

- Die Herausforderung: Die Entwicklung zuverlässiger KI-Agenten ist immer noch zu schwierig
- Die Lösung: Die Selbstoptimierungsarchitektur von MiniMax M2.7
- Technische Spezifikationen & Leistung
- Preise auf Novita AI
- Warum Novita AI für MiniMax M2.7 wählen?
- So starten Sie mit MiniMax M2.7 auf Novita AI
- Was MiniMax M2.7 kann: Praxisbeispiele
- Fazit
MiniMax M2.7 ist jetzt auf Novita AI verfügbar und bietet produktionsreife KI-Agentenfunktionen bei außergewöhnlicher Kosteneffizienz. Dieses selbstoptimierende Reasoning-Modell erreicht einen Intelligence Index von 50 (gleicht dem von GLM-5) bei um das 3-fach geringeren Betriebskosten. Mit 97 % Skill-Einhaltung bei über 40 komplexen Tools, nativer Unterstützung für Agent Teams und branchenführender Leistung bei realen Aufgaben (GDPval-AA Elo 1495) wurde M2.7 für Entwickler:innen entwickelt, die zuverlässige agentische KI benötigen, ohne die Kosten aus dem Ruder laufen zu lassen.
Preise: 0,3 $/Mt Eingabe, 1,2 $/Mt Ausgabe (Cache-Lesen 0,06 $/Mt) Kontextfenster: 204.800 Token
Jetzt im Novita AI Playground ausprobieren!
Die Herausforderung: Die Entwicklung zuverlässiger KI-Agenten ist immer noch zu schwierig
Die meisten großen Sprachmodelle werben mit “agentischen Fähigkeiten”, aber der reale Einsatz zeigt ein anderes Bild:
- Tool-Aufruf-Fehler: Modelle verstehen Funktionssignaturen falsch, überspringen erforderliche Parameter oder halluzinieren nicht existierende Tools
- Kontextkollaps: Lange laufende Agent-Sitzungen erreichen Token-Limits oder verlieren kritischen Kontext mitten in der Aufgabe
- Unzuverlässige Ausführung: Funktioniert in Demos, versagt aber in der Produktion, wenn gleichzeitig über 40 Skills verarbeitet werden
- Kostenexplosion: Der Betrieb von führenden Reasoning-Modellen wie Claude Opus 4.6 oder GPT-5.4 summiert sich schnell
Sie brauchen ein Modell, das tatsächlich in produktiven Agentensystemen funktioniert – nicht nur eines, das in Benchmarks gut aussieht.
Die Lösung: Die Selbstoptimierungsarchitektur von MiniMax M2.7
MiniMax M2.7 ist das erste Modell des Unternehmens, das an seiner eigenen Entwicklung beteiligt war – es hat buchstäblich seinen Trainingsprozess debuggt, Evaluierungs-Harnesses erstellt und sein eigenes Grundgerüst optimiert. Diese Selbstoptimierungsschleife hat ein Modell hervorgebracht, das einzigartig für reale agentische Aufgaben geeignet ist.
Was M2.7 besonders macht
1. Produktionsreife Softwareentwicklung
M2.7 schreibt nicht nur Code – es debuggt Live-Systeme. Wenn ein Produktionsalarm ausgelöst wird, korreliert es Monitoring-Metriken mit Bereitstellungszeitplänen, führt statistische Trace-Analysen durch, verbindet sich mit Datenbanken, um Hypothesen zu überprüfen, identifiziert fehlende Index-Migrationsdateien und weiß, dass es nicht-blockierende Indexerstellung verwenden muss, um das Problem einzudämmen, bevor es den Fix einreicht.
2. Native Unterstützung für Agent Teams
Im Gegensatz zu Modellen, die Multi-Agenten-Workflows durch Prompting simulieren, hat M2.7 Rollengrenzen, adversarielles Reasoning und verhaltensbezogene Differenzierung auf Modellebene integriert. Es kann:
- Seine Rollenidentität in Multi-Agenten-Szenarien stabil verankern
- Logische blinde Flecken von Teammitgliedern proaktiv hinterfragen
- Autonome Entscheidungen in komplexen Zustandsmaschinen treffen
3. 97 % Skill-Einhaltung
Die meisten Modelle versagen, wenn sie mehr als eine Handvoll Tools verarbeiten müssen. M2.7 hält eine Genauigkeit von 97 % bei der Skill-Einhaltung auch bei über 40 komplexen Skills, die jeweils mehr als 2.000 Token umfassen. Es versteht lange, komplexe Funktionsdefinitionen und wendet sie korrekt in erweiterten Interaktionen an.
4. Exzellenz im professionellen Arbeitsbereich
- GDPval-AA Elo: 1495 (höchster Wert unter Open-Source-Modellen, vor MiMo-V2-Pro und Kimi K2.5)
- Hochwertige Office-Bearbeitung: Mehrstufige Überarbeitungen in Excel, PowerPoint und Word
- Reale Aufgaben: Liest Jahresberichte, entwirft Umsatzmodelle, generiert PPTs aus Vorlagen – wie ein Junior-Analyst, der sich selbst über Feedback korrigiert
5. Intelligenz mit emotionaler Intelligenz
M2.7 durchbricht das Klischee des “kalten Tools” mit hoher emotionaler Intelligenz und konsistenter Charakterisierung, die natürliche, menschenähnliche Interaktionen über rein produktive Aufgaben hinaus ermöglichen.
Jetzt im Novita AI Playground ausprobieren!
Technische Spezifikationen & Leistung
Technische Spezifikationen
| Parameter | Wert |
| Kontextfenster | 204.800 Token |
| Maximale Ausgabe | 131.072 Token |
| Quantisierung | FP8 |
| Eingabemodalitäten | Text |
| Ausgabemodalitäten | Text |
| Unterstützte Funktionen | Tools, JSON-Modus, Strukturierte Ausgaben, Reasoning |
| Sampling-Parameter | temperature, top_p, top_k, repetition_penalty, frequency_penalty, presence_penalty, stop, seed |
Benchmark-Leistungsübersicht
MiniMax M2.7 zeigt führende Leistung bei realen agentischen Aufgaben und übertrifft oder gleicht führende Modelle in wichtigen Benchmarks:
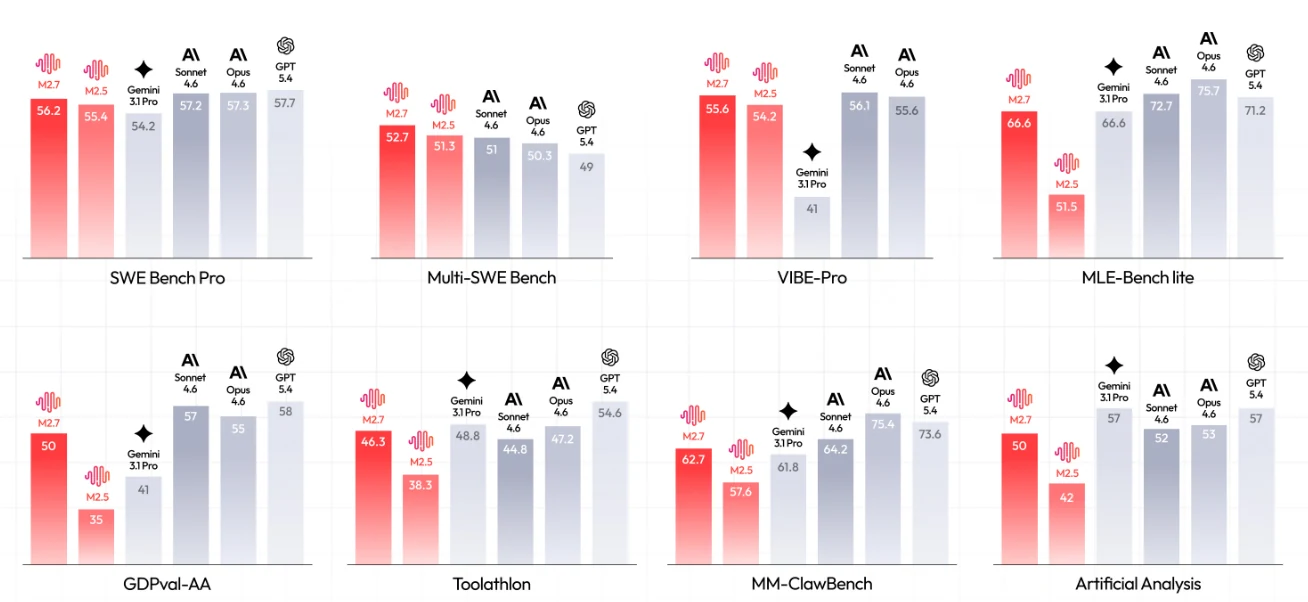
M2.7 (rote Balken) im Vergleich zu konkurrierenden Modellen über 8 kritische Benchmarks. [Quelle: MiniMax Official]
Wichtige Erkenntnisse:
- SWE-Fähigkeiten: 56,2 % auf der SWE Bench Pro, annähernd an führende Modelle (GPT-5.4 bei 57,7 %)
- Mehrsprachiger Vorteil: 52,7 auf der Multi-SWE Bench, übertrifft alle Konkurrenten einschließlich GPT-5.4 (49)
- ML-Automatisierung: 66,6 % auf der MLE-Bench lite, gleichauf mit Gemini 3.1 Pro und nur knapp hinter Opus 4.6 (75,7 %) und GPT-5.4 (71,2 %)
- Agentische Exzellenz: GDPval-AA Intelligence Index 50, gleicht der Benchmark-Baseline für produktionsreife Leistung
Intelligenz vs. Kosten: Best-in-Class-Effizienz
M2.7 sticht nicht nur durch Leistung hervor, sondern liefert Spitzenintelligenz zu einem Bruchteil der Kosten:
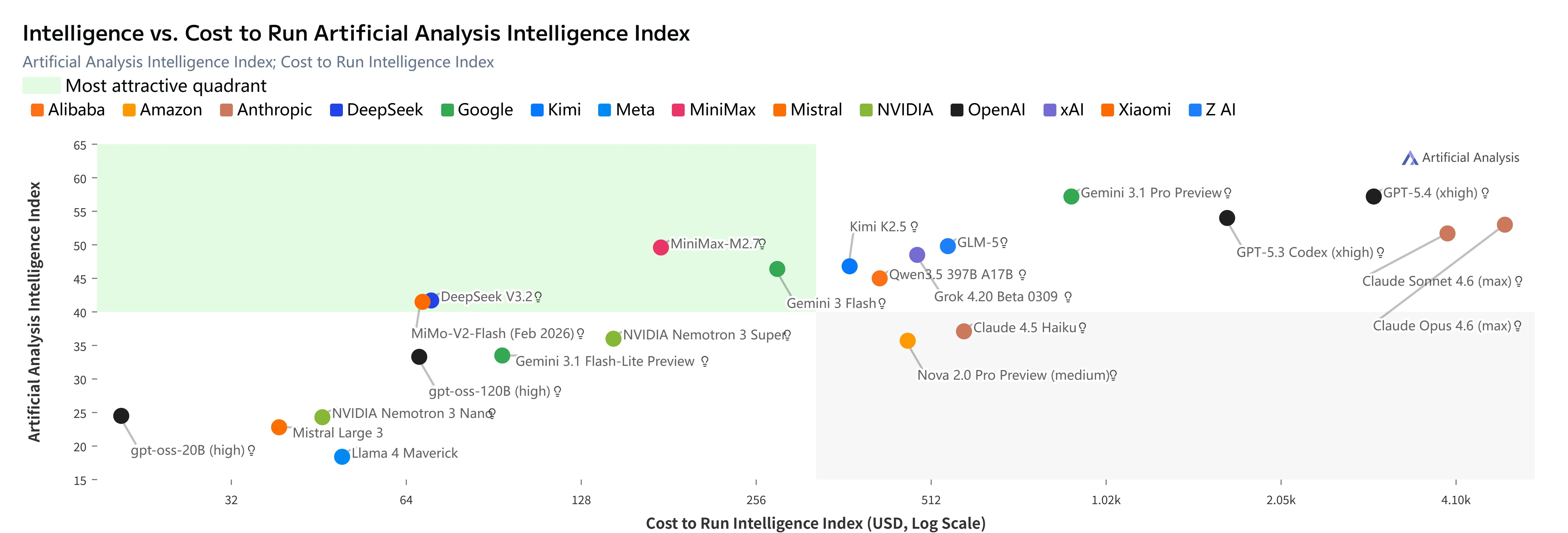
MiniMax M2.7 (roter Punkt) im “attraktivsten Quadranten” des Artificial Analysis Intelligence Index im Vergleich zu den Kosten. [Quelle: Artificial Analysis]
Wichtige Erkenntnisse:
- GLM-5-Niveau an Intelligenz zu fast 2/3 niedrigeren Kosten
- 3 Mal günstiger als Kimi K2.5 bei höherer Intelligenz
- 23 Mal günstiger als Claude Opus 4.6 bei nur 5 Punkten Unterschied in der Intelligenz
- Niedrigste Kosten pro Intelligenzpunkt unter allen Modellen mit Index ≥47
Halluzinationsminderung
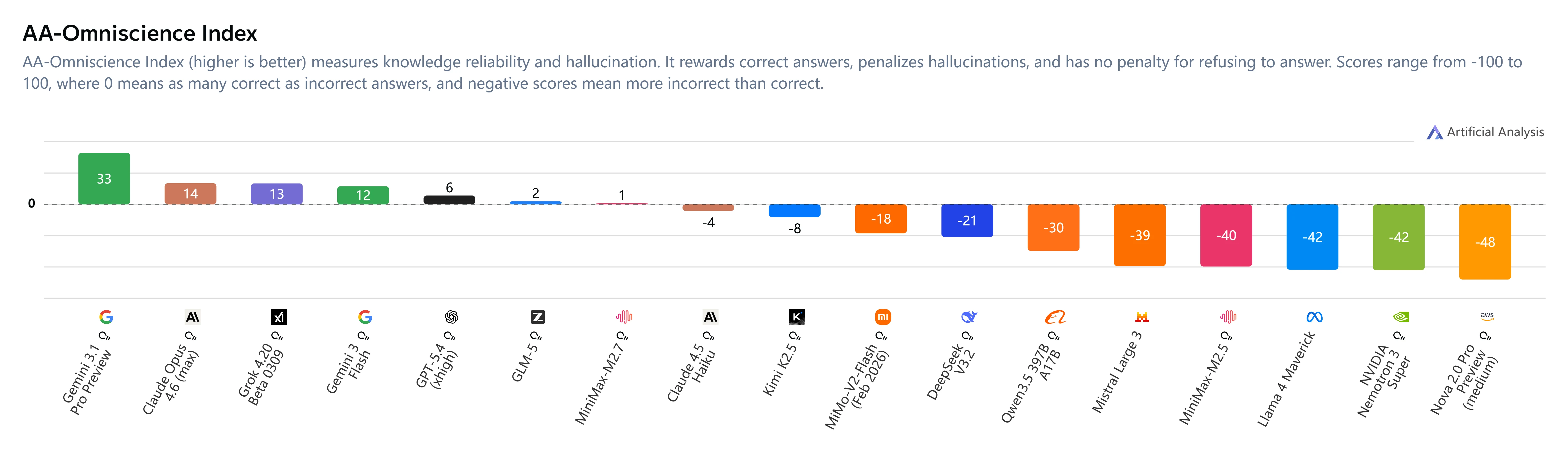
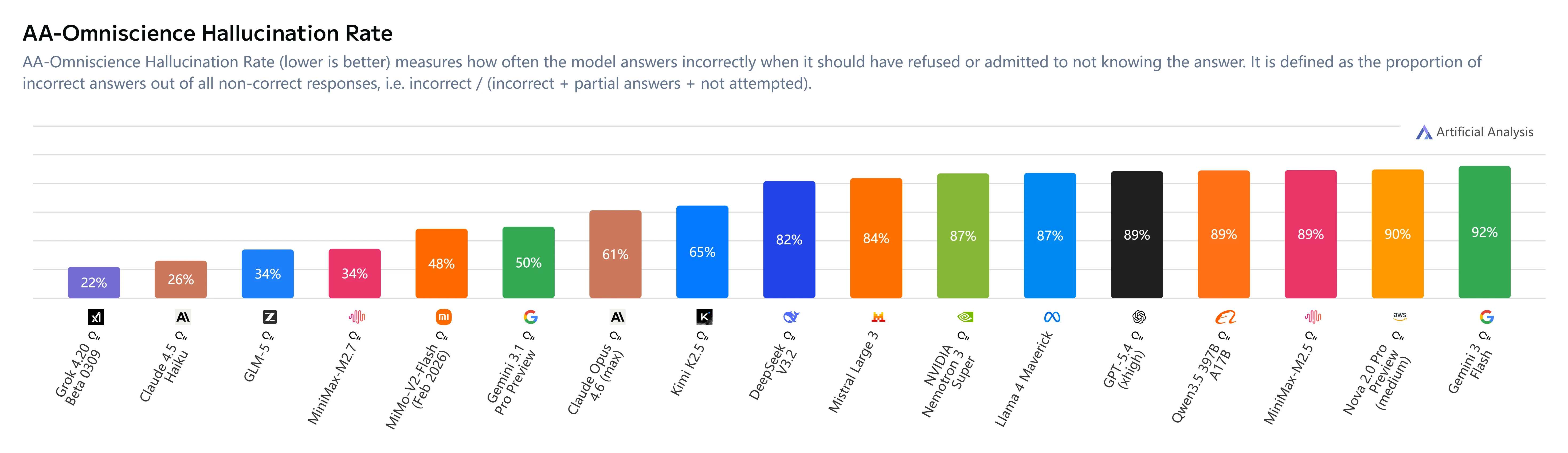
Wichtige Erkenntnisse:
- AA-Omniscience-Index: +1 (angestiegen von -40 bei M2.5)
- Halluzinationsrate: 34 % (niedriger als bei Claude Sonnet 4.6 mit 46 % und Gemini 3.1 Pro mit 50 %)
- Verhaltensänderung: MiniMax M2.7 enthält sich bei Unsicherheit, statt zu raten, was die Zuverlässigkeit deutlich verbessert
Preise auf Novita AI
| Parameter | MiniMax M2.7 | GLM-5 | Kimi K2.5 |
| Eingabe | 0,3 $/Mt | 1,0 $/Mt | 0,6 $/Mt |
| Ausgabe | 1,2 $/Mt | 3,2 $/Mt | 3,0 $/Mt |
| Cache-Lesen | 0,06 $/Mt | 0,2 $/Mt | 0,1 $/Mt |
| Kontextfenster | 204.800 Token | 202.800 Token | 262.144 Token |
Warum Novita AI für MiniMax M2.7 wählen?
- Wettbewerbsfähige Preise: 0,3 $/Mt Eingabe im Vergleich zu höheren Tarifen auf anderen Plattformen
- Prompt-Caching: 80 % Kostenreduzierung bei wiederholtem Kontext durch Cache-Lesen zu 0,06 $/Mt
- Serverlose Bereitstellung: Keine Verwaltung von Infrastruktur erforderlich
- Vereinheitlichte API: OpenAI-kompatibler Endpunkt – wechseln Sie Modelle mit einer Zeile
- Globales Edge-Netzwerk: Niedrige Latenz bei der Inferenz aus US-Rechenzentren
So starten Sie mit MiniMax M2.7 auf Novita AI
Voraussetzungen
- Erstellen Sie ein Novita AI-Konto (kostenlose Anmeldung)
- Holen Sie sich einen API-Schlüssel
Konto erstellen und API-Schlüssel holen
So holen Sie sich einen API-Schlüssel
API-Nutzung (Python)
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="minimax/minimax-m2.7",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
Was MiniMax M2.7 kann: Praxisbeispiele
MiniMax M2.7 zeichnet sich durch komplexe, produktionsreife Aufgaben in verschiedenen Bereichen aus:
Full-Stack-Webentwicklung: Erstellen Sie vollständige, einzelne Websites mit interaktiven Funktionen, responsiven Layouts und funktionalen UI-Komponenten – von Musikbibliotheken bis zu E-Commerce-Plattformen.
Produktions-Debugging & SRE: Erreichen Sie eine 3-minütige Incident-Wiederherstellung durch automatisierte Log-Analyse, Datenbanküberprüfung und proaktive Fix-Bereitstellung. M2.7 erledigt Root-Cause-Analysen, nicht-blockierende Migrationen und Sicherheitsaudits autonom.
Autonome Softwareentwicklung: Liefern Sie End-to-End-Projekte (Web, Android, iOS) von den Anforderungen bis zur Bereitstellung. Dazu gehören Multi-Datei-Refactoring, ML-Experimentautomatisierung und Selbstoptimierung – M2.7 hat sein eigenes Training durch iteratives Debugging um 30 % optimiert.
Professionelle Office-Automatisierung: Lesen Sie Jahresberichte, entwerfen Sie Finanzmodelle und generieren Sie PPTs – alles mit mehrstufiger Bearbeitung in Excel, PowerPoint und Word. Perfekt für Forschungsberichte und komplexe Datenworkflows.
KI-native Anwendungen: Integrieren Sie sich nahtlos mit OpenClaw, Claude Code, Cursor und anderen Agent-Frameworks über eine OpenAI/Anthropic-kompatible API. Ideal für Kundensupport-Bots, Forschungsassistenten und kreative Tools, die 97 % Tool-Einhaltung erfordern.
Fazit
MiniMax M2.7 bietet Entwickler:innen produktionsreife KI-Agentenfunktionen zu einem Bruchteil der Kosten von führenden Reasoning-Modellen. Mit 97 % Tool-Einhaltung, nativer Unterstützung für Agent Teams und außergewöhnlicher Leistung in 8 kritischen Benchmarks im realen Einsatz ist es für zuverlässige agentische Bereitstellung ausgelegt – nicht nur für Demos.
Bei 0,3 $/Mt Eingabe und 1,2 $/Mt Ausgabe auf Novita AI liefert M2.7 wettbewerbsfähige Intelligenz zu einem Drittel des Preises von GLM-5. Egal, ob Sie SRE-Automatisierung, Full-Stack-Webprojekte, professionelle Arbeitsbereich-Tools oder KI-gestützte Entwicklungsumgebungen erstellen – M2.7 ist eine kosteneffiziente, praxiserprobte Wahl.
👉 Jetzt starten: MiniMax M2.7 auf Novita AI ausprobieren
Novita AI ist eine KI-Cloud-Plattform, die Entwickler:innen eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud zum Erstellen und Skalieren von Anwendungen zur Verfügung stellt.
Häufig gestellte Fragen
Was ist der Unterschied zwischen M2.7 und M2.5?
M2.7 verbessert M2.5 in allen Benchmarks: (1) SWE Bench Pro: +4 Punkte (52,2 → 56,2), (2) GDPval-AA: +15 Punkte (35 → 50), (3) MLE-Bench lite: +35 Punkte (31,5 → 66,6) und (4) die Halluzinationsrate sank von -40 auf +1 im AA-Omniscience-Index. M2.7 ist außerdem das erste MiniMax-Modell, das per Selbstoptimierung trainiert wurde.
Unterstützt M2.7 Bild- oder Audioeingaben?
Noch nicht. Die aktuelle Version (M2.7) ist nur textbasiert. MiniMax hat separate multimodale Modelle (Hailuo für Video, Speech für Audio), aber M2.7 konzentriert sich auf textbasiertes Reasoning und agentische Ausführung.
Wie funktioniert die 97 % Skill-Einhaltung in der Praxis?
M2.7 wurde trainiert, um Rollengrenzen und Tool-Protokoll-Einhaltung auch in langen, komplexen Sitzungen beizubehalten. In Tests mit über 40 Tools (jeweils >2.000 Token) hat es Funktionen in 97 % der Fälle mit korrekten Parametern aufgerufen – deutlich höher als bei Modellen, die bei zunehmender Tool-Anzahl an Leistung verlieren.
Empfohlene Artikel
Qwen 3.5 Medium-Modellserie auf Novita AI: Spitzenintelligenz zu einem Bruchteil der Kosten
Drei neue Qwen 3.5 Medium-Modelle bringen agentisches Reasoning auf Spitzeniveau zu Novita AI – Open-Weight, 262K Kontext, produktionsreif. Erfahren Sie, wie diese Modelle GPT-4-klasse-Leistung zu einem Bruchteil der Kosten liefern.
Kosteneffiziente KI-Agenten erstellen: MiniMax M2.5 in OpenClaw über Novita AI nutzen
Integrieren Sie MiniMax M2.5 in OpenClaw (Clawdbolt) mit Novita AI. Erstellen Sie in Minuten skalierbare, kosteneffiziente KI-Agenten mit dieser Schritt-für-Schritt-Anleitung zur Multi-Channel-Agentenbereitstellung.
Optimierung von GLM4-MoE für die Produktion: 65 % schnellerer TTFT mit SGLang
Erfahren Sie, wie Novita AI GLM 4.7 mit SGLang für die Produktion optimiert hat und so eine um 65 % schnellere Time-to-First-Token erreicht hat. Unverzichtbare Lektüre für die Bereitstellung großer MoE-Modelle im großen Maßstab.



