

MiniMax M2.7がNovita AIで利用可能になり、本番グレードのAIエージェント機能を驚異的な費用対効果で提供します。この自己進化型推論モデルは、インテリジェンス指数50(GLM-5と同等)を達成しながら、実行コストは3分の1以下です。40以上の複雑なツールで97%のスキル遵守率、ネイティブのAgent Teamsサポート、業界をリードする実世界タスクのパフォーマンス(GDPval-AA Elo 1495)を備えたM2.7は、予算を抑えつつ信頼性の高いエージェント型AIを必要とする開発者向けに設計されています。
価格:入力0.3ドル/Mt、出力1.2ドル/Mt(キャッシュ読み取り0.06ドル/Mt) コンテキストウィンドウ:204,800トークン
課題:信頼できるAIエージェントの構築は依然として難しい
多くの大規模言語モデルは「エージェント能力」を謳っていますが、実際の導入では別のストーリーが待っています:
- ツール呼び出しの失敗:関数シグネチャの誤解、必須パラメータの省略、存在しないツールの幻覚
- コンテキストの崩壊:長時間のエージェントセッションがトークン制限に達するか、タスク途中で重要なコンテキストを喪失
- 信頼性の低い実行:デモではうまくいくが、40以上のスキルを同時に扱う本番環境で失敗
- コストの高騰:Claude Opus 4.6やGPT-5.4のような最先端推論モデルの実行コストはすぐに膨らむ
ベンチマークで良いスコアを出すだけでなく、本番エージェントシステムで実際に動作するモデルが必要なのです。
解決策:MiniMax M2.7の自己進化アーキテクチャ
MiniMax M2.7は、自らの開発に参加した同社初のモデルです。文字通り、トレーニングプロセスのデバッグ、評価フレームワークの構築、独自のスキャフォールディングの最適化を行いました。この自己進化ループにより、実世界のエージェントタスクに特に適したモデルが生まれました。
M2.7の違いとは
1. 本番対応のソフトウェアエンジニアリング
M2.7はコードを書くだけでなく、ライブシステムのデバッグも行います。本番アラートが発生すると、監視メトリクスとデプロイメントタイムラインを相関させ、統計的トレース分析を実行し、データベースに接続して仮説を検証し、不足しているインデックスマイグレーションファイルを特定し、ノンブロッキングなインデックス作成を使用して修正を提出する前に問題を食い止めます。
2. ネイティブAgent Teamsサポート
プロンプトによってマルチエージェントワークフローをシミュレートするモデルとは異なり、M2.7はモデルレベルでロール境界、敵対的推論、行動の差別化が組み込まれています。これにより、以下が可能です:
- マルチエージェントシナリオにおけるロールアイデンティティの安定した固定
- チームメイトの論理的ブラインドスポットへの積極的な挑戦
- 複雑なステートマシン内での自律的意思決定
3. 97%のスキル遵守率
ほとんどのモデルは、多数のツールを扱うとパフォーマンスが低下します。M2.7は、40以上の複雑なスキル(各スキル2,000トークン以上)でも97%のスキル追随精度を維持します。長く複雑な関数定義を理解し、拡張されたインタラクション内で正しく使用します。
4. プロフェッショナルなワークスペースでの優秀性
- GDPval-AA Elo:1495(オープンソースモデル中最も高く、MiMo-V2-ProやKimi K2.5を上回る)
- 高忠実度のOffice編集:Excel、PowerPoint、Wordにおける複数回の修正
- 実世界のタスク:年次レポートの読み取り、収益モデルの設計、テンプレートからのPPT生成—フィードバックを通じて自己修正するジュニアアナリストのように
5. 感情IQを備えた知能
M2.7は、高い感情的知性と一貫性のあるキャラクター設定により、「冷たいツール」という固定観念を打ち破り、純粋な生産性タスクを超えた自然で人間らしいインタラクションを実現します。
技術仕様とパフォーマンス
技術仕様
| パラメータ | 値 |
|---|---|
| コンテキストウィンドウ | 204,800トークン |
| 最大出力 | 131,072トークン |
| 量子化 | FP8 |
| 入力モダリティ | テキスト |
| 出力モダリティ | テキスト |
| サポート機能 | ツール、JSONモード、構造化出力、推論 |
| サンプリングパラメータ | temperature、top_p、top_k、repetition_penalty、frequency_penalty、presence_penalty、stop、seed |
ベンチマークパフォーマンス概要
MiniMax M2.7は、実世界のエージェントタスクにおいてリーディングパフォーマンスを発揮し、主要なベンチマークで最先端モデルを上回るか、同等の結果を示しています:
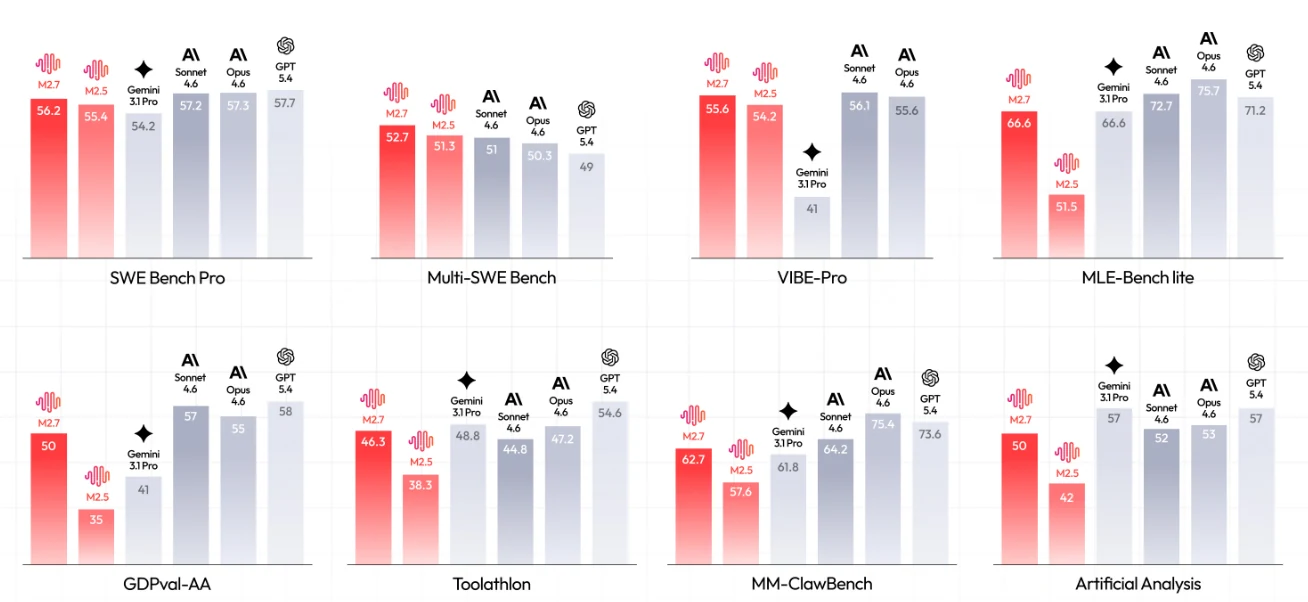
M2.7(赤い棒)と競合モデルを8つの主要ベンチマークで比較。[出典:MiniMax公式]
主な洞察:
- SWE能力:SWE Bench Proで56.2%、最先端モデル(GPT-5.4は57.7%)に迫る
- 多言語での優位性:Multi-SWE Benchで52.7、GPT-5.4(49)を含む全競合を上回る
- ML自動化:MLE-Bench liteで66.6%、Gemini 3.1 Proと同率で、Opus 4.6(75.7%)とGPT-5.4(71.2%)に次ぐ
- エージェントの卓越性:GDPval-AAインテリジェンス指数50、本番環境対応のパフォーマンスとしてベンチマークのベースラインに一致
知能対コスト:クラス最高の効率性
M2.7は、パフォーマンスだけでなく、最先端の知能をわずかなコストで提供する点で際立っています:
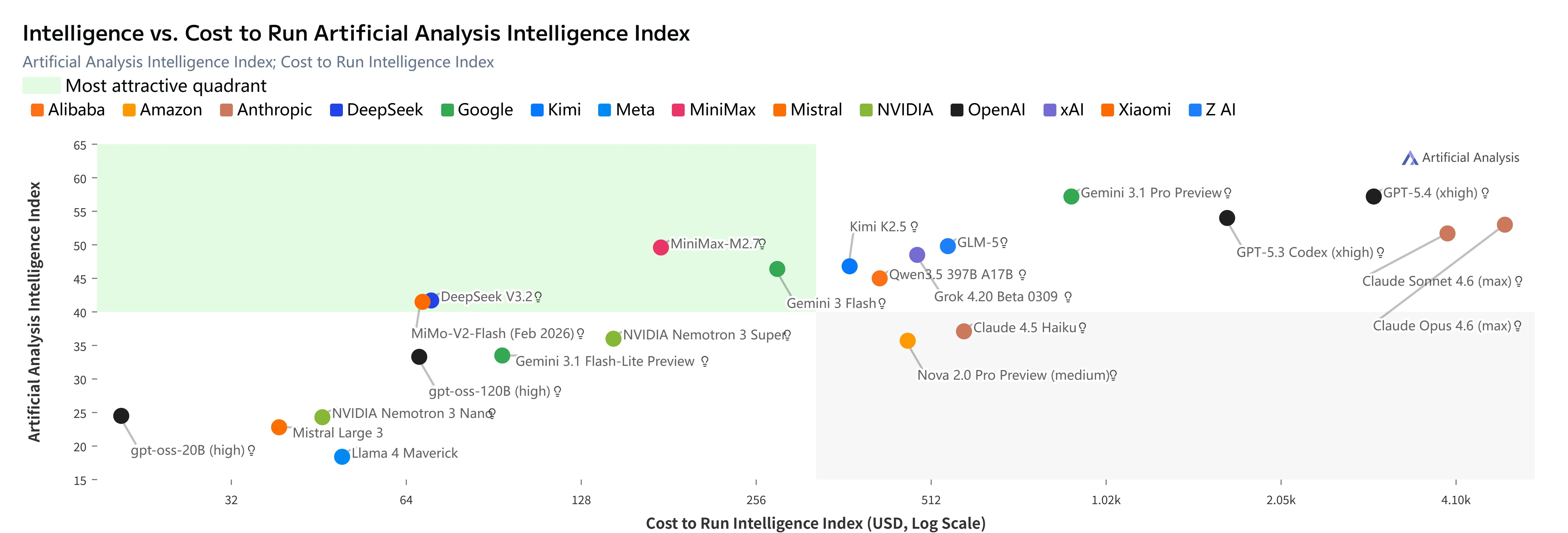
MiniMax M2.7(赤い点)はArtificial Analysis Intelligence Index対コストの「最も魅力的な象限」に位置。[出典:Artificial Analysis]
主な洞察:
- GLM-5レベルの知能を約3分の2低いコストで実現
- Kimi K2.5よりも3倍安く、かつ高い知能を提供
- Claude Opus 4.6よりも23倍安く、わずか5ポイントの知能差
- Indexが47以上の全モデルの中で、知能ポイントあたりのコストが最も低い
幻覚の軽減
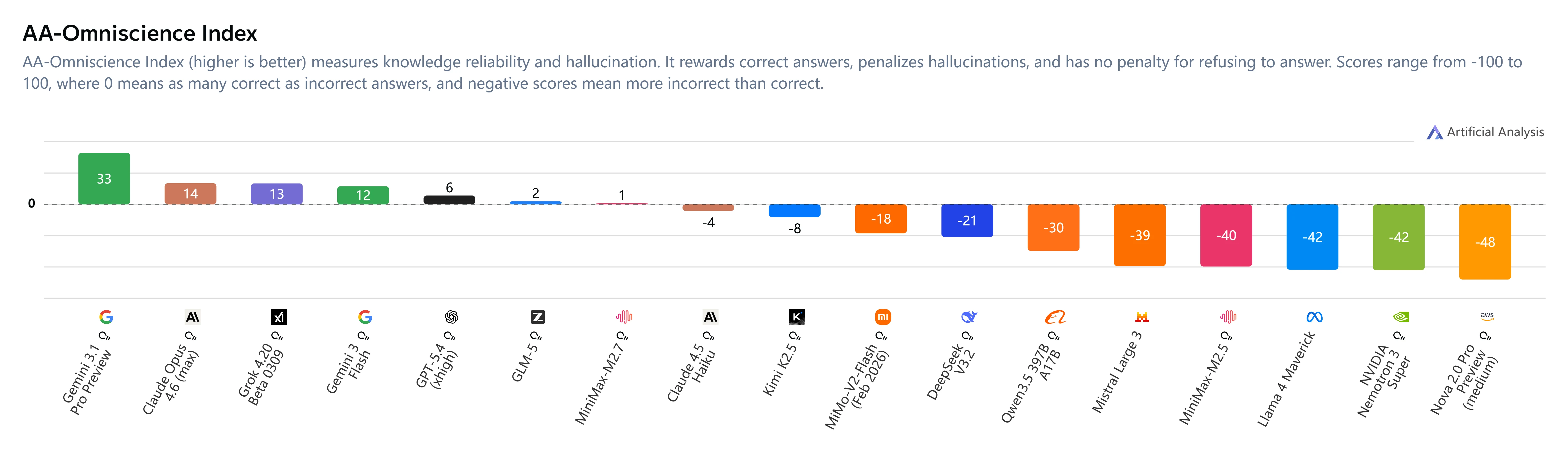
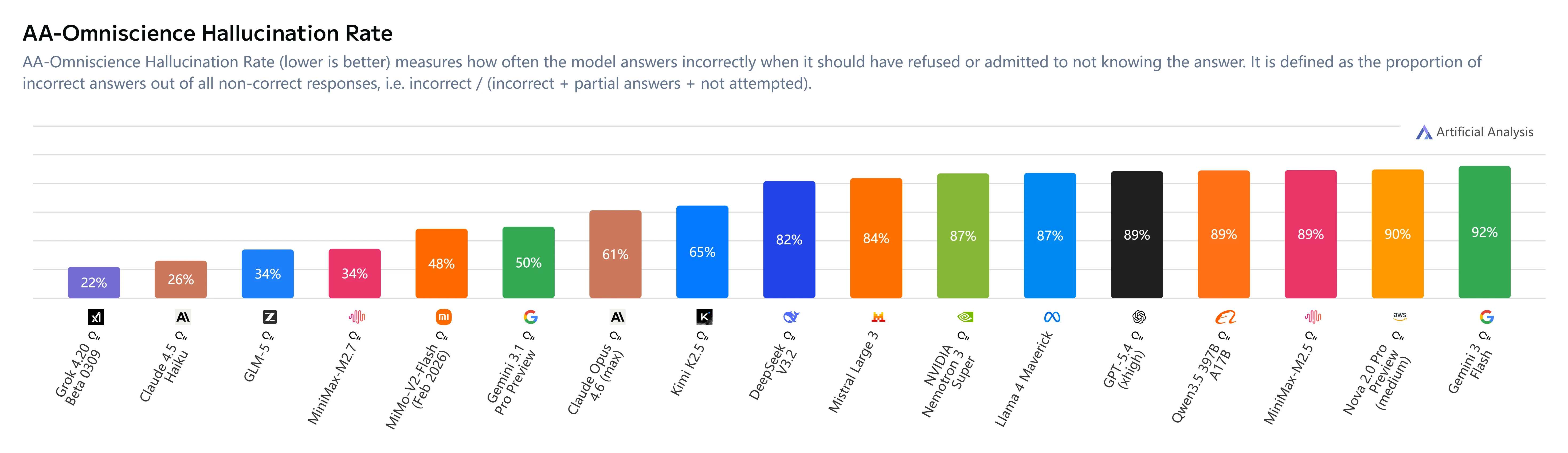
主な洞察:
- AA-Omniscience Index:+1(M2.5の-40から改善)
- 幻覚率:34%(Claude Sonnet 4.6の46%やGemini 3.1 Proの50%より低い)
- 行動の変化:MiniMax M2.7は不確かな場合に推測せずに回答を控えることで、信頼性が大幅に向上
Novita AIでの価格
| パラメータ | MiniMax M2.7 | GLM-5 | Kimi K2.5 |
|---|---|---|---|
| 入力 | 0.3ドル/Mt | 1.0ドル/Mt | 0.6ドル/Mt |
| 出力 | 1.2ドル/Mt | 3.2ドル/Mt | 3.0ドル/Mt |
| キャッシュ読み取り | 0.06ドル/Mt | 0.2ドル/Mt | 0.1ドル/Mt |
| コンテキストウィンドウ | 204,800トークン | 202,800トークン | 262,144トークン |
Novita AIでMiniMax M2.7を選ぶ理由
- 競争力のある価格設定:入力0.3ドル/Mt、他プラットフォームのより高いレートと比較
- プロンプトキャッシング:繰り返しのコンテキストで80%のコスト削減、キャッシュ読み取り0.06ドル/Mt
- サーバーレスデプロイメント:インフラストラクチャ管理不要
- 統一API:OpenAI互換のエンドポイント—1行でモデル切り替え
- グローバルエッジネットワーク:アメリカのデータセンターからの低レイテンシ推論
Novita AIでMiniMax M2.7を使い始める方法
前提条件
- Novita AIアカウントを作成(無料サインアップ)
- APIキーを取得
APIキーの取得方法
APIの使用例(Python)
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="minimax/minimax-m2.7",
messages=[
{"role": "system", "content": "あなたは親切なアシスタントです。"},
{"role": "user", "content": "こんにちは、お元気ですか?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
MiniMax M2.7ができること:実世界のショーケース
MiniMax M2.7は、複数のドメインにわたる複雑な本番環境対応タスクで優れた性能を発揮します:
フルスタックWeb開発:インタラクティブな機能、レスポンシブレイアウト、機能的なUIコンポーネントを備えた完全な単一ショットWebサイトを生成します。音楽ライブラリからeコマースプラットフォームまで対応。
本番デバッグとSRE:自動ログ分析、データベース検証、プロアクティブな修正デプロイメントにより、3分でのインシデント復旧を実現。M2.7は根本原因分析、ノンブロッキングマイグレーション、セキュリティ監査を自律的に実行。
自律的ソフトウェア開発:要件からデプロイメントまでエンドツーエンドのプロジェクト(Web、Android、iOS)を提供。マルチファイルリファクタリング、ML実験の自動化、自己改善を含みます。M2.7は反復的なデバッグを通じて自身のトレーニングを30%最適化しました。
プロフェッショナルなOffice自動化:年次レポートの読み取り、財務モデルの設計、PPTの生成を実行。Excel、PowerPoint、Wordでの複数回の編集にも対応。リサーチレポートや複雑なデータワークフローに最適。
AIネイティブアプリケーション:OpenAI/Anthropic互換APIを介して、OpenClaw、Claude Code、Cursorなどのエージェントフレームワークとシームレスに統合。97%のツール遵守率を必要とするカスタマーサポートボット、リサーチアシスタント、クリエイティブツールに最適。
結論
MiniMax M2.7は、最先端推論モデルの数分の一のコストで、本番グレードのAIエージェント機能を開発者に提供します。97%のツール遵守率、ネイティブのAgent Teamsサポート、8つの主要ベンチマークでの卓越した実世界パフォーマンスにより、デモだけでなく信頼性の高いエージェントデプロイメント向けに構築されています。
Novita AIでの入力0.3ドル/Mt、出力1.2ドル/Mtという価格設定により、M2.7はGLM-5の3分の1の価格で競争力のある知能を提供します。SRE自動化、フルスタックWebプロジェクト、プロフェッショナルワークスペースツール、AIパワード開発環境のいずれを構築している場合でも、M2.7は費用対効果が高く、実戦で試された選択肢です。
👉さあ始めましょう:Novita AIでMiniMax M2.7を試す
Novita AI は、シンプルなAPIを使用してAIモデルを簡単にデプロイできる機能を開発者に提供し、手頃な価格で信頼性の高いGPUクラウドを構築およびスケーリングするためのAIクラウドプラットフォームです。
よくある質問
M2.7とM2.5の違いは何ですか?
M2.7は、すべてのベンチマークでM2.5から改善されています:(1) SWE Bench Pro:+4ポイント(52.2→56.2)、(2) GDPval-AA:+15ポイント(35→50)、(3) MLE-Bench lite:+35ポイント(31.5→66.6)、(4) AA-Omniscience Indexにおける幻覚率が-40から+1に改善。M2.7は自己進化によってトレーニングされた初めてのMiniMaxモデルでもあります。
M2.7はビジョンや音声入力をサポートしていますか?
まだです。現行バージョン(M2.7)はテキストのみです。MiniMaxには別のマルチモーダルモデル(動画用Hailuo、音声用Speech)がありますが、M2.7はテキストベースの推論とエージェント実行に焦点を当てています。
97%のスキル遵守率は実際にどのように機能しますか?
M2.7は、長時間の複雑なセッションでもロール境界とツールプロトコルの遵守を維持するようにトレーニングされています。40以上のツール(各2,000トークン以上)を用いたテストでは、適切なパラメータで関数を正しく呼び出す確率が97%でした。これはツールの増加に伴ってパフォーマンスが低下するモデルよりも大幅に高い数字です。
おすすめ記事
Novita AIのQwen 3.5 Mediumモデルシリーズ:わずかなコストで最先端の知能を
3つの新しいQwen 3.5 Mediumモデルが、Novita AIに最先端のエージェント推論をもたらします。オープンウェイト、262Kコンテキスト、本番環境対応。これらのモデルがどのようにGPT-4クラスのパフォーマンスをわずかなコストで提供するかを探ってみましょう。
費用対効果の高いAIエージェントを構築:Novita AI経由でOpenClawでMiniMax M2.5を使用する
MiniMax M2.5をNovita AIでOpenClaw(Clawdbolt)に統合。このステップバイステップガイドで、スケーラブルで費用対効果の高いAIエージェントを数分で構築できます。
本番環境向けにGLM4-MoEを最適化:SGLangでTTFTを65%高速化
Novita AIがどのようにSGLangを使用してGLM 4.7を本番環境向けに最適化し、最初のトークンまでの時間を65%短縮したかを学びましょう。大規模MoEモデルをスケールデプロイするための必読資料です。



