

Alibaba’s Qwen 3.5 Medium series brings frontier-level reasoning to open-source models you can actually afford to run in production. Three models — Qwen3.5-35B-A3B, Qwen3.5-27B, and Qwen3.5-122B-A10B — are now live on Novita AI, offering GPT-5-mini-class performance with the flexibility of open weights and Apache 2.0 licensing.
🎉All three models are already accessible through Novita AI’s serverless LLM API — no GPU provisioning required.
What Is the Qwen 3.5 Medium Series?
On February 24, 2026, Alibaba’s Qwen team released the Qwen 3.5 Medium model series — four models that sit between the flagship Qwen3.5-397B-A17B and smaller distilled variants. Three are open-weight under Apache 2.0, and all three are now available on Novita AI.
The series targets a specific gap in the market: models compact enough for cost-sensitive production workloads, yet powerful enough to rival proprietary frontier models like GPT-5 mini and Claude Sonnet 4.5.
| Model | Total Params | Active Params | Architecture | Context |
| Qwen3.5-35B-A3B | 35B | 3B | MoE + Hybrid Attention | 262K |
| Qwen3.5-27B | 27B | 27B (dense) | Dense + Hybrid Attention | 262K |
| Qwen3.5-122B-A10B | 122B | 10B | MoE + Hybrid Attention | 262K |
Benchmark Performance
The Qwen 3.5 Medium models punch well above their weight class. Here’s how they stack up against GPT-5 mini across key categories (data from Qwen’s official benchmark results):
Knowledge & Reasoning
| Benchmark | 122B-A10B | 27B | 35B-A3B | GPT-5 mini |
| MMLU-Pro | 86.7 | 86.1 | 85.3 | 83.7 |
| GPQA Diamond | 86.6 | 85.5 | 84.2 | 82.8 |
| MMMLU | 86.7 | 85.9 | 85.2 | 86.2 |
| HMMT Feb 2025 | 91.4 | 92.0 | 89.0 | 89.2 |
Coding
| Benchmark | 122B-A10B | 27B | 35B-A3B | GPT-5 mini |
| SWE-bench Verified | 72.0 | 72.4 | 69.2 | 72.0 |
| Terminal-Bench 2 | 49.4 | 41.6 | 40.5 | 31.9 |
| LiveCodeBench v6 | 78.9 | 80.7 | 74.6 | 80.5 |
Agentic Tasks
| Benchmark | 122B-A10B | 27B | 35B-A3B | GPT-5 mini |
| BFCL-V4 (Tool Use) | 72.2 | 68.5 | 67.3 | 55.5 |
| BrowseComp | 63.8 | 61.0 | 61.0 | 48.1 |
| TAU2-Bench | 79.5 | 79.0 | 81.2 | 69.8 |
🔑 The standout: All three Medium models outperform GPT-5 mini on agentic tasks by 20–30%. On general knowledge and coding, they’re competitive or ahead. The key differentiator isn’t raw benchmark scores — it’s that you get this performance level with open weights, fine-tuning freedom, and no vendor lock-in.
What Makes It Special on Novita AI
Novita AI offers all three open-weight Qwen 3.5 Medium models via serverless API with OpenAI-compatible endpoints:
| Model | Input | Output | Context | Max Output |
| Qwen3.5-35B-A3B | $0.25/Mt | $2.00/Mt | 262K | 65K |
| Qwen3.5-27B | $0.30/Mt | $2.40/Mt | 262K | 65K |
| Qwen3.5-122B-A10B | $0.40/Mt | $3.20/Mt | 262K | 65K |
Key advantages on Novita AI:
- OpenAI-compatible API: Drop-in replacement — switch from GPT endpoints with a base URL change.
- Full 262K context: No truncation. Use the full native context window.
- Serverless: No GPU provisioning, no cold starts to manage.
Want to see how these models handle your workload? Open the Playground and run a test →
Cost Analysis: How Much Can You Save?
Imagine you’re running an agentic coding workflow that processes 1M input tokens and generates 200K output tokens per day.
| Model | Daily Input Cost | Daily Output Cost | Daily Total | Monthly (30d) |
| Qwen3.5-35B-A3B (Novita) | $0.25 | $0.40 | $0.65 | $19.50 |
| Qwen3.5-27B (Novita) | $0.30 | $0.48 | $0.78 | $23.40 |
| Qwen3.5-122B-A10B (Novita) | $0.40 | $0.64 | $1.04 | $31.20 |
| GPT-5 mini (OpenAI) | $0.25 | $0.40 | $0.65 | $19.50 |
| Claude Sonnet 4.5 (Anthropic) | $3.00 | $3.00 | $6.00 | $180.00 |
| GPT-5.2 (OpenAI) | $1.75 | $2.80 | $4.55 | $136.50 |
Pricing sources: OpenAI (GPT-5 mini: $0.25/Mt input,$2.00/Mt output, GPT-5.2: $1.75/Mt input,$14.00/Mt output), Anthropic (Claude Sonnet $3.00/Mt input,$15.00/Mt output), Novita AI .
🔑 The real story: Qwen3.5-35B-A3B on Novita AI matches GPT-5 mini’s price point while delivering significantly stronger agentic performance (BFCL-V4: 67.3 vs 55.5). Compared to GPT-5.2 and Claude Sonnet 4.5, you save 7–9× on cost. The value proposition isn’t just price — it’s open weights at a closed-model price, with better agentic capabilities.
Use Cases and Best Practices
Suppose you’re building an AI-powered code review agent that scans pull requests, identifies issues, and suggests fixes. The agent needs to process entire repository contexts (50K–200K tokens), call external tools (linters, test runners), and generate structured feedback.
Here’s why Qwen 3.5 Medium is a strong fit:
1. Agentic Tool-Calling Pipelines
With a BFCL-V4 score of 72.2 (122B-A10B), these models excel at structured function calling. Build multi-step agents that chain API calls, parse responses, and make decisions — with reliability that exceeds GPT-5 mini by a wide margin.
2. Long-Context Code Analysis
The 262K native context window means you can feed entire codebases without chunking. The hybrid attention architecture keeps costs manageable even at high token counts.
3. Open-Weight Flexibility
Unlike GPT-5 mini, you can fine-tune Qwen 3.5 Medium on your own data, deploy it on-premise for compliance requirements, or run quantized versions locally on consumer GPUs (the 35B-A3B runs on 8GB+ VRAM with 4-bit quantization).
Which Model Should You Pick?
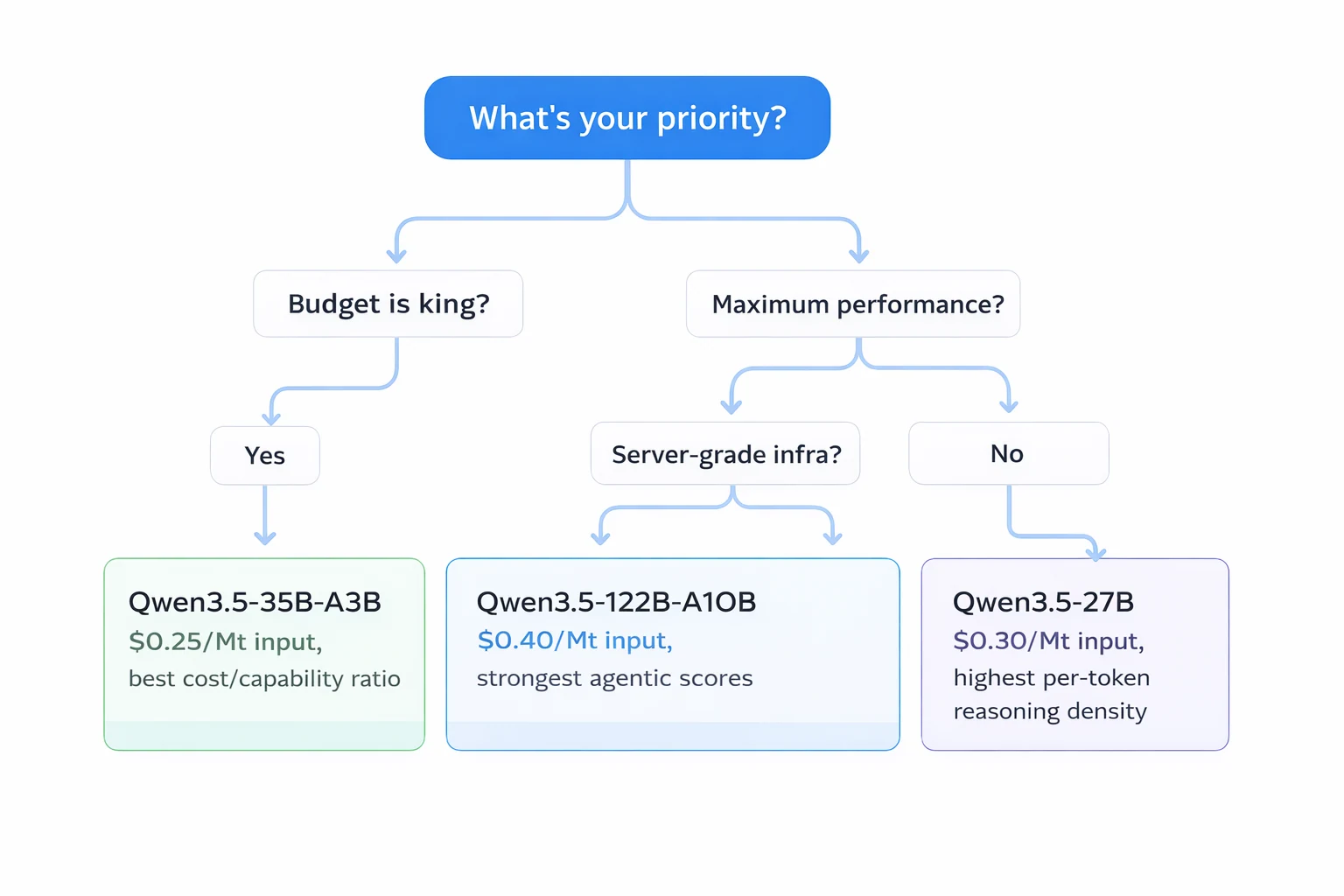
Quick guide:
- Qwen3.5-35B-A3B → Best overall pick. Lowest cost, runs on consumer GPUs locally (8GB+ VRAM with quantization), and still beats GPT-5 mini on most benchmarks.
- Qwen3.5-27B → Highest per-token reasoning density (all 27B params active). Best SWE-bench score (72.4) in the series. Ideal when you need maximum reasoning per forward pass.
- Qwen3.5-122B-A10B → Top agentic scores across the board. Best for complex multi-step agent workflows where tool-calling accuracy is critical.
How to Get Started
Novita AI offers multiple ways to integrate the Qwen 3.5 Medium models into your workflow — from zero-code exploration to production API integration.
Try It in the Playground
Before writing any code, test the models interactively in the Novita AI Playground:
- Switch on Thinking Mode to see the model’s internal reasoning chain.
- Adjust parameters: Temperature and Top_p for controlling output creativity.
- Stress-test long context: Paste documents up to 262K tokens to evaluate recall and comprehension.
New users signing up for a Novita AI account receive free trial credits — enough to run dozens of tests at no cost.
Step 1: Get Your API Key
- Visit novita.ai and sign up or log in.
- Navigate to API Keys in the dashboard.
- Click Add New Key and copy it immediately — the key is shown only once.
Step 2: Call the API
- Base URL:
https://api.novita.ai/openai - Model IDs:
qwen/qwen3.5-35b-a3b,qwen/qwen3.5-27b,qwen/qwen3.5-122b-a10b
Python Example:
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3.5-122b-a10b",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].message.content)Step 3: Integrate with Your Tools
Since Novita AI follows the OpenAI/Anthropic API standard, Qwen 3.5 Medium models work seamlessly with the tools you already use:
- Coding assistants: Cline, Cursor, OpenCode, Trae
- Agent frameworks: LangChain, Langflow, Continue
- Anthropic-compatible workflows: Claude Code
- Chat UIs: AnythingLLM
- Hugging Face Hub: Novita AI is listed as an Inference Provider for supported models.
- Personal AI agents: OpenClaw — connect Qwen 3.5 Medium models to build always-on agents across messaging platforms.
Conclusion
A year ago, getting GPT-5-mini-level agentic performance from an open-weight model you could fine-tune and self-host was not realistic. The Qwen 3.5 Medium series changes that equation, particularly on tool use and multi-step agent workflows, where these models don’t just match proprietary alternatives but measurably exceed them.
For teams evaluating their model stack, the practical next step is straightforward: run your own prompts in the Playground, benchmark against your current provider, and decide based on your data — not ours.
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing the affordable and reliable GPU cloud for building and scaling.
Frequently Asked Questions
What’s the difference between Qwen3.5-Flash and Qwen3.5-35B-A3B?
Qwen3.5-Flash is the proprietary hosted version of the 35B-A3B, available only through Alibaba Cloud. It offers a 1M context window and built-in official tools. The open-weight 35B-A3B on Novita AI supports 262K context natively and is extensible up to 1M tokens.
Can I use these models for commercial applications?
Yes. All three open-weight models are released under the Apache 2.0 license — no restrictions on commercial use, fine-tuning, or redistribution.
How do these compare to the flagship Qwen3.5-397B-A17B?
The 397B flagship (also available on Novita AI at $0.60/Mt input,$3.60/Mt output) is stronger on competitive programming and some reasoning tasks. But the Medium models are surprisingly close — the 122B-A10B matches or exceeds it on agentic benchmarks, and the 35B-A3B delivers 85–95% of the flagship’s performance at less than half the cost.



