

Beim Erstellen autonomer KI-Anwendungen im Jahr 2026 läuft die Wahl zwischen MiniMax-M2.1 und DeepSeek V3.2 oft auf einen kritischen Kompromiss hinaus: agentische Vielseitigkeit gegenüber roher Reasoning-Leistung.
Dieser Vergleich analysiert die architektonischen Unterschiede, die Benchmark-Leistung über alle Varianten hinweg, Hardware-Anforderungen (von RTX 4090 bis hin zu H100-Clustern), Preisstrukturen und reale Bereitstellungskompromisse. Egal, ob Sie autonome Coding-Agenten, wissenschaftliche Reasoning-Systeme oder kostensensitive Produktions-APIs entwickeln: Das Verständnis, welche Modellfamilie zu Ihrem Anwendungsfall passt, kann Tausende an Rechenkosten und Wochen an Integrationsarbeit sparen.
Schnellantwort: Welches Modell sollten Sie wählen?
Wählen Sie MiniMax-M2.1, wenn Sie Folgendes benötigen:
- Autonome Coding-Agenten mit hoher Zuverlässigkeit bei Tool-Aufrufen (agentische Workflows, SWE-bench-Pipelines)
- Stabile Mehrschritt-Ausführung in Frameworks wie Droid / mini-swe-agent
- Mehrsprachiges Engineering (Python, Java, C++, Rust, Kotlin)
- Höhere Effizienz bei output-lastigen Aufgaben für lange Codegenerierung und iteratives Patchen
- Praktischere GPU-Bereitstellung (realistisch auf 4× H100 80GB oder 4× L40S 48GB)
Wählen Sie DeepSeek V3.2 (oder Speciale), wenn Sie Folgendes benötigen:
- Hohe Reasoning-Leistung für komplexe logische Schlussfolgerungen und analyseintensive Aufgaben
- Mathematik-/Wettbewerbsniveau-Leistung (Speciale dominiert AIME 2025, GPQA, Reasoning-Benchmarks)
- Reasoning-intensives Coding (algorithmische und schwierige Programmieraufgaben im Stil von LiveCodeBench)
- Input-lastige Workloads wie lange Dokumentenanalyse und Wissens-Reasoning
- Bereitstellung im Datenzentrumsmaßstab (erfordert oft 16×+ GPUs der H100-Klasse selbst bei Quantisierung)
Probieren Sie jetzt coole Modelle aus!
Architektur von Minimax M2.1 und DeepSeek V3.2
| Spezifikation | MiniMax-M2.1 | DeepSeek V3.2 (Alle Varianten) |
|---|---|---|
| Gesamtparameter | 228,7B | 685B |
| Aktive Parameter (pro Token) | 10B | 37B |
| Kontextlänge | 128K–204,8K Token | 128K Token |
| Präzision | FP8 | FP8/BF16/F32 |
| Multimodale Unterstützung | Text, Audio, Bilder, Video | Nur Text |
| Veröffentlichungsdatum | 23. Dezember 2025 | Dezember 2025 |
Aufschlüsselung der DeepSeek V3.2-Varianten
- Die Varianten DeepSeek V3.2 Standard und Thinking-Modus basieren auf den gleichen Basismodellgewichten. Der Unterschied liegt in der Ausführung des Modells: Eine priorisiert eine standardmäßige Reasoning-Balance, die andere ermöglicht explizites erweitertes Reasoning vor der Ausgabe.
- DeepSeek V3.2 Speciale ist eine eigenständige Variante, die auf maximale Reasoning-Leistung abgestimmt ist, jedoch auf Kosten der Tool-Integration und typischer Agentenfunktionen. Sie hat Goldmedaillen bei IMO/CMO/ICPC/IOI 2025 gewonnen!
- DeepSeek V3.2 Exp ist ein experimenteller Zweig, der entwickelt wurde, um neue architektonische Effizienzen (sparse Attention) zu erforschen, und ist nicht streng identisch mit dem primären V3.2-Training.
Benchmark-Vergleich von Minimax M2.1 und DeepSeek V3.2
DeepSeek V3.2 (Standard) ist generell wettbewerbsfähig mit MiniMax-M2.1 bei realen SWE-bench-ähnlichen Coding-Aufgaben, aber MiniMax-M2.1 zeigt tendenziell eine stärkere Gesamtrobustheit bei mehrsprachigem Software-Engineering und Agenten-Frameworks.
In der Praxis ist DeepSeek V3.2 ein starkes allgemeines Coding- + Agentenmodell, aber MiniMax-M2.1 ist in der Regel besser optimiert für durchgängige Engineering-Ausführung, Framework-Generalisierung und Tool-Nutzungszuverlässigkeit in komplexen mehrstufigen Coding-Pipelines.
| Benchmark | MiniMax M2.1 | DeepSeek V3.2 | Claude Opus 4.5 | Hinweise |
|---|---|---|---|---|
| SWE-bench Verified | 74,0 | 73,1 | 80,9 | Lösung von realen GitHub-Issues |
| Multi-SWE-bench | 49,4 | 37,4 | 50,0 | MiniMax übertrifft Claude Sonnet 4.5 (44,3) |
| SWE-bench Multilingual | 72,5 | 70,2 | 77,5 | Python, Java, C++, Rust, Kotlin |
| Terminal-bench 2.0 | 47,9 | 46,4 | 57,8 | CLI- und Shell-Skripting |
| Framework/Benchmark | MiniMax-M2.1 | DeepSeek V3.2 | Claude Opus 4.5 |
|---|---|---|---|
| SWE-bench Verified (Droid) | 71,3 | 67,0 | 75,2 |
| SWE-bench Verified (mini-swe-agent) | 67,0 | 60,0 | 74,4 |
| SWT-bench (Testgenerierung) | 69,3 | 62,0 | 80,2 |
| SWE-Review (Code-Review) | 8,9 | 6,4 | 16,2 |
| OctoCodingbench | 26,1 | 26,0 | 36,2 |
DeepSeek V3.2 Speciale ist im Wesentlichen eine rechenintensive, für Reasoning optimierte Variante im Vergleich zu sowohl DeepSeek V3.2 Standard als auch MiniMax-M2.1: Sie übertrifft sie tendenziell bei mathelastigen und tiefgehenden Reasoning-Benchmarks wie AIME 2025, GPQA und reasoning-intensiven Coding-Bewertungen wie LiveCodeBench, wodurch sie besser für schwierige algorithmische Probleme und wettbewerbsorientierte Aufgaben geeignet ist.
| Metrik-Kategorie | MiniMax-M2.1 | DeepSeek V3.2 Speciale |
|---|---|---|
| Intelligenzindex (allgemeines Reasoning) | 39,5 | 34,1 |
| Coding-Index | 32,8 | 37,9 |
| Mathe-Index | 82,7 | 96,7 |
| GPQA (Reasoning auf Hochschulniveau) | 83,0 % | 87,1 % |
| MMLU Pro (fortgeschrittenes Wissen) | 87,5 % | 86,3 % |
| HLE (harte Sprachbewertung) | 22,2 % | 26,1 % |
| LiveCodeBench (realweltliches Coding) | 81,0 % | 89,6 % |
| AIME 2025 (fortgeschrittene Mathematik) | 82,7 % | 96,7 % |
| SciCode (wissenschaftlicher Code) | 40,7 % | 44,0 % |
| LCR (Code-Review) | 59,0 % | 59,3 % |
| IFBench (Befolgung von Anweisungen) | 69,9 % | 63,9 % |
| TerminalBench Hard (CLI-Befehlsgenerierung) | 28,8 % | 34,8 % |
Die Stärke von DeepSeek V3.2 liegt in seiner hohen Leistungsfähigkeit für großskaliges Reasoning, komplexe logische Schlussfolgerungen und starkes allgemeines Sprachverständnis.
MiniMax-M2.1 konzentriert sich stärker auf Codequalität, Anpassung an Engineering-Aufgaben und die Verarbeitung langer Konversationskontexte und erzielt in der Regel höhere Werte bei softwareentwicklungsorientierten Benchmarks.
Probieren Sie jetzt coole Modelle aus!
VRAM-Anforderungen von Minimax M2.1 und DeepSeek V3.2
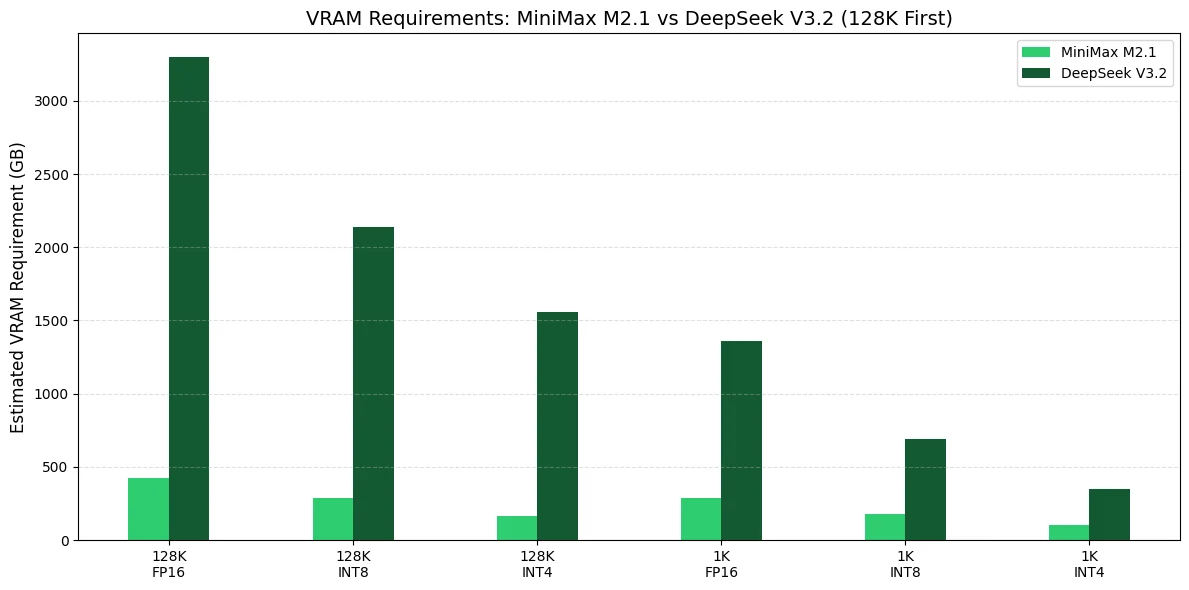
Für Ihre eigene Agenten-Produktionsumgebung empfehle ich sehr unterschiedliche GPU-Strategien für MiniMax M2.1 im Vergleich zu DeepSeek V3.2, da ihre VRAM-Auslastung auf völlig unterschiedlichen Skalen liegt.
Empfohlene GPU für MiniMax M2.1
Beste praktische Wahl: 4× H100 80GB (oder 4× H200 141GB, wenn das Budget es zulässt)
- Stabil für lange, mehrstufige Tool-Aufruf-Workflows
- Genügend VRAM-Spielraum für größere Kontexte + KV-Cache
- Guter Durchsatz und Zuverlässigkeit für SWE-bench-ähnliche Agenten-Pipelines
Kosteneffiziente Alternative: 4× L40S 48GB (INT4/INT8 quantisiert)
- Gut für persönliche Bereitstellung
- Viel günstiger als H100
- Immer noch realistisch für Agenten-Workflows
Nicht empfohlen, es sei denn, das Budget ist knapp: 8× RTX 4090 24GB
- Kann funktionieren, aber PCIe-Engpässe und Multi-GPU-Kommunikation beeinträchtigen die Agenten-Latenz.
Fazit: MiniMax M2.1 ist der klare Gewinner, wenn Sie ein realistisches „persönliches Produktions-Agenten“-Modell wünschen.
Empfohlene GPU für DeepSeek V3.2
Minimale realistische Konfiguration: 16× H100 80GB (INT4/INT8)
- DeepSeek V3.2 erfordert massive VRAM selbst bei Quantisierung
- Tool-Aufruf-Agenten sind kontinuierlich teuer zu betreiben
Realistischere Produktionskonfiguration: 32× H100 80GB (oder 16× H200 141GB)
- Erforderlich, wenn Sie langen Kontext (128K) ohne ständigen Speicherdruck wünschen
- Bessere Stabilität und Durchsatz
Fazit: DeepSeek V3.2 ist eher ein Datenzentrumsmodell. Es ist nicht kosteneffizient für die persönliche Agentenproduktion, es sei denn, Sie verfügen bereits über einen GPU-Cluster.
Wenn Ihr Ziel ein stabiles, skalierbares Coding-Agenten-System ist, wählen Sie:
MiniMax M2.1 + 4× H100 80GB (beste Balance aus Leistung, Kontext und Bereitstellungsmöglichkeit).
On-Demand ist ein Pay-as-you-go-Modell, das ausschließlich nach Laufzeit abgerechnet wird und maximale Flexibilität für variable Workloads und Experimente bietet, da Sie nur zahlen, während die GPU läuft.
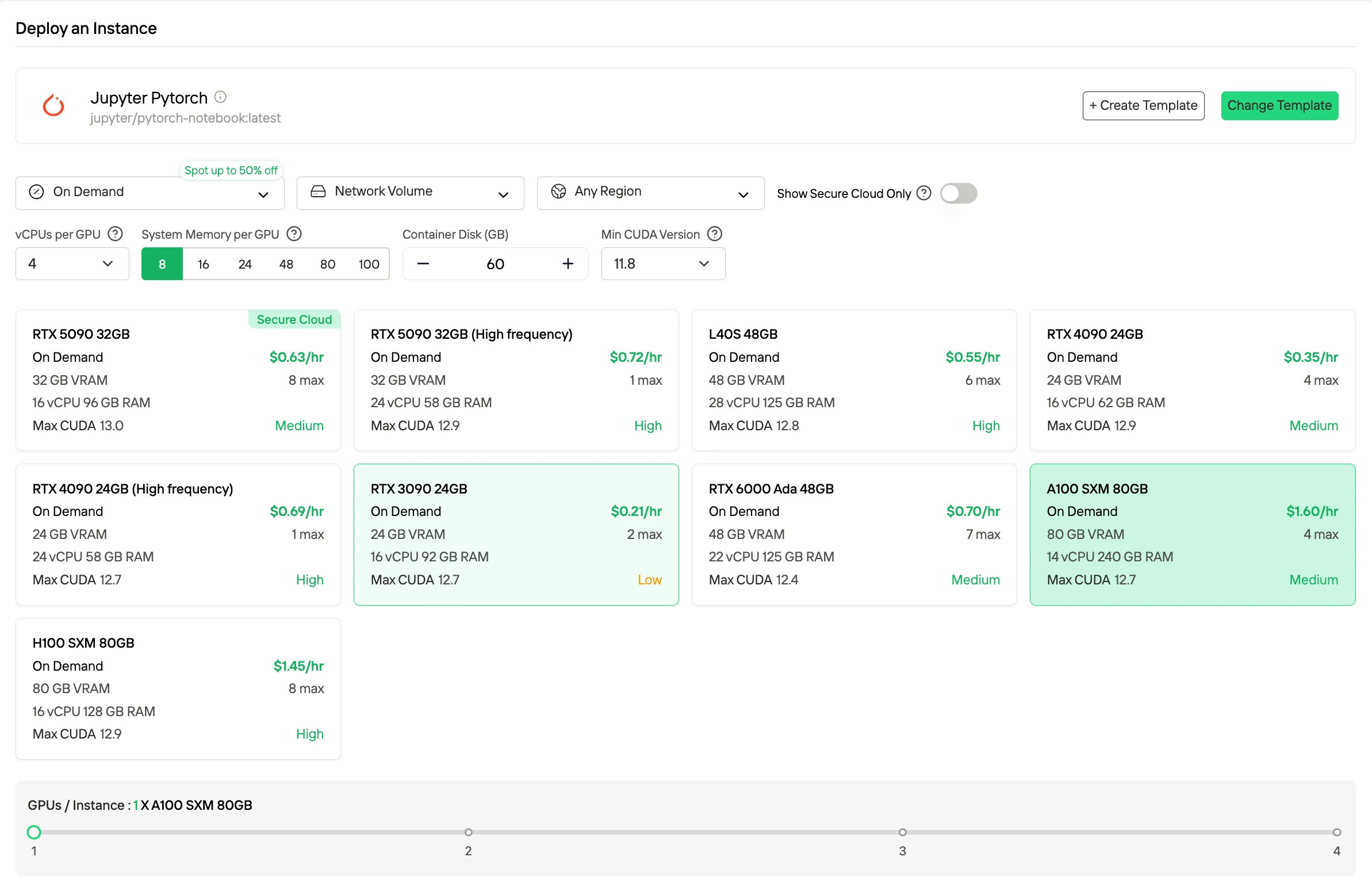
Probieren Sie jetzt schnelle und günstige GPUs aus!
Wenn Sie niedrigere Kosten wünschen, sind Spot-Instances in der Regel um bis zu 50 % günstiger, da sie ungenutzte Kapazitäten nutzen. Sie können jedoch unterbrochen werden, sodass sie sich am besten für fehlertolerante oder Batch-Workloads eignen.
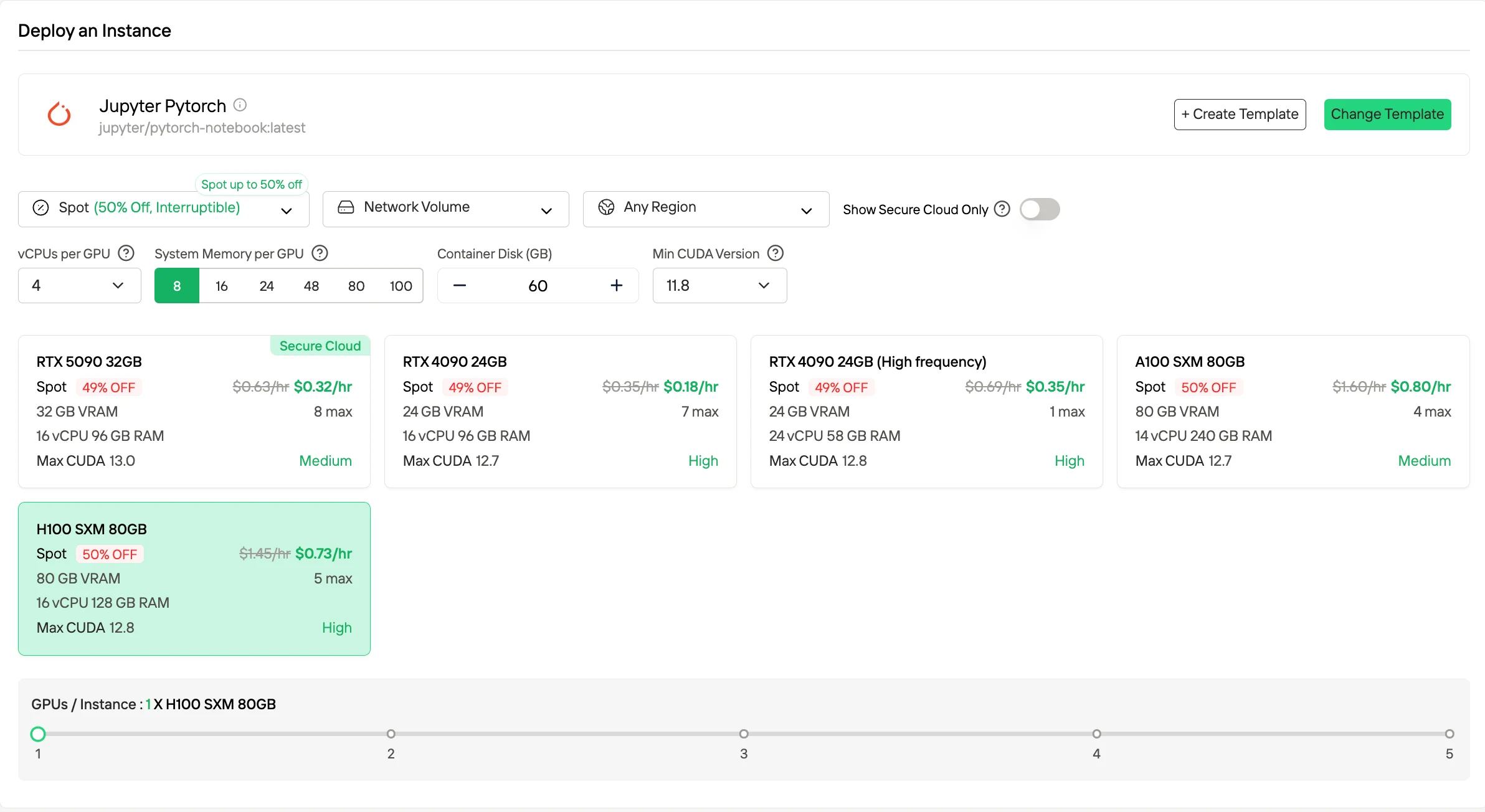
Probieren Sie jetzt schnelle und günstige GPUs aus!
Kostenanalyse von Minimax M2.1 und DeepSeek V3.2
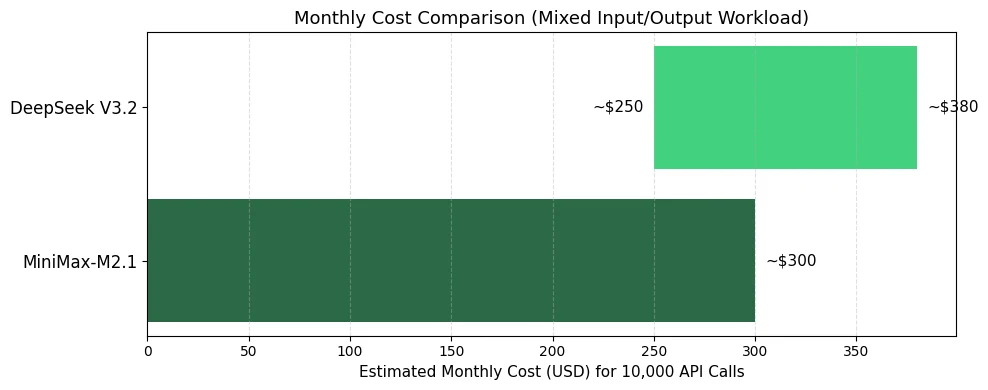
- Wählen Sie MiniMax-M2.1 für: Workloads mit hohem Output-to-Input-Verhältnis, Agentenaufgaben mit Tool-Aufrufen, Anwendungen, die niedrigere gesamte gemischte Kosten erfordern
- Wählen Sie DeepSeek V3.2 für: Input-lastige Workloads (z. B. Dokumentenanalyse), spezialisierte Reasoning-Aufgaben, bei denen die Qualität leicht höhere Kosten rechtfertigt
Zugriff auf Minimax M2.1 und DeepSeek V3.2
Option 1: Schnelle API
Schritt 1: Melden Sie sich an und greifen Sie auf die Modellbibliothek zu
Melden Sie sich bei Ihrem Konto an und klicken Sie auf die Schaltfläche Modellbibliothek.

Schritt 2: Wählen Sie Ihr Modell
Durchsuchen Sie die verfügbaren Optionen und wählen Sie das Modell, das Ihren Anforderungen entspricht.

Probieren Sie jetzt coole Modelle aus!
Schritt 3: Starten Sie Ihre kostenlose Testversion
Starten Sie Ihre kostenlose Testversion, um die Funktionen des ausgewählten Modells zu erkunden.
Schritt 4: Holen Sie sich Ihren API-Schlüssel
Zur Authentifizierung bei der API stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Auf der Seite „Einstellungen“ können Sie den API-Schlüssel wie in der Abbildung gezeigt kopieren.

from openai import OpenAI
client = OpenAI(
api_key="<Ihr API-Schlüssel>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="minimax/minimax-m2.1",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
Option 2: Multi-Agenten-Workflows mit dem OpenAI Agents SDK
Erstellen Sie fortschrittliche Multi-Agenten-Systeme, indem Sie Novita AI mit dem OpenAI Agents SDK integrieren:
- Plug-and-Play: Nutzen Sie die LLMs von Novita AI in jedem OpenAI Agents-Workflow.
- Unterstützt Übergaben, Routing und Tool-Nutzung: Entwerfen Sie Agenten, die delegieren, triagieren oder Funktionen ausführen können, alle angetrieben von den Modellen von Novita AI.
- Python-Integration: Zeigen Sie den SDK einfach auf den Endpunkt von Novita (
https://api.novita.ai/v3/openai) und verwenden Sie Ihren API-Schlüssel.
Option 3: Verbinden Sie die GLM 4.7 Flash API auf Drittanbieterplattformen
- Hugging Face: Nutzen Sie GLM 4.7 und MiniMax M2.1 in Spaces, Pipelines oder mit der Transformers-Bibliothek über Novita AI-Endpunkte.
- Agenten- und Orchestrierungs-Frameworks: Verbinden Sie Novita AI einfach mit Partnerplattformen wie Continue, AnythingLLM,LangChain, Dify und Langflow über offizielle Konnektoren und schrittweise Integrationsanleitungen.
- OpenAI-kompatible API: Verbinden Sie Novita AI einfach mit Partnerplattformen wie Claude code, Cursor, Trae, Continue, Codex, OpenCode, AnythingLLM, LangChain, Dify und Langflow über offizielle Konnektoren und schrittweise Integrationsanleitungen.
Für autonome Agenten, mehrsprachiges Coding und kostensensitive Produktion wählen Sie MiniMax-M2.1. Für wissenschaftliches Reasoning, wettbewerbsorientiertes Programmieren oder spezialisierte mathematische Aufgaben wählen Sie die passende DeepSeek V3.2-Variante: Standard für ausgewogenen täglichen Einsatz, Speciale für maximales Reasoning, Thinking für Chain-of-Thought-Problemlösung oder Exp für Langkontext-Forschung.
Häufig gestellte Fragen
Welches Modell ist besser für autonome Coding-Agenten, MiniMax-M2.1 oder DeepSeek V3.2?
MiniMax-M2.1 ist in der Regel besser als DeepSeek V3.2 für Tool-Aufruf-Coding-Agenten und mehrstufige SWE-bench-Workflows.
Welches Modell ist stärker für Mathematik und Reasoning auf Wettbewerbsniveau, MiniMax-M2.1 oder DeepSeek V3.2?
DeepSeek V3.2 Speciale ist stärker als MiniMax-M2.1 für AIME-ähnliche Mathematik und tiefgehende Reasoning-Benchmarks.
Welches ist einfacher für die persönliche Produktion bereitzustellen, MiniMax-M2.1 oder DeepSeek V3.2?
MiniMax-M2.1 ist weitaus einfacher bereitzustellen als DeepSeek V3.2 und erfordert viel kleinere GPU-Cluster.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud zum Erstellen und Skalieren bereitstellt.



