

يقدم DeepSeek V3.2 على Novita AI أداء استدلال حاصل على ميدالية ذهبية في مسابقات IMO/IOI للمطورين بسعر 0.269 دولار/0.40 دولار لكل مليون رمز إدخال/إخراج. مبني على بنية الخبراء المختلطين (Mixture-of-Experts) ذات 685 مليار معامل، مع آلية الانتباه المتناثر الثورية لـ DeepSeek (DSA)، يقلل هذا النموذج من التعقيد الحسابي للمهام ذات السياق الطويل بينما يحقق نتائج من الفئة الأولى في معايير الاستدلال.
للمطورين الذين يبنون حلول مسائل رياضية، وكلاء برمجة، أو سير عمل استدلال معقد، توفر البنية التحتية بدون خوادم من Novita AI أدنى زمن استجابة في فئتها مع نقاط نهاية متوافقة مع OpenAI و Anthropic — ما عليك سوى تغيير عنوان URL الأساسي وتبدأ العمل في دقيقتين.
ما هو DeepSeek V3.2؟
DeepSeek V3.2 هو نموذج استدلال من نوع الخبراء المختلطين (Mixture-of-Experts) يحتوي على 685.4 مليار معامل، مع 37 مليار معامل نشط لكل رمز، مصمم لمعالجة السياقات الطويلة بكفاءة وأداء متفوق للوكلاء. تم إصداره كتحديث لـ V3.1-Terminus، ويقدم ثلاث ابتكارات رائدة:
البنية التقنية
| المواصفات | القيمة |
|---|---|
| إجمالي المعاملات | 685 مليار |
| المعاملات النشطة | 37 مليار لكل رمز |
| تكوين MoE | 256 خبير مُوجه، 8 نشطين |
| نافذة السياق | 163,840 رمز |
| آلية الانتباه | مزيج من DSA + MLA |
| الدقة | BF16; F8_E4M3; F32 |
الابتكارات الأساسية
1. آلية الانتباه المتناثر لـ DeepSeek (DSA): آلية متناثرة دقيقة تستخدم فهرس البرق ومحدد الرموز لاقتطاع السياق بشكل انتقائي. على عكس آلية الانتباه التقليدية التي تعالج جميع الرموز، تحافظ DSA على الأداء بينما تقلل من التعقيد الحسابي — وهو أمر بالغ الأهمية خاصة للسياقات التي تحتوي على أكثر من 128 ألف رمز.
2. التعزيز القابل للتطوير: بروتوكول تدريب لاحق متقدم يتيح أداء قوي بعد التدريب. يحقق النوع عالي الحساب (Speciale) أداء استدلال من الفئة الأولى.
3. خطوة تجميع مهام الوكلاء: يدمج الاستدلال بشكل منهجي في سيناريوهات استخدام الأدوات على نطاق واسع، مما يوفر امتثالًا وتعميمًا متفوقًا لوكلاء البرمجة وسير العمل متعددة الخطوات.
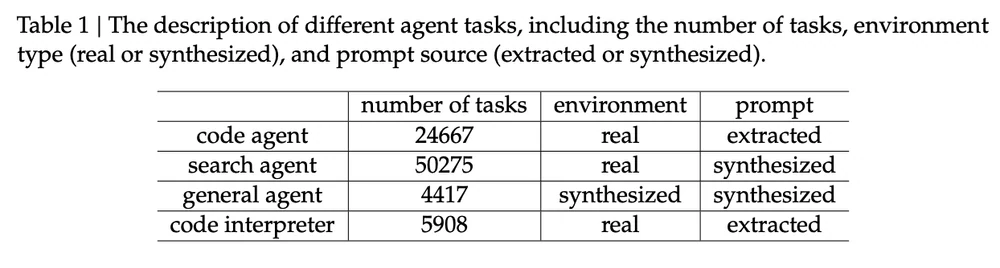
مهام الوكلاء لتدريب DeepSeek-V3.2. مصدر الصورة
معايير الأداء
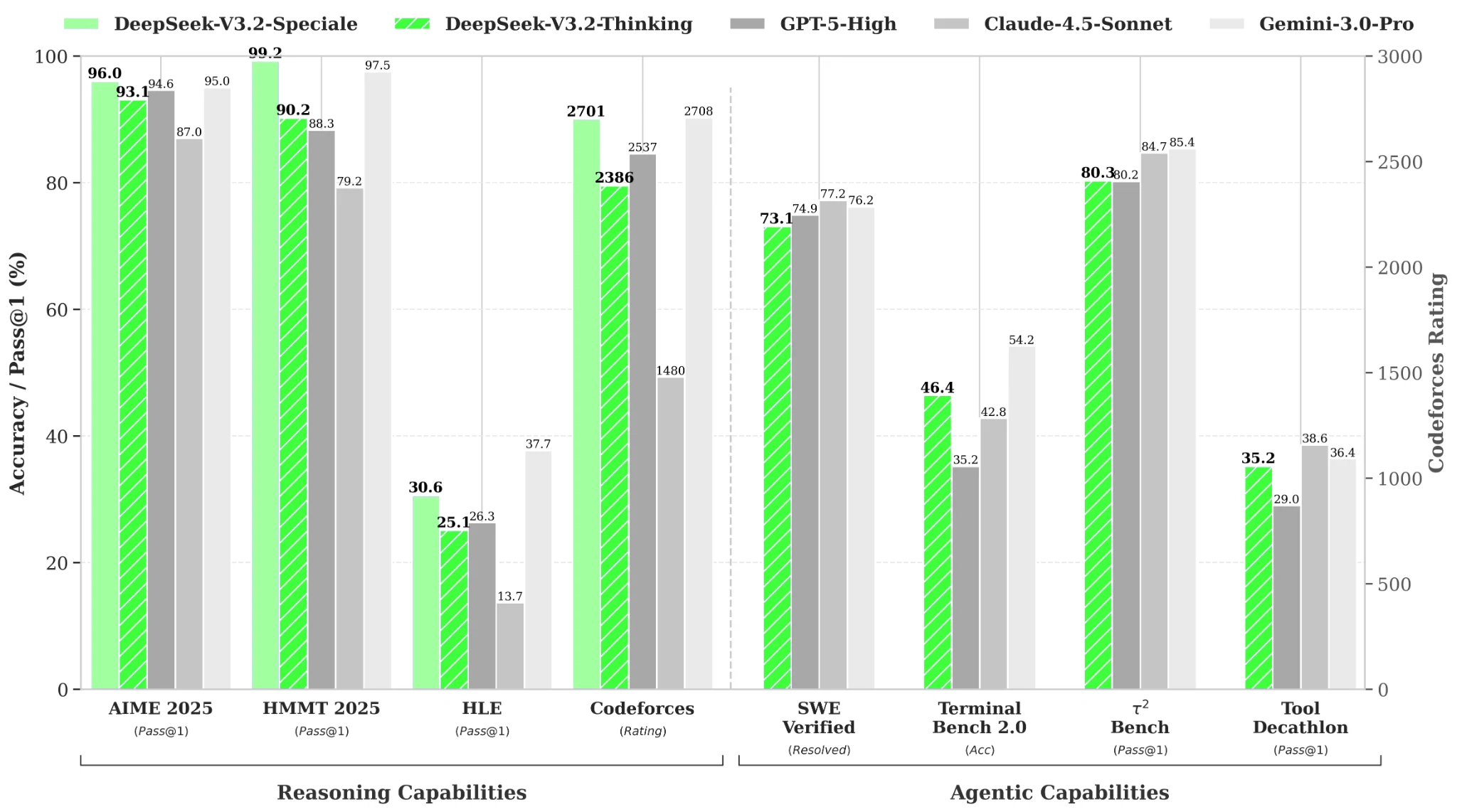
من Hugging Face
الموازنة بين الكفاءة والأداء
توفر DSA تخفيضًا بنسبة 20-50% في رموز سلسلة التفكير مع الحفاظ على درجات المعايير. وكلاء البرمجة الذين يعالجون 50 طلب سحب يوميًا يوفرون 180 دولارًا شهريًا في تكاليف الرموز مقارنة بـ V3.1، دون أي تدهور في الأداء.
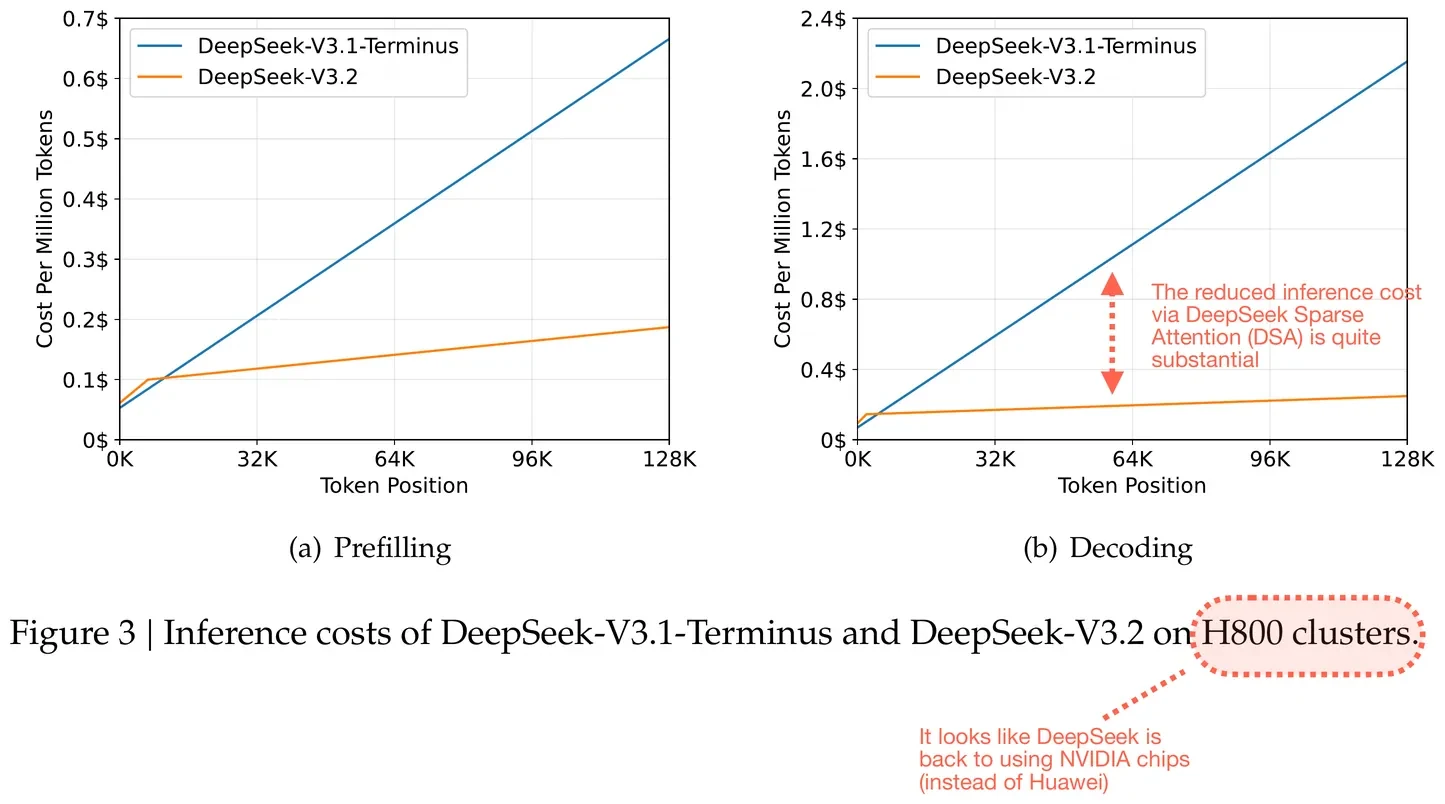
توفير تكاليف الاستدلال بفضل آلية الانتباه المتناثر لـ DeepSeek (DSA). شكل مشروح من تقرير DeepSeek V3.2
لماذا تختار DeepSeek V3.2 على Novita AI؟
توفر Novita AI نشرًا إنتاجيًا عالي الأداء وموفرًا للتكاليف لـ DeepSeek V3.2، بأسعار تنافسية. يقدم DeepSeek V3.2 على Novita AI أداء استدلال حاصل على ميدالية ذهبية في مسابقات IMO/IOI للمطورين بسعر 0.269 دولار/0.40 دولار لكل مليون رمز إدخال/إخراج.
بالنسبة لـ DeepSeek V3.2، يتم احتساب تكلفة قراءة الذاكرة المؤقتة (Cache Read) بمعدل 0.1345 دولار لكل مليون رمز على Novita AI.
قراءة الذاكرة المؤقتة (Cache Read) تشير إلى تكلفة قراءة الرموز التي تم تخزينها مسبقًا في ذاكرة التخزين المؤقت للمطالبات. عندما يتم إعادة استخدام نفس محتوى المطالبة عبر الطلبات، يسترد النموذج هذه الرموز مباشرة من الذاكرة المؤقتة بدلاً من معالجتها مرة أخرى من الصفر. هذا يقلل من كل من زمن الاستجابة وتكاليف الاستدلال.
6 أسباب لاختيار Novita AI
1. متوافق مع OpenAI و Anthropic: بديل جاهز للاستخدام يتطلب فقط تغيير عنوان URL الأساسي. تعمل أكواد SDK الحالية لـ OpenAI فورًا — دون إعادة كتابة أو منحنى تعلم.
2. توسيع تلقائي بدون خوادم: تعامل مع الارتفاعات المفاجئة في حركة المرور من 10 إلى 10,000 طلب في الدقيقة دون الحاجة إلى توفير موارد. ادفع فقط مقابل الرموز المستخدمة — دون تكاليف لبطاقات الرسوميات (GPU) الخاملة.
3. موثوقية على مستوى المؤسسات: بنية تحتية متوافقة مع معيار SOC 2 مع تكرار متعدد المناطق. اتفاقية مستوى خدمة (SLA) بوقت تشغيل 99.5% لأحمال العمل الإنتاجية.
4. نظام بيئي لأكثر من 200 نموذج: الوصول إلى نماذج GLM-5 و Qwen3-Coder-Next و MiniMax M2.5 ونماذج أخرى متقدمة عبر API موحد — اختبر البدائل دون الحاجة إلى تغييرات في البنية التحتية.
5. فواتير شفافة: تسعير لكل رمز دون رسوم خفية. لوحة تحكم في الوقت الفعلي تعرض التكاليف الدقيقة لكل طلب — قم بالميزانية بثقة.

كيفية الوصول إلى DeepSeek V3.2 على Novita AI
ثلاث طرق للنشر، من بداية سريعة في دقيقتين إلى خطوط أنابيب إنتاجية:
الطريقة 1: بداية سريعة عبر API (دقيقتان)
الأفضل لـ: الاختبار، النماذج الأولية، التطبيقات الحالية القائمة على OpenAI
خطوات الإعداد:
- سجل في novita.ai (الطبقة المجانية تتضمن رصيدًا مجانيًا)
- انتقل إلى لوحة التحكم → مفاتيح API → قم بتوليد مفتاح جديد
- قم بتحديث الكود الخاصك باستخدام نقطة نهاية Novita:
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="deepseek/deepseek-v3.2",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].message.content)
الطريقة 2: التكامل مع Hugging Face (5 دقائق)
الأفضل لـ: خطوط أنابيب التعلم الآلي (ML)، سير عمل Transformers الأصلي
from huggingface_hub import InferenceClient
client = InferenceClient(
provider="novita",
api_key="sk_...YxTc",
)
completion = client.chat.completions.create(
model="deepseek-ai/DeepSeek-V3.2",
messages=[
{
"role": "user",
"content": "What is the capital of France?"
}
],
)
print(completion.choices[0].message)
الطريقة 3: النشر الإنتاجي (خيار الاستضافة الذاتية)
الأفضل لـ: أحمال عمل عالية الحجم، متطلبات سيادة البيانات
في ظل النشر القياسي بدقة كاملة (FP16/BF16)، يفرض الاستدلال باستخدام DeepSeek-V3.2 متطلبات عالية جدًا للأجهزة، حيث يتجاوز إجمالي ذاكرة GPU المطلوبة لأوزان النموذج والتنفيذ في وقت التشغيل حوالي 1.3 تيرابايت. في سيناريوهات BF16/FP16، تتضمن التكوينات الشائعة 16 بطاقة رسوميات من فئة H100 بسعة 80 جيجابايت لكل منها، ليصل إجمالي سعة ذاكرة GPU إلى ما يقرب من 1.3 تيرابايت.
| مستوى التكميم | البصمة الذاكرية التقريبية |
|---|---|
| FP16 / BF16 | 1.3 تيرابايت إجمالي |
| 8-bit | 780 جيجابايت إجمالي |
| 4-bit | 380 جيجابايت إجمالي |
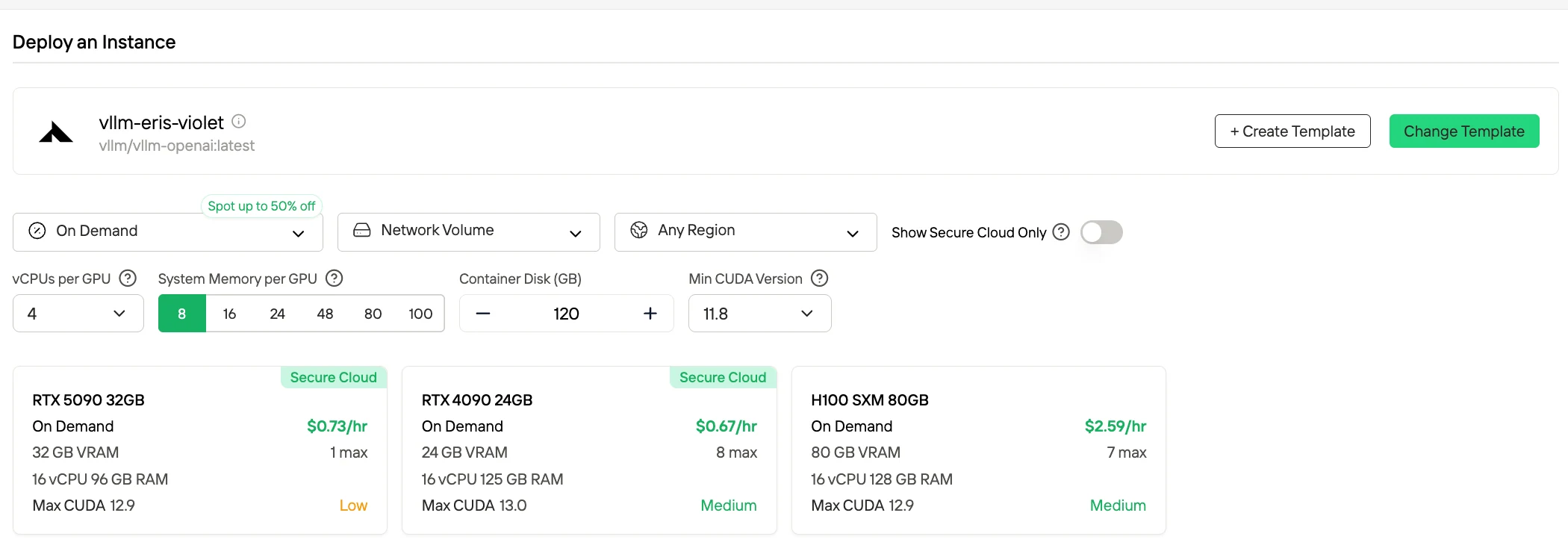
تقدم Novita AI أيضًا وضع Spot، وهو نظام تأجير GPU مُحسّن للتكاليف يستخدم سعة GPU الخاملة أو غير المستخدمة للمنصة. على عكس الحالات عند الطلب التي تحجز أجهزة مخصصة للاستخدام المستقر والمستمر، فإن حالات Spot قابلة للانقطاع — قد يتم إيقاف أو إنهاء مهمتك إذا استعاد النظام GPU. وبما أن وضع Spot يعيد تخصيص موارد GPU التي كانت ستظل خاملة، فهو عادة ما يكون أرخص بنسبة 40-60% من أسعار الطلب عند الحاجة.
حالات الاستخدام الواقعية واستراتيجيات صياغة المطالبات
يتفوق DeepSeek V3.2 في السيناريوهات التي تتطلب استدلالًا متعدد الخطوات، وتكاملًا مع الأدوات، وفهمًا للسياقات الطويلة.
حالة الاستخدام 1: البرمجة بالوكلاء
يتفوق DeepSeek V3.2 في مساعدات البرمجة بالذكاء الاصطناعي مثل OpenCode أو Cursor، حيث يولد طلبات السحب عبر استدعاء الأدوات المدمج. قم بتكوينه عبر API متوافق مع OpenAI (مثل Novita.ai)، مع توفير مطالبات نظام للبرمجة الخبيرة وأدوات لقراءة/كتابة الملفات وتشغيل الاختبارات. يؤدي طلب المستخدم لإعادة هيكلة المصادقة من الجلسات إلى JWT إلى استدلال خطوة بخطوة، مما ينتج تغييرات دقيقة في الكود باستخدام درجة حرارة منخفضة (0.2) لضمان الدقة.
قم بتوصيل Novita AI بسهولة بالمنصات الشريكة مثل Claude Code، Trae، Continue، Codex، OpenCode، AnythingLLM، LangChain، Dify، Langflow و OpenClaw باستخدام تكاملات API وأدلة إعداد خطوة بخطوة.
حالة الاستخدام 2: توليد البراهين الرياضية
للبراهين الرياضية مثل إثبات أن جذر 2 عدد غير نسبي، استخدم مطالبة منظمة توجه إلى التفكير خطوة بخطوة: حدد استراتيجية البرهان (مثل البرهان بالتناقض)، اعرض الخطوات الوسيطة، وتحقق من الاستنتاجات. استدع النموذج بدرجة حرارة 0.1 لاستدلال حتمي وقيمة max_tokens عالية (4096) للسماح بشرحات مفصلة، مستفيدًا من التعزيز المتقدم لـ V3.2 لأداء رياضي على مستوى أولمبياد الرياضيات الدولي (IMO).
حالة الاستخدام 3: تحليل المستندات ذات السياق الطويل
يتعامل سياق V3.2 البالغ 163 ألف رمز مع عقود قانونية تبلغ حوالي 120 صفحة (حوالي 150 ألف رمز). قم بتحميل نص المستند بالكامل، ثم اطبع مطالبة لتحليل بنود محددة مثل مخاطر المسؤولية. استخدم درجة حرارة معتدلة (0.3) و max_tokens (8192) لإنتاج شامل، مع وضع التعليمات الرئيسية في البداية والنهاية لتحسين الانتباه المتناثر لاستخراج دقيق للسياق الطويل.
DeepSeek V3.2 مقابل البدائل على Novita
متى تختار V3.2 بدلاً من النماذج الأخرى في كتالوج Novita:
| المقارنة | اختر DeepSeek V3.2 عندما… | اختر بديلاً عندما… |
|---|---|---|
| مقارنة بـ GLM-5 | أحمال العمل ذات الميزانية المحدودة التي تتطلب استدلالًا على نطاق واسع. | أنت تعطي الأولوية للاستقرار في الحقائق ومعدلات هلوسة أقل على حساب أداء الاستدلال الخام. |
| مقارنة بـ Qwen3-Coder-Next | سير عمل الوكلاء التي تجمع بين الرياضيات والبرمجة واستخدام الأدوات. | أنت تحتاج فقط لمهام برمجة نقية بسعر أقل. |
| مقارنة بـ Kimi K2.5 | إنتاج عالي الحجم أو أحمال عمل دفاعية حيث تكون تكاليف الإخراج مهمة. | أنت تحتاج إلى دعم على مستوى المؤسسات أو تكاملات النظام البيئي. |
يقدم DeepSeek V3.2 على Novita AI أداء استدلال متقدم بسعر 0.269 دولار/0.40 دولار لكل مليون رمز مع كفاءة DSA الثورية للمهام ذات السياق الطويل. للمطورين الذين يبنون أنظمة برمجة بالوكلاء، أو حلول مسائل رياضية، أو خطوط أنابيب تحليل مستندات، يتيح API المتوافق مع OpenAI من Novita نشرًا في دقيقتين مع زمن استجابة رائد في المجال.
الخلاصة
يجمع DeepSeek V3.2 على Novita AI بين بنية MoE ذات 685 مليار معامل وآلية الانتباه المتناثر لـ DeepSeek لتقديم أداء استدلال متقدم بتكلفة تنافسية. سواء كنت تحتاج إلى تكامل API في دقيقتين، أو خط أنابيب Hugging Face، أو مجموعة GPU متعددة للاستضافة الذاتية، توفر Novita مسارًا مرنًا للإنتاج.
النقطة الرئيسية: للمطورين الذين يبنون أنظمة برمجة بالوكلاء، أو حلول مسائل رياضية، أو خطوط أنابيب مستندات ذات سياق طويل، يعد DeepSeek V3.2 عبر API المتوافق مع OpenAI من Novita AI خيارًا عمليًا وموفرًا للتكاليف. جرب DeepSeek V3.2 على Novita AI وابدأ البناء في دقائق.
الأسئلة الشائعة
ما هو الفرق بين DeepSeek V3.2 و V3.2-Exp؟
كان V3.2-Exp هو النموذج التجريبي السابق الذي قدم آلية DSA. أما V3.2 القياسي فهو النموذج الإنتاجي مع توازن بين الاستدلال واستخدام الأدوات. أما V3.2-Speciale فهو نوع بحثي فقط عالي الحساب بدون استدعاء أدوات.
كيف يمكنني التبديل من OpenAI إلى DeepSeek V3.2 على Novita؟
قم بتغيير سطرين: قم بتحديث base_url="https://api.novita.ai/openai" و model="deepseek/deepseek-v3.2". يعمل كود SDK الحالي لـ OpenAI دون أي تعديلات، واحصل على مفتاح API الخاص بك!
ما هي أفضل إعدادات درجة الحرارة لـ DeepSeek V3.2؟
استخدم 0.1-0.3 لمهام الرياضيات/البرمجة/الاستدلال حيث تكون الدقة مهمة. استخدم 0.5-0.7 للكتابة الإبداعية أو العصف الذهني. درجات الحرارة المنخفضة تستفيد من نقاط القوة في الاستدلال الحتمي لـ V3.2.
Novita AI هي منصة سحابية للذكاء الاصطناعي والوكلاء تساعد المطورين والشركات الناشئة على بناء ونشر وتوسيع نطاق النماذج والتطبيقات القائمة على الوكلاء بأداء عالي وموثوقية وكفاءة في التكاليف.
قراءات موصى بها
GLM-5 في OpenCode: بديل مفتوح المصدر لـ Claude Code
متطلبات VRAM لـ ERNIE-4.5-VL-A3B: تشغيل النماذج متعددة الوسائط بتكلفة أقل



