

При создании автономных ИИ-приложений в 2026 году выбор между MiniMax-M2.1 и DeepSeek V3.2 часто сводится к ключевому компромиссу: универсальности агентных возможностей против сырой мощности рассуждений.
В этом сравнении мы разбираем архитектурные различия, результаты бенчмарков для всех вариантов моделей, требования к оборудованию (от отдельных RTX 4090 до кластеров H100), структуры тарификации и компромиссы при развертывании в реальных условиях. Независимо от того, создаете ли вы автономные кодирующие агенты, системы научных рассуждений или экономичные производственные API, понимание того, какое семейство моделей подходит для вашего сценария использования, может сэкономить тысячи долларов на вычислительных затратах и недели работы по интеграции.
Краткий ответ: какую модель стоит выбрать?
Выбирайте MiniMax-M2.1, если вам нужны:
- Автономные кодирующие агенты с высокой надежностью вызова инструментов (агентные рабочие процессы, конвейеры SWE-bench)
- Стабильное многошаговое выполнение в таких фреймворках, как Droid / mini-swe-agent
- Многоязычная инженерная работа (Python, Java, C++, Rust, Kotlin)
- Более высокая эффективность при большой доле выходных данных для длительной генерации кода и итеративного исправления
- Более практичное развертывание на GPU (реализуется на 4× H100 80GB или 4× L40S 48GB)
Выбирайте DeepSeek V3.2 (или Speciale), если вам нужны:
- Глубокие возможности рассуждений для сложных логических выводов и задач, требующих большого объема анализа
- Производительность в математике / на уровне соревнований (Speciale лидирует в AIME 2025, GPQA и бенчмарках рассуждений)
- Кодирование с упором на рассуждения (алгоритмические и сложные программистские задачи в стиле LiveCodeBench)
- Нагрузки с большой долей входных данных, такие как анализ длинных документов и рассуждения на основе знаний
- Развертывание в масштабах дата-центра (часто требует 16 и более GPU класса H100 даже с квантованием)
Архитектура MiniMax M2.1 и DeepSeek V3.2
| Specification | MiniMax-M2.1 | DeepSeek V3.2 (All Variants) |
|---|---|---|
| Total Parameters | 228.7B | 685B |
| Active Parameters (per token) | 10B | 37B |
| Context Length | 128K-204.8K tokens | 128K tokens |
| Precision | FP8 | FP8/BF16/F32 |
| Multimodal Support | Text, audio, images, video | Text only |
| Release Date | December 23, 2025 | December 2025 |
Разбор вариантов DeepSeek V3.2
- Deepseek V3.2 Standard и Thinking используют одни и те же базовые веса модели. Разница в способе запуска: первый вариант использует стандартный баланс рассуждений, второй включает явное расширенное рассуждение перед выводом результата.
- Deepseek V3.2 Speciale — отдельный вариант, настроенный для максимальной мощности рассуждений, но за счет интеграции инструментов и стандартных агентных возможностей, он получил золотые медали на IMO/CMO/ICPC/IOI 2025 года!
- Deepseek V3.2 Exp — экспериментальная ветвь, созданная для исследования новых архитектурных оптимизаций (разреженное внимание), и она не является полностью идентичной основной версии V3.2 по обучению.
Сравнение бенчмарков MiniMax M2.1 и DeepSeek V3.2
DeepSeek V3.2 (Standard) в целом конкурирует с MiniMax-M2.1 на реальных задачах по кодированию в стиле SWE-bench, но MiniMax-M2.1 обычно демонстрирует более высокую общую надежность в многоязычной программной инженерии и агентных фреймворках.
На практике DeepSeek V3.2 — это сильная модель для общего кодирования и агентных задач, но MiniMax-M2.1 обычно лучше оптимизирована для сквозного выполнения инженерных задач, обобщения на фреймворки и надежности использования инструментов в сложных многошаговых конвейерах кодирования.
| Benchmark | MiniMax M2.1 | DeepSeek V3.2 | Claude Opus 4.5 | Notes |
|---|---|---|---|---|
| SWE-bench Verified | 74.0 | 73.1 | 80.9 | Real-world GitHub issue resolution |
| Multi-SWE-bench | 49.4 | 37.4 | 50.0 | MiniMax outperforms Claude Sonnet 4.5 (44.3) |
| SWE-bench Multilingual | 72.5 | 70.2 | 77.5 | Python, Java, C++, Rust, Kotlin |
| Terminal-bench 2.0 | 47.9 | 46.4 | 57.8 | CLI and shell scripting |
| Framework/Benchmark | MiniMax-M2.1 | DeepSeek V3.2 | Claude Opus 4.5 |
|---|---|---|---|
| SWE-bench Verified (Droid) | 71.3 | 67.0 | 75.2 |
| SWE-bench Verified (mini-swe-agent) | 67.0 | 60.0 | 74.4 |
| SWT-bench (Test Generation) | 69.3 | 62.0 | 80.2 |
| SWE-Review (Code Review) | 8.9 | 6.4 | 16.2 |
| OctoCodingbench | 26.1 | 26.0 | 36.2 |
DeepSeek V3.2 Speciale по сути является вариантом с оптимизацией под рассуждения при высоких вычислительных затратах по сравнению с DeepSeek V3.2 Standard и MiniMax-M2.1: он обычно превосходит их на математических бенчмарках и бенчмарках глубоких рассуждений, таких как AIME 2025, GPQA, а также на оценках кодирования с высокой долей рассуждений, например LiveCodeBench, что делает его более подходящим для сложных алгоритмических задач и задач в стиле соревнований.
| Metric Category | MiniMax-M2.1 | DeepSeek V3.2 Speciale |
|---|---|---|
| Intelligence Index (overall reasoning) | 39.5 | 34.1 |
| Coding Index | 32.8 | 37.9 |
| Math Index | 82.7 | 96.7 |
| GPQA (grad-level reasoning) | 83.0 % | 87.1 % |
| MMLU Pro (advanced knowledge) | 87.5 % | 86.3 % |
| HLE (hard language evaluation) | 22.2 % | 26.1 % |
| LiveCodeBench (real-world coding) | 81.0 % | 89.6 % |
| AIME 2025 (advanced math) | 82.7 % | 96.7 % |
| SciCode (scientific code) | 40.7 % | 44.0 % |
| LCR (code review) | 59.0 % | 59.3 % |
| IFBench (instruction-following) | 69.9 % | 63.9 % |
| TerminalBench Hard (CLI command generation) | 28.8 % | 34.8 % |
Сильные стороны DeepSeek V3.2 — высокая производительность в масштабных рассуждениях, сложных логических выводах и сильное общее понимание языка.
MiniMax-M2.1 в большей степени сосредоточена на качестве кода, адаптации к инженерным задачам и обработке длинных контекстов диалогов, а также обычно набирает более высокие баллы в бенчмарках, ориентированных на разработку программного обеспечения.
Требования к VRAM для MiniMax M2.1 и DeepSeek V3.2
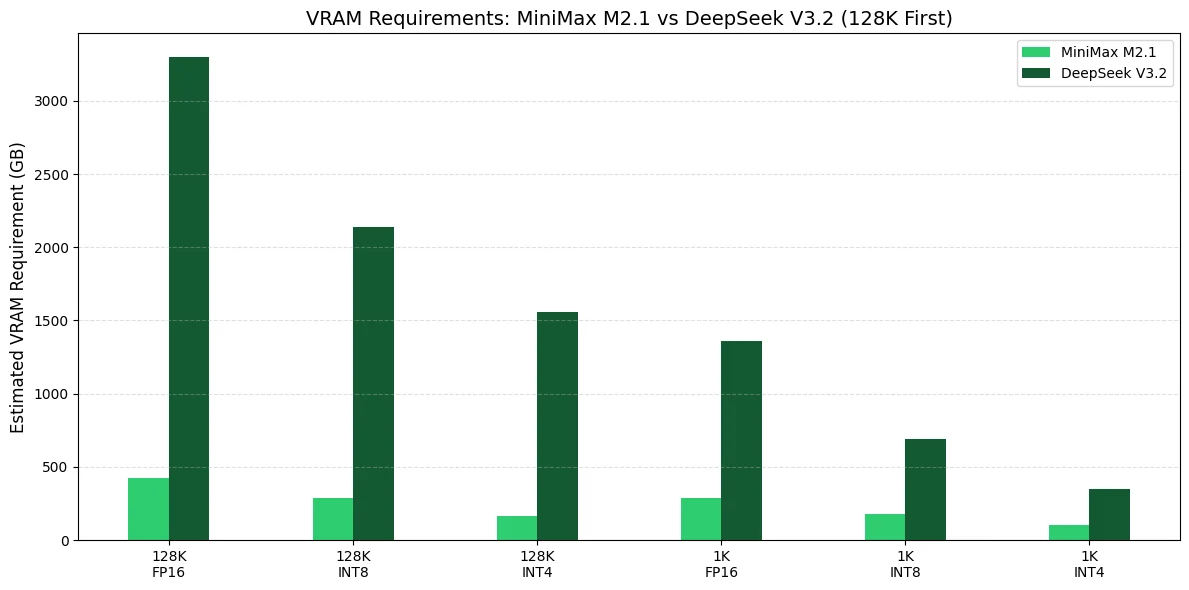
Для вашей собственной производственной настройки агентов я рекомендую совершенно разные стратегии выбора GPU для MiniMax M2.1 и DeepSeek V3.2, поскольку их требования к VRAM находятся на совершенно разных уровнях.
Рекомендуемые GPU для MiniMax M2.1
Лучший практический выбор: 4× H100 80GB (или 4× H200 141GB, если позволяет бюджет)
- Стабильность при длительных многошаговых рабочих процессах с вызовом инструментов
- Достаточный запас VRAM для больших контекстов + кэша KV
- Хорошая пропускная способность и надежность для агентных конвейеров в стиле SWE-bench
Экономичная альтернатива: 4× L40S 48GB (с квантованием INT4/INT8)
- Подходит для личного развертывания
- Значительно дешевле, чем H100
- Все еще подходит для агентных рабочих процессов
Не рекомендуется, если бюджет ограничен: 8× RTX 4090 24GB
- Может работать, но узкие места PCIe и межсоединение нескольких GPU ухудшат задержку работы агента.
Вывод: MiniMax M2.1 — явный победитель, если вы хотите реалистичную модель для «личного производственного агента».
Рекомендуемые GPU для DeepSeek V3.2
Минимальная реализуемая конфигурация: 16× H100 80GB (с квантованием INT4/INT8)
- DeepSeek V3.2 требует огромного объема VRAM даже с квантованием
- Агенты с вызовом инструментов будут дороги в постоянной эксплуатации
Более реализуемая производственная конфигурация: 32× H100 80GB (или 16× H200 141GB)
- Необходима, если вы хотите использовать длинный контекст (128K) без постоянной нехватки памяти
- Более высокая стабильность и пропускная способность
Вывод: DeepSeek V3.2 — это в большей степени модель для дата-центра. Она не является экономически эффективной для личного производства агентов, если у вас уже нет кластера GPU.
Если ваша цель — стабильная масштабируемая система кодирующих агентов, выбирайте:
MiniMax M2.1 + 4× H100 80GB (лучший баланс производительности, контекста и возможности развертывания).
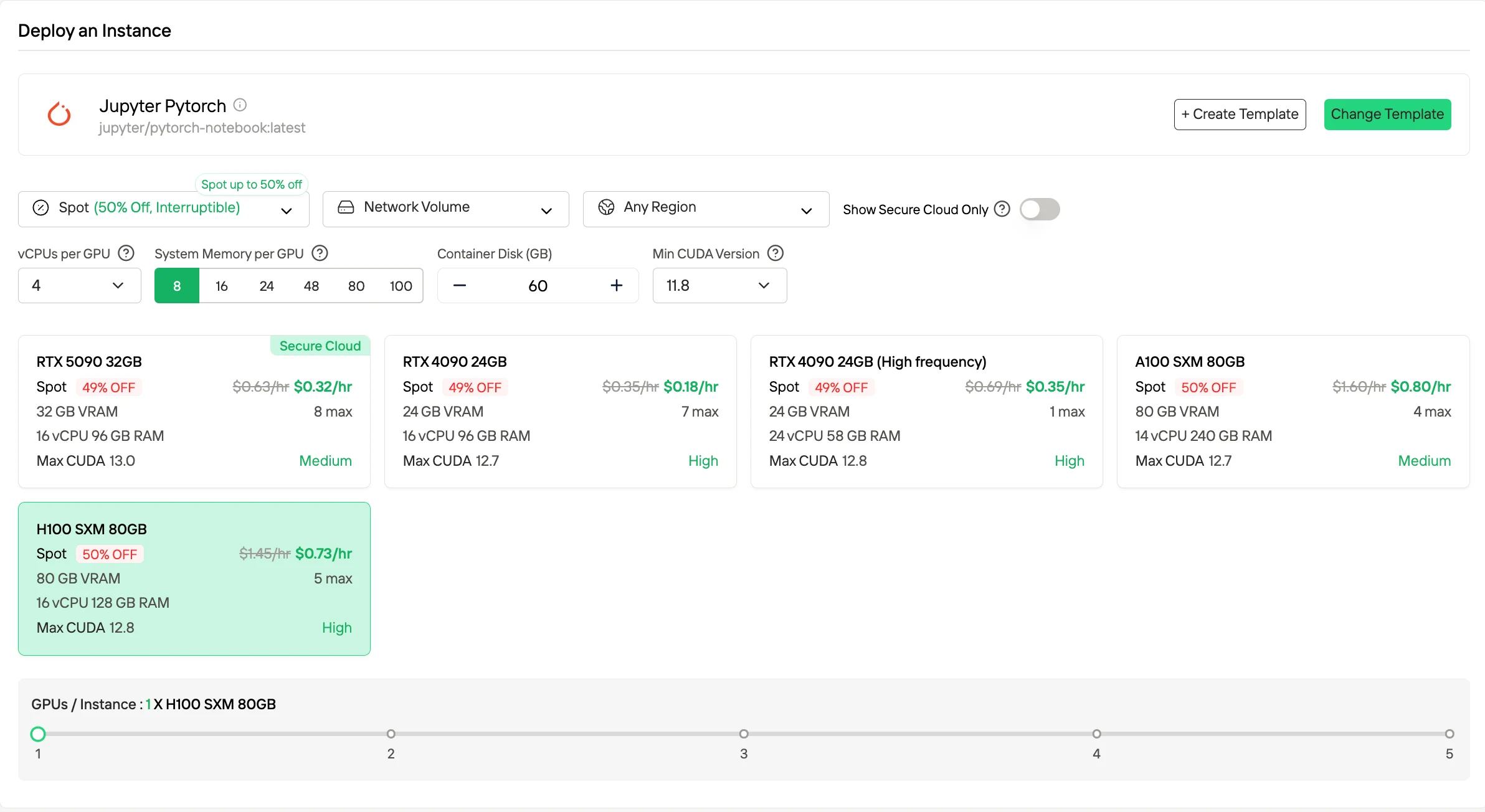
On-Demand — это модель с оплатой по факту использования, которая тарифицируется строго по времени работы, предлагает максимальную гибкость для переменных нагрузок и экспериментов, так как вы платите только тогда, когда GPU работает.
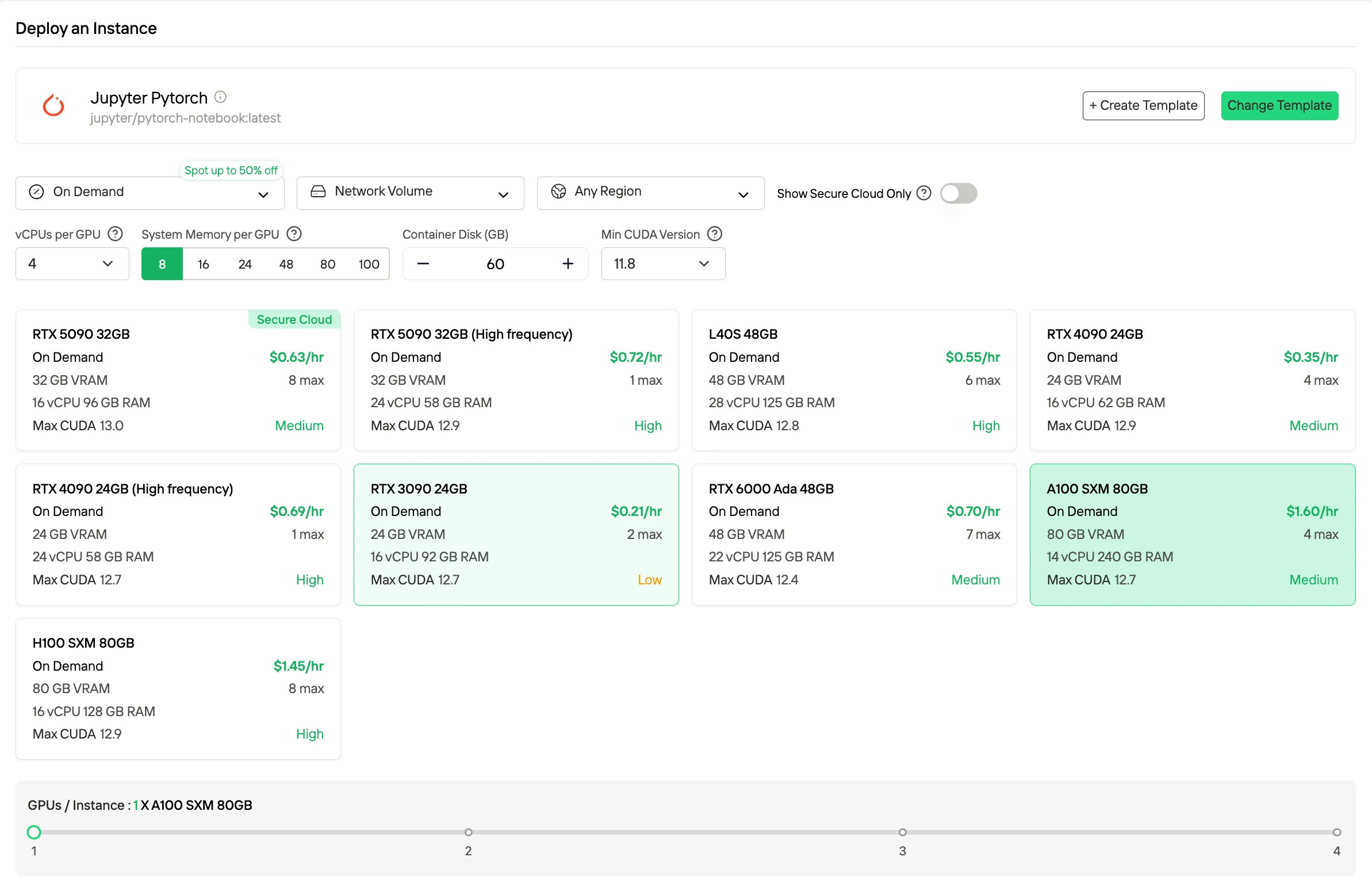
Если вы хотите снизить затраты, Spot Instances обычно на 50% дешевле за счет использования простаивающих мощностей, но их работа может быть прервана, поэтому они лучше всего подходят для отказоустойчивых или пакетных нагрузок.
Анализ стоимости MiniMax M2.1 и DeepSeek V3.2
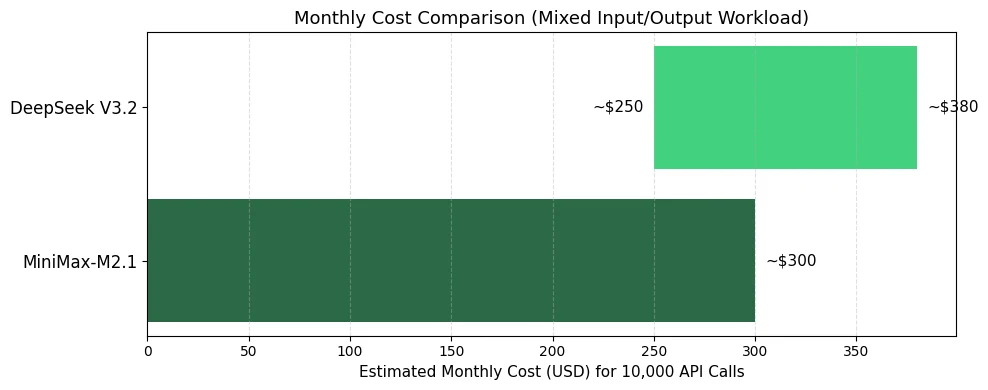
- Выбирайте MiniMax-M2.1 для: нагрузок с высоким соотношением выходных данных к входным, агентных задач с вызовом инструментов, приложений, требующих более низких общих смешанных затрат
- Выбирайте DeepSeek V3.2 для: нагрузок с большой долей входных данных (например, анализ документов), специализированных задач рассуждений, где качество оправдывает немного более высокие затраты
Как получить доступ к MiniMax M2.1 и DeepSeek V3.2
Вариант 1: Быстрый API
Шаг 1: Войдите в аккаунт и перейдите в библиотеку моделей
Войдите в свой аккаунт и нажмите кнопку Библиотека моделей.

Шаг 2: Выберите нужную модель
Просмотрите доступные варианты и выберите модель, подходящую для ваших задач.

Шаг 3: Начните бесплатный пробный период
Начните бесплатный пробный период, чтобы изучить возможности выбранной модели.
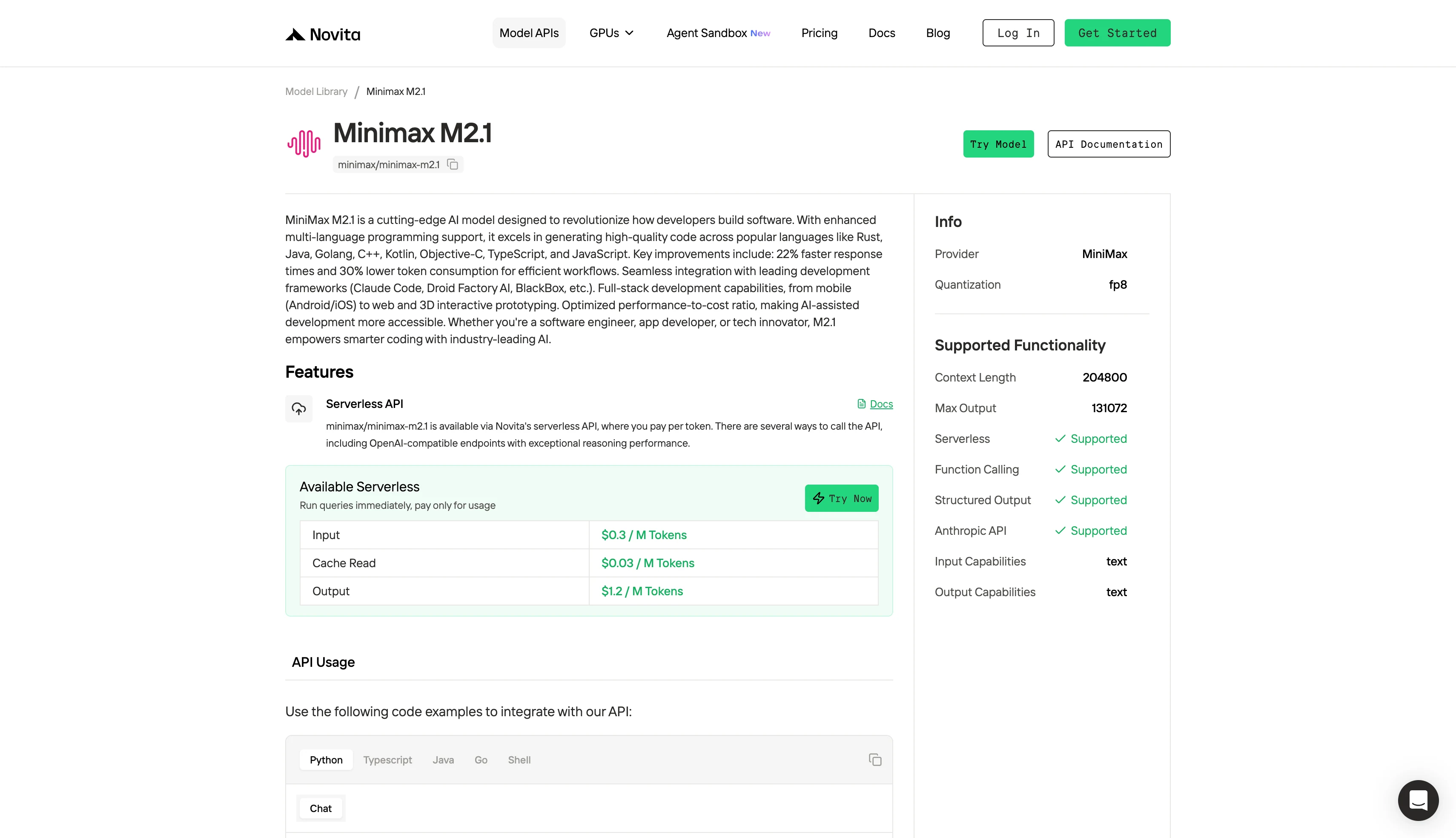
Шаг 4: Получите ваш API-ключ
Для аутентификации через API мы предоставим вам новый API-ключ. Перейдя на страницу «Настройки», вы можете скопировать API-ключ, как показано на изображении.

from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="minimax/minimax-m2.1",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
Вариант 2: Многоагентные рабочие процессы с SDK OpenAI Agents
Создавайте продвинутые многоагентные системы, интегрировав Novita AI с SDK OpenAI Agents:
- Подключи и работай: Используйте LLM от Novita AI в любом рабочем процессе OpenAI Agents.
- Поддерживает передачу задач, маршрутизацию и использование инструментов: Проектируйте агентов, которые могут делегировать задачи, сортировать их или запускать функции, все на основе моделей Novita AI.
- Интеграция с Python: Просто укажите SDK эндпоинт Novita (
https://api.novita.ai/v3/openai) и используйте ваш API-ключ.
Вариант 3:Подключите API GLM 4.7 Flash на сторонних платформах
- Hugging Face: Используйте GLM 4.7 и MInimax M2.1 в Spaces, конвейерах или с библиотекой Transformers через эндпоинты Novita AI.
- Агентные фреймворки и фреймворки оркестрации: Легко подключайте Novita AI к партнерским платформам, таким как Continue, AnythingLLM,LangChain, Dify и Langflow через официальные коннекторы и пошаговые руководства по интеграции.
- Совместимый с OpenAI API: Легко подключайте Novita AI к партнерским платформам, таким как Claude code,Cursor,Trae,Continue, Codex, OpenCode, AnythingLLM,LangChain, Dify и Langflow через официальные коннекторы и пошаговые руководства по интеграции.
Для автономных агентов, многоязычного кодирования и экономичного производства выбирайте MiniMax-M2.1. Для научных рассуждений, конкурентного программирования или специализированных математических задач выбирайте подходящий вариант DeepSeek V3.2: Standard для сбалансированного повседневного использования, Speciale для максимальной мощности рассуждений, Thinking для решения задач с цепочкой рассуждений или Exp для исследований с длинным контекстом.
Часто задаваемые вопросы
Какая модель лучше подходит для автономных кодирующих агентов: MiniMax-M2.1 или DeepSeek V3.2?
MiniMax-M2.1 обычно лучше, чем DeepSeek V3.2, для кодирующих агентов с вызовом инструментов и многошаговых рабочих процессов SWE-bench.
Какая модель сильнее в математике и рассуждениях на уровне соревнований: MiniMax-M2.1 или DeepSeek V3.2?
DeepSeek V3.2 Speciale сильнее, чем MiniMax-M2.1, в математике в стиле AIME и бенчмарках глубоких рассуждений.
Какую модель легче развернуть для личного производства: MiniMax-M2.1 или DeepSeek V3.2?
MiniMax-M2.1 значительно легче развернуть, чем DeepSeek V3.2, так как для нее требуются гораздо меньшие кластеры GPU.
Novita AI — это облачная ИИ-платформа, которая предлагает разработчикам простой способ развертывания ИИ-моделей через наш простой API, а также предоставляет доступное и надежное облако GPU для построения и масштабирования решений.



