

Серия моделей Qwen 3.5 Medium от Alibaba приносит передовые возможности рассуждения в открытые модели, которые вы можете себе позволить запускать в промышленной эксплуатации. Три модели — Qwen3.5-35B-A3B, Qwen3.5-27B и Qwen3.5-122B-A10B — уже доступны на Novita AI, предлагая производительность уровня GPT-5-mini с гибкостью открытых весов и лицензией Apache 2.0.
🎉Все три модели уже доступны через бессерверный API LLM Novita AI — не требуется выделение GPU.
Попробовать Qwen3.5-35B-A3B сейчас!
Что такое серия Qwen 3.5 Medium?
24 февраля 2026 года команда Qwen от Alibaba выпустила серию моделей Qwen 3.5 Medium — четыре модели, которые занимают позицию между флагманской Qwen3.5-397B-A17B и меньшими дистиллированными вариантами. Три из них имеют открытые веса по лицензии Apache 2.0, и все три уже доступны на Novita AI.
Серия ориентирована на конкретный пробел на рынке: модели, достаточно компактные для чувствительных к стоимости производственных рабочих нагрузок, но при этом достаточно мощные, чтобы конкурировать с проприетарными передовыми моделями, такими как GPT-5 mini и Claude Sonnet 4.5.
| Модель | Всего параметров | Активные параметры | Архитектура | Контекст |
| Qwen3.5-35B-A3B | 35B | 3B | MoE + гибридное внимание | 262K |
| Qwen3.5-27B | 27B | 27B (плотная) | Плотная + гибридное внимание | 262K |
| Qwen3.5-122B-A10B | 122B | 10B | MoE + гибридное внимание | 262K |
Производительность в бенчмарках
Модели Qwen 3.5 Medium показывают производительность значительно выше своего класса. Вот как они сравниваются с GPT-5 mini по ключевым категориям (данные из официальных результатов бенчмарков Qwen):
Знания и рассуждение
| Бенчмарк | 122B-A10B | 27B | 35B-A3B | GPT-5 mini |
| MMLU-Pro | 86.7 | 86.1 | 85.3 | 83.7 |
| GPQA Diamond | 86.6 | 85.5 | 84.2 | 82.8 |
| MMMLU | 86.7 | 85.9 | 85.2 | 86.2 |
| HMMT Feb 2025 | 91.4 | 92.0 | 89.0 | 89.2 |
Программирование
| Бенчмарк | 122B-A10B | 27B | 35B-A3B | GPT-5 mini |
| SWE-bench Verified | 72.0 | 72.4 | 69.2 | 72.0 |
| Terminal-Bench 2 | 49.4 | 41.6 | 40.5 | 31.9 |
| LiveCodeBench v6 | 78.9 | 80.7 | 74.6 | 80.5 |
Агентные задачи
| Бенчмарк | 122B-A10B | 27B | 35B-A3B | GPT-5 mini |
| BFCL-V4 (Использование инструментов) | 72.2 | 68.5 | 67.3 | 55.5 |
| BrowseComp | 63.8 | 61.0 | 61.0 | 48.1 |
| TAU2-Bench | 79.5 | 79.0 | 81.2 | 69.8 |
🔑 Главное преимущество: Все три модели Medium превосходят GPT-5 mini на агентных задачах на 20–30%. По общим знаниям и программированию они не уступают или даже опережают его. Ключевое отличие — не сырые баллы в бенчмарках, а то, что вы получаете такой уровень производительности с открытыми весами, свободой для дообучения и отсутствием привязки к поставщику.
Что делает эти модели особенными на Novita AI
Novita AI предлагает все три открытые модели Qwen 3.5 Medium через бессерверный API с совместимыми с OpenAI конечными точками:
| Модель | Ввод | Вывод | Контекст | Макс. вывод |
| Qwen3.5-35B-A3B | $0.25/Mt | $2.00/Mt | 262K | 65K |
| Qwen3.5-27B | $0.30/Mt | $2.40/Mt | 262K | 65K |
| Qwen3.5-122B-A10B | $0.40/Mt | $3.20/Mt | 262K | 65K |
Ключевые преимущества на Novita AI:
- Совместимый с OpenAI API: Готовая замена — переключитесь с конечных точек GPT, изменив только базовый URL.
- Полный контекст 262K: Без обрезки. Используйте всё нативное окно контекста.
- Бессерверный: Не нужно выделять GPU, не нужно управлять холодными запусками.
Хотите увидеть, как эти модели справляются с вашими рабочими нагрузками? Откройте Playground и запустите тест →
Анализ стоимости: сколько вы можете сэкономить?
Представьте, что вы запускаете агентный рабочий процесс программирования, который обрабатывает 1 млн входных токенов и генерирует 200 тыс. выходных токенов в день.
| Модель | Ежедневная стоимость ввода | Ежедневная стоимость вывода | Итого за день | За месяц (30 дней) |
| Qwen3.5-35B-A3B (Novita) | $0.25 | $0.40 | $0.65 | $19.50 |
| Qwen3.5-27B (Novita) | $0.30 | $0.48 | $0.78 | $23.40 |
| Qwen3.5-122B-A10B (Novita) | $0.40 | $0.64 | $1.04 | $31.20 |
| GPT-5 mini (OpenAI) | $0.25 | $0.40 | $0.65 | $19.50 |
| Claude Sonnet 4.5 (Anthropic) | $3.00 | $3.00 | $6.00 | $180.00 |
| GPT-5.2 (OpenAI) | $1.75 | $2.80 | $4.55 | $136.50 |
Источники цен: OpenAI (GPT-5 mini: $0.25 за 1М ввод, $2.00 за 1М вывод, GPT-5.2: $1.75 за 1М ввод, $14.00 за 1М вывод), Anthropic (Claude Sonnet $3.00 за 1М ввод, $15.00 за 1М вывод), Novita AI .
🔑 Реальная история: Qwen3.5-35B-A3B на Novita AI соответствует ценовому уровню GPT-5 mini, но при этом обеспечивает значительно более высокую агентную производительность (BFCL-V4: 67.3 против 55.5). По сравнению с GPT-5.2 и Claude Sonnet 4.5 вы экономите 7–9 раз по стоимости. Ценностное предложение — не только цена, а открытые веса по цене закрытой модели с лучшими агентными возможностями.
Сценарии использования и лучшие практики
Допустим, вы создаете агент для ревью кода на базе ИИ, который сканирует пул-реквесты, выявляет проблемы и предлагает исправления. Агенту нужно обрабатывать контекст целых репозиториев (50K–200K токенов), вызывать внешние инструменты (линтеры, запускатели тестов) и генерировать структурированную обратную связь.
1. Агентные конвейеры вызова инструментов
С баллом BFCL-V4 72.2 (122B-A10B) эти модели отлично справляются со структурированным вызовом функций. Создавайте многошаговых агентов, которые объединяют вызовы API, разбирают ответы и принимают решения — с надежностью, значительно превышающей GPT-5 mini.
2. Анализ кода с длинным контекстом
Нативное окно контекста 262K означает, что вы можете загружать целые кодовые базы без разбиения на фрагменты. Архитектура с гибридным вниманием сохраняет затраты управляемыми даже при большом количестве токенов.
3. Гибкость открытых весов
В отличие от GPT-5 mini, вы можете дообучить Qwen 3.5 Medium на своих данных, развернуть его на локальном оборудовании для соответствия требованиям compliance или запускать квантованные версии локально на потребительских GPU (модель 35B-A3B работает на 8GB+ VRAM с 4-битным квантованием).
Какую модель выбрать?
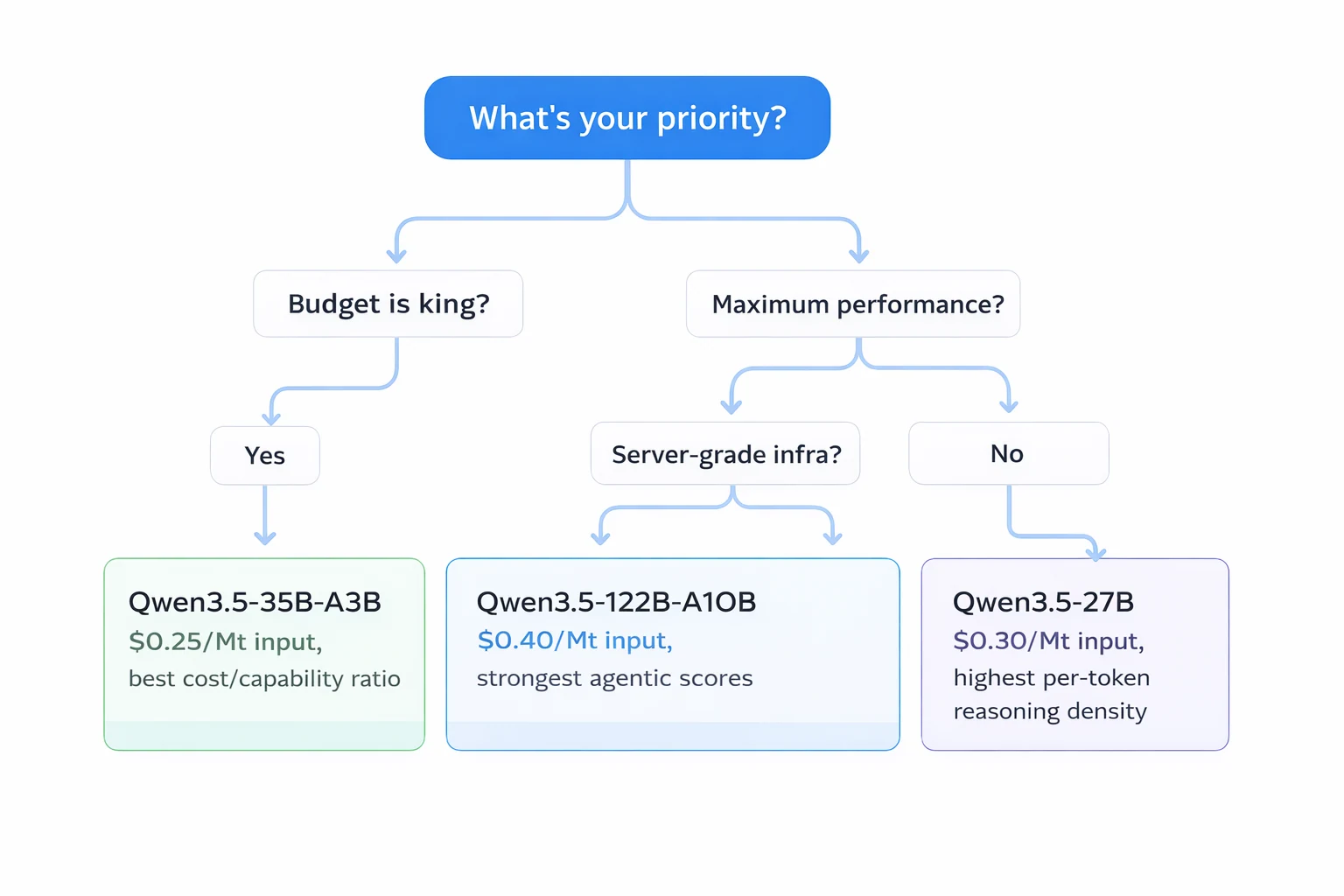
Краткое руководство:
- Qwen3.5-35B-A3B → Лучший выбор в целом. Самая низкая стоимость, работает локально на потребительских GPU (8GB+ VRAM с квантованием) и все равно превосходит GPT-5 mini в большинстве бенчмарков.
- Qwen3.5-27B → Наибольшая плотность рассуждений на токен (все 27B параметров активны). Лучший балл SWE-bench (72.4) в серии. Идеально, когда вам нужно максимальное количество рассуждений на прямой проход.
- Qwen3.5-122B-A10B → Лучшие агентные баллы по всем категориям. Идеально для сложных многошаговых агентных рабочих процессов, где критически важна точность вызова инструментов.
Как начать работу
Novita AI предлагает несколько способов интегрировать модели Qwen 3.5 Medium в ваш рабочий процесс — от исследования без написания кода до интеграции с производственным API.
Попробуйте в Playground
Прежде чем писать какой-либо код, протестируйте модели интерактивно в Playground Novita AI:
- Включите режим рассуждений, чтобы увидеть внутреннюю цепочку рассуждений модели.
- Настройте параметры: Температура и Top_p для управления креативностью вывода.
- Стресс-тест длинного контекста: Вставьте документы объемом до 262K токенов, чтобы оценить способность к запоминанию и пониманию.
Новые пользователи, регистрирующие аккаунт Novita AI, получают бесплатные пробные кредиты — их хватает на десятки тестов без затрат.
Шаг 1: Получите ваш API-ключ
- Перейдите на novita.ai и зарегистрируйтесь или войдите в аккаунт.
- Перейдите в раздел API-ключи в панели управления.
- Нажмите Добавить новый ключ и скопируйте его сразу — ключ отображается только один раз.
Шаг 2: Вызовите API
- Базовый URL:
https://api.novita.ai/openai - Идентификаторы моделей:
qwen/qwen3.5-35b-a3b,qwen/qwen3.5-27b,qwen/qwen3.5-122b-a10b
Пример на Python:
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3.5-122b-a10b",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].message.content)
Шаг 3: Интегрируйте с вашими инструментами
Поскольку Novita AI следует стандарту API OpenAI/Anthropic, модели Qwen 3.5 Medium без проблем работают с инструментами, которые вы уже используете:
- Ассистенты программирования: Cline, Cursor, OpenCode, Trae
- Агентные фреймворки: LangChain, Langflow, Continue
- Рабочие процессы, совместимые с Anthropic: Claude Code
- Чат-интерфейсы: AnythingLLM
- Hugging Face Hub: Novita AI указан как провайдер инференса для поддерживаемых моделей.
- Персональные ИИ-агенты: OpenClaw — подключайте модели Qwen 3.5 Medium для создания постоянно активных агентов для мессенджеров.
Заключение
Год назад получить агентную производительность уровня GPT-5-mini от открытой модели, которую можно дообучить и развернуть на своем оборудовании, было нереалистично. Серия Qwen 3.5 Medium меняет это уравнение, особенно в части использования инструментов и многошаговых агентных рабочих процессов, где эти модели не просто соответствуют проприетарным аналогам, но и измеримо их превосходят.
Для команд, которые оценивают свой стек моделей, практический следующий шаг прост: запустите свои собственные промпты в Playground, сравните с текущим провайдером по бенчмаркам и примите решение на основе ваших данных, а не наших.
Novita AI — это облачная ИИ-платформа, которая предлагает разработчикам простой способ развертывать ИИ-модели с помощью нашего простого API, а также предоставляет доступное и надежное облако GPU для разработки и масштабирования.
Часто задаваемые вопросы
В чем разница между Qwen3.5-Flash и Qwen3.5-35B-A3B?
Qwen3.5-Flash — это проприетарная размещенная версия 35B-A3B, доступная только через Alibaba Cloud. Она предлагает окно контекста 1M и встроенные официальные инструменты. Открытая версия 35B-A3B на Novita AI поддерживает нативное окно контекста 262K и может быть расширена до 1M токенов.
Можно ли использовать эти модели для коммерческих приложений?
Да. Все три открытые модели выпущены по лицензии Apache 2.0 — нет ограничений на коммерческое использование, дообучение или распространение.
Как они сравниваются с флагманской моделью Qwen3.5-397B-A17B?
Флагманская модель 397B (также доступна на Novita AI по $0.60 за 1М ввод, $3.60 за 1М вывод) сильнее в соревновательном программировании и некоторых задачах на рассуждение. Но модели Medium удивительно близки к ней — 122B-A10B соответствует или превосходит ее в агентных бенчмарках, а 35B-A3B обеспечивает 85–95% производительности флагмана при стоимости менее чем в два раза ниже.



