

MiniMax M2.7 現在已在 Novita AI 上線,為您帶來生產級 AI 代理能力,兼具卓越成本效益。這款自我進化推理模型達到 50 的智能指數(與 GLM-5 相當),但運行成本卻低了 3 倍。憑藉 97% 的技能遵循率(跨越 40 多種複雜工具)、原生代理團隊支援,以及業界領先的真實任務表現(GDPval-AA Elo 1495),M2.7 專為需要可靠代理式 AI 卻不想負擔高昂成本的開發者而生。
價格:輸入 $0.3/Mt,輸出 $1.2/Mt(快取讀取 $0.06/Mt) 上下文視窗:204,800 tokens
挑戰:建構可靠 AI 代理仍然太難
大多數大型語言模型都號稱具備「代理能力」,但實際部署卻完全是另一回事:
- 工具呼叫失敗:模型誤解函式簽名、跳過必要參數,或幻覺出不存在的工具
- 上下文崩潰:長時間運行的代理工作階段達到 token 限制,或在任務中途遺失關鍵上下文
- 執行不可靠:演示時運作良好,但在生產環境中同時處理 40 多項技能時卻失敗
- 成本飆升:像 Claude Opus 4.6 或 GPT-5.4 這樣的前沿推理模型,運行成本迅速累積
你需要的是在生產代理系統中真正能運作的模型,而不是只在基準測試中表現亮眼的模型。
解決方案:MiniMax M2.7 的自我進化架構
MiniMax M2.7 是該公司首個參與自身開發過程的模型——它實際除錯了自身的訓練流程、建構了評估工具,並優化了自己的框架。這個自我進化循環產生了一個特別適合真實代理任務的模型。
M2.7 與眾不同之處
1. 生產級軟體工程
M2.7 不只是寫程式碼——它還能對線上系統進行除錯。當生產告警觸發時,它會關聯監控指標與部署時間軸、執行統計跡線分析、連線資料庫驗證假設、找出遺漏的索引遷移檔案,並且知道在提交修復之前使用非阻塞索引創建來止血。
2. 原生代理團隊支援
與那些透過提示模擬多代理工作流程的模型不同,M2.7 在模型層級就內建了角色邊界、對抗性推理和行為差異化。它能:
- 在多代理場景中穩定錨定自身角色身份
- 主動挑戰隊友的邏輯盲點
- 在複雜狀態機中做出自主決策
3. 97% 技能遵循率
大多數模型在處理超過少數工具時就會崩潰。M2.7 即使在擁有 40 多種複雜技能(每種超過 2,000 tokens)的情況下,仍能維持 97% 的技能遵循準確率。它理解冗長複雜的函式定義,並能在長時間互動中正確使用它們。
4. 專業工作空間卓越表現
- GDPval-AA Elo:1495(開源模型最高,領先 MiMo-V2-Pro 和 Kimi K2.5)
- 高保真 Office 編輯:Excel、PowerPoint 和 Word 中的多輪修訂
- 真實任務:閱讀年度報告、設計營收模型、從範本生成 PPT——就像一位能透過反饋自我修正的初級分析師
5. 具備情緒智商的智慧
M2.7 打破了「冰冷工具」的刻板印象,具備高情商和一致的角色個性,能實現超越純生產力任務的自然人性化互動。
技術規格與效能
技術規格
| 參數 | 數值 |
|---|---|
| 上下文視窗 | 204,800 tokens |
| 最大輸出 | 131,072 tokens |
| 量化 | FP8 |
| 輸入模態 | 文字 |
| 輸出模態 | 文字 |
| 支援功能 | 工具、JSON 模式、結構化輸出、推理 |
| 取樣參數 | temperature, top_p, top_k, repetition_penalty, frequency_penalty, presence_penalty, stop, seed |
基準測試表現總覽
MiniMax M2.7 在真實代理任務中展現領先表現,在關鍵基準測試中超越或媲美前沿模型:
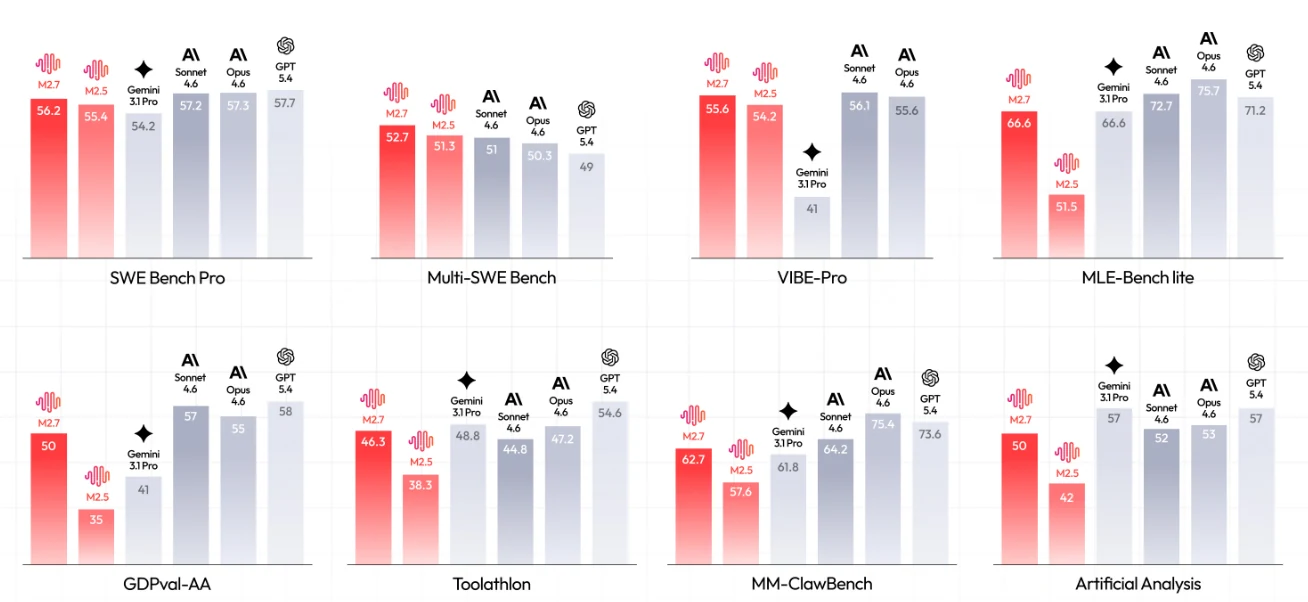
M2.7(紅色長條)與競爭模型在 8 項關鍵基準測試中的比較。[來源:MiniMax 官方]
關鍵洞察:
- SWE 能力:SWE Bench Pro 上 56.2%,接近前沿模型(GPT-5.4 為 57.7%)
- 多語言優勢:Multi-SWE Bench 上 52.7%,超越所有競爭對手,包括 GPT-5.4(49)
- ML 自動化:MLE-Bench lite 上 66.6%,與 Gemini 3.1 Pro 持平,僅次於 Opus 4.6(75.7%)和 GPT-5.4(71.2%)
- 代理卓越表現:GDPval-AA 智能指數 50,與該基準測試的生產就緒性能基線持平
智能 vs. 成本:最佳等級效率
M2.7 的突出之處不僅在於效能,更在於以極低成本提供前沿等級的智能:
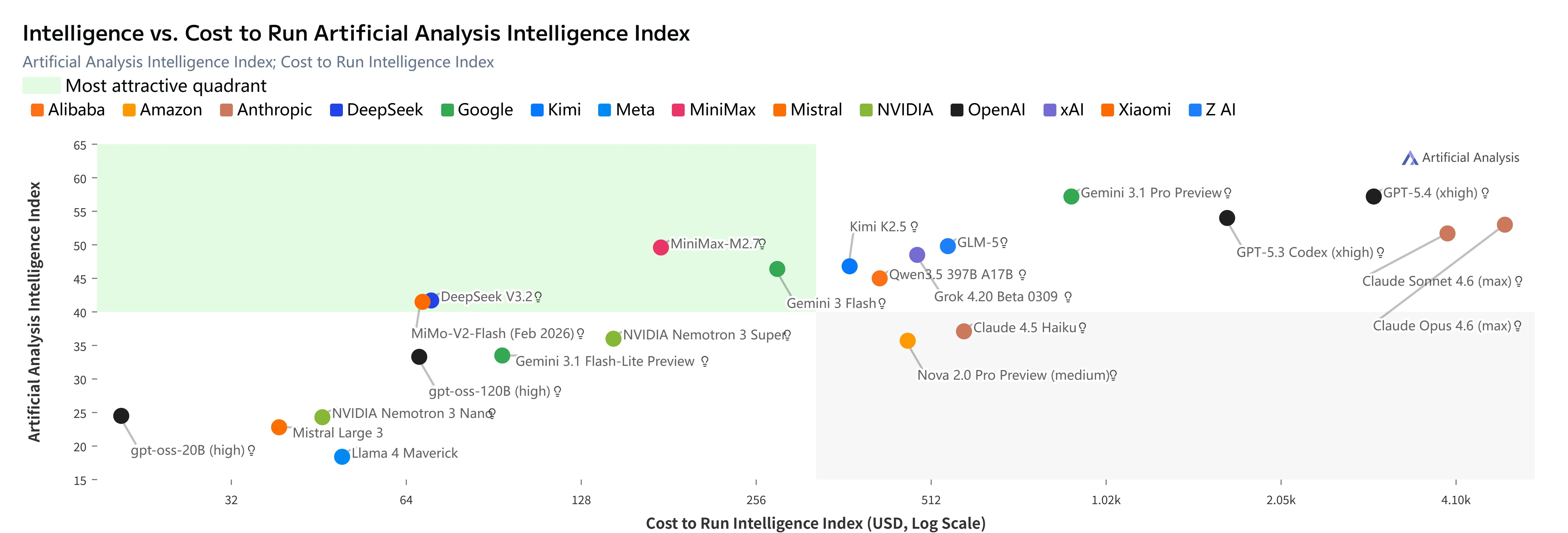
MiniMax M2.7(紅點)位於 Artificial Analysis 智能指數 vs. 成本的「最具吸引力象限」中。[來源:Artificial Analysis]
關鍵洞察:
- GLM-5 等級智能,成本幾乎低了 2/3
- 比 Kimi K2.5 便宜 3 倍,智能卻更高
- 比 Claude Opus 4.6 便宜 23 倍,智能差距僅 5 點
- 在所有 Index ≥47 的模型中,每智能點成本最低
幻覺緩解
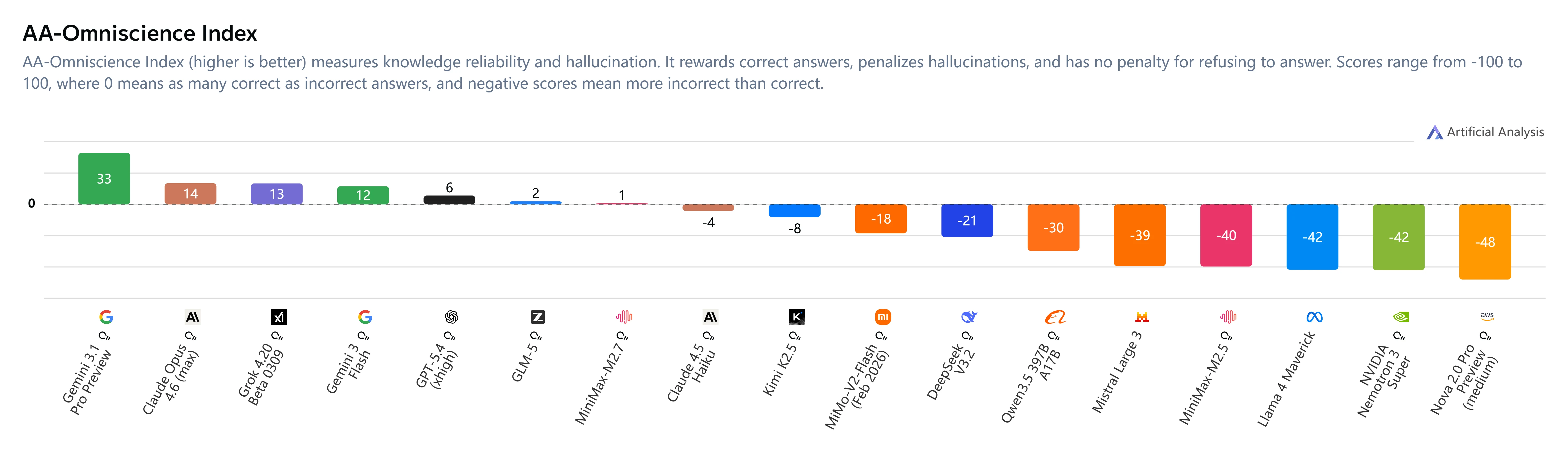
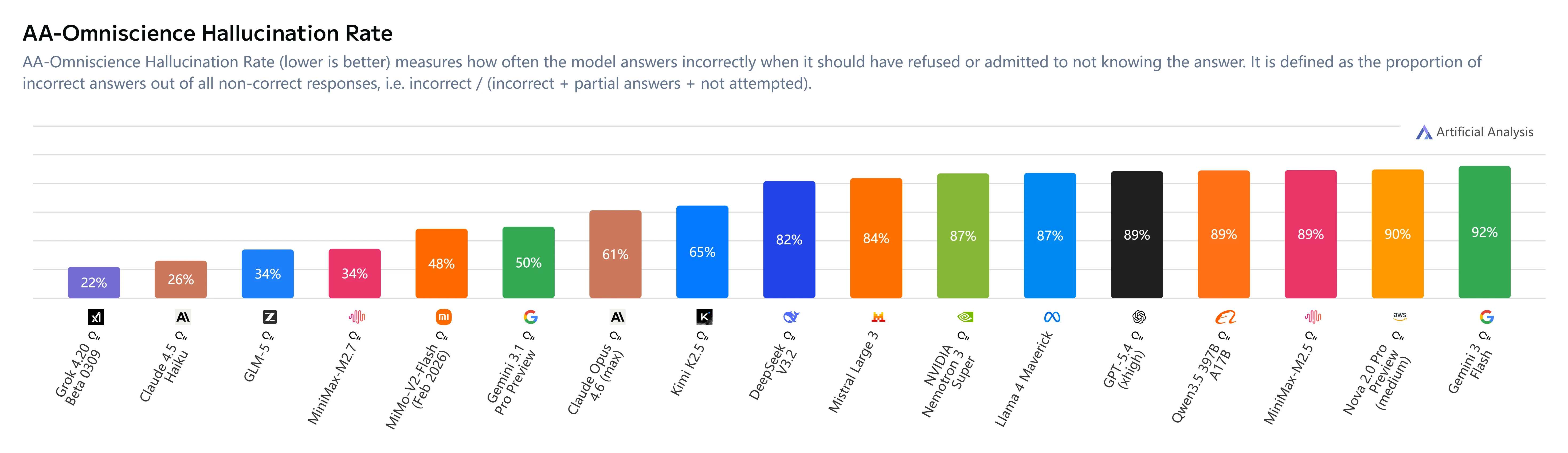
關鍵洞察:
- AA-Omniscience Index:+1(從 M2.5 的 -40 提升)
- 幻覺率:34%(低於 Claude Sonnet 4.6 的 46% 和 Gemini 3.1 Pro 的 50%)
- 行為改變:MiniMax M2.7 在不確定時會選擇棄權而非猜測,大幅提升可靠性
Novita AI 上的定價
| 參數 | MiniMax M2.7 | GLM-5 | Kimi K2.5 |
|---|---|---|---|
| 輸入 | $0.3/Mt | $1.0/Mt | $0.6/Mt |
| 輸出 | $1.2/Mt | $3.2/Mt | $3.0/Mt |
| 快取讀取 | $0.06/Mt | $0.2/Mt | $0.1/Mt |
| 上下文視窗 | 204,800 tokens | 202,800 tokens | 262,144 tokens |
為何選擇 Novita AI 來使用 MiniMax M2.7?
- 具競爭力的定價:輸入 $0.3/Mt,低於其他平台的費率
- 提示快取:重複上下文可節省 80% 成本,快取讀取僅 $0.06/Mt
- 無伺服器部署:無需管理基礎設施
- 統一 API:與 OpenAI 相容的端點——一行程式碼即可切換模型
- 全球邊緣網路:來自美國資料中心的低延遲推理
如何在 Novita AI 上開始使用 MiniMax M2.7
前置準備
- 建立一個 Novita AI 帳戶(免費註冊)
- 取得 API 金鑰
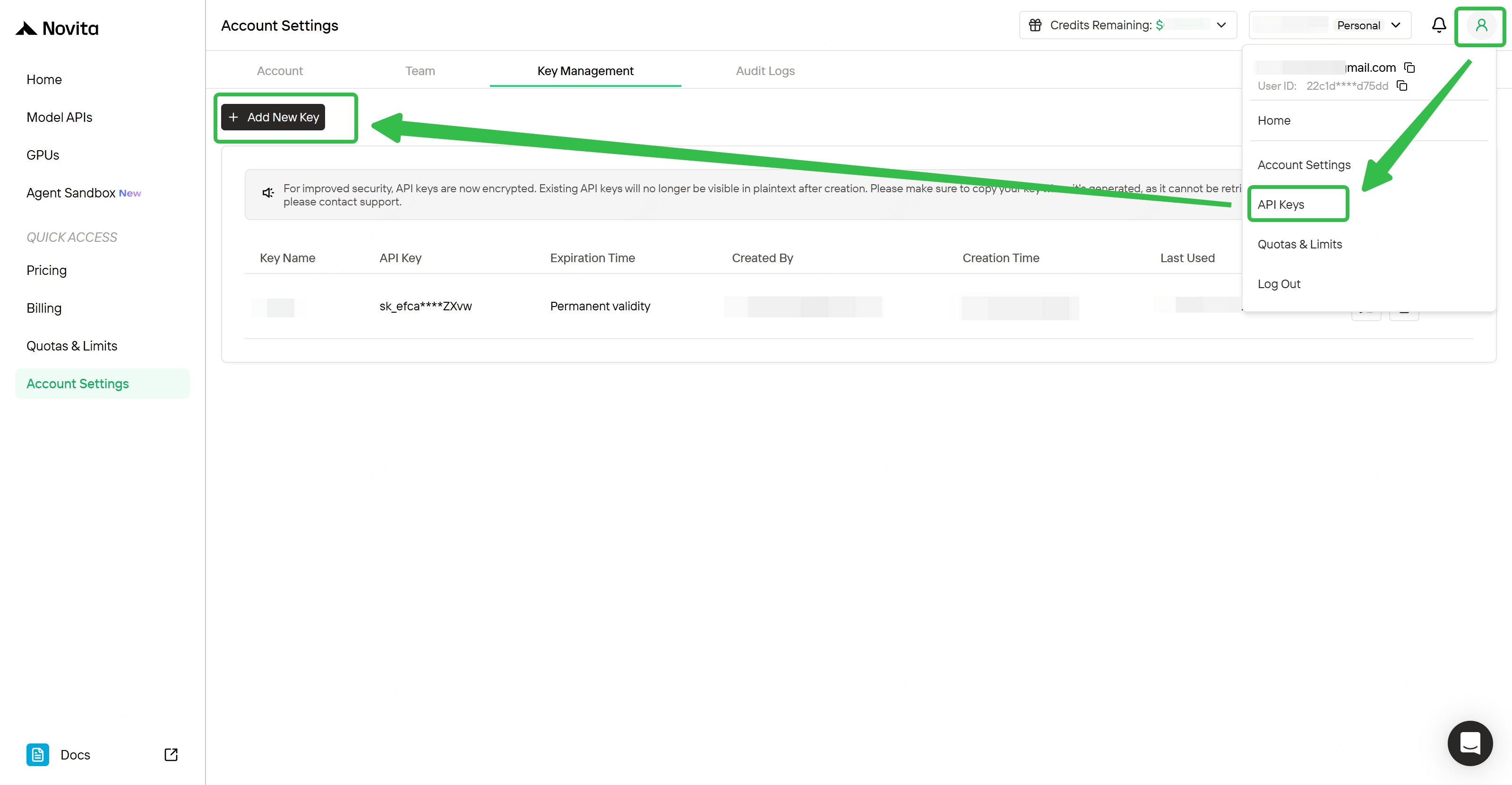
如何取得 API 金鑰
API 使用方式(Python)
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="minimax/minimax-m2.7",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
MiniMax M2.7 能做什麼:真實應用展示
MiniMax M2.7 在多個領域擅長執行複雜、生產就緒的任務:
全端網站開發:一次性生成完整的網站,具備互動功能、響應式佈局和實用的 UI 組件——從音樂庫到電子商務平台。
生產除錯與 SRE:透過自動化日誌分析、資料庫驗證和主動修復部署,實現 3 分鐘內的事件恢復。M2.7 能自主處理根因分析、非阻塞遷移和安全稽核。
自主軟體開發:從需求到部署,交付端到端專案(Web、Android、iOS)。包括多檔案重構、ML 實驗自動化和自我改進——M2.7 透過迭代除錯將其自身訓練優化了 30%。
專業辦公室自動化:閱讀年度報告、設計財務模型、生成 PPT——全部支援 Excel、PowerPoint 和 Word 的多輪編輯。非常適合研究報告和複雜數據工作流程。
AI 原生應用:透過 OpenAI/Anthropic 相容 API 與 OpenClaw、Claude Code、Cursor 及其他代理框架無縫整合。非常需要 97% 工具遵循率的客服機器人、研究助手和創意工具。
結論
MiniMax M2.7 以前沿推理模型的一小部分成本,為開發者帶來生產級 AI 代理能力。憑藉 97% 的工具遵循率、原生代理團隊支援,以及在 8 項關鍵基準測試中的卓越真實表現,它專為可靠的代理部署而建——不只是用來展示。
在 Novita AI 上,輸入僅 $0.3/Mt 且輸出僅 $1.2/Mt,M2.7 以 GLM-5 三分之一的價格提供了具競爭力的智能。無論你正在建構 SRE 自動化、全端網站專案、專業工作空間工具,還是 AI 驅動的開發環境,M2.7 都是一個具成本效益且經過實戰考驗的選擇。
👉立即開始: 在 Novita AI 上試用 MiniMax M2.7
Novita AI 是一個 AI 雲端平台,為開發者提供使用簡單 API 部署 AI 模型的簡便方式,同時也提供經濟實惠且可靠的 GPU 雲端來建構和擴展系統。
常見問題
M2.7 與 M2.5 之間的差異是什麼?
M2.7 在所有基準測試上都優於 M2.5:(1) SWE Bench Pro:+4 分(52.2 → 56.2),(2) GDPval-AA:+15 分(35 → 50),(3) MLE-Bench lite:+35 分(31.5 → 66.6),以及 (4) 幻覺率從 AA-Omniscience Index 的 -40 降至 +1。M2.7 也是首個透過自我進化訓練的 MiniMax 模型。
M2.7 是否支援視覺或音訊輸入?
目前還不支援。當前版本(M2.7)僅限文字。MiniMax 有各自的多模態模型(Hailuo 用於影片,Speech 用於音訊),但 M2.7 專注於文字推理和代理執行。
97% 的技能遵循率在實際中如何運作?
M2.7 經過訓練,即使在長時間、複雜的工作階段中也能維持角色邊界和工具協議遵循。在對 40 多種工具(每種 >2,000 tokens)的測試中,它以正確參數正確呼叫函式的比例達到 97%——遠高於那些隨著工具增加而效能下降的模型。
推薦文章
Qwen 3.5 Medium 模型系列在 Novita AI 上:以極低成本獲得前沿智能
三個新的 Qwen 3.5 Medium 模型為 Novita AI 帶來前沿等級的代理推理能力——開放權重、262K 上下文,準備好用於生產環境。探索這些模型如何以極低成本提供 GPT-4 等級的效能。
建構具成本效益的 AI 代理:透過 Novita AI 在 OpenClaw 中使用 MiniMax M2.5
將 MiniMax M2.5 整合到 OpenClaw (Clawdbolt) 並搭配 Novita AI。透過這份逐步指南,在幾分鐘內建構可擴展、具成本效益的 AI 代理,實現多通道代理部署。
優化 GLM4-MoE 以用於生產環境:使用 SGLang 將 TTFT 加快 65%
了解 Novita AI 如何使用 SGLang 優化 GLM 4.7 以用於生產環境,將首個 token 時間加快 65%。對於大規模部署 MoE 模型至關重要的讀物。



