

MiniMax M2.7 现已登陆 Novita AI,为用户带来生产级 AI 智能体能力,并具备卓越的成本效益。这款自我进化推理模型取得了 50 分的智能指数(与 GLM-5 相当),而运行成本却低三倍。凭借对 40 多种复杂工具的 97% 技能遵循率、原生智能体团队支持,以及行业领先的真实任务表现(GDPval-AA Elo 1495),M2.7 专为需要可靠智能体 AI 且预算有限的开发者打造。
定价:输入 $0.3/Mt,输出 $1.2/Mt(缓存读取 $0.06/Mt)
上下文窗口:204,800 tokens
挑战:构建可靠的 AI 智能体仍然太难
大多数大语言模型都声称具备“智能体能力”,但实际部署情况却截然不同:
- 工具调用失败:模型误解函数签名、跳过必要参数或幻觉出不存在的工具
- 上下文崩溃:长时间运行的智能体会话遭遇 token 限制或在任务中途丢失关键上下文
- 不可靠的执行:在演示中表现良好,但在生产环境中处理 40 多种技能时却失败
- 成本激增:运行前沿推理模型(如 Claude Opus 4.6 或 GPT-5.4)成本迅速攀升
你需要一个能在生产智能体系统中真正工作的模型——而不仅仅是在基准测试中表现优异的模型。
解决方案:MiniMax M2.7 的自我进化架构
MiniMax M2.7 是该公司首个参与自身开发的模型——它实际调试了自己的训练过程、构建了评估框架,并优化了自身的脚手架。这种自我进化循环产生了一款特别适合真实智能体任务的模型。
M2.7 的独特之处
1. 生产级软件工程
M2.7 不仅能写代码——它还能调试线上系统。当生产告警触发时,它能关联监控指标与部署时间线,执行统计跟踪分析,连接数据库验证假设,精准定位缺失的索引迁移文件,并知晓使用非阻塞索引创建来止血,然后提交修复。
2. 原生智能体团队支持
不同于通过提示词模拟多智能体工作流的模型,M2.7 在模型层面内置了角色边界、对抗推理和行为差异化。它能:
- 在多智能体场景中稳定锚定自身角色身份
- 主动挑战队友的逻辑盲点
- 在复杂状态机中自主决策
3. 97% 技能遵循率
大多数模型在处理超过几种工具时就会崩溃。M2.7 即使在面对 40 多种复杂技能(每种超过 2,000 tokens)时,仍能保持 97% 的技能遵循准确率。它能理解冗长复杂的函数定义,并在扩展交互中正确使用它们。
4. 专业工作空间卓越表现
- GDPval-AA Elo:1495(开源模型中最高,领先于 MiMo-V2-Pro 和 Kimi K2.5)
- 高保真办公编辑:在 Excel、PowerPoint 和 Word 中进行多轮修订
- 真实任务:阅读年度报告、设计收入模型、根据模板生成 PPT——就像一位通过反馈自我修正的初级分析师
5. 兼具智能与情感 IQ
M2.7 以高情商和角色一致性打破了“冰冷工具”的刻板印象,能够在纯生产力任务之外实现自然、类人的交互。
技术规格与性能
技术规格
| 参数 | 值 |
| 上下文窗口 | 204,800 tokens |
| 最大输出 | 131,072 tokens |
| 量化 | FP8 |
| 输入模态 | 文本 |
| 输出模态 | 文本 |
| 支持特性 | 工具、JSON 模式、结构化输出、推理 |
| 采样参数 | temperature、top_p、top_k、repetition_penalty、frequency_penalty、presence_penalty、stop、seed |
基准测试性能概览
MiniMax M2.7 在真实智能体任务中展现领先性能,在关键基准测试中优于或持平前沿模型:
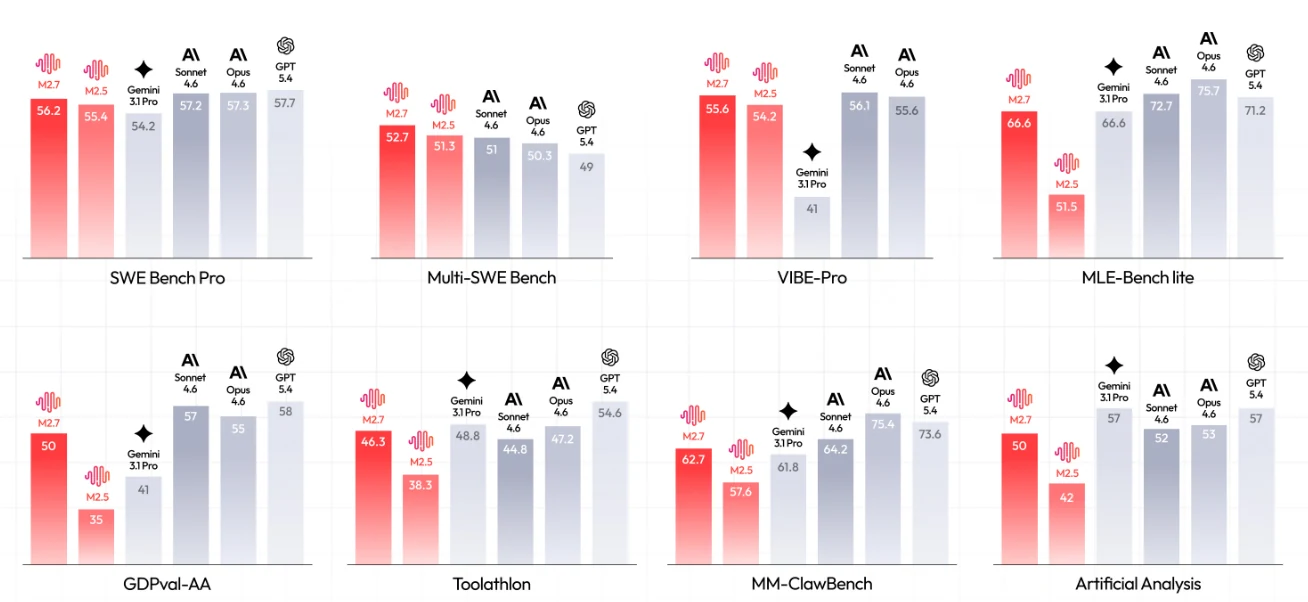
M2.7(红色柱状)与竞争模型在 8 个关键基准测试上的对比。[来源:MiniMax 官方]
关键洞察:
- SWE 能力:SWE Bench Pro 上 56.2%,接近前沿模型(GPT-5.4 为 57.7%)
- 多语言优势:Multi-SWE Bench 上 52.7,优于包括 GPT-5.4(49)在内的所有竞争者
- ML 自动化:MLE-Bench lite 上 66.6%,与 Gemini 3.1 Pro 持平,仅落后于 Opus 4.6(75.7%)和 GPT-5.4(71.2%)
- 智能体卓越性:GDPval-AA 智能指数 50,与基准测试的生产就绪基线持平
智能与成本:同类最优效率
M2.7 的突出之处不仅在于性能,更在于以极低成本提供前沿级别的智能:
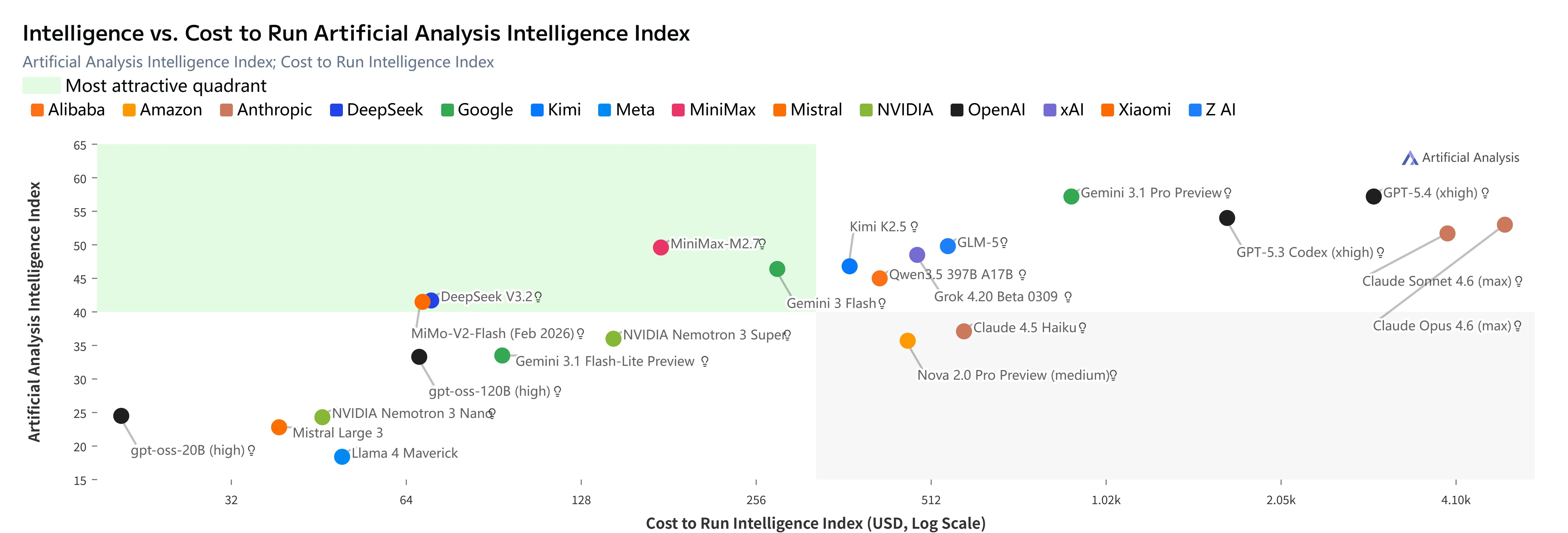
MiniMax M2.7(红点)位于 Artificial Analysis 智能指数与成本图的“最具吸引力象限”。[来源:Artificial Analysis]
关键洞察:
- GLM-5 级别的智能,成本降低近 2/3
- 比 Kimi K2.5 便宜 3 倍,且智能更高
- 比 Claude Opus 4.6 便宜 23 倍,智能差距仅 5 分
- 在所有智能指数 ≥47 的模型中,每智能点成本最低
幻觉缓解
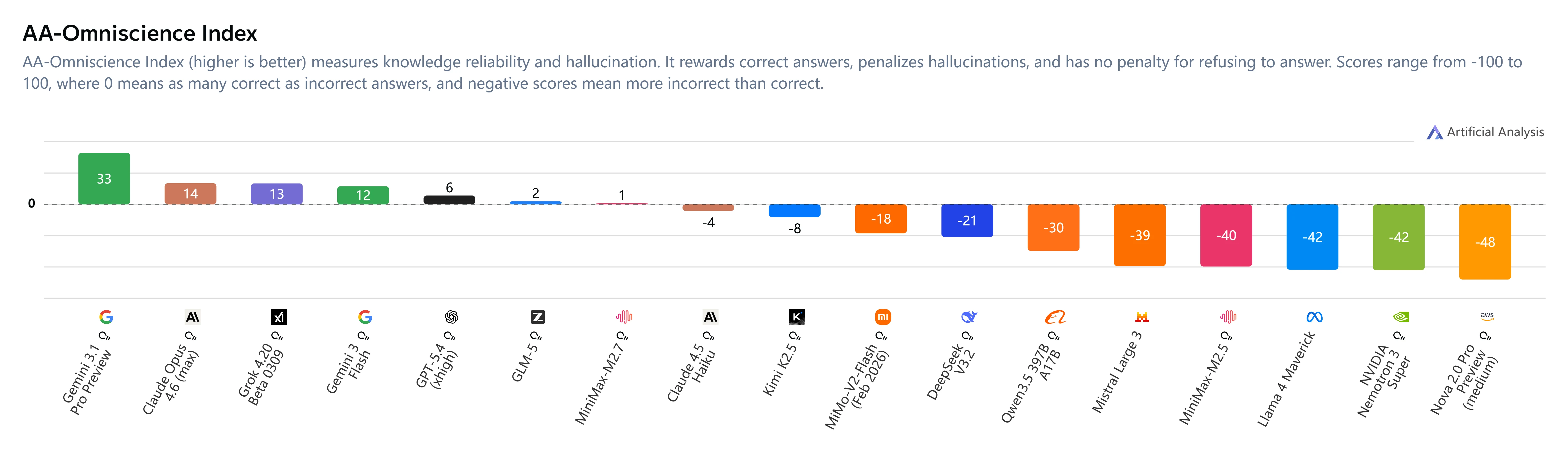
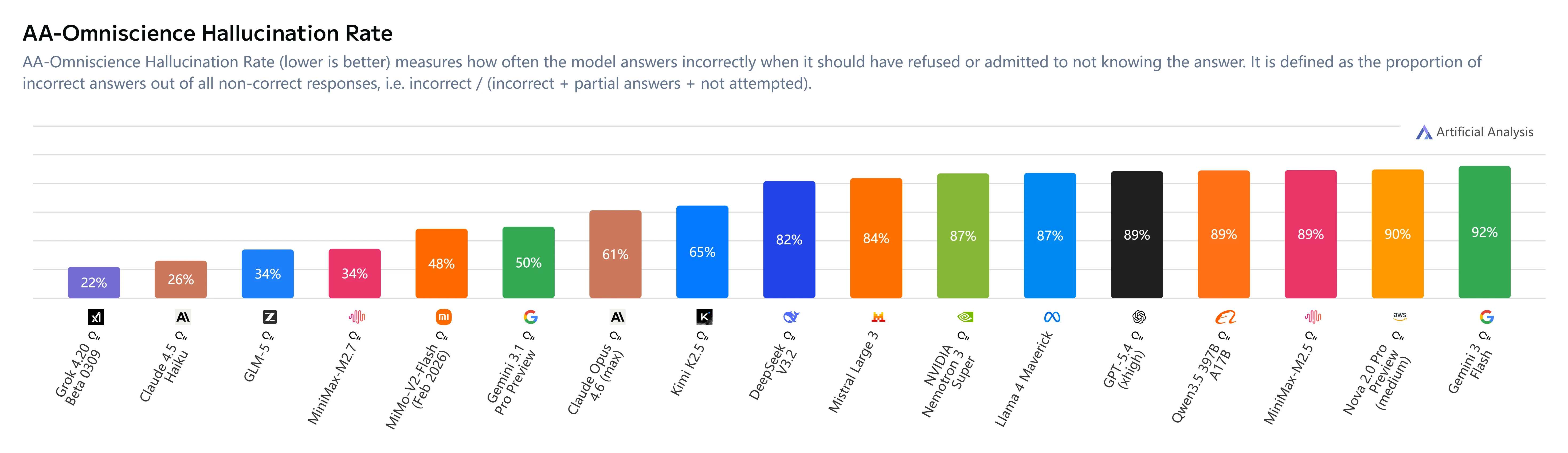
关键洞察:
- AA-Omniscience 指数:+1(较 M2.5 的 -40 显著提升)
- 幻觉率:34%(低于 Claude Sonnet 4.6 的 46% 和 Gemini 3.1 Pro 的 50%)
- 行为变化:MiniMax M2.7 在不确定时会选择回避而非猜测,显著提升可靠性
Novita AI 上的定价
| 参数 | MiniMax M2.7 | GLM-5 | Kimi K2.5 |
| 输入 | $0.3/Mt | $1.0/Mt | $0.6/Mt |
| 输出 | $1.2/Mt | $3.2/Mt | $3.0/Mt |
| 缓存读取 | $0.06/Mt | $0.2/Mt | $0.1/Mt |
| 上下文窗口 | 204,800 tokens | 202,800 tokens | 262,144 tokens |
为什么选择 Novita AI 来使用 MiniMax M2.7?
- 具有竞争力的定价:输入 $0.3/Mt,远低于其他平台
- 提示缓存:对重复上下文实现 80% 成本降低,缓存读取仅 $0.06/Mt
- 无服务器部署:无需管理基础设施
- 统一 API:兼容 OpenAI 的端点——一行代码切换模型
- 全球边缘网络:来自美国数据中心的低延迟推理
如何在 Novita AI 上开始使用 MiniMax M2.7
前提条件
- 创建一个 Novita AI 账户(免费注册)
- 获取 API 密钥
如何获取 API 密钥
API 使用(Python)
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="minimax/minimax-m2.7",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
MiniMax M2.7 能做什么:真实用例展示
MiniMax M2.7 在多个领域的复杂、生产就绪任务中表现出色:
全栈 Web 开发:生成完整的、一次性输出的网站,具备交互功能、响应式布局和实用 UI 组件——从音乐库到电子商务平台。
生产调试与 SRE:通过自动日志分析、数据库验证和主动修复部署,实现 3 分钟的事故恢复。M2.7 可自主处理根本原因分析、非阻塞迁移和安全审计。
自主软件开发:从需求到部署交付端到端项目(Web、Android、iOS)。包括多文件重构、机器学习实验自动化和自我改进——M2.7 通过迭代调试将其自身训练性能优化了 30%。
专业办公自动化:阅读年度报告、设计财务模型、生成 PPT——全部在 Excel、PowerPoint 和 Word 中完成多轮编辑。非常适合研究报告和复杂数据工作流。
AI 原生应用:通过兼容 OpenAI/Anthropic 的 API,无缝集成 OpenClaw、Claude Code、Cursor 及其他智能体框架。适用于需要 97% 工具遵循率的客服机器人、研究助手和创意工具。
结论
MiniMax M2.7 以极低的成本为开发者带来生产级 AI 智能体能力。凭借 97% 的工具遵循率、原生智能体团队支持,以及在 8 个关键基准测试中出色的真实性能,它为可靠的智能体部署而生——而不仅仅是演示。
在 Novita AI 上,输入仅 $0.3/Mt、输出 $1.2/Mt,M2.7 以 GLM-5 三分之一的价格提供同等智能。无论你是构建 SRE 自动化、全栈 Web 项目、专业工作空间工具,还是 AI 驱动的开发环境,M2.7 都是一个经济高效且经过实战检验的选择。
👉 立即开始:在 Novita AI 上体验 MiniMax M2.7
Novita AI 是一个 AI 云平台,为开发者提供通过简单 API 部署 AI 模型的便捷方式,同时提供经济可靠的高性能 GPU 云,用于构建和扩展 AI 应用。
常见问题
M2.7 和 M2.5 有什么区别?
M2.7 在所有基准测试上均优于 M2.5:(1) SWE Bench Pro:+4 分(52.2 → 56.2),(2) GDPval-AA:+15 分(35 → 50),(3) MLE-Bench lite:+35 分(31.5 → 66.6),(4) AA-Omniscience 指数上的幻觉率从 -40 降至 +1。M2.7 也是首款通过自我进化训练而成的 MiniMax 模型。
M2.7 是否支持视觉或音频输入?
目前不支持。当前版本(M2.7)仅限文本。MiniMax 拥有独立的多模态模型(Hailuo 用于视频,Speech 用于音频),但 M2.7 专注于基于文本的推理和智能体执行。
97% 的技能遵循率在实际中如何工作?
M2.7 经过训练,即使在长时间、复杂的会话中也能保持角色边界和工具协议遵循。在包含 40 多种工具(每种超过 2,000 tokens)的测试中,它能够在 97% 的情况下以正确的参数正确调用函数——远高于那些因工具数量增长而性能下降的模型。
推荐文章
Qwen 3.5 Medium 模型系列登陆 Novita AI:以低成本获取前沿智能
三款全新的 Qwen 3.5 Medium 模型为 Novita AI 带来前沿级别的智能体推理能力——开放权重、262K 上下文、可投入生产。了解这些模型如何以低廉的成本提供 GPT-4 级别的性能。
构建高性价比 AI 智能体:通过 Novita AI 在 OpenClaw 中使用 MiniMax M2.5
将 MiniMax M2.5 集成到 OpenClaw(Clawdbolt)中,搭配 Novita AI。按照这份多通道智能体部署的分步指南,在几分钟内构建可扩展、高性价比的 AI 智能体。
优化 GLM4-MoE 以投入生产:使用 SGLang 将首 Token 延迟降低 65%
了解 Novita AI 如何使用 SGLang 优化 GLM 4.7,将首 Token 生成时间加快 65%。这是在规模化部署大型 MoE 模型时的必读资料。



