

Novita AI 上の DeepSeek V3.2 は、入力/出力トークン 100 万あたり $0.269/$0.40 で、IMO/IOI 金メダル級の推論性能を開発者に提供します。 685B パラメータの Mixture-of-Experts アーキテクチャと革新的な DeepSeek Sparse Attention (DSA) を基盤としており、長いコンテキストのタスクにおける計算の複雑さを軽減しながら、推論ベンチマークでトップクラスの結果を達成します。
数学ソルバー、コーディングエージェント、複雑な推論ワークフローを構築する開発者にとって、Novita AI のサーバーレスインフラストラクチャは、OpenAI 互換および Anthropic 互換のエンドポイントにより、最速クラスのレイテンシを実現します。ベース URL を変更するだけで、2 分で実行を開始できます。
DeepSeek V3.2 とは?
DeepSeek V3.2 は、685.4B パラメータの Mixture-of-Experts 推論モデルで、トークンあたり 37B のアクティブパラメータを持ち、効率的な長いコンテキスト処理と優れたエージェント性能を実現するように設計されています。V3.1-Terminus のアップグレードとしてリリースされ、3 つの革新的な機能を導入しています。
技術アーキテクチャ
| 仕様 | 値 |
|---|---|
| 総パラメータ数 | 685B |
| アクティブパラメータ数 | トークンあたり 37B |
| MoE 構成 | 256 ルーティングエキスパート、8 アクティブ |
| コンテキストウィンドウ | 163,840 トークン |
| アテンション機構 | DSA + MLA ハイブリッド |
| 精度 | BF16; F8_E4M3; F32 |
中核となる革新
1. DeepSeek Sparse Attention (DSA): 軽量インデクサーとトークンセレクターを使用してコンテキストを選択的に刈り込む、きめ細かいスパース機構。従来のアテンションがすべてのトークンを処理するのに対し、DSA は性能を維持しながら計算の複雑さを軽減します。特に 128K+ トークンのコンテキストで重要です。
2. スケーラブルな強化学習: 強力なポストトレーニング性能を可能にする高度なポストトレーニングプロトコル。高計算バリアント (Speciale) はトップクラスの推論性能を達成します。
3. エージェントタスク合成パイプライン: ツール使用シナリオに推論を大規模に体系的に統合し、コーディングエージェントやマルチステップワークフローに対して優れたコンプライアンスと汎化を提供します。
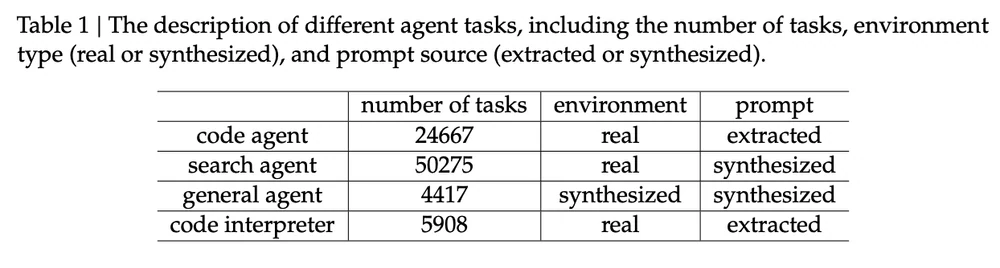
DeepSeek-V3.2 のトレーニング用エージェントタスク。画像出典
性能ベンチマーク
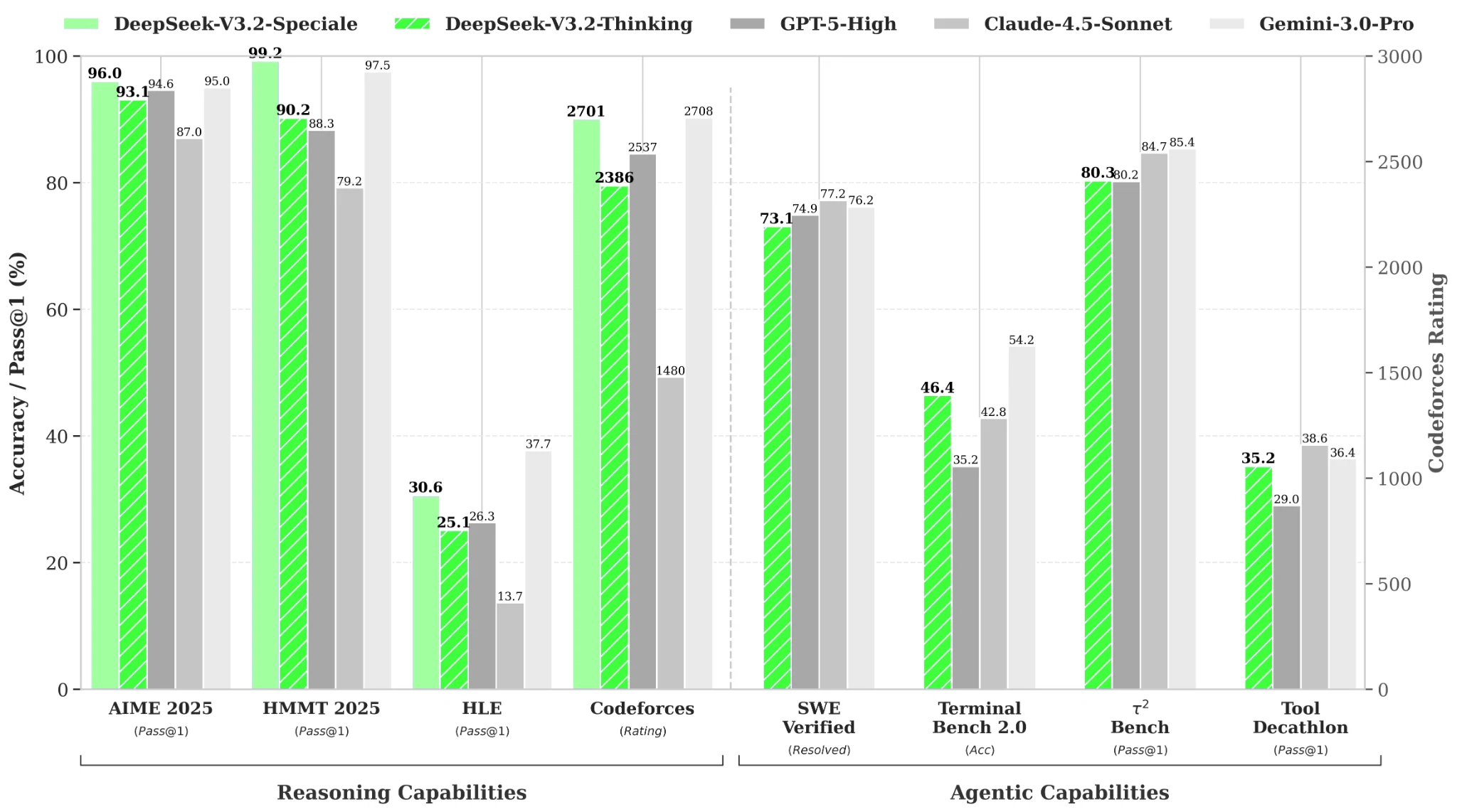
Hugging Face より
効率性と性能のトレードオフ
DSA は、ベンチマークスコアを維持しながら、Chain-of-Thought トークンを 20~50% 削減します。毎日 50 件のプルリクエストを処理するコーディングエージェントは、V3.1 と比較してトークンコストを月額 $180 節約でき、性能低下はありません。
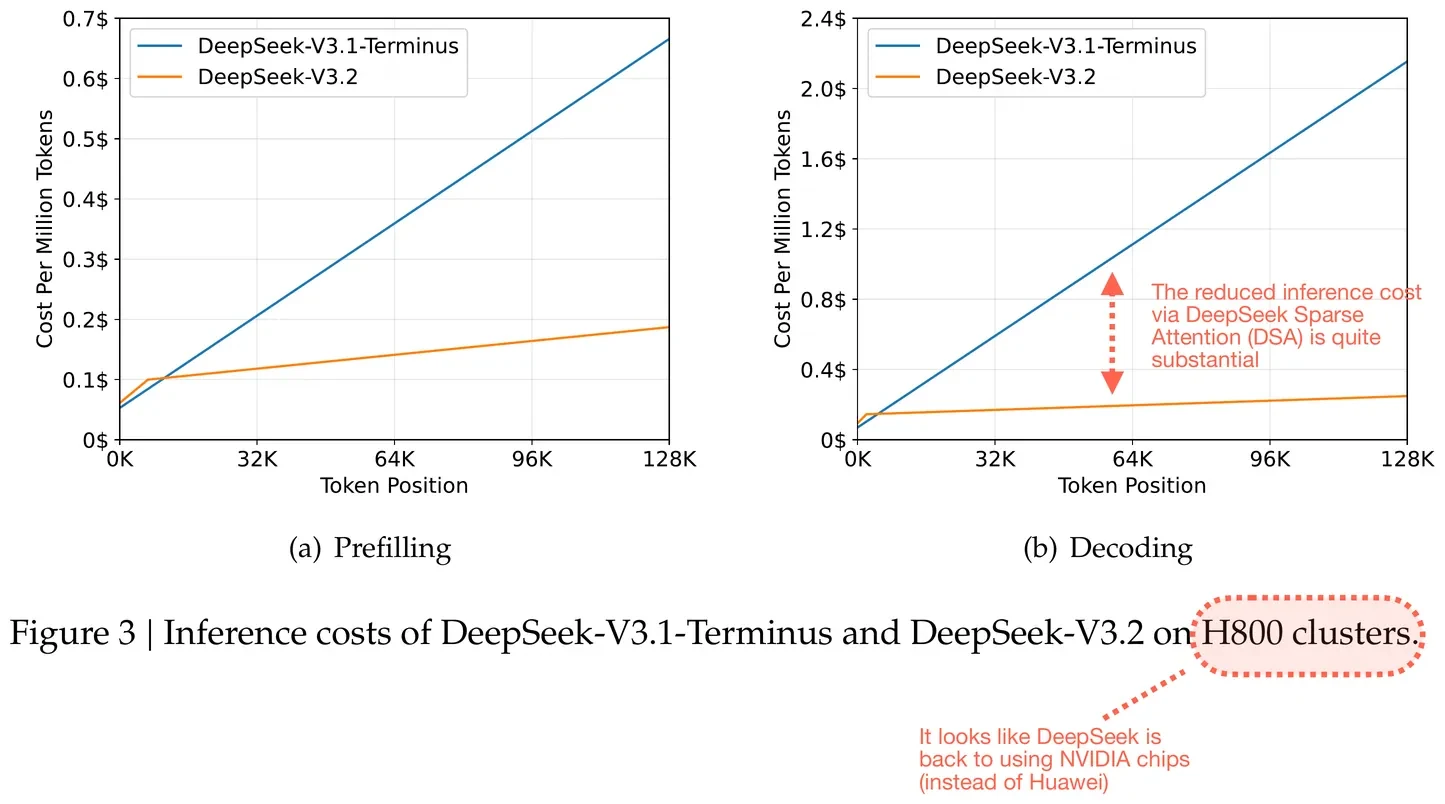
DeepSeek Sparse Attention (DSA) による推論コスト削減。DeepSeek V3.2 レポート からの注釈付き図
Novita AI で DeepSeek V3.2 を選ぶ理由
Novita AI は、DeepSeek V3.2 の高性能でコスト効率の高い本番環境デプロイを、競争力のある価格で提供します。 Novita AI 上の DeepSeek V3.2 は、入力/出力トークン 100 万あたり $0.269/$0.40 で、IMO/IOI 金メダル級の推論性能を開発者に提供します。
Novita AI では、DeepSeek V3.2 のキャッシュ読み取りは、トークン 100 万あたり $0.1345 で課金されます。
キャッシュ読み取りとは、以前にプロンプトキャッシュに保存されたトークンを読み取るコストを指します。同じプロンプトコンテンツがリクエスト間で再利用される場合、モデルはこれらのトークンを最初から再処理する代わりに、キャッシュから直接取得します。これにより、推論レイテンシとコストの両方が削減されます。
Novita AI を選ぶ 6 つの理由
1. OpenAI 互換および Anthropic 互換: ベース URL の変更のみでドロップイン置換可能。既存の OpenAI SDK コードはそのまま動作します。書き換えも学習曲線も不要です。
2. サーバーレス自動スケーリング: プロビジョニングなしで、毎分 10 から 10,000 リクエストまでのトラフィックスパイクを処理。使用したトークンに対してのみ支払います。アイドル状態の GPU コストは発生しません。
3. エンタープライズグレードの信頼性: SOC 2 準拠のインフラストラクチャとマルチリージョン冗長性。本番環境ワークロード向けの 99.5% アップタイム SLA。
4. 200 以上のモデルエコシステム: 統一 API を介して GLM-5、Qwen3-Coder-Next、MiniMax M2.5 などのフロンティアモデルにアクセス。インフラストラクチャを変更せずに代替モデルをテスト可能。
5. 透明な課金: 隠れた料金のないトークン単位の価格設定。リアルタイムダッシュボードでリクエストごとの正確なコストを表示。自信を持って予算を計画できます。

Novita AI で DeepSeek V3.2 にアクセスする方法
3 つのデプロイ方法。2 分のクイックスタートから本番環境パイプラインまで。
方法 1: API クイックスタート (2 分)
最適な用途: テスト、プロトタイプ、既存の OpenAI ベースのアプリ
セットアップ手順:
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="deepseek/deepseek-v3.2",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].message.content)
方法 2: Hugging Face 統合 (5 分)
最適な用途: ML パイプライン、Transformers ネイティブワークフロー
from huggingface_hub import InferenceClient
client = InferenceClient(
provider="novita",
api_key="sk_...YxTc",
)
completion = client.chat.completions.create(
model="deepseek-ai/DeepSeek-V3.2",
messages=[
{
"role": "user",
"content": "What is the capital of France?"
}
],
)
print(completion.choices[0].message)
方法 3: 本番環境デプロイ (セルフホストオプション)
最適な用途: 高負荷ワークロード、データ主権要件
標準の完全精度 (FP16/BF16) デプロイでは、DeepSeek-V3.2 の推論には非常に高いハードウェア要件が課されます。モデルウェイトとランタイム実行に必要な合計 GPU メモリは約 1.3TB を超えるためです。BF16/FP16 シナリオでは、一般的に各 80 GB VRAM の H100 クラス GPU 16 台で構成され、合計 GPU メモリ容量は約 1.3 TB になります。
| 量子化レベル | おおよそのメモリフットプリント |
|---|---|
| FP16 / BF16 | 合計 1.3 TB |
| 8 ビット | 合計 780 GB |
| 4 ビット | 合計 380 GB |
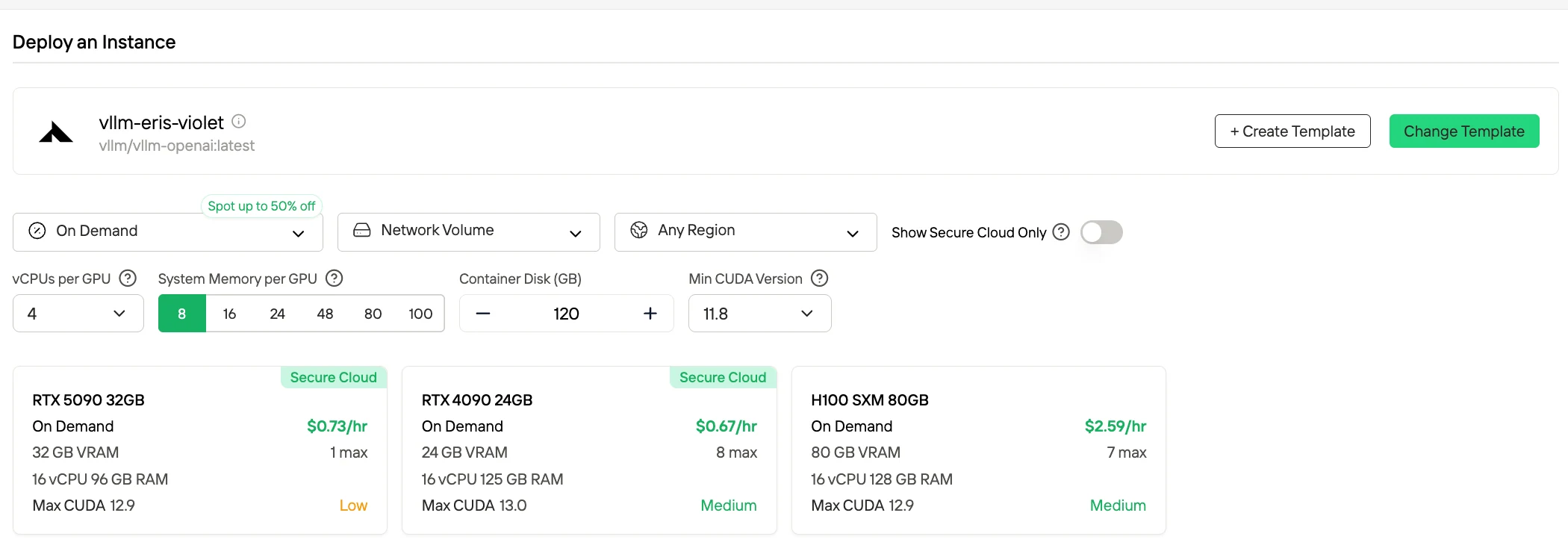
Novita AI は、プラットフォームのアイドル状態または未使用の GPU 容量を活用する、コスト最適化された GPU レンタルシステムである Spot モードも提供しています。安定した継続的な使用のために専用ハードウェアを予約するオンデマンドインスタンスとは異なり、Spot インスタンスは中断可能です。GPU がシステムによって再利用されると、ジョブが一時停止または終了される可能性があります。Spot モードはアイドル状態の GPU リソースを再割り当てするため、通常はオンデマンド価格よりも 40~60% 安価です。
実際のユースケースとプロンプト戦略
DeepSeek V3.2 は、マルチステップ推論、ツール統合、長いコンテキストの理解を必要とするシナリオで優れています。
ユースケース 1: エージェントコーディング
DeepSeek V3.2 は、OpenCode や Cursor などの AI コーディングアシスタントで優れており、統合されたツール呼び出しを通じてプルリクエストを生成します。Novita.ai などの OpenAI 互換 API を介して構成し、エキスパートコーディング用のシステムプロンプトと、ファイルの読み取り/書き込みやテスト実行用のツールを提供します。認証をセッションから JWT にリファクタリングするというユーザーリクエストは、ステップバイステップの推論をトリガーし、精度のために低い温度 (0.2) で正確なコード変更を生成します。
API 統合とステップバイステップのセットアップガイドを使用して、Claude Code、Trae、Continue、Codex、OpenCode、AnythingLLM、LangChain、Dify、Langflow、OpenClaw などのパートナープラットフォームと Novita AI を簡単に接続できます。
ユースケース 2: 数学的証明の生成
√2 が無理数であることを示すなどの数学的証明には、ステップバイステップの思考を指示する構造化プロンプトを使用します。証明戦略 (例: 背理法) を述べ、中間結果を示し、結論を検証します。決定論的な推論のために温度 0.1、詳細な説明を可能にするために高い max_tokens (4096) でモデルを呼び出し、V3.2 の高度な強化学習を活用して IMO レベルの数学性能を実現します。
ユースケース 3: 長いコンテキストのドキュメント分析
V3.2 の 163K トークンコンテキストは、約 120 ページの法的契約書 (約 150K トークン) を処理できます。完全なドキュメントテキストを読み込み、特定の条項 (責任リスクなど) の分析をプロンプトします。包括的な出力には中程度の温度 (0.3) と max_tokens (8192) を使用し、主要な指示を開始と終了の両方に配置して、スパースアテンションを最適化し、長いコンテキストからの正確な抽出を実現します。
Novita 上の DeepSeek V3.2 と代替モデルの比較
Novita のカタログで、V3.2 を他のモデルよりも選ぶべきタイミング:
| 比較 | DeepSeek V3.2 を選ぶべき場合… | 代替モデルを選ぶべき場合… |
|---|---|---|
| vs. GLM-5 | 大規模な推論を必要とする予算制約のあるワークロード。 | 生の推論性能よりも、事実の安定性と低い幻覚率を優先する場合。 |
| vs. Qwen3-Coder-Next | 数学、コーディング、ツール使用を組み合わせたエージェントワークフロー。 | より低い価格帯で純粋なコーディングタスクのみが必要な場合。 |
| vs. Kimi K2.5 | 出力コストが重要な大量出力またはバッチワークロード。 | エンタープライズグレードのサポートまたはエコシステム統合が必要な場合。 |
Novita AI 上の DeepSeek V3.2 は、革新的な DSA 効率により、長いコンテキストタスクにおいて、トークン 100 万あたり $0.269/$0.40 で高度な推論性能を提供します。エージェントコーディングシステム、数学ソルバー、ドキュメント分析パイプラインを構築する開発者にとって、Novita の OpenAI 互換 API は、業界をリードするレイテンシで 2 分のデプロイを可能にします。
結論
Novita AI 上の DeepSeek V3.2 は、685B パラメータの MoE アーキテクチャと DeepSeek Sparse Attention を組み合わせ、競争力のあるコストで高度な推論性能を提供します。2 分の API 統合、Hugging Face パイプライン、セルフホストのマルチ GPU クラスターのいずれが必要でも、Novita は本番環境への柔軟なパスを提供します。
重要なポイント: エージェントコーディングシステム、数学ソルバー、長いコンテキストのドキュメントパイプラインを構築する開発者にとって、Novita AI の OpenAI 互換 API を介した DeepSeek V3.2 は、実用的でコスト効率の高い選択肢です。Novita AI で DeepSeek V3.2 を試す 今すぐ、数分で構築を始めましょう。
よくある質問
DeepSeek V3.2 と V3.2-Exp の違いは何ですか?
V3.2-Exp は DSA を導入した実験的な前身でした。標準の V3.2 は、推論とツール使用のバランスが取れた本番モデルです。V3.2-Speciale は研究専用の高計算バリアントで、ツール呼び出しはありません。
OpenAI から Novita 上の DeepSeek V3.2 に切り替えるにはどうすればよいですか?
2 行を変更します: base_url="https://api.novita.ai/openai" と model="deepseek/deepseek-v3.2" を更新します。既存の OpenAI SDK コードは変更なしで動作し、API キーを取得 してください!
DeepSeek V3.2 に最適な温度設定は何ですか?
精度が重要な数学/コーディング/推論タスクには 0.1~0.3 を使用します。クリエイティブライティングやブレインストーミングには 0.5~0.7 を使用します。低い温度は V3.2 の決定論的な推論の強みを活用します。
Novita AI は、開発者やスタートアップが高性能、信頼性、コスト効率に優れたモデルとエージェントアプリケーションを構築、デプロイ、スケーリングできるようにする AI & エージェントクラウドプラットフォームです。
おすすめの記事
OpenCode の GLM-5: Claude Code のオープンソース代替



