

DeepSeek V3.2 sur Novita AI apporte des performances de raisonnement de niveau médaille d’or aux IMO/IOI aux développeurs à $0,269/$0,40 par 1M de tokens d’entrée/sortie. Construit sur une architecture Mixture-of-Experts de 685B paramètres avec le DeepSeek Sparse Attention (DSA) révolutionnaire, ce modèle réduit la complexité computationnelle pour les tâches à contexte long tout en obtenant des résultats de premier plan dans les benchmarks de raisonnement.
Pour les développeurs créant des solveurs mathématiques, des agents de codage ou des flux de travail de raisonnement complexes, l’infrastructure serverless de Novita AI offre la latence la plus rapide de sa catégorie avec des endpoints compatibles OpenAI et Anthropic : changez simplement votre URL de base et commencez à l’utiliser en 2 minutes.
Qu’est-ce que DeepSeek V3.2 ?
DeepSeek V3.2 est un modèle de raisonnement Mixture-of-Experts de 685,4 milliards de paramètres avec 37 milliards de paramètres actifs par token, conçu pour un traitement efficace de contexte long et des performances agentiques supérieures. Publié en mise à jour de V3.1-Terminus, il introduit trois innovations révolutionnaires :
Architecture technique
| Spécification | Valeur |
|---|---|
| Paramètres totaux | 685B |
| Paramètres actifs | 37B par token |
| Configuration MoE | 256 experts routés, 8 actifs |
| Fenêtre de contexte | 163 840 tokens |
| Mécanisme d’attention | Hybride DSA + MLA |
| Précision | BF16 ; F8_E4M3 ; F32 |
Innovations principales
1. DeepSeek Sparse Attention (DSA) : Un mécanisme sparse granulaire utilisant un indexeur foudre et un sélecteur de tokens pour élaguer le contexte de manière sélective. Contrairement à l’attention traditionnelle qui traite tous les tokens, le DSA maintient les performances tout en réduisant la complexité computationnelle, ce qui est particulièrement critique pour les contextes de plus de 128K tokens.
2. Reinforcement Learning évolutif : Protocole post-entraînement avancé permettant des performances post-entraînement solides. La variante haute puissance de calcul (Speciale) obtient des performances de raisonnement de premier plan.
3. Pipeline de synthèse de tâches agentiques : Intègre systématiquement le raisonnement dans les scénarios d’utilisation d’outils à grande échelle, offrant une conformité et une généralisation supérieures pour les agents de codage et les flux de travail multi-étapes.
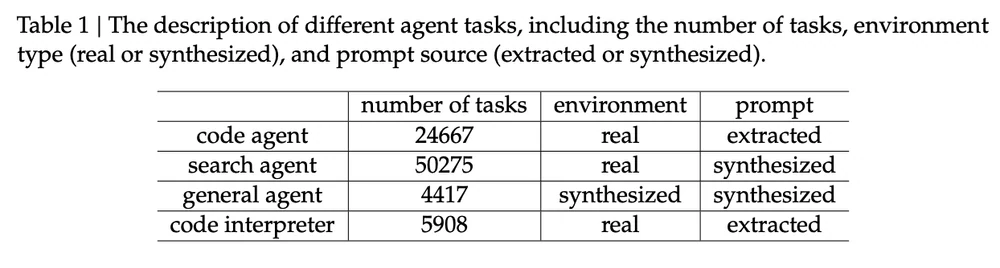
Tâches d’agent pour l’entraînement de DeepSeek-V3.2. Source de l’image
Benchmarks de performance
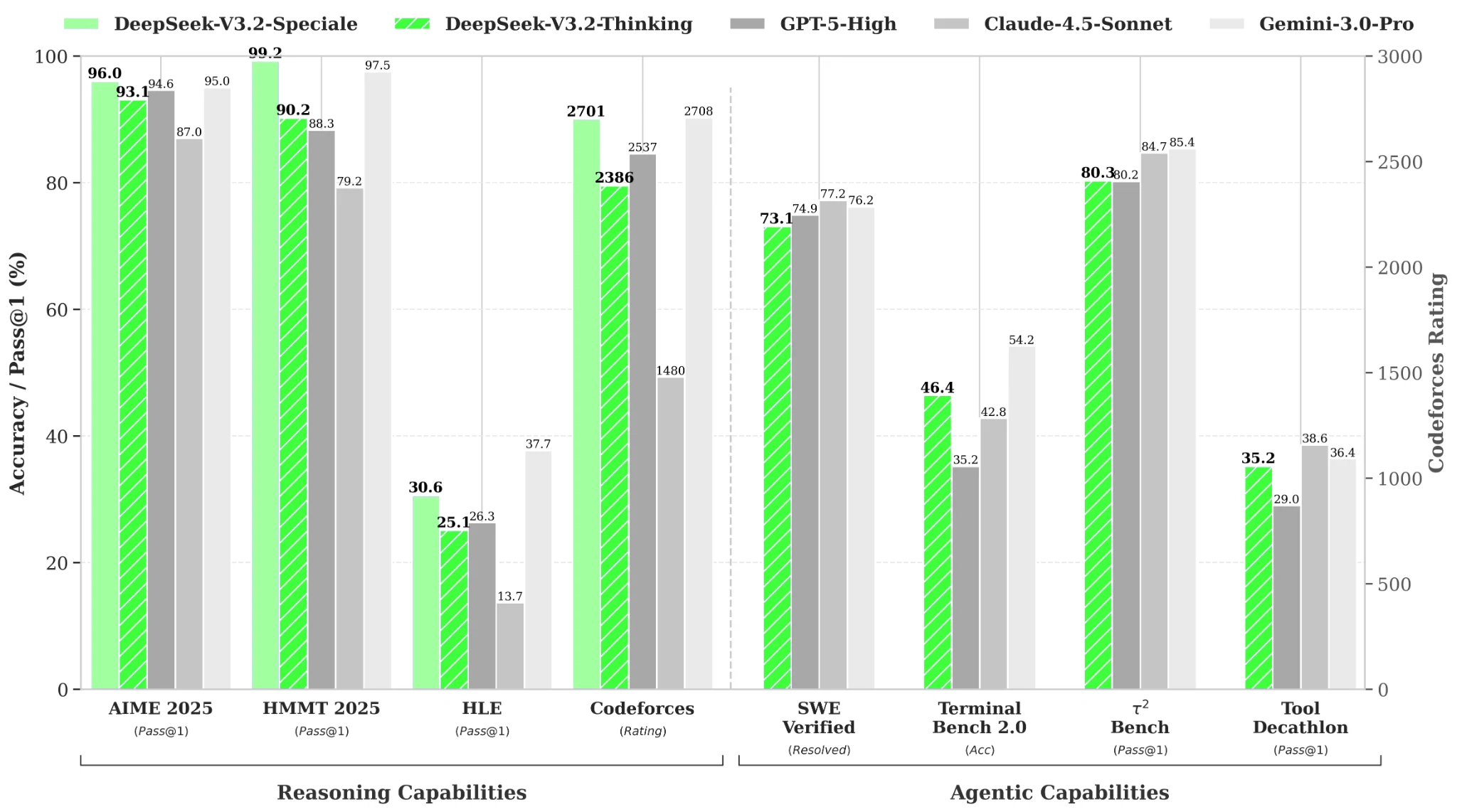
Depuis Hugging Face
Compromis efficacité / performance
Le DSA permet une réduction de 20 à 50 % des tokens de Chain-of-Thought tout en maintenant les scores des benchmarks. Un agent de codage traitant 50 pull requests par jour économise 180 $ par mois sur les coûts de tokens par rapport à V3.1, sans dégradation des performances.
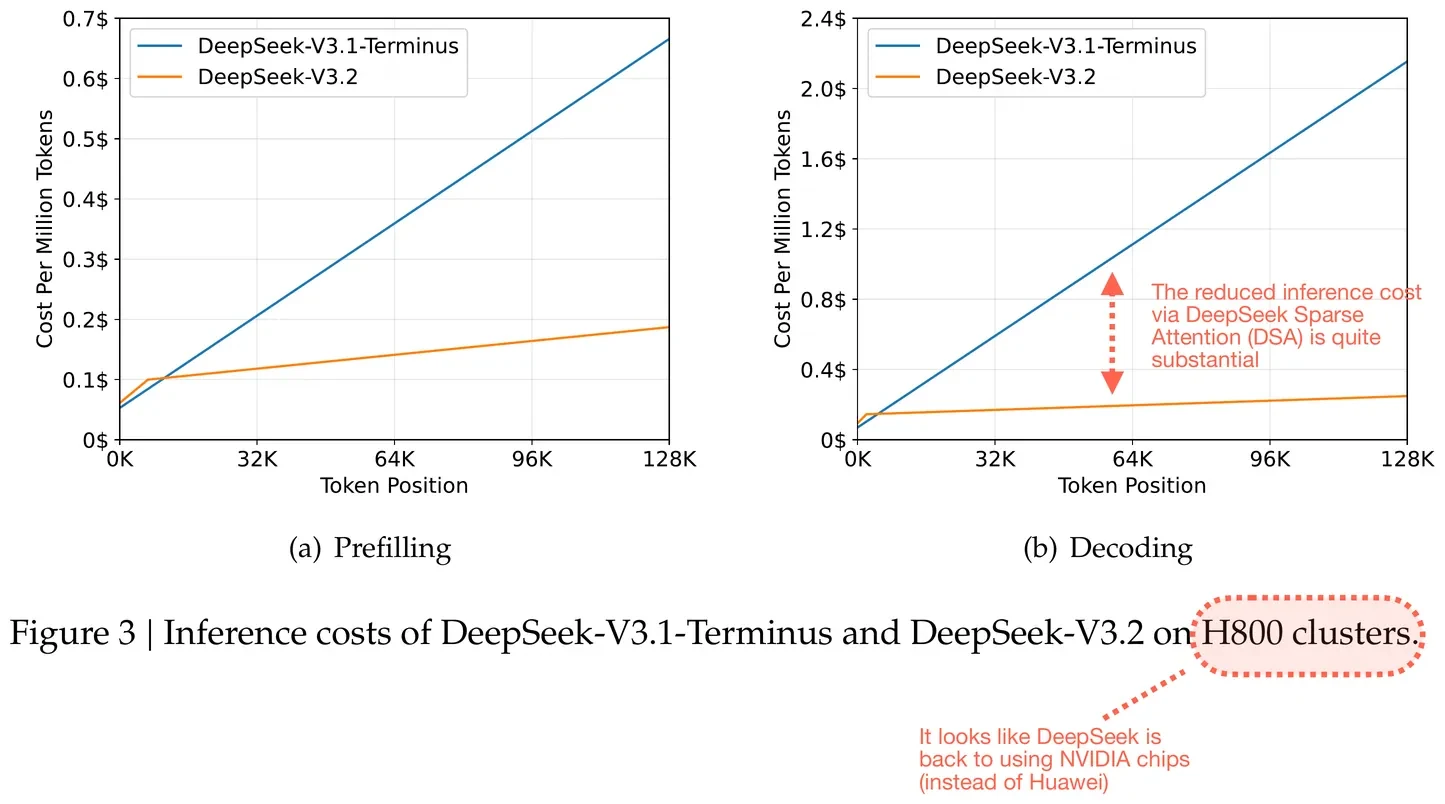
Économies de coûts d’inférence grâce à l’attention sparse DeepSeek (DSA). Figure annotée du rapport DeepSeek V3.2
Essayez DeepSeek V3.2 dès maintenant !
Pourquoi DeepSeek V3.2 sur Novita AI ?
Novita AI fournit un déploiement de production haute performance et rentable pour DeepSeek V3.2, avec des tarifs compétitifs. DeepSeek V3.2 sur Novita AI apporte des performances de raisonnement de niveau médaille d’or aux IMO/IOI aux développeurs à $0,269/$0,40 par 1M de tokens d’entrée/sortie.
Pour DeepSeek V3.2, la lecture de cache est facturée à 0,1345 $ / million de tokens sur Novita AI.
La lecture de cache fait référence au coût de lecture des tokens précédemment stockés dans le cache de prompts. Lorsque le même contenu de prompt est réutilisé entre plusieurs requêtes, le modèle récupère ces tokens directement depuis le cache au lieu de les traiter à nouveau depuis zéro. Cela réduit à la fois la latence d’inférence et les coûts.
Essayez DeepSeek V3.2 dès maintenant !
6 raisons de choisir Novita AI
1. Compatible OpenAI et Anthropic : Remplacement plug-and-play nécessitant uniquement un changement d’URL de base. Le code SDK OpenAI existant fonctionne instantanément : pas de réécriture, pas de courbe d’apprentissage.
2. Mise à l’échelle automatique serverless : Gérez des pics de trafic de 10 à 10 000 requêtes par minute sans provisionnement. Ne payez que pour les tokens utilisés : pas de coûts de GPU inactifs.
3. Fiabilité de niveau entreprise : Infrastructure conforme SOC 2 avec redondance multi-région. SLA de disponibilité de 99,5 % pour les charges de travail de production.
4. Écosystème de plus de 200 modèles : Accédez à GLM-5, Qwen3-Coder-Next, MiniMax M2.5 et autres modèles de pointe via une API unifiée : testez des alternatives sans modification d’infrastructure.
5. Facturation transparente : Tarification par token sans frais cachés. Le tableau de bord en temps réel affiche les coûts exacts par requête : budgétisez en toute confiance.

Essayez DeepSeek V3.2 dès maintenant !
Comment accéder à DeepSeek V3.2 sur Novita AI
Trois méthodes de déploiement, du démarrage rapide de 2 minutes aux pipelines de production :
Méthode 1 : Démarrage rapide API (2 minutes)
Idéal pour : Tests, prototypes, applications existantes basées sur OpenAI
Étapes de configuration :
- Inscrivez-vous sur novita.ai (l’offre gratuite inclut des crédits)
- Accédez au Tableau de bord → Clés API → Générez une nouvelle clé
- Mettez à jour votre code avec l’endpoint Novita :
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="deepseek/deepseek-v3.2",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].message.content)
Méthode 2 : Intégration Hugging Face (5 minutes)
Idéal pour : Pipelines ML, workflows natifs Transformers
from huggingface_hub import InferenceClient
client = InferenceClient(
provider="novita",
api_key="sk_...YxTc",
)
completion = client.chat.completions.create(
model="deepseek-ai/DeepSeek-V3.2",
messages=[
{
"role": "user",
"content": "What is the capital of France?"
}
],
)
print(completion.choices[0].message)
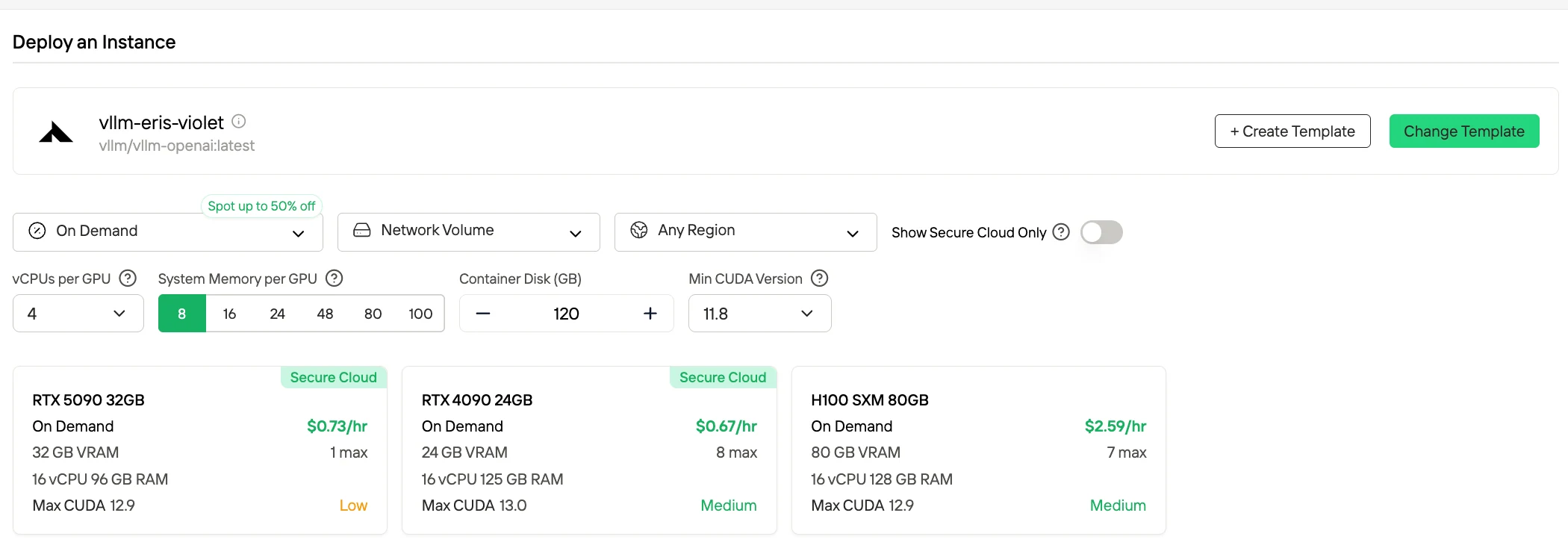
Méthode 3 : Déploiement en production (option auto-hébergée)
Idéal pour : Charges de travail à haut volume, exigences de souveraineté des données
Dans le cadre d’un déploiement en pleine précision standard (FP16/BF16), l’inférence avec DeepSeek-V3.2 impose des exigences matérielles extrêmement élevées, car la mémoire GPU combinée nécessaire pour les poids du modèle et l’exécution runtime dépasse environ 1,3 To. Pour les scénarios BF16/FP16, les configurations couramment adoptées incluent 16 GPU de classe H100 avec 80 Go de VRAM chacun, soit une capacité totale de mémoire GPU d’environ 1,3 To.
| Niveau de quantification | Empreinte mémoire approximative |
|---|---|
| FP16 / BF16 | 1,3 To total |
| 8 bits | 780 Go total |
| 4 bits | 380 Go total |
Essayez des GPU rapides et peu coûteux dès maintenant !
Novita AI propose également le mode Spot, un système de location de GPU optimisé pour les coûts qui exploite la capacité GPU inactive ou inutilisée de la plateforme. Contrairement aux instances à la demande, qui réservent du matériel dédié pour une utilisation stable et continue, les instances Spot sont interruptibles : votre travail peut être mis en pause ou interrompu si le GPU est récupéré par le système. Comme le mode Spot réaffecte des ressources GPU qui seraient autrement inactives, il est généralement 40 à 60 % moins cher que la tarification à la demande.
Cas d’usage concrets et stratégies de prompting
DeepSeek V3.2 excelle dans les scénarios nécessitant un raisonnement multi-étapes, une intégration d’outils et une compréhension de contexte long.
Cas d’usage 1 : Codage agentique
DeepSeek V3.2 excelle dans les assistants de codage IA comme OpenCode ou Cursor, où il génère des pull requests via des appels d’outils intégrés. Configurez-le via une API compatible OpenAI (comme Novita.ai), en fournissant des prompts système pour un codage expert et des outils pour la lecture/écriture de fichiers et l’exécution de tests. Une demande utilisateur de refactorisation de l’authentification de sessions vers JWT déclenche un raisonnement étape par étape, produisant des modifications de code précises avec une température basse (0,2) pour la précision.
Connectez facilement Novita AI à des plateformes partenaires comme Claude Code, Trae, Continue, Codex, OpenCode, AnythingLLM, LangChain, Dify, Langflow et OpenClaw grâce à des intégrations API et des guides de configuration étape par étape.
Cas d’usage 2 : Génération de preuves mathématiques
Pour des preuves mathématiques comme démontrer que √2 est irrationnel, utilisez un prompt structuré qui demande un raisonnement étape par étape : indiquez la stratégie de preuve (par exemple, par l’absurde), montrez les étapes intermédiaires et vérifiez les conclusions. Appelez le modèle avec une température de 0,1 pour un raisonnement déterministe et un max_tokens élevé (4096) pour autoriser des explications détaillées, en tirant parti de l’apprentissage par renforcement avancé de V3.2 pour des performances mathématiques de niveau IMO.
Cas d’usage 3 : Analyse de documents à contexte long
Le contexte de 163K tokens de V3.2 permet de traiter des contrats juridiques d’environ 120 pages (~150K tokens). Chargez l’intégralité du texte du document, puis demandez une analyse de clauses spécifiques comme les risques de responsabilité. Utilisez une température modérée (0,3) et un max_tokens de 8192 pour une sortie complète, en plaçant des instructions clés au début et à la fin pour optimiser l’attention sparse et garantir une extraction précise du contexte long.
DeepSeek V3.2 vs. les alternatives sur Novita
Quand choisir V3.2 plutôt que les autres modèles du catalogue Novita :
| Comparaison | Choisissez DeepSeek V3.2 quand… | Choisissez une alternative quand… |
|---|---|---|
| vs. GLM-5 | Charges de travail à budget limité nécessitant un raisonnement à grande échelle. | Vous privilégiez la stabilité factuelle et des taux d’hallucination plus faibles plutôt que des performances de raisonnement brutes. |
| vs. Qwen3-Coder-Next | Flux de travail agentiques combinant mathématiques, codage et utilisation d’outils. | Vous n’avez besoin que de tâches de codage pur à un prix plus bas. |
| vs. Kimi K2.5 | Charges de travail de sortie à haut volume ou par lots où le coût de sortie est important. | Vous avez besoin d’un support de niveau entreprise ou d’intégrations d’écosystème. |
DeepSeek V3.2 sur Novita AI offre des performances de raisonnement avancées à 0,269/0,40 $ par 1M de tokens, avec une efficacité DSA révolutionnaire pour les tâches à contexte long. Pour les développeurs créant des systèmes de codage agentiques, des solveurs mathématiques ou des pipelines d’analyse de documents, l’API compatible OpenAI de Novita permet un déploiement en 2 minutes avec une latence leader du secteur.
Conclusion
DeepSeek V3.2 sur Novita AI combine une architecture MoE de 685B paramètres avec l’attention sparse DeepSeek pour offrir des performances de raisonnement avancées à un coût compétitif. Que vous ayez besoin d’une intégration API en 2 minutes, d’un pipeline Hugging Face ou d’un cluster multi-GPU auto-hébergé, Novita propose un chemin flexible vers la production.
Point clé à retenir : Pour les développeurs créant des systèmes de codage agentiques, des solveurs mathématiques ou des pipelines de documents à contexte long, DeepSeek V3.2 via l’API compatible OpenAI de Novita AI est un choix pratique et rentable. Essayez DeepSeek V3.2 sur Novita AI et commencez à développer en quelques minutes.
Foire aux questions
Quelle est la différence entre DeepSeek V3.2 et V3.2-Exp ?
V3.2-Exp était le précurseur expérimental introduisant le DSA. V3.2 standard est le modèle de production avec un équilibre raisonnement/utilisation d’outils. V3.2-Speciale est une variante haute puissance de calcul réservée à la recherche, sans appel d’outils.
Comment passer d’OpenAI à DeepSeek V3.2 sur Novita ?
Modifiez deux lignes : mettez à jour base_url="https://api.novita.ai/openai" et model="deepseek/deepseek-v3.2". Votre code SDK OpenAI existant fonctionne sans modification, et récupérez votre clé API !
Quelle est la meilleure valeur de température pour DeepSeek V3.2 ?
Utilisez 0,1 à 0,3 pour les tâches de mathématiques/codage/raisonnement où la précision est importante. Utilisez 0,5 à 0,7 pour la création littéraire ou le brainstorming. Les températures plus basses exploitent les forces de raisonnement déterministe de V3.2.
Novita AI est une plateforme cloud IA et agentique aidant les développeurs et les startups à créer, déployer et mettre à l’échelle des modèles et des applications agentiques avec des performances élevées, une fiabilité et une efficacité de coûts.
Lectures recommandées
GLM-5 dans OpenCode : Alternative open source à Claude Code
Exigences VRAM d’ERNIE-4.5-VL-A3B : Exécutez des modèles multimodaux à moindre coût
Qwen3 Embedding 8B : Recherche puissante, personnalisation flexible et multilingue



