

O DeepSeek V3.2 na Novita AI traz desempenho de raciocínio de medalha de ouro nas Olimpíadas Internacionais de Matemática (IMO) e Olimpíadas Internacionais de Informática (IOI) para desenvolvedores por $0,269/$0,40 por 1M de tokens de entrada/saída. Construído em uma arquitetura Mixture-of-Experts de 685B de parâmetros, com o revolucionário DeepSeek Sparse Attention (DSA), este modelo reduz a complexidade computacional para tarefas de longo contexto, ao mesmo tempo que alcança resultados de nível superior em benchmarks de raciocínio.
Para desenvolvedores que criam solucionadores de matemática, agentes de codificação ou fluxos de trabalho de raciocínio complexo, a infraestrutura serverless da Novita AI oferece latência de classe líder, com endpoints compatíveis com OpenAI e Anthropic — basta alterar a URL base e começar a executar em 2 minutos.
O que é o DeepSeek V3.2?
O DeepSeek V3.2 é um modelo de raciocínio Mixture-of-Experts com 685,4B de parâmetros, com 37B de parâmetros ativos por token, projetado para processamento eficiente de longo contexto e desempenho agênico superior. Lançado como uma atualização do V3.1-Terminus, ele apresenta três inovações revolucionárias:
Arquitetura Técnica
| Especificação | Valor |
|---|---|
| Total de Parâmetros | 685B |
| Parâmetros Ativos | 37B por token |
| Configuração MoE | 256 especialistas roteados, 8 ativos |
| Janela de Contexto | 163.840 tokens |
| Mecanismo de Atenção | Híbrido DSA + MLA |
| Precisão | BF16; F8_E4M3; F32 |
Inovações Principais
1. DeepSeek Sparse Attention (DSA): Um mecanismo esparso de granularidade fina que usa um indexador rápido e um seletor de tokens para podar o contexto de forma seletiva. Diferente da atenção tradicional que processa todos os tokens, o DSA mantém o desempenho enquanto reduz a complexidade computacional — especialmente crítico para contextos de 128K+ tokens.
2. Aprendizado por Reforço Escalável: Protocolo avançado de pós-treinamento que permite um desempenho forte após o treinamento. A variante de alta computação (Speciale) alcança desempenho de raciocínio de nível superior.
3. Pipeline de Síntese de Tarefas Agênicas: Integra sistematicamente o raciocínio em cenários de uso de ferramentas em grande escala, oferecendo conformidade e generalização superiores para agentes de codificação e fluxos de trabalho de múltiplas etapas.
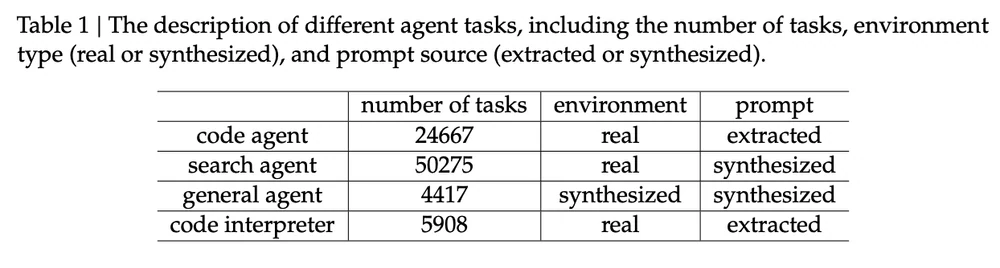
Tarefas de agente para treinamento do DeepSeek-V3.2. Fonte da imagem
Benchmarks de Desempenho
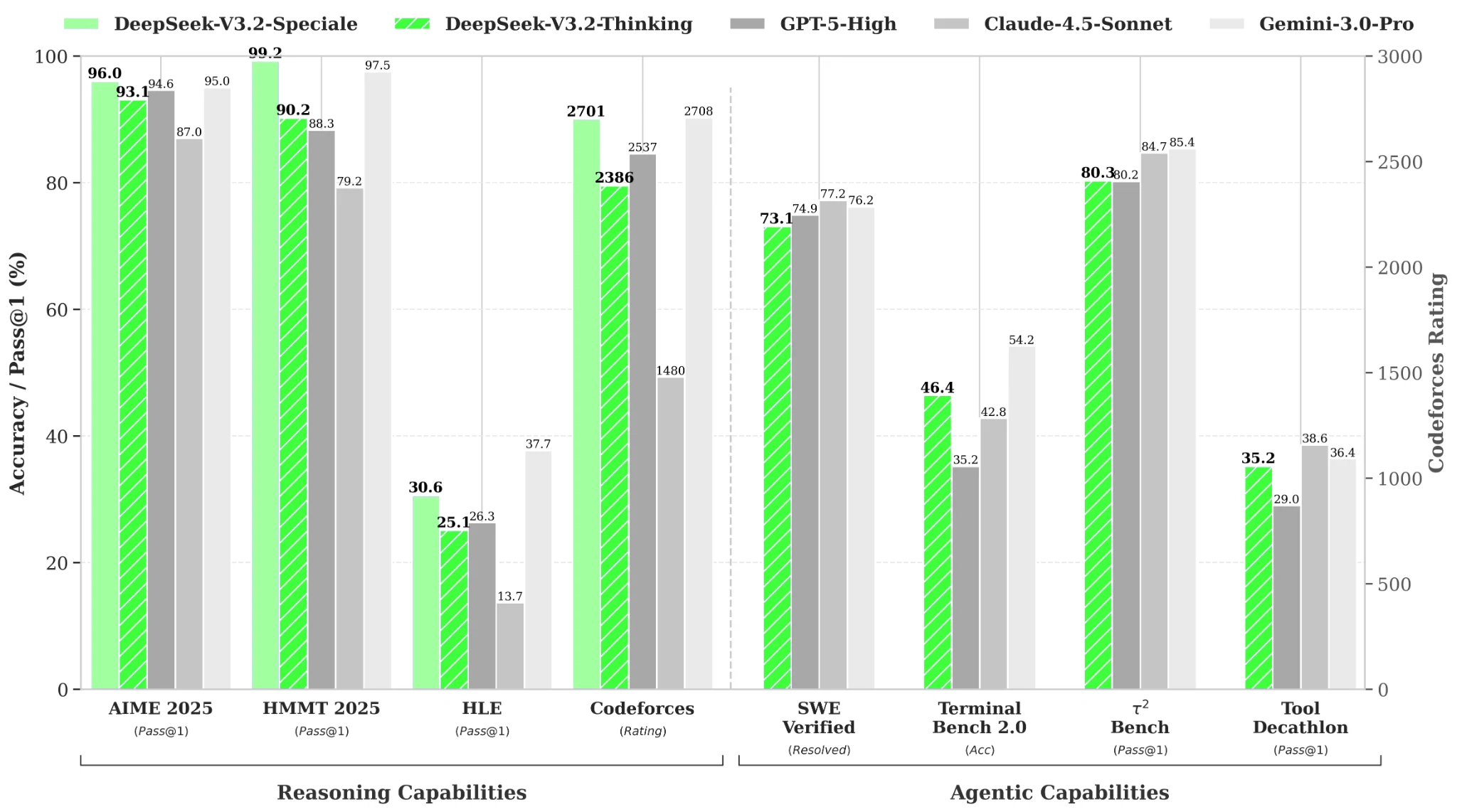
Fonte: Hugging Face
Trade-off entre Eficiência e Desempenho
O DSA proporciona uma redução de 20-50% nos tokens de Cadeia de Pensamento (Chain-of-Thought), mantendo as pontuações nos benchmarks. Um agente de codificação que processa 50 pull requests por dia economiza $180/mês em custos de tokens em comparação com o V3.1, sem degradação de desempenho.
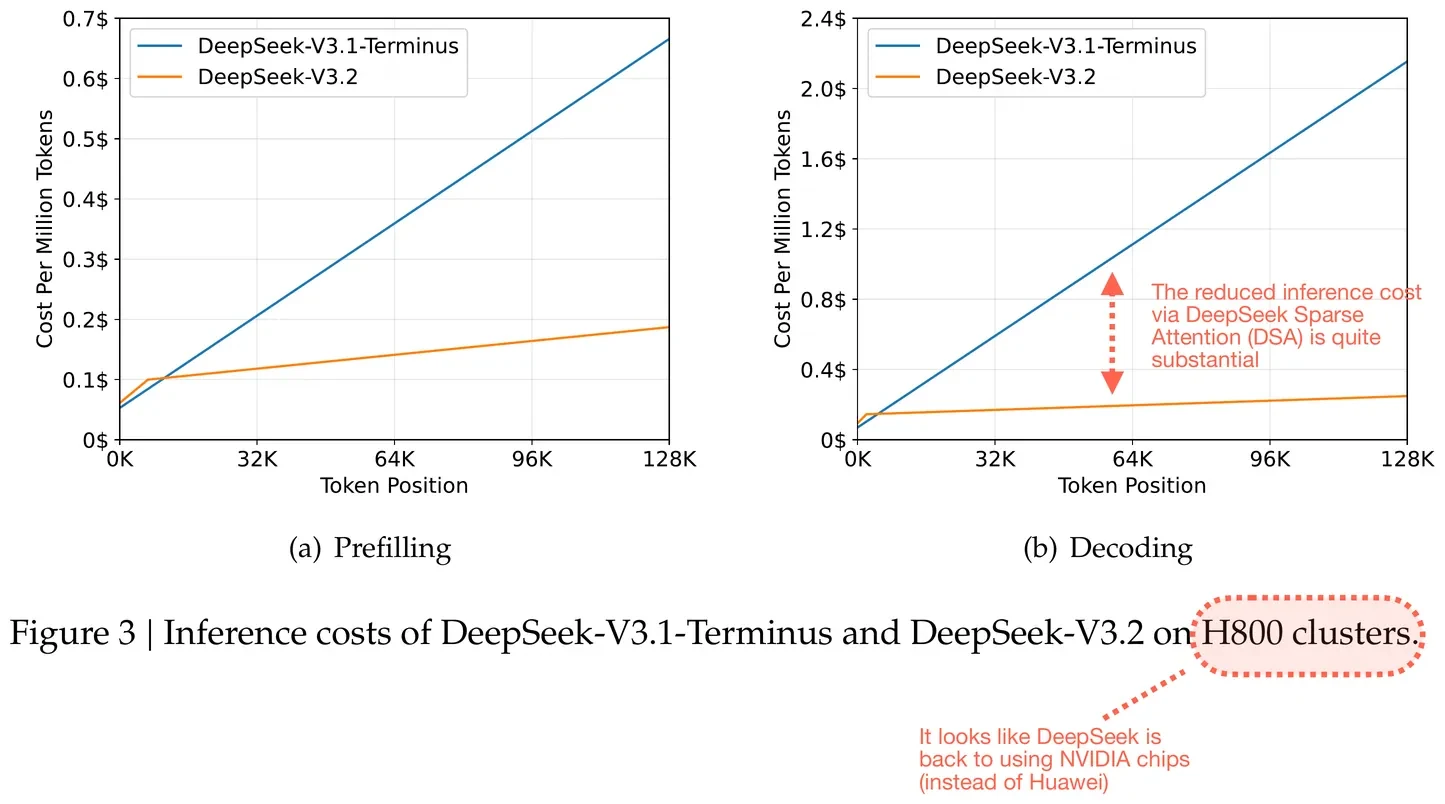
Economia de custos de inferência graças ao DeepSeek Sparse Attention (DSA). Figura anotada do relatório do DeepSeek V3.2
Experimente o DeepSeek V3.2 agora!
Por que escolher o DeepSeek V3.2 na Novita AI?
A Novita AI oferece implantação em produção de alto desempenho e custo-benefício para o DeepSeek V3.2, com preços competitivos. O DeepSeek V3.2 na Novita AI traz desempenho de raciocínio de medalha de ouro nas IMO/IOI para desenvolvedores por $0,269/$0,40 por 1M de tokens de entrada/saída.
Para o DeepSeek V3.2, a leitura de cache (Cache Read) é cobrada a $0,1345 / M tokens na Novita AI.
O Cache Read se refere ao custo de leitura de tokens que foram armazenados anteriormente no cache de prompts. Quando o mesmo conteúdo de prompt é reutilizado em várias solicitações, o modelo recupera esses tokens diretamente do cache, em vez de processá-los novamente do zero. Isso reduz tanto a latência de inferência quanto o custo.
Experimente o DeepSeek V3.2 agora!
6 Motivos para escolher a Novita AI
1. Compatível com OpenAI e Anthropic: Substituição imediata que requer apenas a alteração da URL base. O código existente do SDK da OpenAI funciona instantaneamente — sem reescritas, sem curva de aprendizado.
2. Escalonamento Automático Serverless: Lide com picos de tráfego de 10 a 10.000 solicitações por minuto sem provisionamento. Pague apenas pelos tokens usados — sem custos de GPU ociosa.
3. Confiabilidade de Nível Empresarial: Infraestrutura em conformidade com a SOC 2 com redundância multirregional. SLA de 99,5% de tempo de atividade para cargas de trabalho de produção.
4. Ecossistema de mais de 200 modelos: Acesse o GLM-5, Qwen3-Coder-Next, MiniMax M2.5 e outros modelos de ponta por meio de uma API unificada — teste alternativas sem alterações de infraestrutura.
5. Cobrança Transparente: Preço por token, sem taxas ocultas. O painel em tempo real mostra os custos exatos por solicitação — planeje seu orçamento com confiança.

Experimente o DeepSeek V3.2 agora!
Como acessar o DeepSeek V3.2 na Novita AI
Três métodos de implantação, do início rápido de 2 minutos a pipelines de nível de produção:
Método 1: Início Rápido via API (2 minutos)
Ideal para: Testes, protótipos, aplicativos existentes baseados em OpenAI
Passos de Configuração:
- Cadastre-se em novita.ai (o plano gratuito inclui créditos)
- Acesse o Painel → Chaves de API → Gere uma nova chave
- Atualize seu código com o endpoint da Novita:
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="deepseek/deepseek-v3.2",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].message.content)
Método 2: Integração com o Hugging Face (5 minutos)
Ideal para: Pipelines de ML, fluxos de trabalho nativos do Transformers
from huggingface_hub import InferenceClient
client = InferenceClient(
provider="novita",
api_key="sk_...YxTc",
)
completion = client.chat.completions.create(
model="deepseek-ai/DeepSeek-V3.2",
messages=[
{
"role": "user",
"content": "What is the capital of France?"
}
],
)
print(completion.choices[0].message)
Método 3: Implantação em Produção (Opção Auto-Hospedada)
Ideal para: Cargas de trabalho de alto volume, requisitos de soberania de dados
Em implantações padrão de precisão total (FP16/BF16), a inferência com o DeepSeek-V3.2 impõe requisitos de hardware extremamente altos, pois a memória GPU combinada necessária para os pesos do modelo e a execução em tempo de execução excede aproximadamente 1,3 TB. Para cenários BF16/FP16, as configurações comumente adotadas incluem 16 GPUs da classe H100 com 80 GB de VRAM cada, totalizando uma capacidade de memória GPU de quase 1,3 TB.
| Nível de Quantização | Pegada de Memória Aproximada |
|---|---|
| FP16 / BF16 | 1,3 TB total |
| 8-bit | 780 GB total |
| 4-bit | 380 GB total |
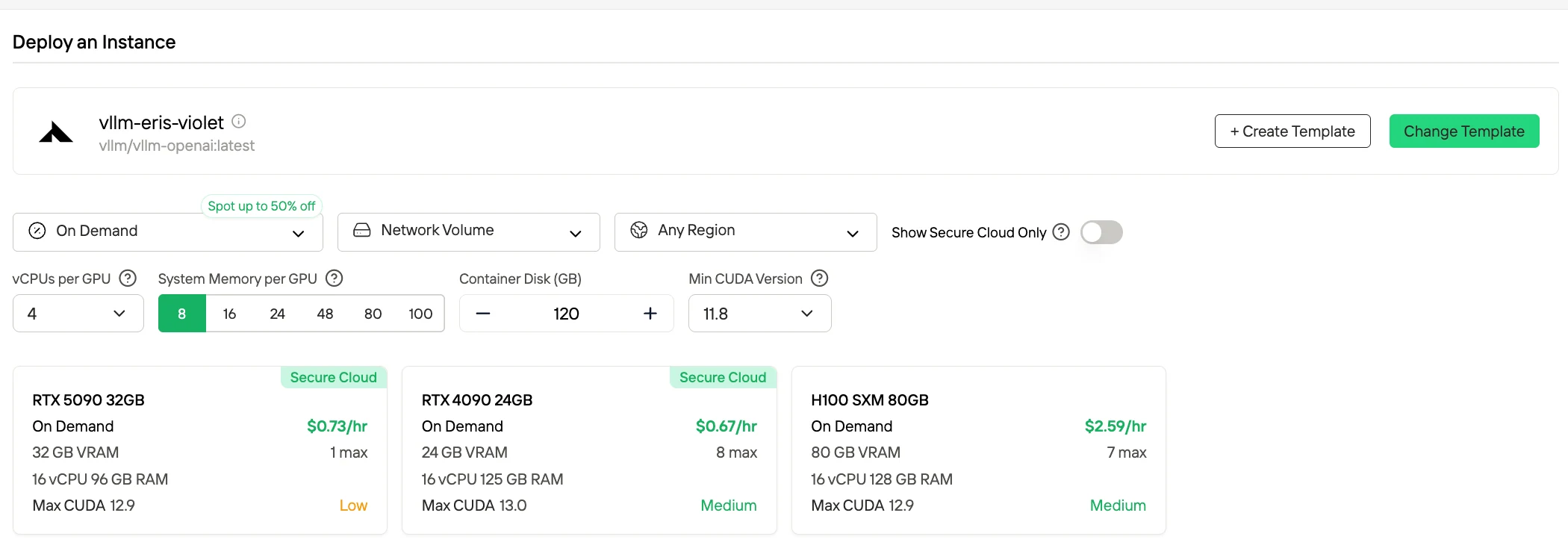
Experimente GPUs rápidas e baratas agora!
A Novita AI também oferece o modo Spot, um sistema de aluguel de GPUs otimizado para custos que aproveita a capacidade de GPU ociosa ou não utilizada da plataforma. Diferente das instâncias sob demanda, que reservam hardware dedicado para uso estável e contínuo, as instâncias Spot são interrompíveis — seu trabalho pode ser pausado ou encerrado se a GPU for recuperada pelo sistema. Como o modo Spot realoca recursos de GPU que de outra forma estariam ociosos, ele é geralmente 40-60% mais barato que os preços sob demanda.
Casos de Uso Reais e Estratégias de Prompting
O DeepSeek V3.2 se destaca em cenários que exigem raciocínio de múltiplas etapas, integração de ferramentas e compreensão de longo contexto.
Caso de Uso 1: Codificação Agênica
O DeepSeek V3.2 se destaca em assistentes de codificação de IA como OpenCode ou Cursor, onde ele gera pull requests por meio de chamadas de ferramentas integradas. Configure-o por meio de uma API compatível com OpenAI (como a Novita.ai), fornecendo prompts de sistema para codificação especializada e ferramentas para leitura/gravação de arquivos e execução de testes. Uma solicitação de usuário para refatorar a autenticação de sessões para JWT aciona um raciocínio passo a passo, produzindo alterações de código precisas com temperatura baixa (0,2) para garantir precisão.
Conecte facilmente a Novita AI a plataformas parceiras como Claude Code, Trae, Continue, Codex, OpenCode, AnythingLLM, LangChain, Dify, Langflow e OpenClaw usando integrações de API e guias de configuração passo a passo.
Caso de Uso 2: Geração de Provas Matemáticas
Para provas matemáticas, como demonstrar que √2 é irracional, use um prompt estruturado que instrua o pensamento passo a passo: declare a estratégia da prova (ex: contradição), mostre os passos intermediários e verifique as conclusões. Chame o modelo com temperatura 0,1 para raciocínio determinístico e max_tokens alto (4096) para permitir explicações detalhadas, aproveitando o aprendizado por reforço avançado do V3.2 para desempenho matemático de nível IMO.
Caso de Uso 3: Análise de Documentos de Longo Contexto
O contexto de 163K tokens do V3.2 lida com contratos legais de ~120 páginas (~150K tokens). Carregue o texto completo do documento e, em seguida, solicite a análise de cláusulas específicas, como riscos de responsabilidade. Use temperatura moderada (0,3) e max_tokens (8192) para uma saída abrangente, colocando instruções-chave no início e no fim para otimizar a atenção esparsa para uma extração precisa de longo contexto.
DeepSeek V3.2 vs. Alternativas na Novita
Quando escolher o V3.2 em vez de outros modelos do catálogo da Novita:
| Comparação | Escolha o DeepSeek V3.2 quando… | Escolha uma alternativa quando… |
|---|---|---|
| vs. GLM-5 | Cargas de trabalho com orçamento limitado que exigem raciocínio em larga escala. | Você prioriza estabilidade factual e taxas de alucinação mais baixas em vez de desempenho de raciocínio bruto. |
| vs. Qwen3-Coder-Next | Fluxos de trabalho agênicos que combinam matemática, codificação e uso de ferramentas. | Você precisa apenas de tarefas de codificação puras a um preço mais baixo. |
| vs. Kimi K2.5 | Saída de alto volume ou cargas de trabalho em lote em que o custo de saída é relevante. | Você precisa de suporte de nível empresarial ou integrações de ecossistema. |
O DeepSeek V3.2 na Novita AI oferece desempenho de raciocínio avançado por $0,269/$0,40 por 1M de tokens, com a eficiência revolucionária do DSA para tarefas de longo contexto. Para desenvolvedores que criam sistemas de codificação agênica, solucionadores matemáticos ou pipelines de análise de documentos, a API compatível com OpenAI da Novita permite implantação em 2 minutos com latência líder de mercado.
Conclusão
O DeepSeek V3.2 na Novita AI combina uma arquitetura MoE de 685B de parâmetros com o DeepSeek Sparse Attention para oferecer desempenho de raciocínio avançado a um custo competitivo. Seja você precisar de uma integração de API de 2 minutos, um pipeline do Hugging Face ou um cluster multi-GPU auto-hospedado, a Novita oferece um caminho flexível para a produção.
Principal Conclusão: Para desenvolvedores que criam sistemas de codificação agênica, solucionadores matemáticos ou pipelines de documentos de longo contexto, o DeepSeek V3.2 via API compatível com OpenAI da Novita AI é uma escolha prática e econômica. Experimente o DeepSeek V3.2 na Novita AI e comece a construir em minutos.
Perguntas Frequentes
Qual a diferença entre o DeepSeek V3.2 e o V3.2-Exp?
O V3.2-Exp foi o precursor experimental que introduziu o DSA. O V3.2 padrão é o modelo de produção com raciocínio/uso de ferramentas equilibrado. O V3.2-Speciale é uma variante de alta computação, exclusiva para pesquisa, sem suporte a chamadas de ferramentas.
Como migro do OpenAI para o DeepSeek V3.2 na Novita?
Altere apenas duas linhas: atualize base_url="https://api.novita.ai/openai" e model="deepseek/deepseek-v3.2". Seu código existente do SDK da OpenAI funciona sem modificações, e obtenha sua chave de API!
Qual a melhor configuração de temperatura para o DeepSeek V3.2?
Use 0,1-0,3 para tarefas de matemática/codificação/raciocínio em que a precisão é importante. Use 0,5-0,7 para redação criativa ou brainstorming. Temperaturas mais baixas aproveitam os pontos fortes de raciocínio determinístico do V3.2.
A Novita AI é uma plataforma de nuvem de IA e agentes que ajuda desenvolvedores e startups a construir, implantar e escalar modelos e aplicações agênicas com alto desempenho, confiabilidade e eficiência de custos.
Leituras Recomendadas
GLM-5 no OpenCode: Alternativa Open Source para o Claude Code
Requisitos de VRAM do ERNIE-4.5-VL-A3B: Execute Modelos Multimodais a Custo Reduzido
Qwen3 Embedding 8B: Busca Poderosa, Personalização Flexível e Multilíngue



