

DeepSeek V3.2 auf Novita AI bringt Goldmedaillen-Reasoning-Leistung bei IMO/IOI für Entwickler zu $0,269/$0,40 pro 1M Eingabe-/Ausgabetoken. Basierend auf einer 685B-Parameter-Mixture-of-Experts-Architektur mit dem revolutionären DeepSeek Sparse Attention (DSA) reduziert dieses Modell die Rechenkomplexität für Aufgaben mit langem Kontext und erreicht gleichzeitig Spitzenergebnisse in Reasoning-Benchmarks.
Für Entwickler, die Mathematik-Löser, Coding-Agenten oder komplexe Reasoning-Workflows erstellen, liefert Novita AIs serverlose Infrastruktur branchenweit niedrigste Latenz mit OpenAI-kompatiblen und Anthropic-kompatiblen Endpunkten – tauschen Sie einfach die Basis-URL aus und starten Sie in 2 Minuten.
Was ist DeepSeek V3.2?
DeepSeek V3.2 ist ein 685,4B-Parameter-Mixture-of-Experts-Reasoning-Modell mit 37B aktiven Parametern pro Token, das für effiziente Verarbeitung von langem Kontext und überlegene agentische Leistung entwickelt wurde. Als Upgrade zu V3.1-Terminus eingeführt, bringt es drei bahnbrechende Innovationen mit sich:
Technische Architektur
| Spezifikation | Wert |
|---|---|
| Gesamtparameter | 685B |
| Aktive Parameter | 37B pro Token |
| MoE-Konfiguration | 256 geroutete Experten, 8 aktiv |
| Kontextfenster | 163.840 Token |
| Aufmerksamkeitsmechanismus | DSA + MLA Hybrid |
| Präzision | BF16; F8_E4M3; F32 |
Kerninnovationen
1. DeepSeek Sparse Attention (DSA): Ein feingranularer spärlicher Mechanismus, der einen Lightning-Indexer und Token-Selektor verwendet, um den Kontext selektiv auszudünnen. Im Gegensatz zu traditioneller Aufmerksamkeit, die alle Token verarbeitet, behält DSA die Leistung bei und reduziert gleichzeitig die Rechenkomplexität – besonders kritisch für Kontexte mit 128K+ Token.
2. Skalierbares Reinforcement Learning: Fortschrittliches Post-Training-Protokoll, das eine starke Leistung nach dem Training ermöglicht. Die Variante mit hoher Rechenleistung (Speciale) erreicht Spitzenleistung im Reasoning.
3. Agentic Task Synthesis Pipeline: Systematisch integriert dieses System Reasoning in Tool-Nutzungsszenarien im großen Maßstab und liefert überlegene Compliance sowie Generalisierung für Coding-Agenten und mehrstufige Workflows.
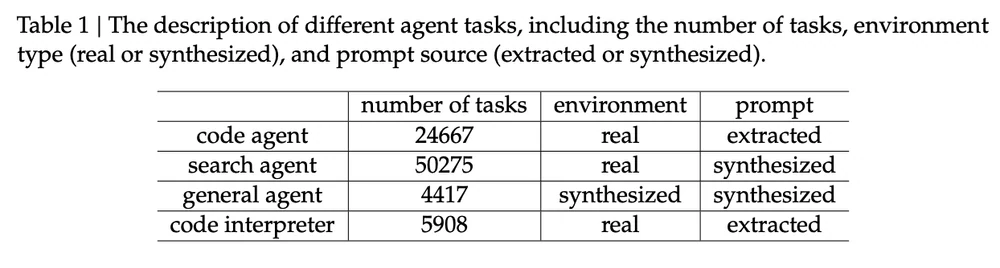
Agentenaufgaben zum Training von DeepSeek-V3.2. Bildquelle
Leistungsbenchmarks
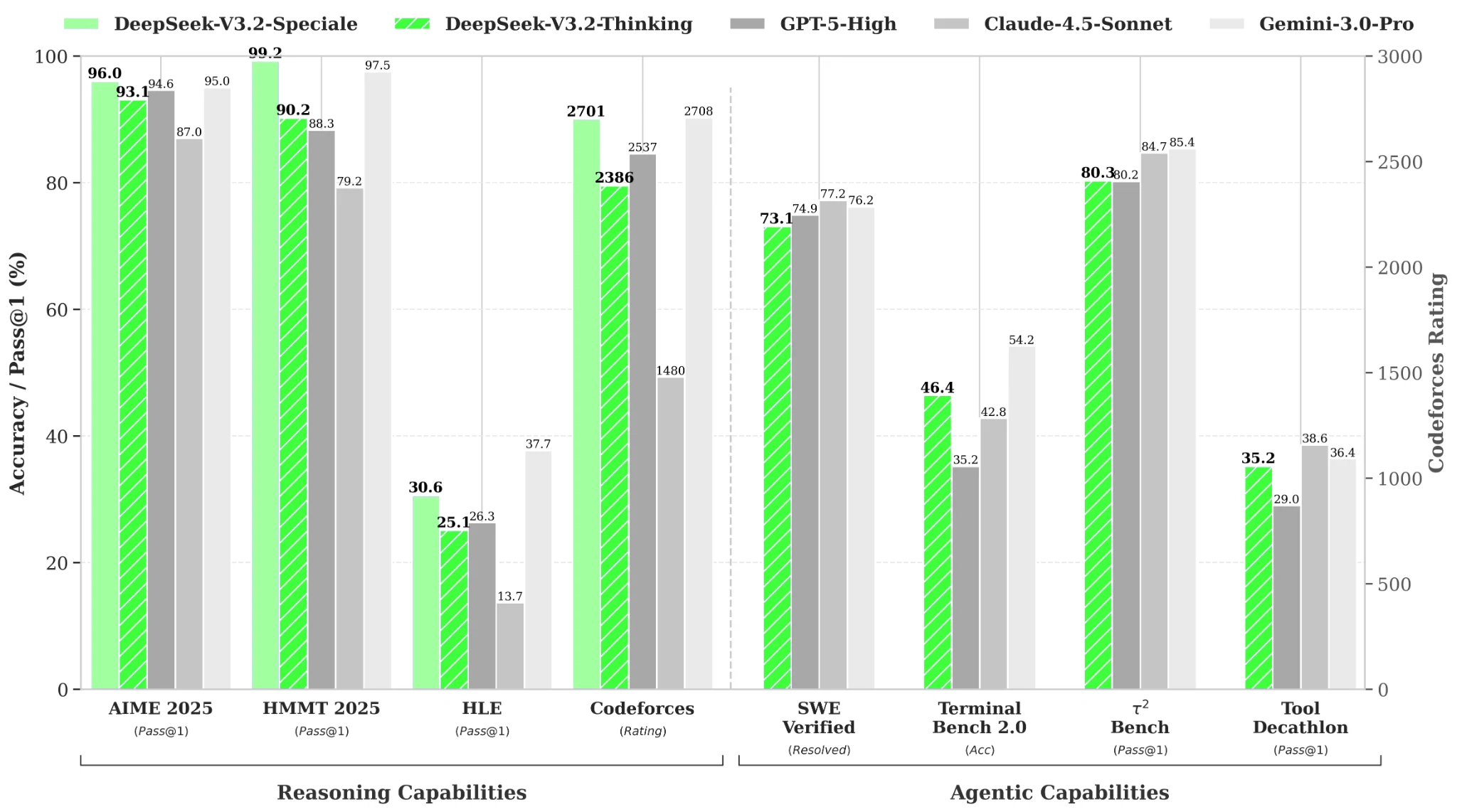
Von Hugging Face
Effizienz vs. Leistungsabwägung
DSA liefert eine 20–50%ige Reduzierung der Chain-of-Thought-Token bei gleichbleibenden Benchmark-Ergebnissen. Ein Coding-Agent, der täglich 50 Pull Requests verarbeitet, spart 180 $ pro Monat an Token-Kosten im Vergleich zu V3.1, ohne Leistungseinbußen.
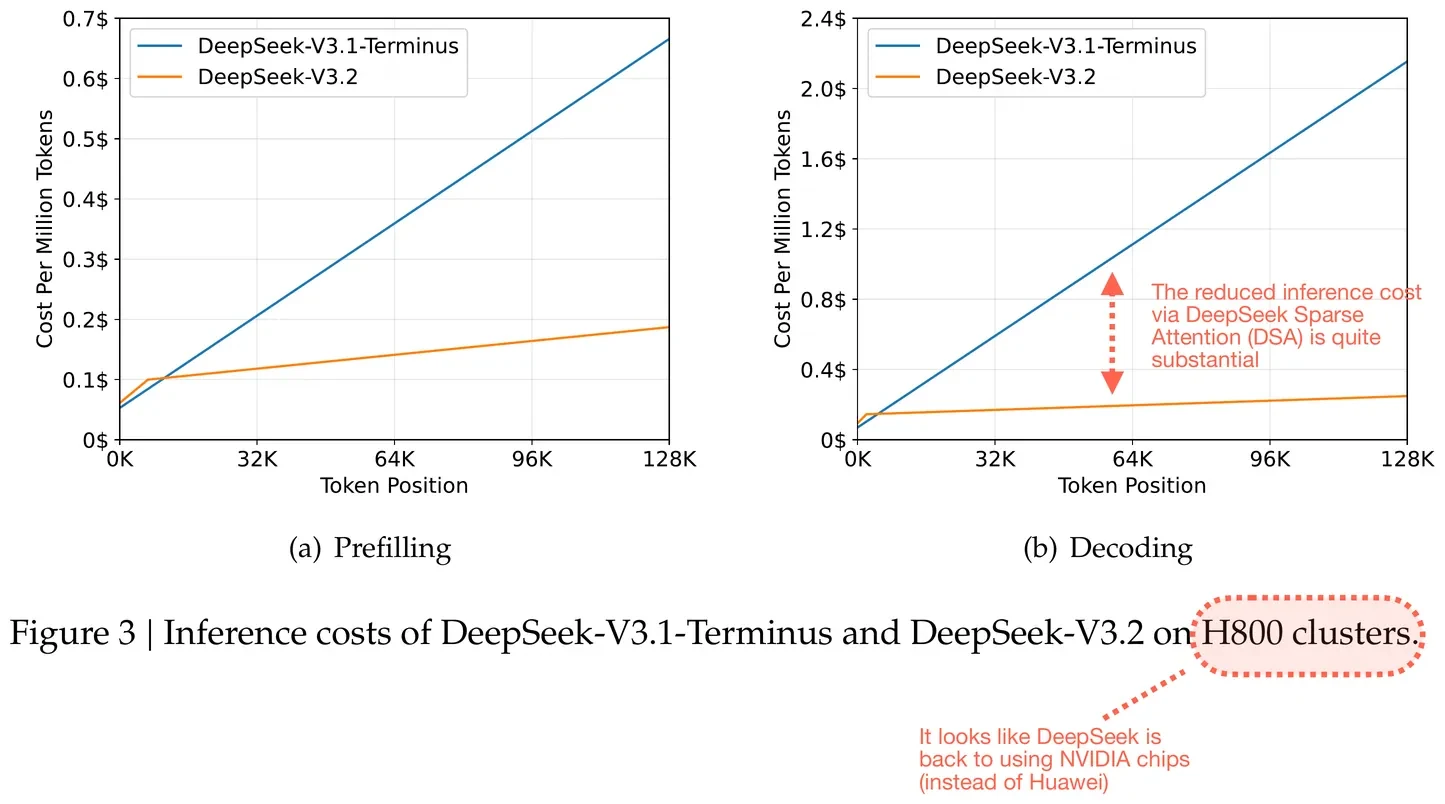
Kosteneinsparungen bei der Inferenz dank DeepSeek Sparse Attention (DSA). Annotierte Abbildung aus dem DeepSeek-V3.2-Bericht
Probieren Sie DeepSeek V3.2 jetzt aus!
Warum DeepSeek V3.2 auf Novita AI?
Novita AI bietet eine hochleistungsfähige, kosteneffektive Produktionsbereitstellung für DeepSeek V3.2, mit wettbewerbsfähigen Preisen. DeepSeek V3.2 auf Novita AI bringt Goldmedaillen-Reasoning-Leistung bei IMO/IOI für Entwickler zu $0,269/$0,40 pro 1M Eingabe-/Ausgabetoken.
Für DeepSeek V3.2 wird Cache Read auf Novita AI mit 0,1345 $ pro M Token berechnet.
Cache Read bezieht sich auf die Kosten für das Lesen von Token, die zuvor im Prompt-Cache gespeichert wurden. Wenn derselbe Prompt-Inhalt über mehrere Anfragen hinweg wiederverwendet wird, ruft das Modell diese Token direkt aus dem Cache ab, anstatt sie von Grund auf neu zu verarbeiten. Dies reduziert sowohl die Inferenzlatenz als auch die Kosten.
Probieren Sie DeepSeek V3.2 jetzt aus!
6 Gründe für Novita AI
1. OpenAI-kompatibel und Anthropic-kompatibel: Drop-In-Ersatz, der nur eine Änderung der Basis-URL erfordert. Vorhandener OpenAI-SDK-Code funktioniert sofort – keine Anpassungen, keine Lernkurve.
2. Serverlose Auto-Skalierung: Bewältigen Sie Verkehrsspitzen von 10 bis 10.000 Anfragen/Minute ohne Bereitstellung von Ressourcen. Sie zahlen nur für die verwendeten Token – keine Kosten für im Leerlauf befindliche GPUs.
3. Unternehmensgrade Zuverlässigkeit: SOC-2-konforme Infrastruktur mit Multi-Region-Redundanz. 99,5 % Uptime-SLA für Produktionsworkloads.
4. Ökosystem mit über 200 Modellen: Greifen Sie auf GLM-5, Qwen3-Coder-Next, MiniMax M2.5 und andere Spitzenmodelle über eine einheitliche API zu – testen Sie Alternativen ohne Änderungen an der Infrastruktur.
5. Transparente Abrechnung: Preise pro Token ohne versteckte Gebühren. Das Echtzeit-Dashboard zeigt die genauen Kosten pro Anfrage an – budgetieren Sie mit Zuversicht.

Probieren Sie DeepSeek V3.2 jetzt aus!
So greifen Sie auf DeepSeek V3.2 auf Novita AI zu
Drei Bereitstellungsmethoden, vom 2-Minuten-Schnellstart bis zu produktionsreifen Pipelines:
Methode 1: API-Schnellstart (2 Minuten)
Geeignet für: Tests, Prototypen, bestehende OpenAI-basierte Anwendungen
Einrichtungsschritte:
- Registrieren Sie sich auf novita.ai (kostenlose Stufe enthält Guthaben)
- Navigieren Sie zu Dashboard → API-Schlüssel → Neuen Schlüssel generieren
- Aktualisieren Sie Ihren Code mit dem Novita-Endpunkt:
Probieren Sie DeepSeek V3.2 aus!
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="deepseek/deepseek-v3.2",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].message.content)
Methode 2: Hugging Face Integration (5 Minuten)
Geeignet für: ML-Pipelines, Transformers-native Workflows
from huggingface_hub import InferenceClient
client = InferenceClient(
provider="novita",
api_key="sk_...YxTc",
)
completion = client.chat.completions.create(
model="deepseek-ai/DeepSeek-V3.2",
messages=[
{
"role": "user",
"content": "What is the capital of France?"
}
],
)
print(completion.choices[0].message)
Probieren Sie DeepSeek V3.2 aus!
Methode 3: Produktionsbereitstellung (Selbst gehostete Option)
Geeignet für: Hochvolumige Workloads, Anforderungen an die Datenhoheit
Bei einer Standard-Bereitstellung mit voller Präzision (FP16/BF16) erfordert die Inferenz mit DeepSeek-V3.2 extrem hohe Hardware-Anforderungen, da der kombinierte GPU-Speicher, der für Modellgewichte und Laufzeitausführung benötigt wird, etwa 1,3 TB übersteigt. Für BF16/FP16-Szenarien sind häufig Konfigurationen mit 16 H100-Klasse-GPUs mit jeweils 80 GB VRAM üblich, was zu einer gesamten GPU-Speicherkapazität von fast 1,3 TB führt.
| Quantisierungsstufe | Ungefährer Speicherbedarf |
|---|---|
| FP16 / BF16 | 1,3 TB gesamt |
| 8-Bit | 780 GB gesamt |
| 4-Bit | 380 GB gesamt |
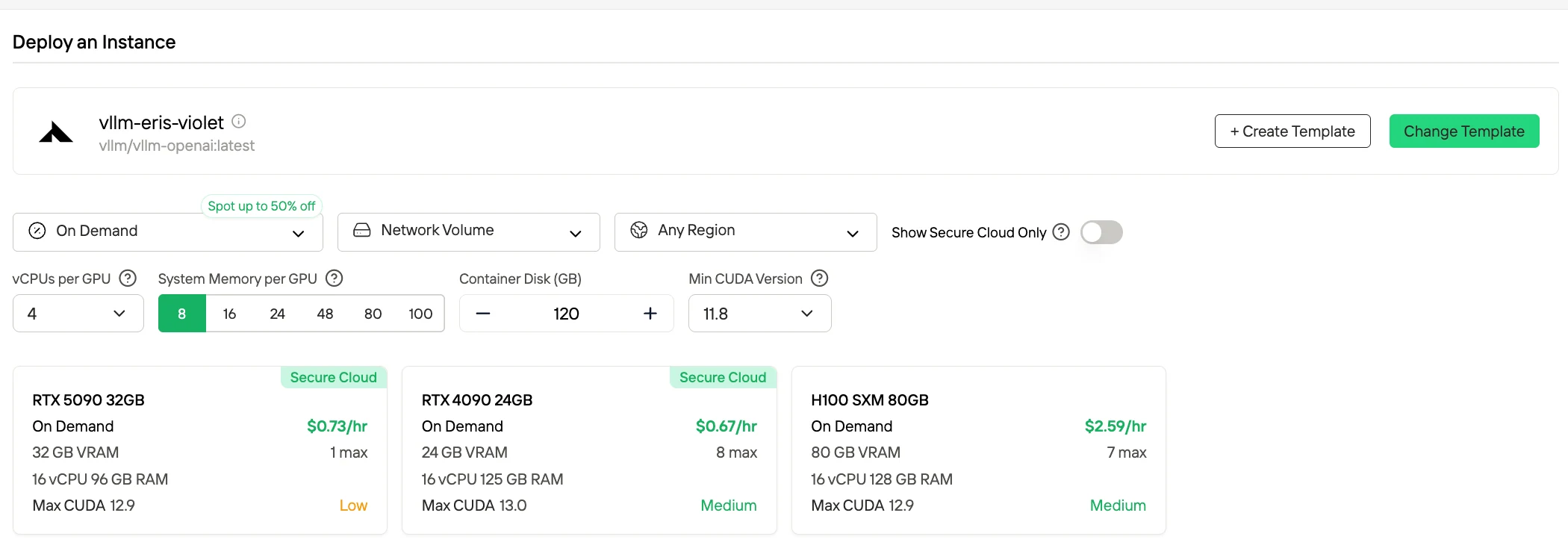
Probieren Sie jetzt schnelle und günstige GPUs aus!
Novita AI bietet außerdem den Spot-Modus, ein kostengünstiges GPU-Mietsystem, das die ungenutzte GPU-Kapazität der Plattform nutzt. Im Gegensatz zu On-Demand-Instanzen, die dedizierte Hardware für stabile, kontinuierliche Nutzung reservieren, sind Spot-Instanzen unterbrechbar – Ihr Job kann pausiert oder beendet werden, wenn die GPU vom System zurückgefordert wird. Da der Spot-Modus ansonsten ungenutzte GPU-Ressourcen neu zuweist, ist er in der Regel 40–60 % günstiger als On-Demand-Preise.
Praxisanwendungen & Prompting-Strategien
DeepSeek V3.2 zeichnet sich in Szenarien aus, die mehrstufiges Reasoning, Tool-Integration und Verständnis von langem Kontext erfordern.
Anwendungsfall 1: Agentisches Coding
DeepSeek V3.2 zeichnet sich in KI-Coding-Assistenten wie OpenCode oder Cursor aus, wo es Pull Requests über integrierten Tool-Aufruf generiert. Konfigurieren Sie es über eine OpenAI-kompatible API (wie Novita.ai), geben Sie System-Prompts für Experten-Coding und Tools zum Lesen/Schreiben von Dateien und Ausführen von Tests an. Eine Benutzeranfrage zum Refaktorieren von Authentifizierung von Sessions zu JWT löst schrittweises Reasoning aus und erzeugt präzise Code-Änderungen mit niedriger Temperatur (0,2) für Genauigkeit.
Verbinden Sie Novita AI einfach mit Partnerplattformen wie Claude Code, Trae, Continue, Codex, OpenCode, AnythingLLM, LangChain, Dify, Langflow und OpenClaw mithilfe von API-Integrationen und Schritt-für-Schritt-Setup-Anleitungen.
Anwendungsfall 2: Generierung mathematischer Beweise
Für mathematische Beweise wie den Nachweis, dass √2 irrational ist, verwenden Sie einen strukturierten Prompt, der schrittweises Denken anweist: nennen Sie die Beweisstrategie (z. B. Widerspruch), zeigen Sie Zwischenschritte und überprüfen Sie die Schlussfolgerungen. Rufen Sie das Modell mit Temperatur 0,1 für deterministisches Reasoning und hohem max_tokens (4096) auf, um detaillierte Erklärungen zu ermöglichen, und nutzen Sie dabei V3.2s fortschrittliches Reinforcement Learning für Mathematikleistung auf IMO-Niveau.
Anwendungsfall 3: Langkontext-Dokumentenanalyse
V3.2s 163K-Token-Kontext bewältigt etwa 120-seitige Verträge (~150K Token). Laden Sie den vollständigen Dokumenttext, und fordern Sie dann eine Analyse spezifischer Klauseln wie Haftungsrisiken an. Verwenden Sie eine moderate Temperatur (0,3) und max_tokens (8192) für umfassende Ausgaben, und platzieren Sie wichtige Anweisungen sowohl am Anfang als auch am Ende, um die Sparse Attention für genaue Langkontext-Extraktion zu optimieren.
DeepSeek V3.2 im Vergleich zu Alternativen auf Novita
Wann Sie V3.2 gegenüber anderen Modellen im Novita-Katalog wählen sollten:
| Vergleich | Wählen Sie DeepSeek V3.2, wenn… | Wählen Sie eine Alternative, wenn… |
|---|---|---|
| vs. GLM-5 | Budget-beschränkte Workloads, die groß angelegtes Reasoning erfordern. | Sie faktische Stabilität und niedrigere Halluzinationsraten gegenüber roher Reasoning-Leistung priorisieren. |
| vs. Qwen3-Coder-Next | Agentische Workflows, die Mathematik, Coding und Tool-Nutzung kombinieren. | Sie nur reine Coding-Aufgaben zu einem niedrigeren Preis benötigen. |
| vs. Kimi K2.5 | Hochvolumige Ausgaben oder Batch-Workloads, bei denen die Ausgabekosten eine Rolle spielen. | Sie unternehmensgrade Support oder Ökosystem-Integrationen benötigen. |
DeepSeek V3.2 auf Novita AI liefert fortgeschrittene Reasoning-Leistung zu 0,269 $/0,40 $ pro 1M Token mit revolutionärer DSA-Effizienz für Langkontext-Aufgaben. Für Entwickler, die agentische Coding-Systeme, Mathematik-Löser oder Dokumentenanalyse-Pipelines erstellen, ermöglicht Novitas OpenAI-kompatible API eine 2-minütige Bereitstellung mit branchenweit führender Latenz.
Fazit
DeepSeek V3.2 auf Novita AI kombiniert eine 685B-Parameter-MoE-Architektur mit DeepSeek Sparse Attention, um fortgeschrittene Reasoning-Leistung zu wettbewerbsfähigen Kosten zu liefern. Egal, ob Sie eine 2-minütige API-Integration, eine Hugging Face-Pipeline oder einen selbst gehosteten Multi-GPU-Cluster benötigen, Novita bietet einen flexiblen Weg zur Produktion.
Hauptvorteil: Für Entwickler, die agentische Coding-Systeme, Mathematik-Löser oder Langkontext-Dokumenten-Pipelines erstellen, ist DeepSeek V3.2 über Novita AIs OpenAI-kompatible API eine praktische, kosteneffiziente Wahl. Probieren Sie DeepSeek V3.2 auf Novita AI aus und beginnen Sie in Minuten mit der Entwicklung.
Häufig gestellte Fragen
Was ist der Unterschied zwischen DeepSeek V3.2 und V3.2-Exp?
V3.2-Exp war der experimentelle Vorläufer, der DSA eingeführt hat. Das Standard-V3.2 ist das Produktionsmodell mit ausgewogenem Reasoning/Tool-Nutzung. V3.2-Speciale ist eine forschungsorientierte Variante mit hoher Rechenleistung, die keine Tool-Aufrufe unterstützt.
Wie wechsle ich von OpenAI zu DeepSeek V3.2 auf Novita?
Ändern Sie zwei Zeilen: Aktualisieren Sie base_url="https://api.novita.ai/openai" und model="deepseek/deepseek-v3.2". Ihr vorhandener OpenAI-SDK-Code funktioniert ohne Änderungen, und holen Sie sich Ihren API-Schlüssel!
Was ist die beste Temperatureinstellung für DeepSeek V3.2?
Verwenden Sie 0,1–0,3 für Mathematik-, Coding- oder Reasoning-Aufgaben, bei denen es auf Genauigkeit ankommt. Verwenden Sie 0,5–0,7 für kreatives Schreiben oder Brainstorming. Niedrigere Temperaturen nutzen V3.2s deterministische Reasoning-Stärken.
Novita AI ist eine KI- & Agenten-Cloud-Plattform, die Entwicklern und Startups hilft, Modelle und agentische Anwendungen mit hoher Leistung, Zuverlässigkeit und Kosteneffizienz zu erstellen, bereitzustellen und zu skalieren.
Empfohlene Lektüre
GLM-5 in OpenCode: Open-Source-Alternative für Claude Code
ERNIE-4.5-VL-A3B VRAM-Anforderungen: Führen Sie multimodale Modelle zu geringeren Kosten aus
Qwen3 Embedding 8B: Leistungsstarke Suche, flexible Anpassung und mehrsprachig



