

Lors de la création d’applications IA autonomes en 2026, le choix entre MiniMax-M2.1 et DeepSeek V3.2 se résume souvent à un compromis critique : polyvalence agentique contre puissance de raisonnement brute.
Cette comparaison dissèque les différences architecturales, les performances sur l’ensemble des benchmarks, les exigences matérielles (des RTX 4090 aux clusters H100), les structures tarifaires et les compromis de déploiement concrets. Que vous construisiez des agents de codage autonomes, des systèmes de raisonnement scientifique ou des API de production sensibles aux coûts, comprendre quelle famille de modèles correspond à votre cas d’usage peut vous faire économiser des milliers en coûts de calcul et des semaines de travail d’intégration.
Réponse rapide : Quel modèle devez-vous choisir ?
Choisissez MiniMax-M2.1 si vous avez besoin de :
- Agents de codage autonomes avec une fiabilité élevée d’appel d’outils (workflows agentiques, pipelines SWE-bench)
- Exécution multi-étapes stable dans des frameworks comme Droid / mini-swe-agent
- Ingénierie multilingue (Python, Java, C++, Rust, Kotlin)
- Efficacité élevée pour les charges de travail à forte production de sortie pour la génération de code longue et les correctifs itératifs
- Déploiement GPU plus pratique (réaliste sur 4× H100 80Go ou 4× L40S 48Go)
Choisissez DeepSeek V3.2 (ou Speciale) si vous avez besoin de :
- Puissance de raisonnement profond pour des inférences logiques complexes et des tâches lourdes en analyse
- Performances mathématiques / de niveau compétition (Speciale domine AIME 2025, GPQA, les benchmarks de raisonnement)
- Codage lourd en raisonnement (tâches algorithmiques de style LiveCodeBench et tâches de programmation difficiles)
- Charges de travail à forte entrée comme l’analyse de documents longs et le raisonnement sur les connaissances
- Déploiement à l’échelle de datacenter (nécessite souvent 16× ou plus de GPU de classe H100 même avec quantification)
Essayez des modèles cool maintenant !
Architecture de Minimax M2.1 et Deepseek V3.2
| Spécification | MiniMax-M2.1 | DeepSeek V3.2 (Toutes variantes) |
|---|---|---|
| Nombre total de paramètres | 228.7B | 685B |
| Paramètres actifs (par jeton) | 10B | 37B |
| Longueur de contexte | 128K à 204.8K jetons | 128K jetons |
| Précision | FP8 | FP8/BF16/F32 |
| Support multimodal | Texte, audio, images, vidéo | Texte uniquement |
| Date de sortie | 23 décembre 2025 | Décembre 2025 |
Décomposition des variantes de DeepSeek V3.2
- Les variantes Deepseek V3.2 Standard et Thinking sont les mêmes poids de modèle de base. La différence réside dans la façon dont le modèle est exécuté : l’une privilégie un équilibre de raisonnement par défaut, l’autre active un raisonnement étendu explicite avant la sortie.
- Deepseek V3.2 Speciale est une variante distincte optimisée pour une puissance de raisonnement maximale, mais au détriment de l’intégration d’outils et des capacités agentiques typiques, remportant les médailles d’or IMO/CMO/ICPC/IOI 2025 !
- Deepseek V3.2 Exp est une branche expérimentale conçue pour explorer de nouvelles efficacités architecturales (attention éparse) et n’est pas strictement identique à l’entraînement principal de V3.2.
Comparaison des benchmarks de Minimax M2.1 et Deepseek V3.2
DeepSeek V3.2 (Standard) est généralement compétitif avec MiniMax-M2.1 sur des tâches de codage de style SWE-bench réelles, mais MiniMax-M2.1 tend à montrer une robustesse globale plus forte sur l’ingénierie logicielle multilingue et les frameworks agentiques.
En pratique, DeepSeek V3.2 est un modèle de codage général et agentique solide, mais MiniMax-M2.1 est généralement mieux optimisé pour l’exécution d’ingénierie de bout en bout, la généralisation aux frameworks et la fiabilité d’utilisation d’outils dans des pipelines de codage multi-étapes complexes.
| Benchmark | MiniMax M2.1 | DeepSeek V3.2 | Claude Opus 4.5 | Notes |
|---|---|---|---|---|
| SWE-bench Vérifié | 74.0 | 73.1 | 80.9 | Résolution de problèmes GitHub réels |
| Multi-SWE-bench | 49.4 | 37.4 | 50.0 | MiniMax surpasse Claude Sonnet 4.5 (44.3) |
| SWE-bench Multilingue | 72.5 | 70.2 | 77.5 | Python, Java, C++, Rust, Kotlin |
| Terminal-bench 2.0 | 47.9 | 46.4 | 57.8 | Scripting CLI et shell |
| Framework/Benchmark | MiniMax-M2.1 | DeepSeek V3.2 | Claude Opus 4.5 |
|---|---|---|---|
| SWE-bench Vérifié (Droid) | 71.3 | 67.0 | 75.2 |
| SWE-bench Vérifié (mini-swe-agent) | 67.0 | 60.0 | 74.4 |
| SWT-bench (Génération de tests) | 69.3 | 62.0 | 80.2 |
| SWE-Review (Revue de code) | 8.9 | 6.4 | 16.2 |
| OctoCodingbench | 26.1 | 26.0 | 36.2 |
DeepSeek V3.2 Speciale est essentiellement une variante optimisée pour le raisonnement à haut calcul par rapport à DeepSeek V3.2 Standard et MiniMax-M2.1 : elle a tendance à les surpasser sur les benchmarks lourds en mathématiques et en raisonnement profond tels que AIME 2025, GPQA et les évaluations de codage intensives en raisonnement comme LiveCodeBench, ce qui la rend mieux adaptée aux problèmes algorithmiques difficiles et aux tâches de style compétition.
| Catégorie de métrique | MiniMax-M2.1 | DeepSeek V3.2 Speciale |
|---|---|---|
| Indice d’intelligence (raisonnement global) | 39.5 | 34.1 |
| Indice de codage | 32.8 | 37.9 |
| Indice de mathématiques | 82.7 | 96.7 |
| GPQA (raisonnement de niveau universitaire supérieur) | 83.0 % | 87.1 % |
| MMLU Pro (connaissances avancées) | 87.5 % | 86.3 % |
| HLE (évaluation linguistique difficile) | 22.2 % | 26.1 % |
| LiveCodeBench (codage réel) | 81.0 % | 89.6 % |
| AIME 2025 (mathématiques avancées) | 82.7 % | 96.7 % |
| SciCode (code scientifique) | 40.7 % | 44.0 % |
| LCR (revue de code) | 59.0 % | 59.3 % |
| IFBench (respect des instructions) | 69.9 % | 63.9 % |
| TerminalBench Hard (génération de commandes CLI) | 28.8 % | 34.8 % |
Les points forts de DeepSeek V3.2 résident dans sa capacité élevée pour le raisonnement à grande échelle, l’inférence logique complexe et une compréhension générale du langage forte.
MiniMax-M2.1 se concentre davantage sur la qualité du code, l’adaptation aux tâches d’ingénierie et la gestion de longs contextes conversationnels, et obtient généralement des scores plus élevés sur les benchmarks orientés développement logiciel.
Essayez des modèles cool maintenant !
Exigences VRAM de Minimax M2.1 et Deepseek V3.2
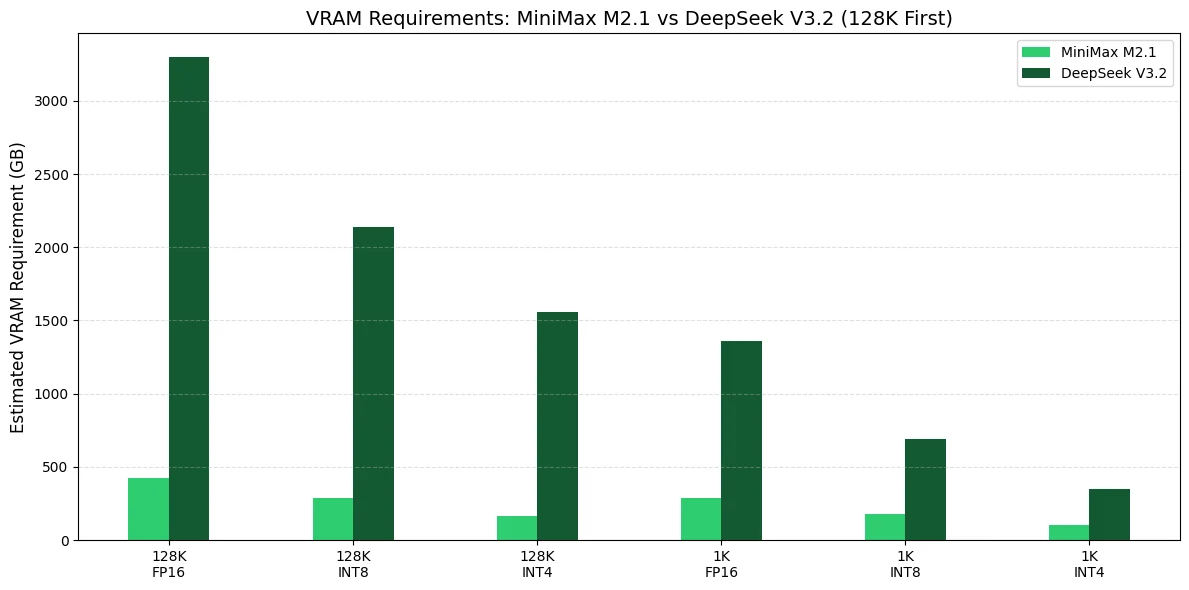
Pour votre propre configuration de production agentique, je recommanderais des stratégies GPU très différentes pour MiniMax M2.1 par rapport à DeepSeek V3.2, car leurs empreintes VRAM sont à des échelles complètement différentes.
GPU recommandé pour MiniMax M2.1
Meilleur choix pratique : 4× H100 80Go (ou 4× H200 141Go si le budget le permet)
- Stable pour des workflows d’appel d’outils multi-étapes longs
- Assez de marge VRAM pour des contextes plus grands + cache KV
- Bon débit et fiabilité pour les pipelines agentiques de style SWE-bench
Alternative économique : 4× L40S 48Go (quantifié INT4/INT8)
- Idéal pour un déploiement personnel
- Beaucoup moins cher que le H100
- Toujours réaliste pour des workflows agentiques
Non recommandé sauf si le budget est serré : 8× RTX 4090 24Go
- Peut fonctionner, mais les goulots d’étranglement PCIe et la communication multi-GPU dégraderont la latence des agents.
Conclusion : MiniMax M2.1 est le gagnant évident si vous voulez un modèle « agent de production personnel » réaliste.
GPU recommandé pour DeepSeek V3.2
Configuration réaliste minimale : 16× H100 80Go (INT4/INT8)
- DeepSeek V3.2 nécessite une VRAM massive même avec quantification
- Les agents avec appel d’outils seront coûteux à exécuter en continu
Configuration de production plus réaliste : 32× H100 80Go (ou 16× H200 141Go)
- Nécessaire si vous voulez un contexte long (128K) sans pression mémoire constante
- Meilleure stabilité et débit
Conclusion : DeepSeek V3.2 est davantage un modèle de datacenter. Il n’est pas rentable pour une production agentique personnelle à moins que vous ne disposiez déjà d’un cluster GPU.
Si votre objectif est un système d’agent de codage stable et évolutif, optez pour :
MiniMax M2.1 + 4× H100 80Go (meilleur équilibre entre performance, contexte et faisabilité de déploiement).
On-Demand est un modèle de facturation à l’usage, facturé strictement selon le temps d’exécution, offrant une flexibilité maximale pour des charges de travail variables et des expérimentations puisque vous ne payez que pendant que le GPU est en cours d’exécution.
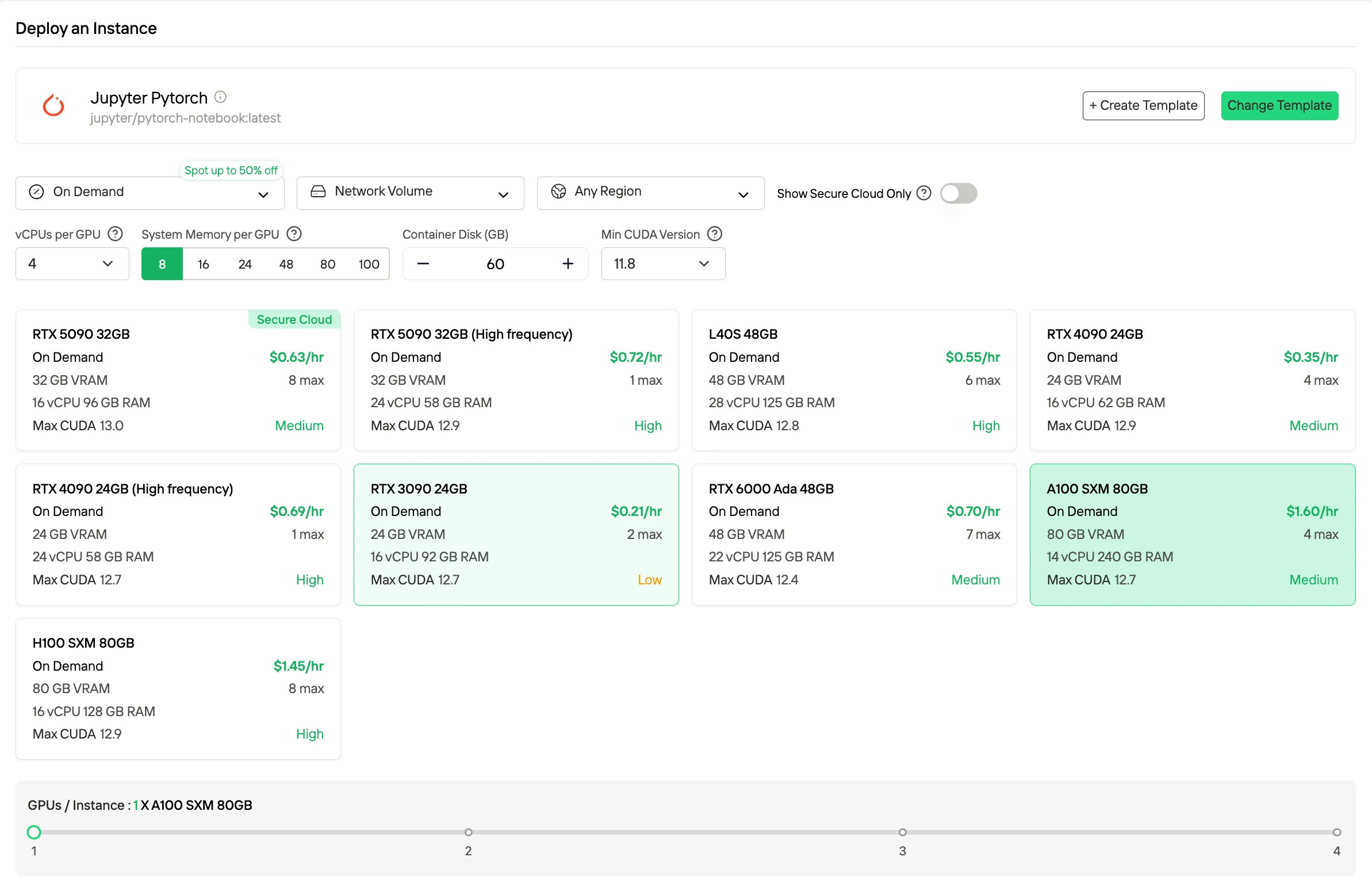
Essayez des GPU rapides et bon marché maintenant !
Si vous voulez réduire les coûts, les instances Spot sont généralement jusqu’à 50 % moins chères en utilisant la capacité inutilisée, mais elles peuvent être interrompues, donc elles sont idéales pour des charges de travail tolérantes aux pannes ou par lots.
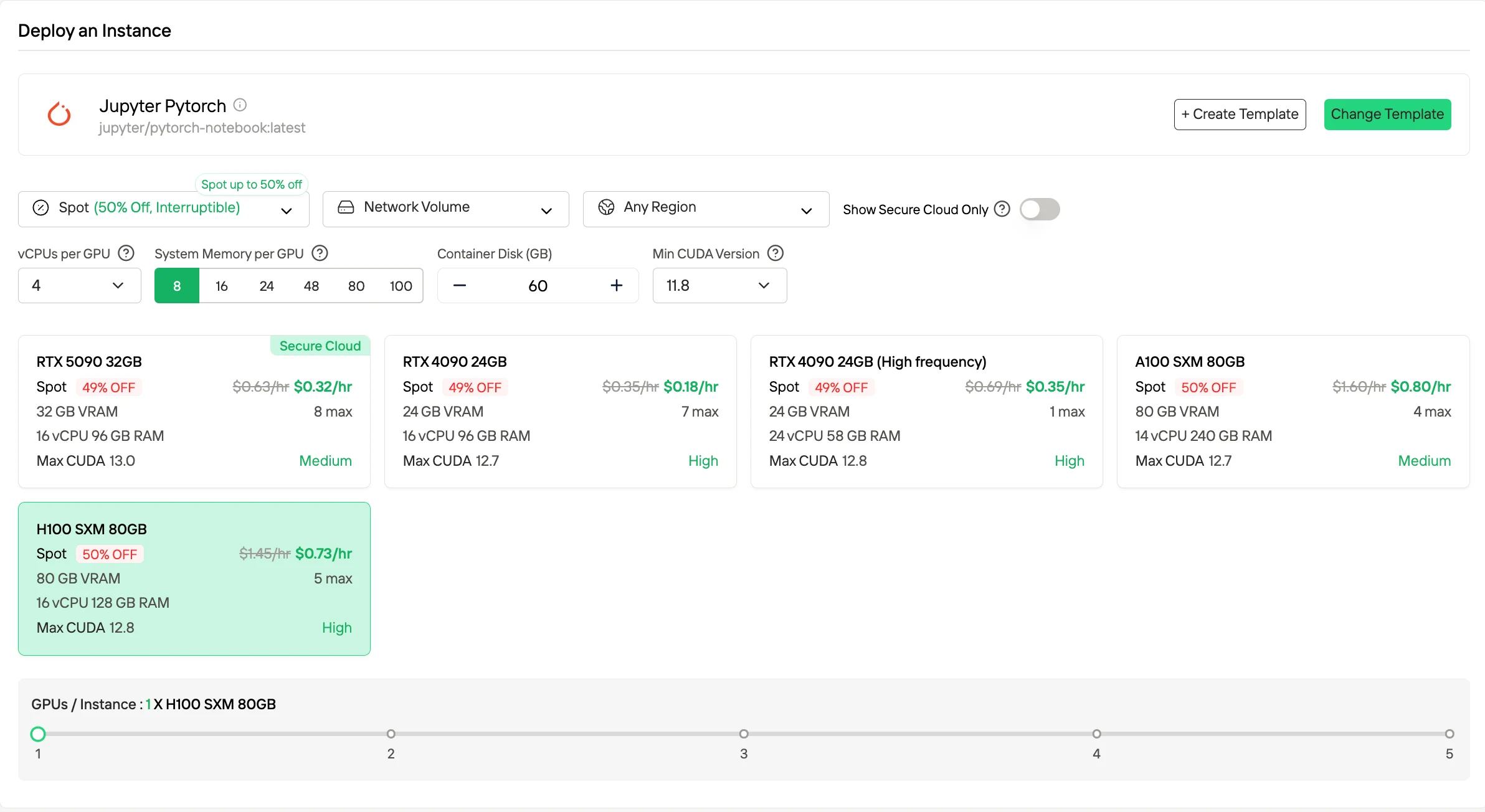
Essayez des GPU rapides et bon marché maintenant !
Analyse des coûts de Minimax M2.1 et Deepseek V3.2
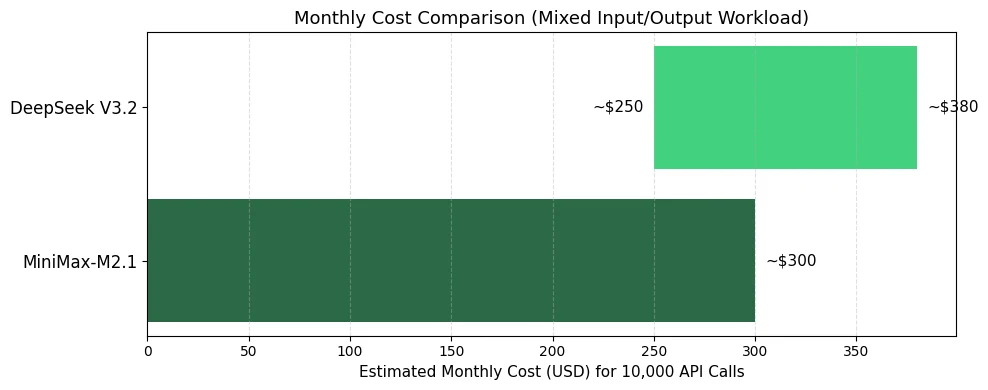
- Choisissez MiniMax-M2.1 pour : Des charges de travail avec un ratio sortie/entrée élevé, des tâches agentiques avec appel d’outils, des applications nécessitant des coûts combinés plus bas
- Choisissez DeepSeek V3.2 pour : Des charges de travail à forte entrée (par exemple, analyse de documents), des tâches de raisonnement spécialisées où la qualité justifie des coûts légèrement plus élevés
Comment accéder à Minimax M2.1 et Deepseek V3.2
Option 1 : API rapide
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Bibliothèque de modèles.

Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.

Essayez des modèles cool maintenant !
Étape 3 : Commencez votre essai gratuit
Commencez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Étape 4 : Récupérez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. En vous rendant sur la page « Paramètres », vous pouvez copier la clé API comme indiqué sur l’image.

from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="minimax/minimax-m2.1",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
Option 2 : Workflows multi-agents avec le SDK OpenAI Agents
Construisez des systèmes multi-agents avancés en intégrant Novita AI avec le SDK OpenAI Agents :
- Prêt à l’emploi : Utilisez les LLM de Novita AI dans n’importe quel workflow OpenAI Agents.
- Prend en charge les transferts, le routage et l’utilisation d’outils : Concevez des agents qui peuvent déléguer, trier ou exécuter des fonctions, le tout alimenté par les modèles de Novita AI.
- Intégration Python : Il suffit de pointer le SDK vers le point de terminaison de Novita (
https://api.novita.ai/v3/openai) et d’utiliser votre clé API.
Option 3 : Connectez l’API GLM 4.7 Flash sur des plateformes tierces
- Hugging Face : Utilisez GLM 4.7 et MiniMax M2.1 dans des Spaces, des pipelines ou avec la bibliothèque Transformers via les points de terminaison Novita AI.
- Frameworks d’agents et d’orchestration : Connectez facilement Novita AI à des plateformes partenaires comme Continue, AnythingLLM,LangChain, Dify et Langflow via des connecteurs officiels et des guides d’intégration étape par étape.
- API compatible OpenAI : Connectez facilement Novita AI à des plateformes partenaires comme Claude code,Cursor,Trae,Continue, Codex, OpenCode, AnythingLLM,LangChain, Dify et Langflow via des connecteurs officiels et des guides d’intégration étape par étape.
Pour des agents autonomes, du codage multilingue et une production sensible aux coûts, choisissez MiniMax-M2.1. Pour le raisonnement scientifique, la programmation compétitive ou des tâches mathématiques spécialisées, sélectionnez la variante DeepSeek V3.2 appropriée : Standard pour un usage quotidien équilibré, Speciale pour un raisonnement maximal, Thinking pour la résolution de problèmes par chaîne de pensée, ou Exp pour la recherche sur contexte long.
Foire aux questions
Quel modèle est meilleur pour les agents de codage autonomes, MiniMax-M2.1 ou DeepSeek V3.2 ? MiniMax-M2.1 est généralement meilleur que DeepSeek V3.2 pour les agents de codage avec appel d’outils et les workflows SWE-bench multi-étapes.
Quel modèle est plus fort pour les mathématiques et le raisonnement de niveau compétition, MiniMax-M2.1 ou DeepSeek V3.2 ? DeepSeek V3.2 Speciale est plus fort que MiniMax-M2.1 pour les mathématiques de style AIME et les benchmarks de raisonnement profond.
Lequel est plus facile à déployer pour une production personnelle, MiniMax-M2.1 ou DeepSeek V3.2 ? MiniMax-M2.1 est bien plus facile à déployer que DeepSeek V3.2, nécessitant des clusters GPU beaucoup plus petits.
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles IA via notre API simple, tout en fournissant un cloud GPU abordable et fiable pour construire et mettre à l’échelle.



