

La série Qwen 3.5 Medium d’Alibaba apporte un raisonnement de niveau pointe à des modèles open source que vous pouvez réellement vous permettre d’exécuter en production. Trois modèles — Qwen3.5-35B-A3B, Qwen3.5-27B et Qwen3.5-122B-A10B — sont désormais disponibles sur Novita AI, offrant des performances équivalentes à GPT-5-mini avec la flexibilité de poids ouverts et une licence Apache 2.0.
🎉 Les trois modèles sont déjà accessibles via l’API LLM serverless de Novita AI — aucune provision de GPU requise.
Essayez Qwen3.5-35B-A3B dès maintenant !
Qu’est-ce que la série Qwen 3.5 Medium ?
Le 24 février 2026, l’équipe Qwen d’Alibaba a publié la série de modèles Qwen 3.5 Medium — quatre modèles qui se situent entre le flagship Qwen3.5-397B-A17B et les variantes distillées plus petites. Trois d’entre eux sont en poids ouverts sous licence Apache 2.0, et les trois sont désormais disponibles sur Novita AI.
Cette série cible un manque spécifique sur le marché : des modèles suffisamment compacts pour des charges de travail de production sensibles aux coûts, mais suffisamment puissants pour rivaliser avec des modèles propriétaires de pointe comme GPT-5 mini et Claude Sonnet 4.5.
| Modèle | Paramètres totaux | Paramètres actifs | Architecture | Contexte |
| Qwen3.5-35B-A3B | 35B | 3B | MoE + Attention hybride | 262K |
| Qwen3.5-27B | 27B | 27B (dense) | Dense + Attention hybride | 262K |
| Qwen3.5-122B-A10B | 122B | 10B | MoE + Attention hybride | 262K |
Performances aux benchmarks
Les modèles Qwen 3.5 Medium performent bien au-delà de leur catégorie. Voici comment ils se comparent à GPT-5 mini sur des catégories clés (données issues des résultats de benchmark officiels de Qwen) :
Connaissance et raisonnement
| Benchmark | 122B-A10B | 27B | 35B-A3B | GPT-5 mini |
| MMLU-Pro | 86.7 | 86.1 | 85.3 | 83.7 |
| GPQA Diamond | 86.6 | 85.5 | 84.2 | 82.8 |
| MMMLU | 86.7 | 85.9 | 85.2 | 86.2 |
| HMMT Feb 2025 | 91.4 | 92.0 | 89.0 | 89.2 |
Codage
| Benchmark | 122B-A10B | 27B | 35B-A3B | GPT-5 mini |
| SWE-bench Verified | 72.0 | 72.4 | 69.2 | 72.0 |
| Terminal-Bench 2 | 49.4 | 41.6 | 40.5 | 31.9 |
| LiveCodeBench v6 | 78.9 | 80.7 | 74.6 | 80.5 |
Tâches agentiques
| Benchmark | 122B-A10B | 27B | 35B-A3B | GPT-5 mini |
| BFCL-V4 (Tool Use) | 72.2 | 68.5 | 67.3 | 55.5 |
| BrowseComp | 63.8 | 61.0 | 61.0 | 48.1 |
| TAU2-Bench | 79.5 | 79.0 | 81.2 | 69.8 |
🔑 Le point fort : Les trois modèles Medium surpassent GPT-5 mini de 20 à 30 % sur les tâches agentiques. Sur les connaissances générales et le codage, ils sont compétitifs ou en avance. Le différenciateur clé n’est pas les scores bruts des benchmarks : c’est que vous obtenez ce niveau de performance avec des poids ouverts, la liberté de fine-tuning et pas de verrouillage fournisseur.
Ce qui le rend spécial sur Novita AI
Novita AI propose les trois modèles Qwen 3.5 Medium en poids ouverts via une API serverless avec des endpoints compatibles OpenAI :
| Modèle | Entrée | Sortie | Contexte | Sortie maximale |
| Qwen3.5-35B-A3B | 0,25 $/Mt | 2,00 $/Mt | 262K | 65K |
| Qwen3.5-27B | 0,30 $/Mt | 2,40 $/Mt | 262K | 65K |
| Qwen3.5-122B-A10B | 0,40 $/Mt | 3,20 $/Mt | 262K | 65K |
Avantages clés sur Novita AI :
- API compatible OpenAI : remplacement plug-and-play — passez des endpoints GPT en changeant simplement l’URL de base.
- Contexte complet de 262K : pas de troncature. Utilisez la totalité de la fenêtre de contexte native.
- Serverless : aucune provision de GPU, pas de démarrages à froid à gérer.
Vous voulez voir comment ces modèles gèrent votre charge de travail ? Ouvrez le playground et lancez un test →
Analyse des coûts : combien pouvez-vous économiser ?
Imaginez que vous exécutez un flux de travail de codage agentique qui traite 1 million de tokens d’entrée et génère 200 000 tokens de sortie par jour.
| Modèle | Coût d’entrée quotidien | Coût de sortie quotidien | Total quotidien | Mensuel (30 jours) |
| Qwen3.5-35B-A3B (Novita) | 0,25 $ | 0,40 $ | 0,65 $ | 19,50 $ |
| Qwen3.5-27B (Novita) | 0,30 $ | 0,48 $ | 0,78 $ | 23,40 $ |
| Qwen3.5-122B-A10B (Novita) | 0,40 $ | 0,64 $ | 1,04 $ | 31,20 $ |
| GPT-5 mini (OpenAI) | 0,25 $ | 0,40 $ | 0,65 $ | 19,50 $ |
| Claude Sonnet 4.5 (Anthropic) | 3,00 $ | 3,00 $ | 6,00 $ | 180,00 $ |
| GPT-5.2 (OpenAI) | 1,75 $ | 2,80 $ | 4,55 $ | 136,50 $ |
Sources de tarification : OpenAI (GPT-5 mini : 0,25 $/Mt en entrée, 2,00 $/Mt en sortie, GPT-5.2 : 1,75 $/Mt en entrée, 14,00 $/Mt en sortie), Anthropic (Claude Sonnet : 3,00 $/Mt en entrée, 15,00 $/Mt en sortie), Novita AI .
🔑 Le vrai avantage : Le Qwen3.5-35B-A3B sur Novita AI correspond au point de prix de GPT-5 mini tout en offrant des performances agentiques significativement supérieures (BFCL-V4 : 67,3 contre 55,5). Par rapport à GPT-5.2 et Claude Sonnet 4.5, vous économisez 7 à 9 fois sur les coûts. La proposition de valeur n’est pas seulement le prix : ce sont des poids ouverts au prix d’un modèle fermé, avec de meilleures capacités agentiques.
Cas d’usage et bonnes pratiques
Imaginons que vous construisiez un agent de revue de code alimenté par l’IA qui analyse les pull requests, identifie les problèmes et suggère des corrections. L’agent doit traiter des contextes de dépôts entiers (50 000 à 200 000 tokens), appeler des outils externes (linters, exécuteurs de tests) et générer des retours structurés.
Voici pourquoi Qwen 3.5 Medium est un choix solide :
1. Pipelines d’appel d’outils agentiques
Avec un score BFCL-V4 de 72,2 (122B-A10B), ces mod excellent à l’appel de fonctions structuré. Construisez des agents multi-étapes qui enchaînent des appels d’API, analysent les réponses et prennent des décisions — avec une fiabilité qui dépasse largement celle de GPT-5 mini.
2. Analyse de code à long contexte
La fenêtre de contexte native de 262K signifie que vous pouvez fournir des bases de code entières sans découpage. L’architecture d’attention hybride permet de maintenir les coûts maîtrisés même avec un nombre élevé de tokens.
3. Flexibilité des poids ouverts
Contrairement à GPT-5 mini, vous pouvez fine-tuner le Qwen 3.5 Medium sur vos propres données, le déployer sur site pour des exigences de conformité, ou exécuter des versions quantifiées localement sur des GPU grand public (le 35B-A3B fonctionne sur 8 Go de VRAM ou plus avec une quantification 4 bits).
Quel modèle choisir ?
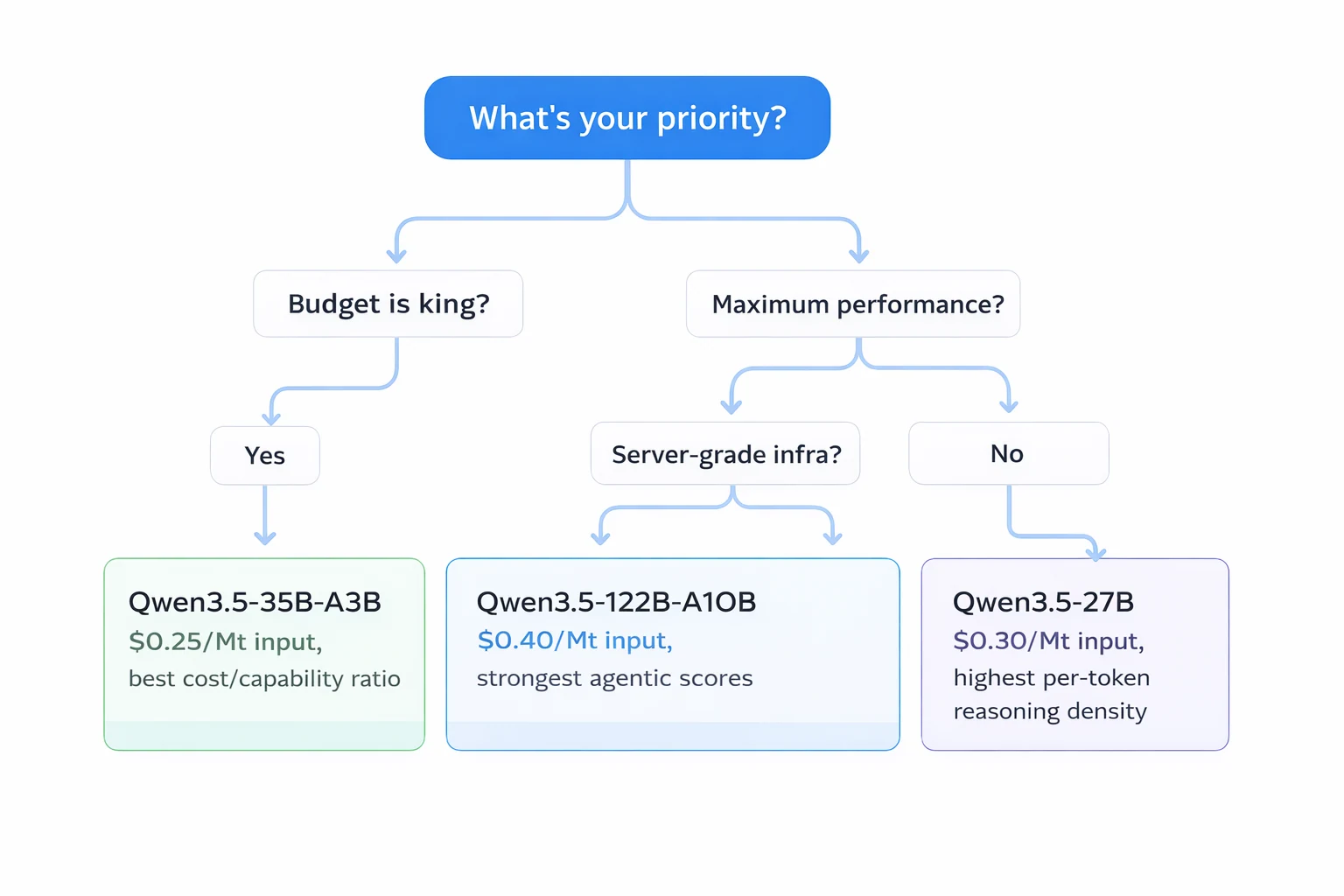
Guide rapide :
- Qwen3.5-35B-A3B → Meilleur choix global. Coût le plus bas, fonctionne sur des GPU grand public localement (8 Go de VRAM ou plus avec quantification) et surpasse toujours GPT-5 mini sur la plupart des benchmarks.
- Qwen3.5-27B → Densité de raisonnement par token la plus élevée (tous les 27 milliards de paramètres sont actifs). Meilleur score SWE-bench (72,4) de la série. Idéal lorsque vous avez besoin d’un raisonnement maximal par passage avant.
- Qwen3.5-122B-A10B → Meilleurs scores agentiques sur l’ensemble des benchmarks. Idéal pour des flux de travail agentiques complexes multi-étapes où la précision de l’appel d’outils est critique.
Comment commencer
Novita AI propose plusieurs façons d’intégrer les modèles Qwen 3.5 Medium dans votre flux de travail — de l’exploration sans code à l’intégration d’API en production.
Essayez-le dans le playground
Avant d’écrire du code, testez les modèles de manière interactive dans le playground Novita AI :
- Activez le mode réflexion pour voir la chaîne de raisonnement interne du modèle.
- Ajustez les paramètres : Température et Top_p pour contrôler la créativité des sorties.
- Testez la résistance du long contexte : collez des documents jusqu’à 262 000 tokens pour évaluer la mémorisation et la compréhension.
Les nouveaux utilisateurs qui s’inscrivent sur un compte Novita AI reçoivent des crédits d’essai gratuits — suffisants pour exécuter des dizaines de tests sans frais.
Étape 1 : Récupérez votre clé API
- Rendez-vous sur novita.ai et inscrivez-vous ou connectez-vous.
- Accédez à Clés API dans le tableau de bord.
- Cliquez sur Ajouter une nouvelle clé et copiez-la immédiatement — la clé n’est affichée qu’une seule fois.
Étape 2 : Appelez l’API
- URL de base :
https://api.novita.ai/openai - IDs de modèle :
qwen/qwen3.5-35b-a3b,qwen/qwen3.5-27b,qwen/qwen3.5-122b-a10b
Exemple Python :
from openai import OpenAI
client = OpenAI(
api_key="<Votre clé API>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3.5-122b-a10b",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].message.content)
Étape 3 : Intégrez avec vos outils
Comme Novita AI suit la norme d’API OpenAI/Anthropic, les modèles Qwen 3.5 Medium fonctionnent parfaitement avec les outils que vous utilisez déjà :
- Assistants de codage : Cline, Cursor, OpenCode, Trae
- Frameworks d’agents : LangChain, Langflow, Continue
- Flux de travail compatibles Anthropic : Claude Code
- Interfaces de chat : AnythingLLM
- Hub Hugging Face : Novita AI est répertorié comme fournisseur d’inférence pour les modèles pris en charge.
- Agents IA personnels : OpenClaw — connectez les modèles Qwen 3.5 Medium pour construire des agents toujours actifs sur les plateformes de messagerie.
Conclusion
Il y a un an, obtenir des performances agentiques de niveau GPT-5-mini à partir d’un modèle à poids ouverts que vous pouviez fine-tuner et auto-héberger n’était pas réaliste. La série Qwen 3.5 Medium change cette équation, notamment sur l’utilisation d’outils et les flux de travail agentiques multi-étapes, où ces modèles ne se contentent pas de rivaliser avec les alternatives propriétaires mais les surpassent de manière mesurable.
Pour les équipes qui évaluent leur pile de modèles, la prochaine étape pratique est simple : exécutez vos propres prompts dans le playground, comparez-les aux benchmarks de votre fournisseur actuel et décidez sur la base de vos données — pas des nôtres.
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles IA via notre API intuitive, tout en fournissant un cloud GPU abordable et fiable pour construire et mettre à l’échelle.
Foire aux questions
Quelle est la différence entre Qwen3.5-Flash et Qwen3.5-35B-A3B ?
Qwen3.5-Flash est la version hébergée propriétaire du 35B-A3B, disponible uniquement via Alibaba Cloud. Elle offre une fenêtre de contexte de 1 million de tokens et des outils officiels intégrés. Le 35B-A3B en poids ouverts sur Novita AI prend en charge nativement un contexte de 262K tokens et est extensible jusqu’à 1 million de tokens.
Puis-je utiliser ces modèles pour des applications commerciales ?
Oui. Les trois modèles en poids ouverts sont publiés sous licence Apache 2.0 — aucune restriction sur l’usage commercial, le fine-tuning ou la redistribution.
Comment se comparent-ils au flagship Qwen3.5-397B-A17B ?
Le flagship 397B (également disponible sur Novita AI à 0,60 $/Mt en entrée, 3,60 $/Mt en sortie) est plus performant sur la programmation compétitive et certaines tâches de raisonnement. Mais les modèles Medium sont étonnamment proches : le 122B-A10B l’égale ou le dépasse sur les benchmarks agentiques, et le 35B-A3B délivre 85 à 95 % des performances du flagship à moins de la moitié du coût.



