

Alibabas Qwen 3.5 Medium-Reihe bringt Schlussfolgerung auf Spitzenmodell-Niveau zu Open-Source-Modellen, die Sie sich tatsächlich leisten können, in der Produktion zu betreiben. Drei Modelle — Qwen3.5-35B-A3B, Qwen3.5-27B und Qwen3.5-122B-A10B — sind jetzt auf Novita AI verfügbar und bieten Leistung auf dem Niveau von GPT-5-mini mit der Flexibilität offener Gewichte und Apache-2.0-Lizenzierung.
🎉Alle drei Modelle sind bereits über die serverlose LLM-API von Novita AI verfügbar — keine GPU-Bereitstellung erforderlich.
Was ist die Qwen 3.5 Medium-Reihe?
Am 24. Februar 2026 veröffentlichte Alibabas Qwen-Team die Qwen 3.5 Medium-Modellreihe — vier Modelle, die zwischen dem Flaggschiff Qwen3.5-397B-A17B und kleineren destillierten Varianten liegen. Drei davon sind unter Apache 2.0 als offene Gewichte verfügbar, und alle drei sind jetzt auf Novita AI erhältlich.
Die Reihe zielt auf eine spezifische Lücke im Markt ab: Modelle, die kompakt genug für kostensensitive Produktionsworkloads sind, aber leistungsstark genug, um proprietäre Spitzenmodelle wie GPT-5 mini und Claude Sonnet 4.5 zu übertreffen.
| Modell | Gesamtparameter | Aktive Parameter | Architektur | Kontext |
| Qwen3.5-35B-A3B | 35B | 3B | MoE + Hybride Aufmerksamkeit | 262K |
| Qwen3.5-27B | 27B | 27B (dicht) | Dicht + Hybride Aufmerksamkeit | 262K |
| Qwen3.5-122B-A10B | 122B | 10B | MoE + Hybride Aufmerksamkeit | 262K |
Benchmark-Leistung
Die Qwen 3.5 Medium-Modelle übertreffen ihre Gewichtsklasse deutlich. Hier sehen Sie, wie sie im Vergleich zu GPT-5 mini in wichtigen Kategorien abschneiden (Daten aus Qwens offiziellen Benchmark-Ergebnissen):
Wissen & Schlussfolgerung
| Benchmark | 122B-A10B | 27B | 35B-A3B | GPT-5 mini |
| MMLU-Pro | 86.7 | 86.1 | 85.3 | 83.7 |
| GPQA Diamond | 86.6 | 85.5 | 84.2 | 82.8 |
| MMMLU | 86.7 | 85.9 | 85.2 | 86.2 |
| HMMT Feb 2025 | 91.4 | 92.0 | 89.0 | 89.2 |
Programmierung
| Benchmark | 122B-A10B | 27B | 35B-A3B | GPT-5 mini |
| SWE-bench Verified | 72.0 | 72.4 | 69.2 | 72.0 |
| Terminal-Bench 2 | 49.4 | 41.6 | 40.5 | 31.9 |
| LiveCodeBench v6 | 78.9 | 80.7 | 74.6 | 80.5 |
Agentische Aufgaben
| Benchmark | 122B-A10B | 27B | 35B-A3B | GPT-5 mini |
| BFCL-V4 (Tool Use) | 72.2 | 68.5 | 67.3 | 55.5 |
| BrowseComp | 63.8 | 61.0 | 61.0 | 48.1 |
| TAU2-Bench | 79.5 | 79.0 | 81.2 | 69.8 |
🔑 Das Highlight: Alle drei Medium-Modelle übertreffen GPT-5 mini bei agentischen Aufgaben um 20–30 %. Bei allgemeinem Wissen und Programmierung sind sie wettbewerbsfähig oder sogar besser. Der wichtigste Unterschied liegt nicht in rohen Benchmark-Ergebnissen — sondern darin, dass Sie dieses Leistungsniveau mit offenen Gewichten, vollem Fine-Tuning-Spielraum und ohne Herstellerbindung erhalten.
Was macht es auf Novita AI besonders?
Novita AI bietet alle drei Qwen 3.5 Medium-Modelle mit offenen Gewichten über eine serverlose API mit OpenAI-kompatiblen Endpunkten an:
| Modell | Eingabe | Ausgabe | Kontext | Max. Ausgabe |
| Qwen3.5-35B-A3B | 0,25 $/Mt | 2,00 $/Mt | 262K | 65K |
| Qwen3.5-27B | 0,30 $/Mt | 2,40 $/Mt | 262K | 65K |
| Qwen3.5-122B-A10B | 0,40 $/Mt | 3,20 $/Mt | 262K | 65K |
Key advantages on Novita AI:
- OpenAI-kompatible API: Direkt einsetzbarer Ersatz — wechseln Sie von GPT-Endpunkten einfach durch Änderung der Basis-URL.
- Vollständiger 262K-Kontext: Keine Kürzung. Nutzen Sie das gesamte native Kontextfenster.
- Serverlos: Keine GPU-Bereitstellung, keine zu verwaltenden Kaltstarts.
Möchten Sie sehen, wie diese Modelle Ihre Workload verarbeiten? Öffnen Sie den Playground und führen Sie einen Test durch →
Kostenanalyse: Wie viel können Sie sparen?
Stellen Sie sich vor, Sie betreiben einen agentischen Programmierworkflow, der täglich 1M Eingabetoken verarbeitet und 200K Ausgabetoken generiert.
| Modell | Tägliche Eingabekosten | Tägliche Ausgabekosten | Tagesgesamt | Monatlich (30 Tage) |
| Qwen3.5-35B-A3B (Novita) | 0,25 $ | 0,40 $ | 0,65 $ | 19,50 $ |
| Qwen3.5-27B (Novita) | 0,30 $ | 0,48 $ | 0,78 $ | 23,40 $ |
| Qwen3.5-122B-A10B (Novita) | 0,40 $ | 0,64 $ | 1,04 $ | 31,20 $ |
| GPT-5 mini (OpenAI) | 0,25 $ | 0,40 $ | 0,65 $ | 19,50 $ |
| Claude Sonnet 4.5 (Anthropic) | 3,00 $ | 3,00 $ | 6,00 $ | 180,00 $ |
| GPT-5.2 (OpenAI) | 1,75 $ | 2,80 $ | 4,55 $ | 136,50 $ |
Preisquellen: OpenAI (GPT-5 mini: 0,25 $/Mt Eingabe, 2,00 $/Mt Ausgabe, GPT-5.2: 1,75 $/Mt Eingabe, 14,00 $/Mt Ausgabe), Anthropic (Claude Sonnet 3,00 $/Mt Eingabe, 15,00 $/Mt Ausgabe), Novita AI .
🔑 Die eigentliche Geschichte: Qwen3.5-35B-A3B auf Novita AI liegt preislich auf dem Niveau von GPT-5 mini, liefert aber eine deutlich stärkere agentische Leistung (BFCL-V4: 67,3 vs. 55,5). Im Vergleich zu GPT-5.2 und Claude Sonnet 4.5 sparen Sie 7–9× bei den Kosten. Das Wertversprechen ist nicht nur der Preis — es sind offene Gewichte zum Preis von Closed-Source-Modellen, mit besseren agentischen Fähigkeiten.
Anwendungsfälle und Best Practices
Nehmen wir an, Sie bauen einen KI-gestützten Code-Review-Agenten, der Pull Requests scannt, Probleme erkennt und Korrekturen vorschlägt. Der Agent muss gesamte Repository-Kontexte (50K–200K Token) verarbeiten, externe Tools (Linter, Test-Runner) aufrufen und strukturiertes Feedback generieren.
Hier ist, warum Qwen 3.5 Medium eine starke Wahl ist:
1. Agentische Tool-Aufruf-Pipelines
Mit einem BFCL-V4-Wert von 72,2 (122B-A10B) glänzen diese Modelle bei strukturierten Funktionsaufrufen. Erstellen Sie mehrstufige Agenten, die API-Aufrufe verketten, Antworten parsen und Entscheidungen treffen — mit einer Zuverlässigkeit, die GPT-5 mini deutlich übertrifft.
2. Langkontext-Code-Analyse
Das 262K große native Kontextfenster bedeutet, dass Sie gesamte Codebasen ohne Aufteilung in Chunks füttern können. Die hybride Aufmerksamkeitsarchitektur hält die Kosten selbst bei hohen Token-Zahlen überschaubar.
3. Flexibilität durch offene Gewichte
Im Gegensatz zu GPT-5 mini können Sie Qwen 3.5 Medium mit Ihren eigenen Daten fine-tunen, es für Compliance-Anforderungen On-Premise bereitstellen oder quantisierte Versionen lokal auf Consumer-GPUs ausführen (das 35B-A3B läuft mit 4-Bit-Quantisierung auf 8GB+ VRAM).
Welches Modell sollten Sie wählen?
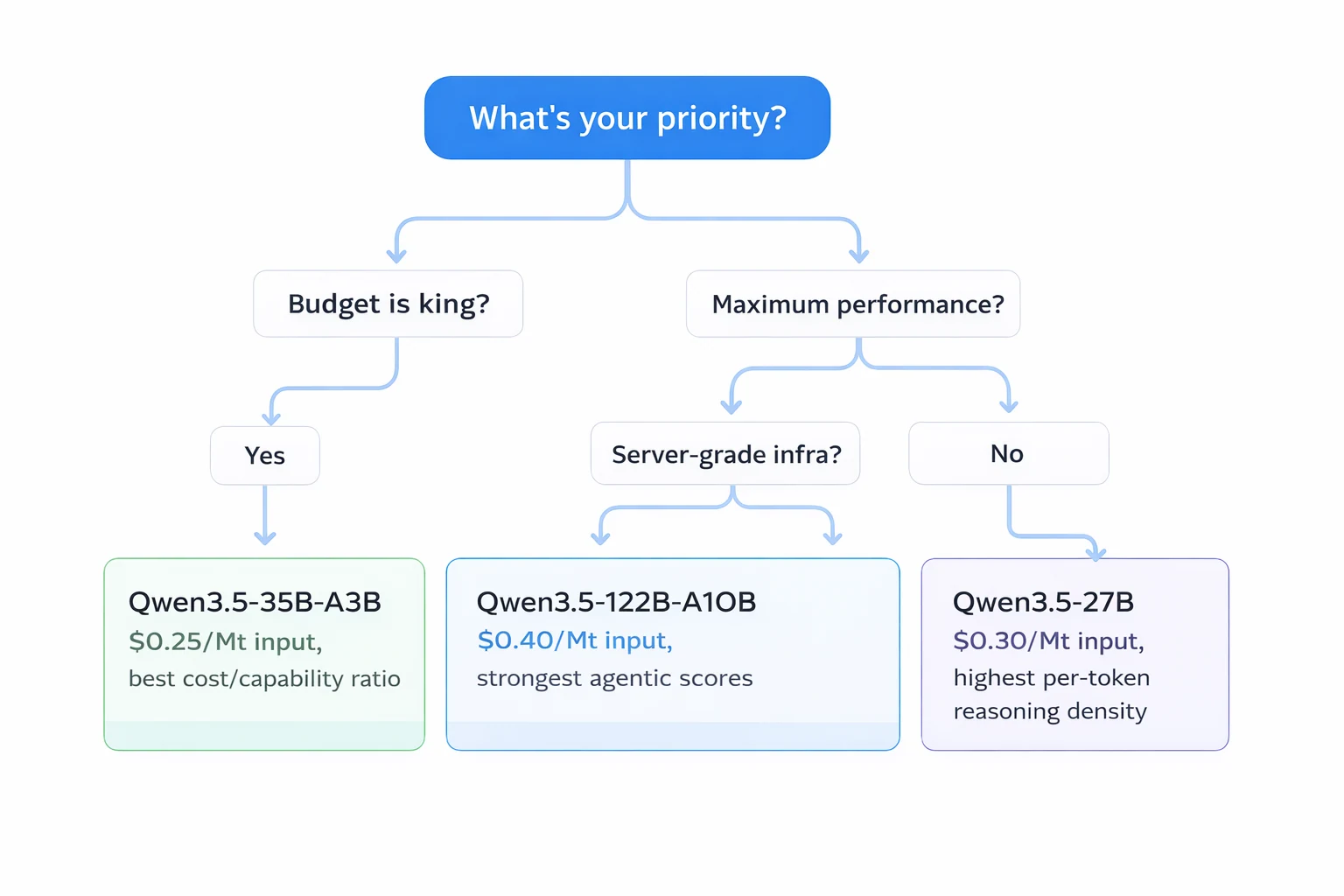
Kurzanleitung:
- Qwen3.5-35B-A3B → Beste Gesamtwahl. Geringste Kosten, läuft lokal auf Consumer-GPUs (8GB+ VRAM mit Quantisierung) und schlägt GPT-5 mini in den meisten Benchmarks noch immer.
- Qwen3.5-27B → Höchste Schlussfolgerungsdichte pro Token (alle 27B Parameter aktiv). Bester SWE-bench-Wert (72,4) der Reihe. Ideal, wenn Sie maximale Schlussfolgerung pro Vorwärtsdurchlauf benötigen.
- Qwen3.5-122B-A10B → Spitzenwerte bei agentischen Aufgaben in allen Bereichen. Am besten geeignet für komplexe mehrstufige Agentenworkflows, bei denen die Genauigkeit von Tool-Aufrufen kritisch ist.
So legen Sie los
Novita AI bietet mehrere Möglichkeiten, die Qwen 3.5 Medium-Modelle in Ihren Workflow zu integrieren — von der Code-freien Erkundung bis zur Produktions-API-Integration.
Testen Sie es im Playground
Bevor Sie Code schreiben, testen Sie die Modelle interaktiv im Novita AI Playground:
- Schalten Sie den Denkmodus ein, um die interne Schlussfolgerungskette des Modells zu sehen.
- Passen Sie Parameter an: Temperatur und Top_p zur Steuerung der Ausgabekreativität.
- Stresstest für Langkontext: Fügen Sie Dokumente mit bis zu 262K Token ein, um Abruf und Verständnis zu evaluieren.
Neue Benutzer, die sich für ein Novita AI-Konto anmelden, erhalten kostenlose Testguthaben — genug, um Dutzende von Tests kostenlos durchzuführen.
Schritt 1: Holen Sie sich Ihren API-Schlüssel
- Besuchen Sie novita.ai und registrieren Sie sich oder melden Sie sich an.
- Navigieren Sie im Dashboard zu API-Schlüsseln.
- Klicken Sie auf Neuen Schlüssel hinzufügen und kopieren Sie ihn sofort — der Schlüssel wird nur einmal angezeigt.
Schritt 2: Rufen Sie die API auf
- Basis-URL:
https://api.novita.ai/openai - Modell-IDs:
qwen/qwen3.5-35b-a3b,qwen/qwen3.5-27b,qwen/qwen3.5-122b-a10b
Python-Beispiel:
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3.5-122b-a10b",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].message.content)
Schritt 3: Integrieren Sie es in Ihre Tools
Da Novita AI dem OpenAI-/Anthropic-API-Standard folgt, funktionieren Qwen 3.5 Medium-Modelle nahtlos mit den Tools, die Sie bereits nutzen:
- Programmierassistenten: Cline, Cursor, OpenCode, Trae
- Agenten-Frameworks: LangChain, Langflow, Continue
- Anthropic-kompatible Workflows: Claude Code
- Chat-Oberflächen: AnythingLLM
- Hugging Face Hub: Novita AI ist als Inferenzanbieter für unterstützte Modelle gelistet.
- Persönliche KI-Agenten: OpenClaw — verbinden Sie Qwen 3.5 Medium-Modelle, um durchgehend aktive Agenten über Messaging-Plattformen hinweg aufzubauen.
Fazit
Vor einem Jahr war es noch nicht realistisch, agentische Leistung auf dem Niveau von GPT-5 mini von einem Open-Weight-Modell zu erhalten, das Sie fine-tunen und selbst hosten können. Die Qwen 3.5 Medium-Reihe ändert diese Gleichung, insbesondere bei der Tool-Nutzung und mehrstufigen Agentenworkflows, wo diese Modelle proprietäre Alternativen nicht nur erreichen, sondern messbar übertreffen.
Für Teams, die ihren Modell-Stack evaluieren, ist der praktische nächste Schritt einfach: führen Sie Ihre eigenen Prompts im Playground aus, benchmarken Sie sie gegen Ihren aktuellen Anbieter und entscheiden Sie auf Basis Ihrer Daten — nicht unserer.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud zum Erstellen und Skalieren von Anwendungen zur Verfügung stellt.
Häufig gestellte Fragen
Was ist der Unterschied zwischen Qwen3.5-Flash und Qwen3.5-35B-A3B?
Qwen3.5-Flash ist die proprietäre gehostete Version des 35B-A3B, die nur über Alibaba Cloud verfügbar ist. Sie bietet ein 1M-Kontextfenster und integrierte offizielle Tools. Das offene 35B-A3B auf Novita AI unterstützt nativ 262K Kontext und ist auf bis zu 1M Token erweiterbar.
Kann ich diese Modelle für kommerzielle Anwendungen nutzen?
Ja. Alle drei Modelle mit offenen Gewichten werden unter der Apache-2.0-Lizenz veröffentlicht — keine Einschränkungen bei kommerzieller Nutzung, Fine-Tuning oder Weiterverbreitung.
Wie schneiden diese im Vergleich zum Flaggschiff Qwen3.5-397B-A17B ab?
Das 397B-Flaggschiff (ebenfalls auf Novita AI verfügbar für 0,60 $/Mt Eingabe, 3,60 $/Mt Ausgabe) ist stärker bei Wettbewerbsprogrammierung und einigen Schlussfolgerungsaufgaben. Aber die Medium-Modelle sind überraschend nah dran — das 122B-A10B erreicht oder übertrifft es bei agentischen Benchmarks, und das 35B-A3B liefert 85–95 % der Leistung des Flaggschiffs zu weniger als der Hälfte der Kosten.



