

A série Qwen 3.5 Medium da Alibaba traz raciocínio de nível de ponta para modelos de código aberto que você pode realmente arcar com os custos de executar em produção. Três modelos — Qwen3.5-35B-A3B, Qwen3.5-27B e Qwen3.5-122B-A10B — já estão disponíveis na Novita AI, oferecendo desempenho da classe do GPT-5-mini com a flexibilidade de pesos abertos e licença Apache 2.0.
🎉Todos os três modelos já estão acessíveis por meio da API de LLM serverless da Novita AI — não é necessário provisionar GPUs.
O que é a Série Qwen 3.5 Medium?
Em 24 de fevereiro de 2026, a equipe Qwen da Alibaba lançou a série de modelos Qwen 3.5 Medium — quatro modelos que ficam entre o principal Qwen3.5-397B-A17B e as variantes destiladas menores. Três são de pesos abertos sob a licença Apache 2.0, e todos os três já estão disponíveis na Novita AI.
A série visa uma lacuna específica no mercado: modelos compactos o suficiente para cargas de trabalho de produção sensíveis a custos, mas poderosos o suficiente para rivalizar com modelos de ponta proprietários como o GPT-5 mini e o Claude Sonnet 4.5.
| Modelo | Parâmetros Totais | Parâmetros Ativos | Arquitetura | Contexto |
| Qwen3.5-35B-A3B | 35B | 3B | MoE + Hybrid Attention | 262K |
| Qwen3.5-27B | 27B | 27B (denso) | Dense + Hybrid Attention | 262K |
| Qwen3.5-122B-A10B | 122B | 10B | MoE + Hybrid Attention | 262K |
Desempenho em Benchmarks
Os modelos Qwen 3.5 Medium têm desempenho muito acima da sua classe. Veja como eles se comparam ao GPT-5 mini nas principais categorias (dados dos resultados oficiais de benchmark da Qwen):
Conhecimento e Raciocínio
| Benchmark | 122B-A10B | 27B | 35B-A3B | GPT-5 mini |
| MMLU-Pro | 86.7 | 86.1 | 85.3 | 83.7 |
| GPQA Diamond | 86.6 | 85.5 | 84.2 | 82.8 |
| MMMLU | 86.7 | 85.9 | 85.2 | 86.2 |
| HMMT Feb 2025 | 91.4 | 92.0 | 89.0 | 89.2 |
Codificação
| Benchmark | 122B-A10B | 27B | 35B-A3B | GPT-5 mini |
| SWE-bench Verified | 72.0 | 72.4 | 69.2 | 72.0 |
| Terminal-Bench 2 | 49.4 | 41.6 | 40.5 | 31.9 |
| LiveCodeBench v6 | 78.9 | 80.7 | 74.6 | 80.5 |
Tarefas Agênticas
| Benchmark | 122B-A10B | 27B | 35B-A3B | GPT-5 mini |
| BFCL-V4 (Tool Use) | 72.2 | 68.5 | 67.3 | 55.5 |
| BrowseComp | 63.8 | 61.0 | 61.0 | 48.1 |
| TAU2-Bench | 79.5 | 79.0 | 81.2 | 69.8 |
🔑 Destaque: Todos os três modelos Medium superam o GPT-5 mini em tarefas agênticas em 20–30%. Em conhecimento geral e codificação, eles são competitivos ou melhores. O principal diferencial não são as pontuações brutas de benchmark — é que você obtém esse nível de desempenho com pesos abertos, liberdade de ajuste fino e sem lock-in de fornecedor.
O que o Torna Especial na Novita AI
A Novita AI oferece todos os três modelos Qwen 3.5 Medium de pesos abertos por meio de API serverless com endpoints compatíveis com a OpenAI:
| Modelo | Entrada | Saída | Contexto | Saída Máxima |
| Qwen3.5-35B-A3B | $0.25/Mt | $2.00/Mt | 262K | 65K |
| Qwen3.5-27B | $0.30/Mt | $2.40/Mt | 262K | 65K |
| Qwen3.5-122B-A10B | $0.40/Mt | $3.20/Mt | 262K | 65K |
Vantagens principais na Novita AI:
- API compatível com a OpenAI: Substituição direta — alterne de endpoints GPT apenas mudando a URL base.
- Contexto completo de 262K: Sem truncamento. Use a janela de contexto nativa completa.
- Serverless: Sem provisionamento de GPUs, sem cold starts para gerenciar.
Quer ver como esses modelos lidam com a sua carga de trabalho? Abra o Playground e faça um teste →
Análise de Custos: Quanto Você Pode Economizar?
Imagine que você está executando um fluxo de trabalho de codificação agêntica que processa 1M de tokens de entrada e gera 200K de tokens de saída por dia.
| Modelo | Custo Diário de Entrada | Custo Diário de Saída | Total Diário | Mensal (30d) |
| Qwen3.5-35B-A3B (Novita) | $0.25 | $0.40 | $0.65 | $19.50 |
| Qwen3.5-27B (Novita) | $0.30 | $0.48 | $0.78 | $23.40 |
| Qwen3.5-122B-A10B (Novita) | $0.40 | $0.64 | $1.04 | $31.20 |
| GPT-5 mini (OpenAI) | $0.25 | $0.40 | $0.65 | $19.50 |
| Claude Sonnet 4.5 (Anthropic) | $3.00 | $3.00 | $6.00 | $180.00 |
| GPT-5.2 (OpenAI) | $1.75 | $2.80 | $4.55 | $136.50 |
Fontes de preços: OpenAI (GPT-5 mini: $0.25/Mt entrada, $2.00/Mt saída, GPT-5.2: $1.75/Mt entrada, $14.00/Mt saída), Anthropic (Claude Sonnet $3.00/Mt entrada, $15.00/Mt saída), Novita AI .
🔑 A história real: O Qwen3.5-35B-A3B na Novita AI tem o mesmo preço do GPT-5 mini, mas oferece desempenho agêntico significativamente superior (BFCL-V4: 67.3 vs 55.5). Comparado ao GPT-5.2 e ao Claude Sonnet 4.5, você economiza 7 a 9 vezes no custo. A proposta de valor não é apenas o preço — são pesos abertos pelo preço de um modelo fechado, com capacidades agênticas melhores.
Casos de Uso e Melhores Práticas
Suponha que você esteja construindo um agente de revisão de código alimentado por IA que escaneia pull requests, identifica problemas e sugere correções. O agente precisa processar contextos inteiros de repositórios (50K–200K tokens), chamar ferramentas externas (linters, executores de testes) e gerar feedback estruturado.
Veja por que o Qwen 3.5 Medium é uma ótima escolha:
1. Pipelines de Chamada de Ferramentas Agênticas
Com uma pontuação BFCL-V4 de 72.2 (122B-A10B), esses modelos se destacam em chamadas de funções estruturadas. Construa agentes de múltiplos passos que encadeiam chamadas de API, analisam respostas e tomam decisões — com uma confiabilidade que supera o GPT-5 mini por uma ampla margem.
2. Análise de Código de Longo Contexto
A janela de contexto nativa de 262K significa que você pode alimentar bases de código inteiras sem dividir em blocos. A arquitetura de atenção híbrida mantém os custos gerenciáveis mesmo com contagens altas de tokens.
3. Flexibilidade de Pesos Abertos
Ao contrário do GPT-5 mini, você pode ajustar finamente o Qwen 3.5 Medium com os seus próprios dados, implantá-lo on-premise para requisitos de conformidade ou executar versões quantizadas localmente em GPUs de consumo (o 35B-A3B funciona em 8GB+ de VRAM com quantização de 4 bits).
Qual Modelo Você Deve Escolher?
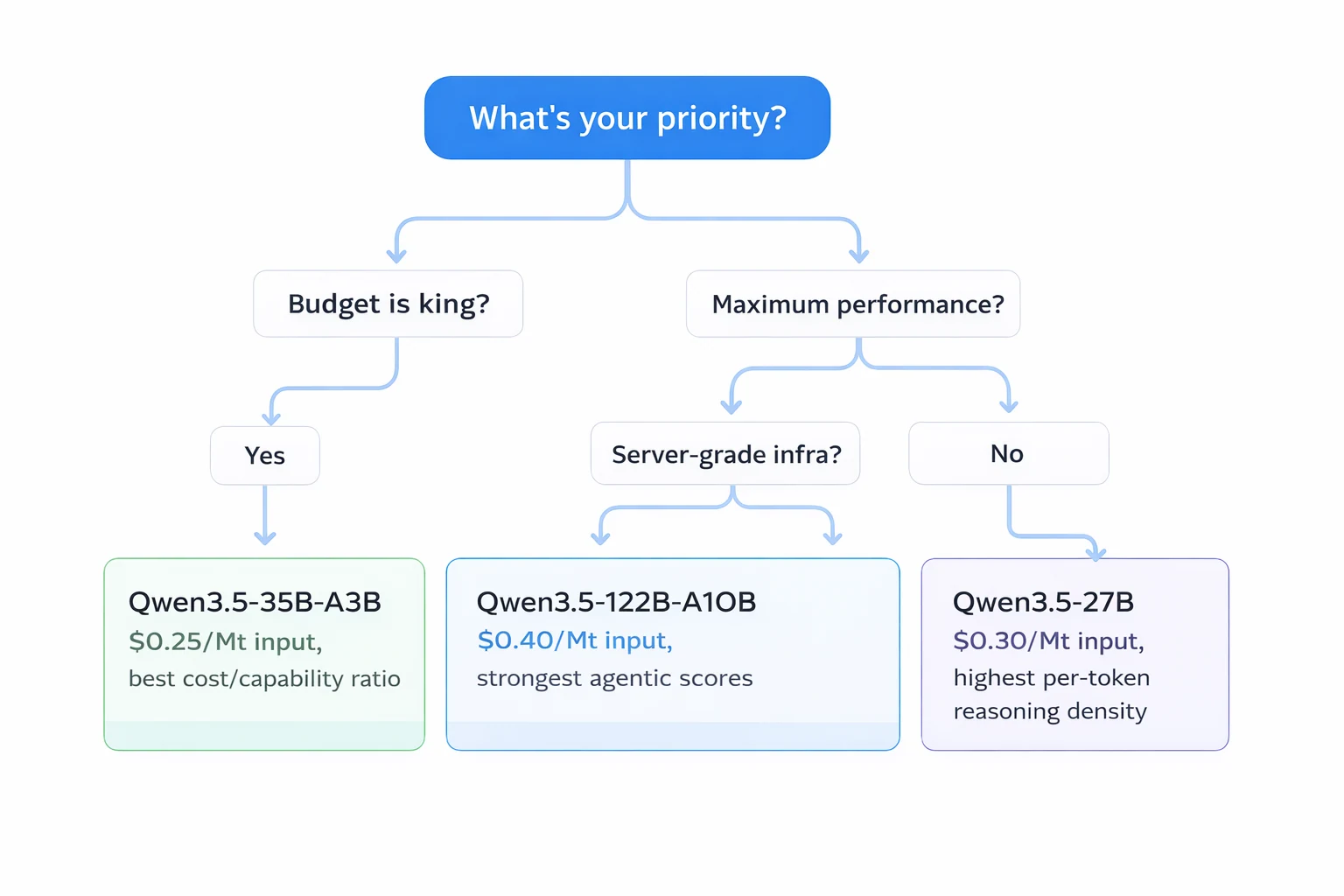
Guia rápido:
- Qwen3.5-35B-A3B → Melhor escolha geral. Menor custo, funciona em GPUs de consumo localmente (8GB+ de VRAM com quantização) e ainda supera o GPT-5 mini na maioria dos benchmarks.
- Qwen3.5-27B → Maior densidade de raciocínio por token (todos os 27B de parâmetros ativos). Melhor pontuação no SWE-bench (72.4) da série. Ideal quando você precisa de máximo raciocínio por passagem forward.
- Qwen3.5-122B-A10B → Melhores pontuações agênticas em todas as categorias. Melhor para fluxos de trabalho de agentes complexos de múltiplos passos onde a precisão da chamada de ferramentas é crítica.
Como Começar
A Novita AI oferece várias maneiras de integrar os modelos Qwen 3.5 Medium ao seu fluxo de trabalho — desde exploração sem código até integração de API em produção.
Teste no Playground
Antes de escrever qualquer código, teste os modelos de forma interativa no Playground da Novita AI:
- Ative o Modo de Pensamento para ver a cadeia de raciocínio interna do modelo.
- Ajuste os parâmetros: Temperatura e Top_p para controlar a criatividade da saída.
- Teste de estresse de contexto longo: Cole documentos de até 262K tokens para avaliar a recall e a compreensão.
Novos usuários que se cadastrarem em uma conta da Novita AI recebem créditos de teste gratuitos — suficientes para executar dezenas de testes sem custo.
Passo 1: Obtenha a Sua Chave de API
- Acesse novita.ai e cadastre-se ou faça login.
- Navegue até Chaves de API no painel de controle.
- Clique em Adicionar Nova Chave e copie-a imediatamente — a chave é exibida apenas uma vez.
Passo 2: Chame a API
- URL base:
https://api.novita.ai/openai - IDs de modelo:
qwen/qwen3.5-35b-a3b,qwen/qwen3.5-27b,qwen/qwen3.5-122b-a10b
Exemplo em Python:
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3.5-122b-a10b",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].message.content)
Passo 3: Integre com as Suas Ferramentas
Como a Novita AI segue o padrão de API da OpenAI/Anthropic, os modelos Qwen 3.5 Medium funcionam perfeitamente com as ferramentas que você já usa:
- Assistentes de codificação: Cline, Cursor, OpenCode, Trae
- Frameworks de agentes: LangChain, Langflow, Continue
- Fluxos de trabalho compatíveis com Anthropic: Claude Code
- Interfaces de chat: AnythingLLM
- Hugging Face Hub: A Novita AI está listada como Provedor de Inferência para os modelos suportados.
- Agentes de IA pessoais: OpenClaw — conecte os modelos Qwen 3.5 Medium para construir agentes sempre ativos em plataformas de mensagens.
Conclusão
Um ano atrás, obter desempenho agêntico de nível do GPT-5-mini a partir de um modelo de pesos abertos que você pudesse ajustar finamente e auto-hospedar não era realista. A série Qwen 3.5 Medium muda essa equação, especialmente no uso de ferramentas e fluxos de trabalho de agentes de múltiplos passos, onde esses modelos não apenas igualam alternativas proprietárias, mas as superam de forma mensurável.
Para equipes que avaliam a sua pilha de modelos, o próximo passo prático é simples: execute os seus próprios prompts no Playground, faça benchmarks contra o seu provedor atual e decida com base nos seus dados — não nos nossos.
Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando a nossa API simples, além de fornecer uma nuvem de GPUs acessível e confiável para construir e escalar.
Perguntas Frequentes
Qual a diferença entre o Qwen3.5-Flash e o Qwen3.5-35B-A3B?
O Qwen3.5-Flash é a versão hospedada proprietária do 35B-A3B, disponível apenas por meio da Alibaba Cloud. Ele oferece uma janela de contexto de 1M e ferramentas oficiais integradas. O 35B-A3B de pesos abertos na Novita AI suporta contexto nativo de 262K e é extensível até 1M de tokens.
Posso usar esses modelos para aplicações comerciais?
Sim. Todos os três modelos de pesos abertos são lançados sob a licença Apache 2.0 — sem restrições para uso comercial, ajuste fino ou redistribuição.
Como eles se comparam ao modelo principal Qwen3.5-397B-A17B?
O modelo principal 397B (também disponível na Novita AI por $0.60/Mt entrada, $3.60/Mt saída) é mais forte em programação competitiva e algumas tarefas de raciocínio. Mas os modelos Medium são surpreendentemente próximos — o 122B-A10B iguala ou supera ele em benchmarks agênticos, e o 35B-A3B entrega 85–95% do desempenho do modelo principal por menos da metade do custo.



