

2026 年構建自主 AI 應用時,在 MiniMax-M2.1 與 DeepSeek V3.2 之間做選擇,往往取決於一個關鍵取捨:代理任務的多功能性與原始推理能力。
這篇對比將深入剖析兩者的架構差異、所有變體的基準測試表現、硬體需求(從 RTX 4090 到 H100 集群)、定價結構,以及實際部署的取捨。無論您正在構建自主編碼代理、科學推理系統,還是對成本敏感的生產級 API,了解哪個模型系列適合您的使用場景,都能節省數千元的運算成本,並減少數週的整合工作。
快速解答:該選擇哪個模型?
選擇 MiniMax-M2.1 如果您需要:
- 自主編碼代理,具備強大的工具呼叫可靠性(代理工作流、SWE-bench 流程)
- 穩定的多步驟執行,適用於 Droid / mini-swe-agent 等框架
- 多語言工程開發(Python、Java、C++、Rust、Kotlin)
- 高輸出效率,適合長代碼生成與迭代修補
- 更實用的 GPU 部署方案(4× H100 80GB 或 4× L40S 48GB 即可穩定運行)
選擇 DeepSeek V3.2(或 Speciale 變體)如果您需要:
- 深度推理能力,適用於複雜邏輯推斷與分析密集型任務
- 數學/競賽級表現(Speciale 變體在 AIME 2025、GPQA、推理基準測試中均位居前列)
- 推理密集型編碼(LiveCodeBench 風格的算法與高難度編程任務)
- 輸入密集型工作負載,如長文檔分析與知識推理
- 數據中心級部署(即使量化後通常也需要 16 張以上 H100 級 GPU)
MiniMax M2.1 與 DeepSeek V3.2 的架構對比
| 規格 | MiniMax-M2.1 | DeepSeek V3.2(所有變體) |
|---|---|---|
| 總參數量 | 228.7B | 685B |
| 活躍參數量(每 token) | 10B | 37B |
| 上下文長度 | 128K-204.8K tokens | 128K tokens |
| 精度 | FP8 | FP8/BF16/F32 |
| 多模態支援 | 文字、音訊、圖片、影片 | 僅文字 |
| 發布日期 | 2025 年 12 月 23 日 | 2025 年 12 月 |
DeepSeek V3.2 變體明細
- DeepSeek V3.2 標準版與思考模式變體使用相同的基礎模型權重,差異在於模型的運行方式:前者預設平衡推理與輸出,後者會在輸出前啟用明確的擴展推理流程。
- DeepSeek V3.2 Speciale 是專為最大化推理能力調優的獨立變體,但犧牲了工具整合與常規代理能力,曾在 2025 年 IMO/CMO/ICPC/IOI 競賽中獲得金牌!
- DeepSeek V3.2 Exp 是實驗性分支,旨在探索新的架構效率(稀疏注意力),與主線 V3.2 的訓練並不完全相同。
MiniMax M2.1 與 DeepSeek V3.2 的基準測試對比
在真實世界的 SWE-bench 風格編碼任務中,DeepSeek V3.2(標準版)通常能與 MiniMax-M2.1 勢均力敵,但 MiniMax-M2.1 在多語言軟體工程與代理框架方面展現出更強的整體穩健性。
實際使用中,DeepSeek V3.2 是強大的通用編碼+代理模型,但 MiniMax-M2.1 通常在端到端工程執行、框架泛化能力,以及複雜多步驟編碼流程中的工具使用可靠性方面表現更優。
| 基準測試 | MiniMax M2.1 | DeepSeek V3.2 | Claude Opus 4.5 | 備註 |
|---|---|---|---|---|
| SWE-bench 驗證版 | 74.0 | 73.1 | 80.9 | 真實 GitHub 問題解決能力 |
| 多語言 SWE-bench | 49.4 | 37.4 | 50.0 | MiniMax 表現優於 Claude Sonnet 4.5(44.3 分) |
| SWE-bench 多語言版 | 72.5 | 70.2 | 77.5 | 支援 Python、Java、C++、Rust、Kotlin |
| Terminal-bench 2.0 | 47.9 | 46.4 | 57.8 | CLI 與 shell 腳本編寫 |
| 框架/基準測試 | MiniMax-M2.1 | DeepSeek V3.2 | Claude Opus 4.5 |
|---|---|---|---|
| SWE-bench 驗證版(Droid 框架) | 71.3 | 67.0 | 75.2 |
| SWE-bench 驗證版(mini-swe-agent 框架) | 67.0 | 60.0 | 74.4 |
| SWT-bench(測試生成) | 69.3 | 62.0 | 80.2 |
| SWE-Review(代碼審查) | 8.9 | 6.4 | 16.2 |
| OctoCodingbench | 26.1 | 26.0 | 36.2 |
與 DeepSeek V3.2 標準版和 MiniMax-M2.1 相比,DeepSeek V3.2 Speciale 本質上是高算力推理優化變體:它在數學密集型與深度推理基準測試(如 AIME 2025、GPQA)以及推理密集型編碼評估(如 LiveCodeBench)中通常表現優於兩者,更適合解決困難算法問題與競賽風格任務。
| 指標類別 | MiniMax-M2.1 | DeepSeek V3.2 Speciale |
|---|---|---|
| 智慧指數(整體推理) | 39.5 | 34.1 |
| 編碼指數 | 32.8 | 37.9 |
| 數學指數 | 82.7 | 96.7 |
| GPQA(研究生級推理) | 83.0 % | 87.1 % |
| MMLU Pro(進階知識) | 87.5 % | 86.3 % |
| HLE(難度語言評估) | 22.2 % | 26.1 % |
| LiveCodeBench(真實場景編碼) | 81.0 % | 89.6 % |
| AIME 2025(進階數學) | 82.7 % | 96.7 % |
| SciCode(科學編碼) | 40.7 % | 44.0 % |
| LCR(代碼審查) | 59.0 % | 59.3 % |
| IFBench(指令遵循) | 69.9 % | 63.9 % |
| TerminalBench Hard(CLI 指令生成) | 28.8 % | 34.8 % |
DeepSeek V3.2 的優勢在於其強大的大規模推理、複雜邏輯推斷與優異的通用語言理解能力。 MiniMax-M2.1 則更專注於代碼品質、工程任務適配與長對話上下文處理,在軟體開發導向的基準測試中通常得分更高。
MiniMax M2.1 與 DeepSeek V3.2 的 VRAM 需求
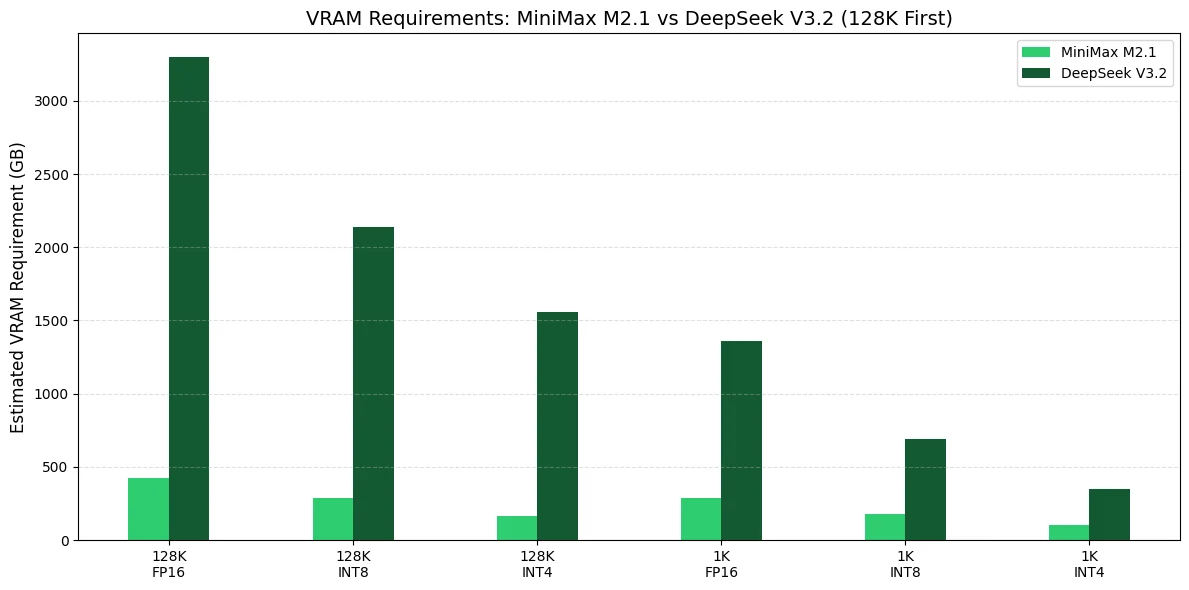
若您要搭建自主代理的生產環境,我建議為 MiniMax M2.1 和 DeepSeek V3.2 採用完全不同的 GPU 策略,因為兩者的 VRAM 佔用規模差距極大。
MiniMax M2.1 推薦 GPU
最優實用選擇:4× H100 80GB(預算充足可選 4× H200 141GB)
- 穩定運行長多步驟工具呼叫工作流
- 有足夠的 VRAM 餘量應對大上下文與 KV 快取
- 對 SWE-bench 風格的代理流程有良好的吞吐量與可靠性
高性價比替代方案:4× L40S 48GB(INT4/INT8 量化)
- 適合個人部署
- 成本遠低於 H100
- 仍可勝任代理工作流需求
除非預算非常緊張,否則不推薦:8× RTX 4090 24GB
- 可以運行,但 PCIe 瓶頸與多 GPU 通訊會嚴重影響代理延遲。
結論:如果您想要一個切實可行的「個人生產級代理」模型,MiniMax M2.1 是毫無疑問的勝出者。
DeepSeek V3.2 推薦 GPU
最低可行配置:16× H100 80GB(INT4/INT8 量化)
- 即使量化後,DeepSeek V3.2 仍需要極大的 VRAM
- 持續運行工具呼叫代理的成本會非常高昂
更合理的生產配置:32× H100 80GB(或 16× H200 141GB)
- 若想無壓力運行 128K 長上下文,需要此配置
- 能提供更好的穩定性與吞吐量
結論:DeepSeek V3.2 更偏向數據中心級模型。除非您已經擁有 GPU 集群,否則對個人代理生產而言性價比極低。
如果您目標是搭建穩定、可擴展的編碼代理系統,推薦選擇: MiniMax M2.1 + 4× H100 80GB(性能、上下文長度與部署可行性的最佳平衡)。
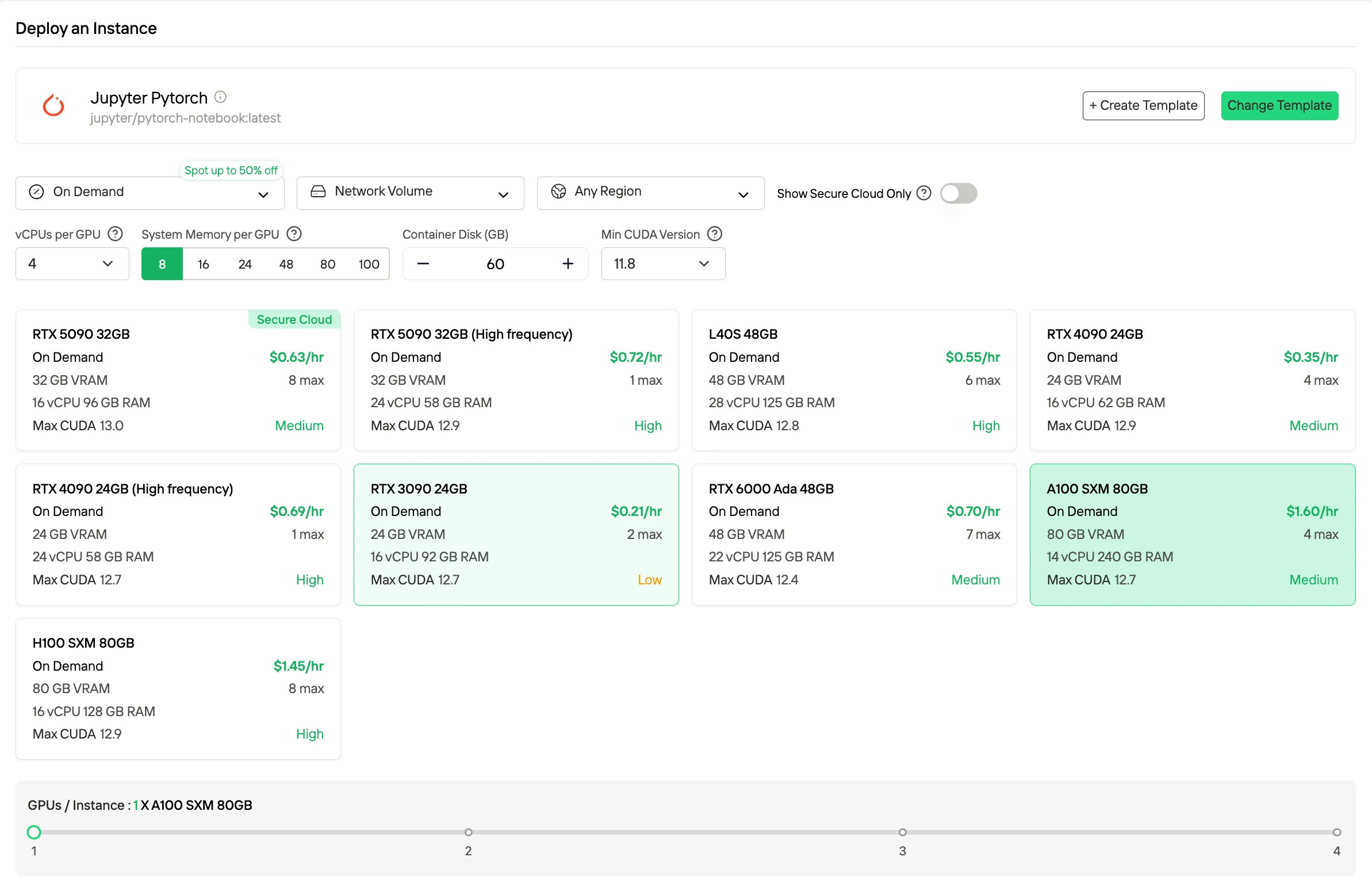
隨需應變(On-Demand) 是按運行時長付費的計費模式,僅在 GPU 運行時計費,為可變工作負載與實驗提供最大的靈活性。
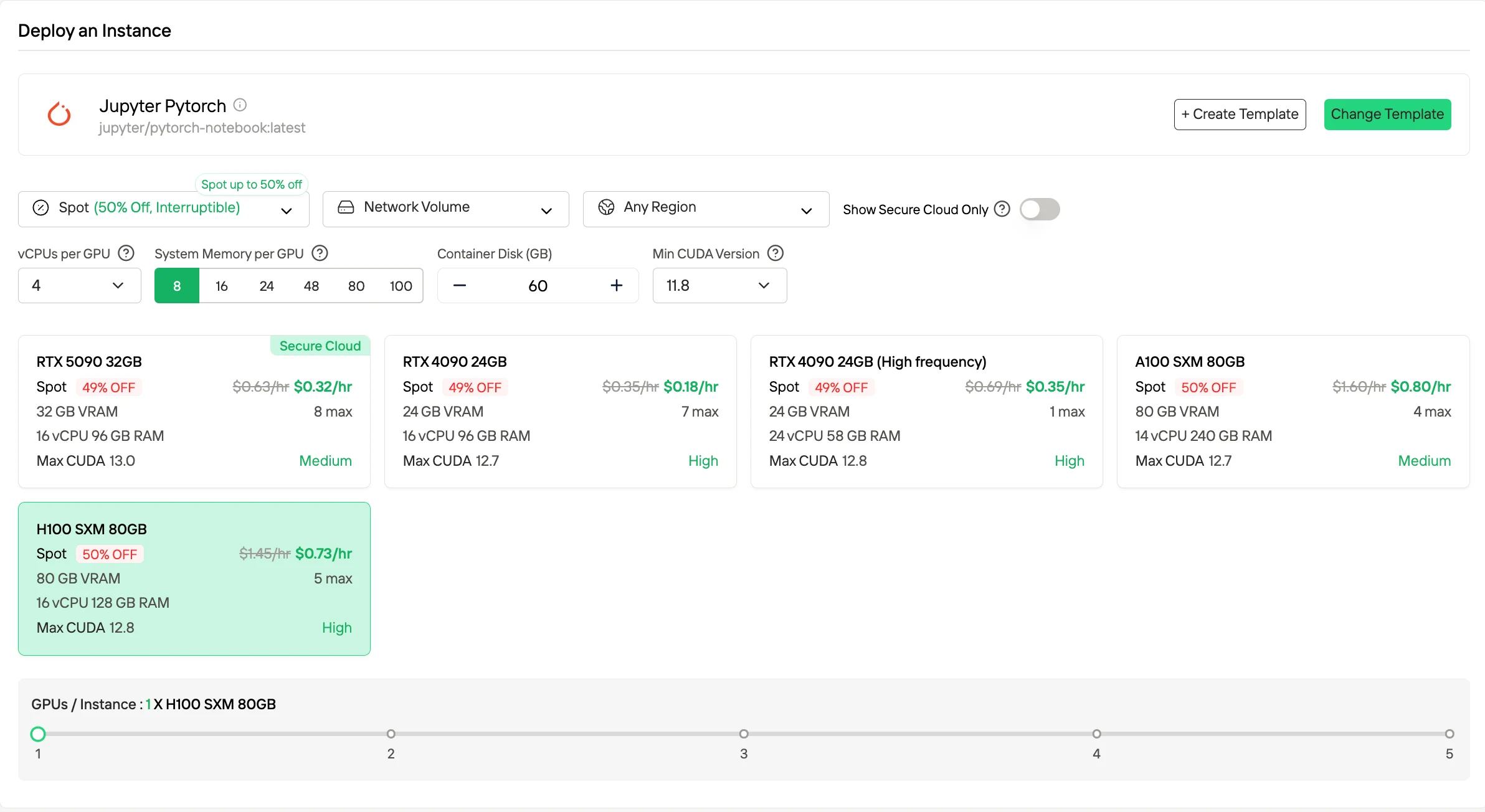
如果您想進一步降低成本,搶佔式實例(Spot Instances) 通常能利用閒置容量,價格比隨需應變實例低 50% 左右,但可能會被中斷,因此最適合容錯或批次工作負載。
MiniMax M2.1 與 DeepSeek V3.2 的成本分析
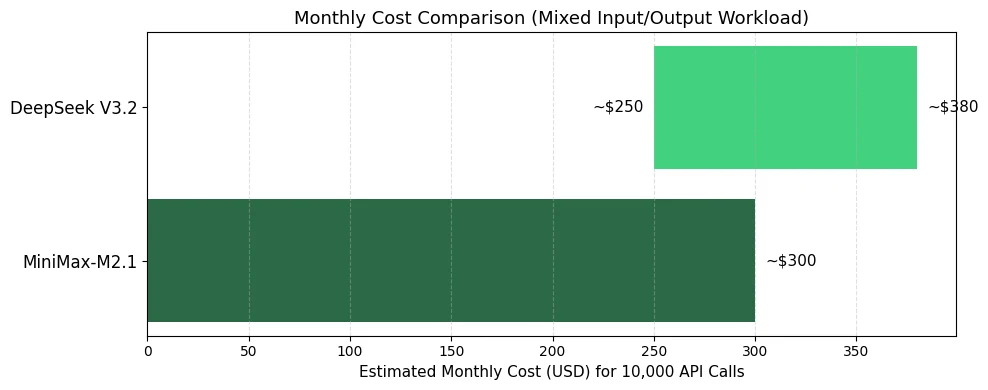
- 選擇 MiniMax-M2.1 適用於: 高輸出輸入比的工作負載、帶工具呼叫的代理任務、需要較低總體混合成本的應用
- 選擇 DeepSeek V3.2 適用於: 輸入密集型工作負載(如文檔分析)、品質優先且可接受略高成本的專業推理任務
如何獲取 MiniMax M2.1 與 DeepSeek V3.2
選項 1:快速 API
步驟 1:登入並進入模型庫
登入您的帳號,點擊 模型庫 按鈕。

步驟 2:選擇所需模型
瀏覽可用選項,選擇符合您需求的模型。

步驟 3:開始免費試用
開始免費試用,探索所選模型的能力。
步驟 4:獲取 API 金鑰
要進行 API 認證,我們會為您提供新的 API 金鑰。進入「設定」頁面,即可按照圖中指示複製 API 金鑰。

from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="minimax/minimax-m2.1",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
選項 2:使用 OpenAI Agents SDK 構建多代理工作流
通過將 Novita AI 與 OpenAI Agents SDK 整合,構建高級多代理系統:
- 即插即用: 可在任何 OpenAI Agents 工作流中使用 Novita AI 的 LLM。
- 支援交接、路由與工具使用: 可設計能委派任務、分流處理或執行函數的代理,全部由 Novita AI 的模型驅動。
- Python 整合: 只需將 SDK 指向 Novita 的端點(
https://api.novita.ai/v3/openai)並使用您的 API 金鑰即可。
選項 3:在第三方平台連接 GLM 4.7 Flash API
- Hugging Face:可透過 Novita AI 端點,在 Spaces、pipeline 中或搭配 Transformers 庫使用 GLM 4.7 與 MiniMax M2.1。
- 代理與編排框架: 透過官方連接器與逐步整合指南,可輕鬆將 Novita AI 與合作夥伴平台如 Continue、AnythingLLM、LangChain、Dify 和 Langflow 連接。
- OpenAI 相容 API: 透過官方連接器與逐步整合指南,可輕鬆將 Novita AI 與合作夥伴平台如 Claude code、Cursor、Trae、Continue、Codex、OpenCode、AnythingLLM、LangChain、Dify 和 Langflow 連接。
總結:若需要自主代理、多語言編碼或對成本敏感的生產環境,選擇 MiniMax-M2.1。若需要科學推理、競賽編程或專業數學任務,可根據需求選擇對應的 DeepSeek V3.2 變體:日常平衡使用選標準版、最大化推理選 Speciale、需要鏈式思考解題選 Thinking 模式、長上下文研究選 Exp 變體。
常見問題
哪個模型更適合自主編碼代理,MiniMax-M2.1 還是 DeepSeek V3.2? MiniMax-M2.1 在工具呼叫型編碼代理與多步驟 SWE-bench 工作流方面通常優於 DeepSeek V3.2。
哪個模型在數學與競賽級推理方面更強,MiniMax-M2.1 還是 DeepSeek V3.2? DeepSeek V3.2 Speciale 在 AIME 風格數學與深度推理基準測試中優於 MiniMax-M2.1。
哪個模型更適合個人生產部署,MiniMax-M2.1 還是 DeepSeek V3.2? MiniMax-M2.1 的部署難度遠低於 DeepSeek V3.2,僅需小得多的 GPU 集群即可運行。
Novita AI 是一個 AI 雲端平台,為開發者提供簡單的 API 介面,方便部署 AI 模型,同時也提供高性價比、可靠的 GPU 雲端服務,用於構建與擴展 AI 應用。



