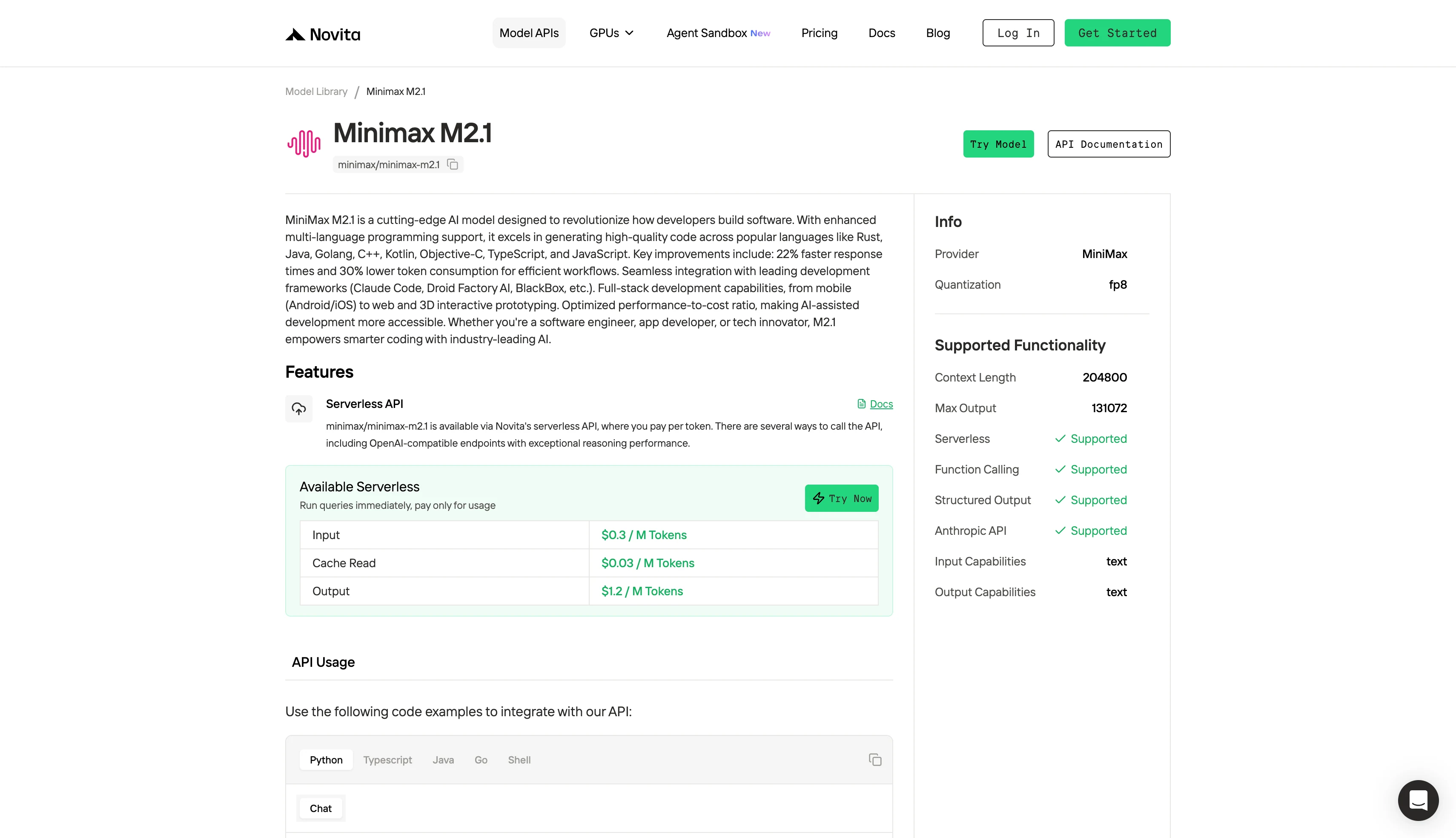
在 2026 年构建自主 AI 应用时,选择 MiniMax-M2.1 还是 DeepSeek V3.2 常常归结为关键权衡:代理通用性与原始推理能力。
本文对比了架构差异、所有变体的基准测试表现、硬件需求(从 RTX 4090 到 H100 集群)、定价结构以及实际部署权衡。无论你是构建自主编码代理、科学推理系统,还是对成本敏感的生产 API,了解哪个模型系列适合你的用例都能节省数千计算成本和数周集成工作。
快速回答:您应该选择哪个模型?
选择 MiniMax-M2.1 如果您需要:
- 自主编码代理,具备强大的工具调用可靠性(代理工作流、SWE-bench 流水线)
- 在多步执行中的稳定性,适用于 Droid / mini-swe-agent 等框架
- 多语言工程(Python、Java、C++、Rust、Kotlin)
- 更高的输出效率,适用于长代码生成和迭代补丁
- 更实际的 GPU 部署(在 4× H100 80GB 或 4× L40S 48GB 上可行)
选择 DeepSeek V3.2(或 Speciale)如果您需要:
- 深度推理能力,处理复杂逻辑推理和分析密集型任务
- 数学/竞赛级性能(Speciale 在 AIME 2025、GPQA、推理基准测试中占优)
- 推理密集的编码(LiveCodeBench 风格的算法和困难编程任务)
- 输入密集型工作负载,如长文档分析和知识推理
- 数据中心规模部署(即使量化也常需要 16+ 块 H100 级 GPU)
MiniMax M2.1 与 DeepSeek V3.2 架构对比
| 规格 | MiniMax-M2.1 | DeepSeek V3.2(所有变体) |
|---|---|---|
| 总参数量 | 228.7B | 685B |
| 每 token 活跃参数 | 10B | 37B |
| 上下文长度 | 128K–204.8K tokens | 128K tokens |
| 精度 | FP8 | FP8/BF16/F32 |
| 多模态支持 | 文本、音频、图像、视频 | 仅文本 |
| 发布日期 | 2025 年 12 月 23 日 | 2025 年 12 月 |
DeepSeek V3.2 变体分解
- DeepSeek V3.2 标准版和思考模式变体使用相同的基座模型权重。区别在于模型运行方式:一种优先使用默认推理平衡,另一种在输出前启用显式扩展推理。
- DeepSeek V3.2 Speciale 是一个独特的变体,针对最大推理能力进行了调优,但牺牲了工具集成和典型代理能力,在 2025 年 IMO/CMO/ICPC/IOI 中获得金牌!
- DeepSeek V3.2 Exp 是一个实验性分支,旨在探索新的架构效率(稀疏注意力),并非严格与主要 V3.2 训练相同。
MiniMax M2.1 与 DeepSeek V3.2 基准测试对比
DeepSeek V3.2(标准版)在实际 SWE-bench 风格编码任务中通常与 MiniMax-M2.1 有竞争力,但 MiniMax-M2.1 在多语言软件工程和代理框架方面通常表现出更强的整体鲁棒性。
实践中,DeepSeek V3.2 是一个强大的通用编码 + 代理模型,但 MiniMax-M2.1 通常在端到端工程执行、框架泛化和复杂多步编码流水线的工具使用可靠性方面优化得更好。
| 基准测试 | MiniMax M2.1 | DeepSeek V3.2 | Claude Opus 4.5 | 备注 |
|---|---|---|---|---|
| SWE-bench Verified | 74.0 | 73.1 | 80.9 | 实际 GitHub 问题解决 |
| Multi-SWE-bench | 49.4 | 37.4 | 50.0 | MiniMax 优于 Claude Sonnet 4.5(44.3) |
| SWE-bench Multilingual | 72.5 | 70.2 | 77.5 | Python, Java, C++, Rust, Kotlin |
| Terminal-bench 2.0 | 47.9 | 46.4 | 57.8 | CLI 和 shell 脚本 |
| 框架/基准测试 | MiniMax-M2.1 | DeepSeek V3.2 | Claude Opus 4.5 |
|---|---|---|---|
| SWE-bench Verified (Droid) | 71.3 | 67.0 | 75.2 |
| SWE-bench Verified (mini-swe-agent) | 67.0 | 60.0 | 74.4 |
| SWT-bench (测试生成) | 69.3 | 62.0 | 80.2 |
| SWE-Review (代码审查) | 8.9 | 6.4 | 16.2 |
| OctoCodingbench | 26.1 | 26.0 | 36.2 |
DeepSeek V3.2 Speciale 本质上是一个高计算推理优化变体,相比 DeepSeek V3.2 标准版和 MiniMax-M2.1,它在数学密集和深度推理基准测试(如 AIME 2025、GPQA 和推理密集型编码评估(如 LiveCodeBench))上往往表现更优,使其更适合困难算法问题和竞赛风格任务。
| 指标类别 | MiniMax-M2.1 | DeepSeek V3.2 Speciale |
|---|---|---|
| 智能指数(整体推理) | 39.5 | 34.1 |
| 编码指数 | 32.8 | 37.9 |
| 数学指数 | 82.7 | 96.7 |
| GPQA(研究生级推理) | 83.0 % | 87.1 % |
| MMLU Pro(高级知识) | 87.5 % | 86.3 % |
| HLE(硬语言评估) | 22.2 % | 26.1 % |
| LiveCodeBench(实际编码) | 81.0 % | 89.6 % |
| AIME 2025(高级数学) | 82.7 % | 96.7 % |
| SciCode(科学代码) | 40.7 % | 44.0 % |
| LCR(代码审查) | 59.0 % | 59.3 % |
| IFBench(指令遵循) | 69.9 % | 63.9 % |
| TerminalBench Hard(CLI 命令生成) | 28.8 % | 34.8 % |
DeepSeek V3.2 的优势在于其大规模推理、复杂逻辑推断和强大的通用语言理解能力。
MiniMax-M2.1 更侧重于代码质量、对工程任务的适应以及处理长对话上下文,通常在面向软件开发的基准测试中得分更高。
MiniMax M2.1 与 DeepSeek V3.2 的显存需求
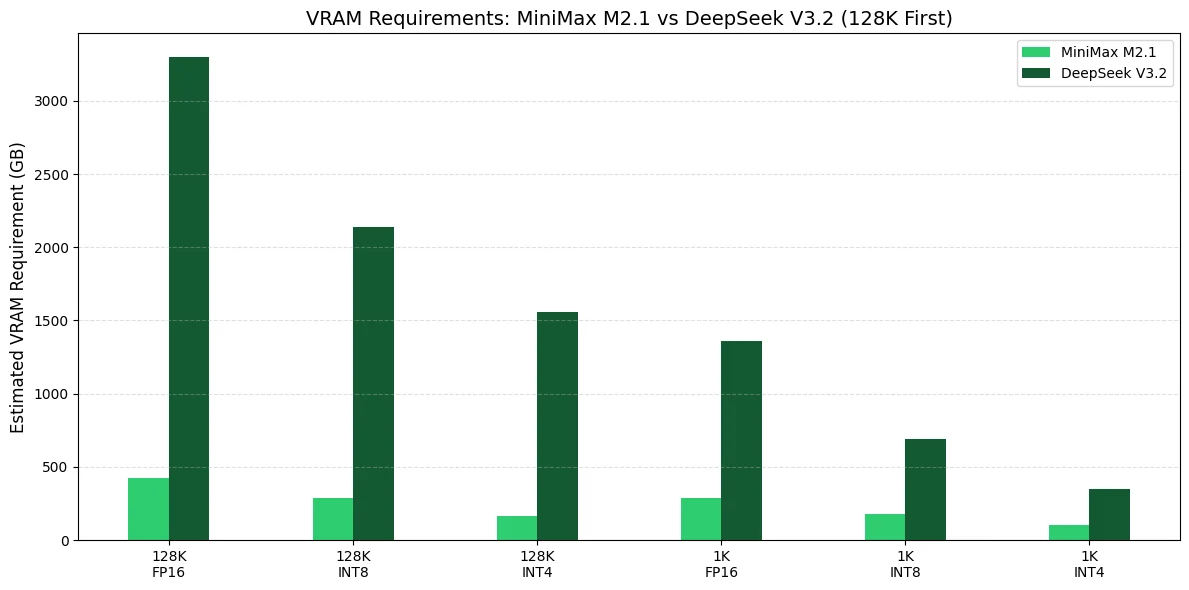
对于你自己的代理生产环境,我会推荐截然不同的 GPU 策略来处理 MiniMax M2.1 与 DeepSeek V3.2,因为它们的显存占用规模完全不同。
MiniMax M2.1 推荐 GPU
最佳实践选择: 4× H100 80GB(如果预算允许,可选 4× H200 141GB)
- 稳定的长多步工具调用工作流
- 为较大上下文 + KV 缓存留出足够的显存余量
- SWE-bench 风格代理流水线的良好吞吐量和可靠性
高性价比替代方案: 4× L40S 48GB(INT4/INT8 量化)
- 适合个人部署
- 比 H100 便宜得多
- 对代理工作流仍然实用
除非预算紧张,否则不推荐: 8× RTX 4090 24GB
- 可以工作,但 PCIe 瓶颈和多 GPU 通信会损害代理延迟。
结论: 如果你想要一个现实的“个人生产代理”模型,MiniMax M2.1 是明确的选择。
DeepSeek V3.2 推荐 GPU
最低实际配置: 16× H100 80GB(INT4/INT8)
- 即使量化,DeepSeek V3.2 也需要大量显存
- 工具调用代理持续运行会很昂贵
更实际的生产配置: 32× H100 80GB(或 16× H200 141GB)
- 如果你想要长上下文(128K)且没有持续内存压力,则需要此配置
- 更好的稳定性和吞吐量
结论: DeepSeek V3.2 更像是一个数据中心模型。除非你已经拥有 GPU 集群,否则个人代理生产并不划算。
如果你的目标是稳定、可扩展的编码代理系统,请选择:
MiniMax M2.1 + 4× H100 80GB(性能、上下文和部署可行性的最佳平衡)。
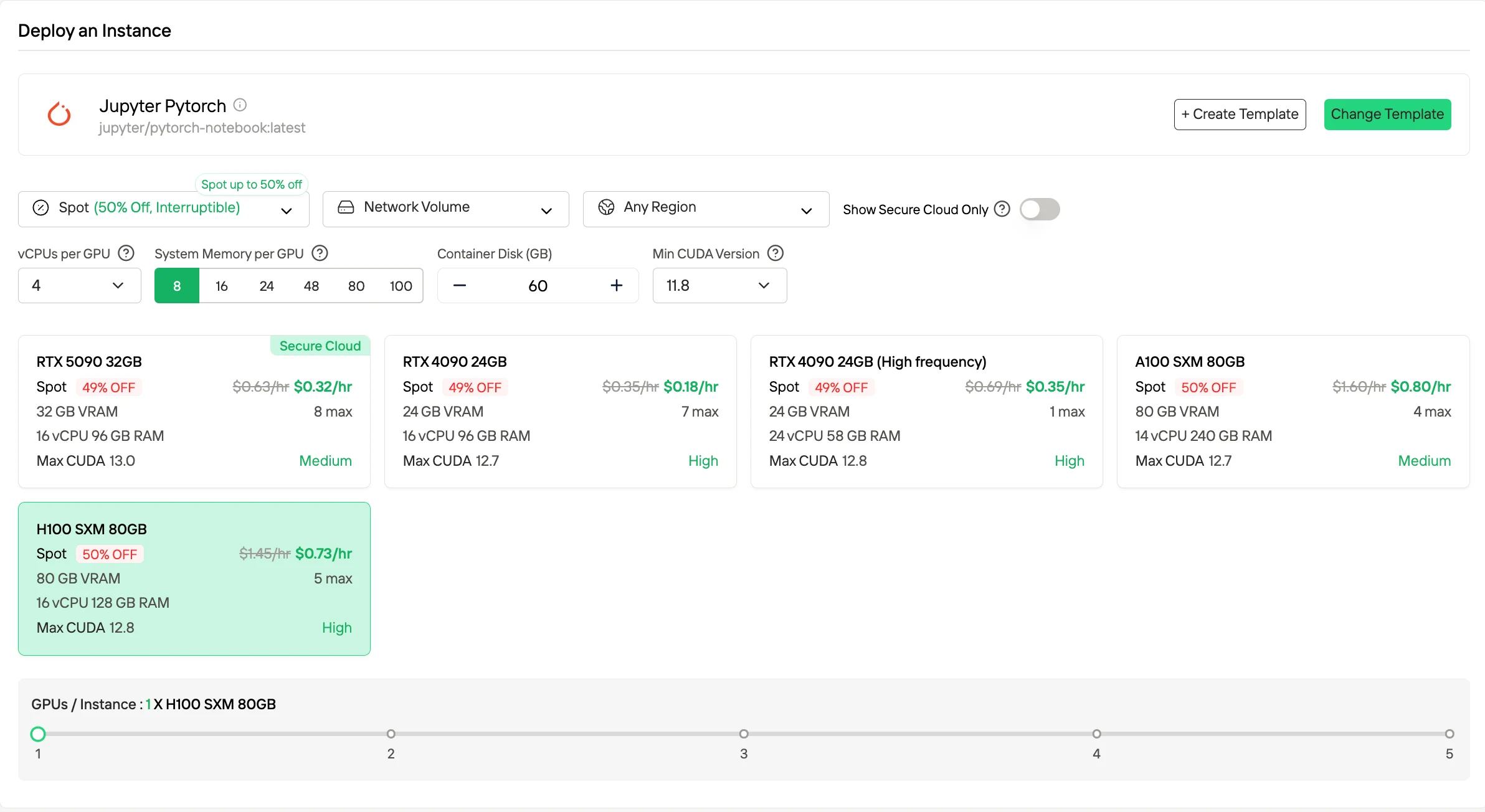
按需付费是一种按实际运行时间计费的即用即付模式,为可变工作负载和实验提供最大灵活性,因为你只需在 GPU 运行时付费。
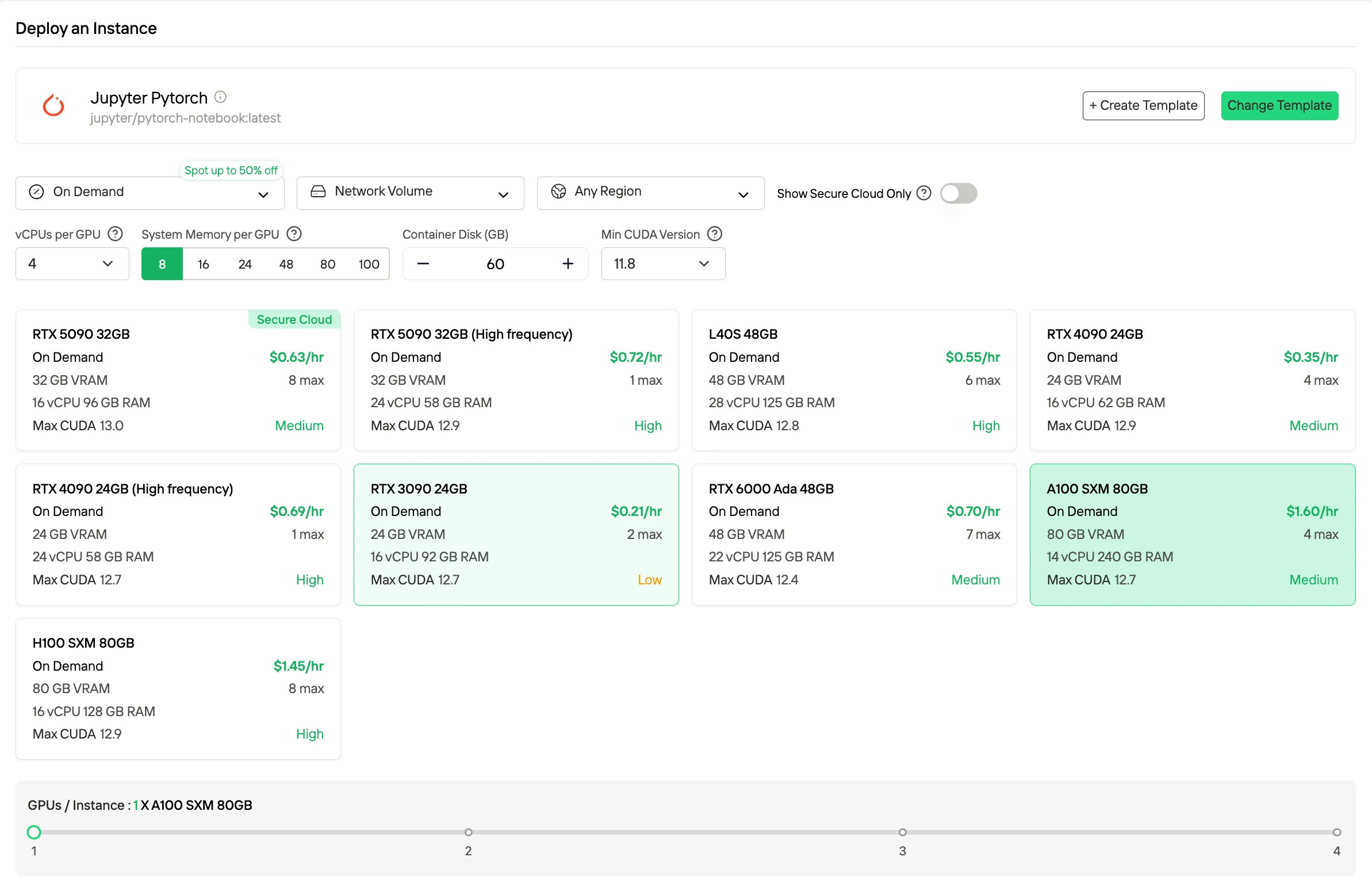
如果你想要更低成本,Spot 实例通常通过使用闲置容量便宜高达 50%,但它们可能会被中断,因此最适合容错或批处理工作负载。
MiniMax M2.1 与 DeepSeek V3.2 成本分析
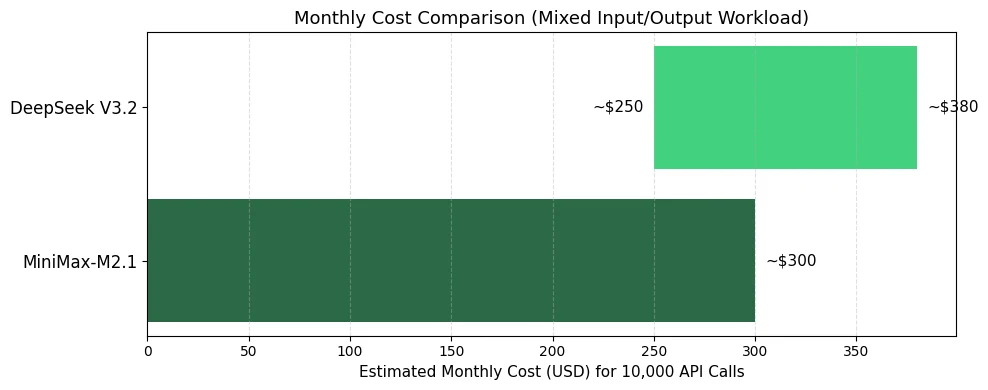
- 选择 MiniMax-M2.1 用于: 高输出与输入比的工作负载、涉及工具调用的代理任务、需要较低总混合成本的应用
- 选择 DeepSeek V3.2 用于: 输入密集型工作负载(例如文档分析)、专用推理任务(质量足以证明稍高成本的合理性)
如何访问 MiniMax M2.1 和 DeepSeek V3.2
选项 1:快速 API
步骤 1:登录并访问模型库
登录你的账户,点击 模型库 按钮。

步骤 2:选择模型
浏览可用选项,选择适合你需求的模型。

步骤 3:开始免费试用
开始免费试用,探索所选模型的能力。
步骤 4:获取 API 密钥
为了通过 API 进行身份验证,我们将为你提供一个新 API 密钥。进入“设置“页面,你可以复制 API 密钥,如图所示。

from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="minimax/minimax-m2.1",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
选项 2:使用 OpenAI Agents SDK 的多代理工作流
通过将 Novita AI 与 OpenAI Agents SDK 集成,构建高级多代理系统:
- 即插即用: 在任何 OpenAI Agents 工作流中使用 Novita AI 的 LLM。
- 支持交接、路由和工具使用: 设计能够委托、分流或运行函数的代理,所有这些都由 Novita AI 的模型驱动。
- Python 集成: 只需将 SDK 指向 Novita 的端点(
https://api.novita.ai/v3/openai)并使用你的 API 密钥。
选项 3:在第三方平台上连接 GLM 4.7 Flash API
- Hugging Face:在 Spaces、pipeline 或通过 Novita AI 端点的 Transformers 库中使用 GLM 4.7 和 MiniMax M2.1。
- 代理与编排框架: 通过官方连接器和逐步集成指南,轻松将 Novita AI 与 Continue、AnythingLLM、LangChain、Dify 和 Langflow 等合作伙伴平台连接。
- OpenAI 兼容 API: 通过官方连接器和逐步集成指南,轻松将 Novita AI 与 Claude code、Cursor、Trae、Continue、Codex、OpenCode、AnythingLLM、LangChain、Dify 和 Langflow 等合作伙伴平台连接。
对于自主代理、多语言编码和对成本敏感的生产环境,选择 MiniMax-M2.1。对于科学推理、竞赛编程或专用数学任务,选择合适的 DeepSeek V3.2 变体:标准版用于平衡日常使用,Speciale 用于最大化推理,思考模式用于思维链问题解决,Exp 用于长上下文研究。
常见问题
对于自主编码代理,MiniMax-M2.1 和 DeepSeek V3.2 哪个更好?
MiniMax-M2.1 通常比 DeepSeek V3.2 更适合工具调用的编码代理和多步 SWE-bench 工作流。
对于数学和竞赛级推理,MiniMax-M2.1 和 DeepSeek V3.2 哪个更强?
DeepSeek V3.2 Speciale 在 AIME 风格数学和深度推理基准上比 MiniMax-M2.1 更强。
对于个人生产部署,MiniMax-M2.1 和 DeepSeek V3.2 哪个更容易?
MiniMax-M2.1 比 DeepSeek V3.2 容易部署得多,需要的 GPU 集群小得多。
Novita AI 是一个 AI 云平台,为开发者提供通过简单 API 部署 AI 模型的便捷方式,同时提供价格实惠且可靠的 GPU 云用于构建和扩展。



