

DeepSeek V3.2 на Novita AI обеспечивает производительность рассуждений уровня золотой медали IMO/IOI для разработчиков по цене $0,269/$0,40 за 1M входных/выходных токенов. Построенная на архитектуре Mixture-of-Experts с 685B параметров с революционным разреженным вниманием DeepSeek (DSA), эта модель снижает вычислительную сложность для задач с длинным контекстом, достигая при этом результатов верхнего уровня в бенчмарках рассуждений.
Для разработчиков, создающих математические решатели, кодирующие агенты или сложные рабочие процессы рассуждений, бессерверная инфраструктура Novita AI обеспечивает самую низкую в классе задержку с OpenAI-совместимыми и Anthropic-совместимыми эндпоинтами — измените базовый URL и запустите работу за 2 минуты.
Что такое DeepSeek V3.2?
DeepSeek V3.2 — это модель рассуждений с архитектурой смеси экспертов (Mixture-of-Experts) на 685,4B параметров с 37B активных параметров на токен, разработанная для эффективной обработки длинного контекста и превосходной производительности в агентных задачах. Выпущенная как обновление для V3.1-Terminus, она включает три прорывных инновации:
Техническая архитектура
| Спецификация | Значение |
|---|---|
| Общее количество параметров | 685B |
| Активные параметры | 37B на токен |
| Конфигурация MoE | 256 маршрутизируемых экспертов, 8 активных |
| Окно контекста | 163 840 токенов |
| Механизм внимания | Гибрид DSA + MLA |
| Точность | BF16; F8_E4M3; F32 |
Ключевые инновации
1. DeepSeek Sparse Attention (DSA, разреженное внимание DeepSeek): Тонкоструктурированный разреженный механизм, использующий молниеносный индексатор и селектор токенов для выборочного удаления контекста. В отличие от традиционного внимания, которое обрабатывает все токены, DSA сохраняет производительность, снижая вычислительную сложность — это особенно критично для контекстов длиной 128K+ токенов.
2. Масштабируемое обучение с подкреплением: Продвинутый протокол пост-обучения, обеспечивающий высокую производительность после обучения. Вариант с высокой вычислительной мощностью (Speciale) достигает результатов верхнего уровня в задачах рассуждений.
3. Конвейер синтеза агентных задач: Систематически интегрирует рассуждения в сценарии использования инструментов в масштабах, обеспечивая превосходную соответствие и обобщение для кодирующих агентов и многошаговых рабочих процессов.
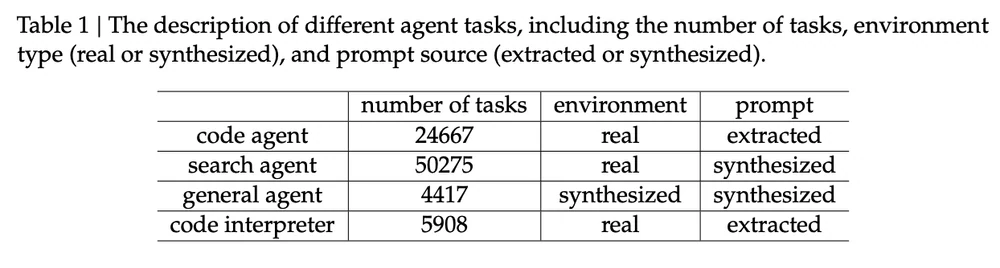
Задачи агентов для обучения DeepSeek-V3.2. Источник изображения
Бенчмарки производительности
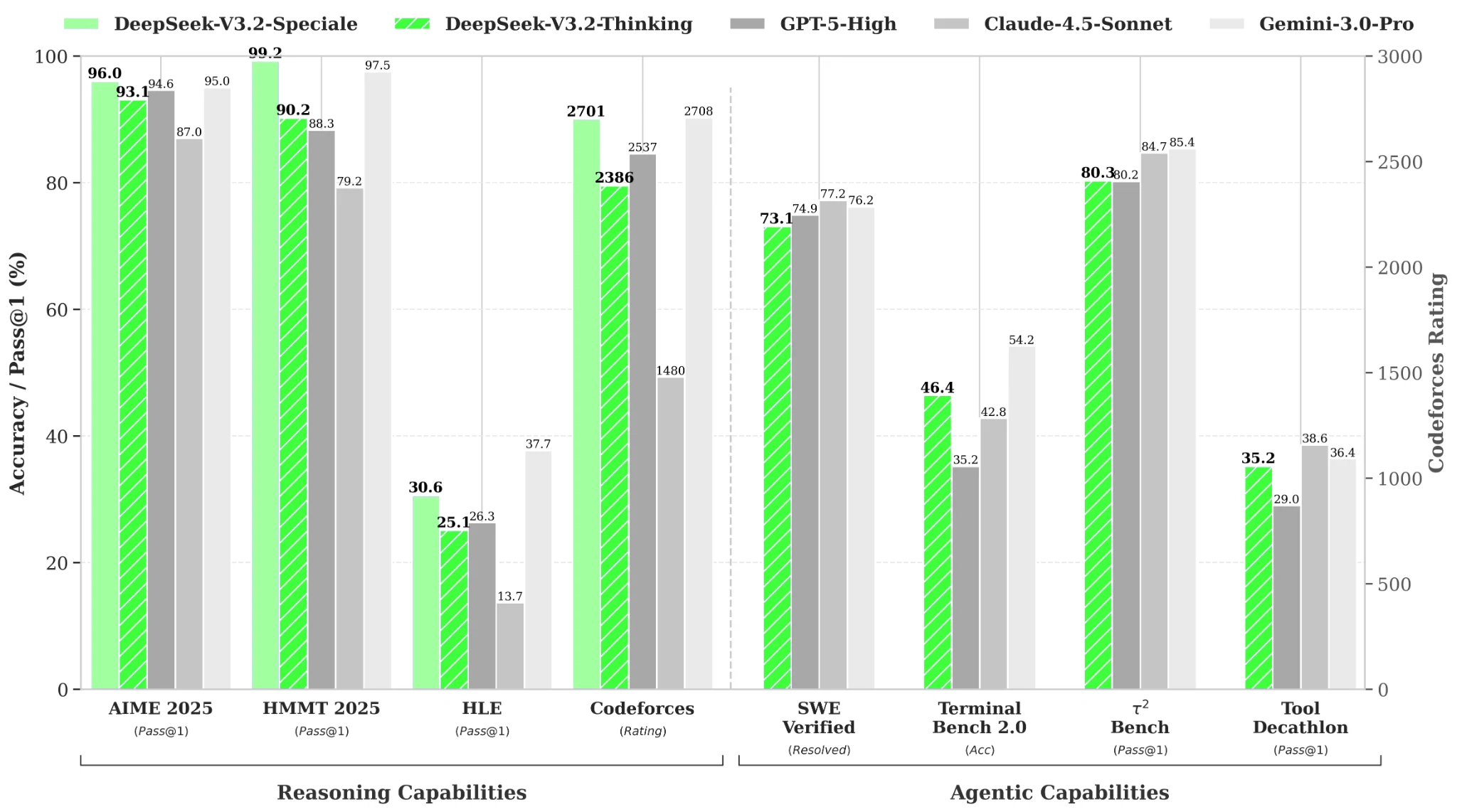
Из Hugging Face
Компромисс между эффективностью и производительностью
DSA обеспечивает сокращение на 20-50% токенов цепочки рассуждений при сохранении показателей бенчмарков. Кодирующий агент, обрабатывающий 50 pull-запросов в день, экономит $180 в месяц на стоимости токенов по сравнению с V3.1, без снижения производительности.
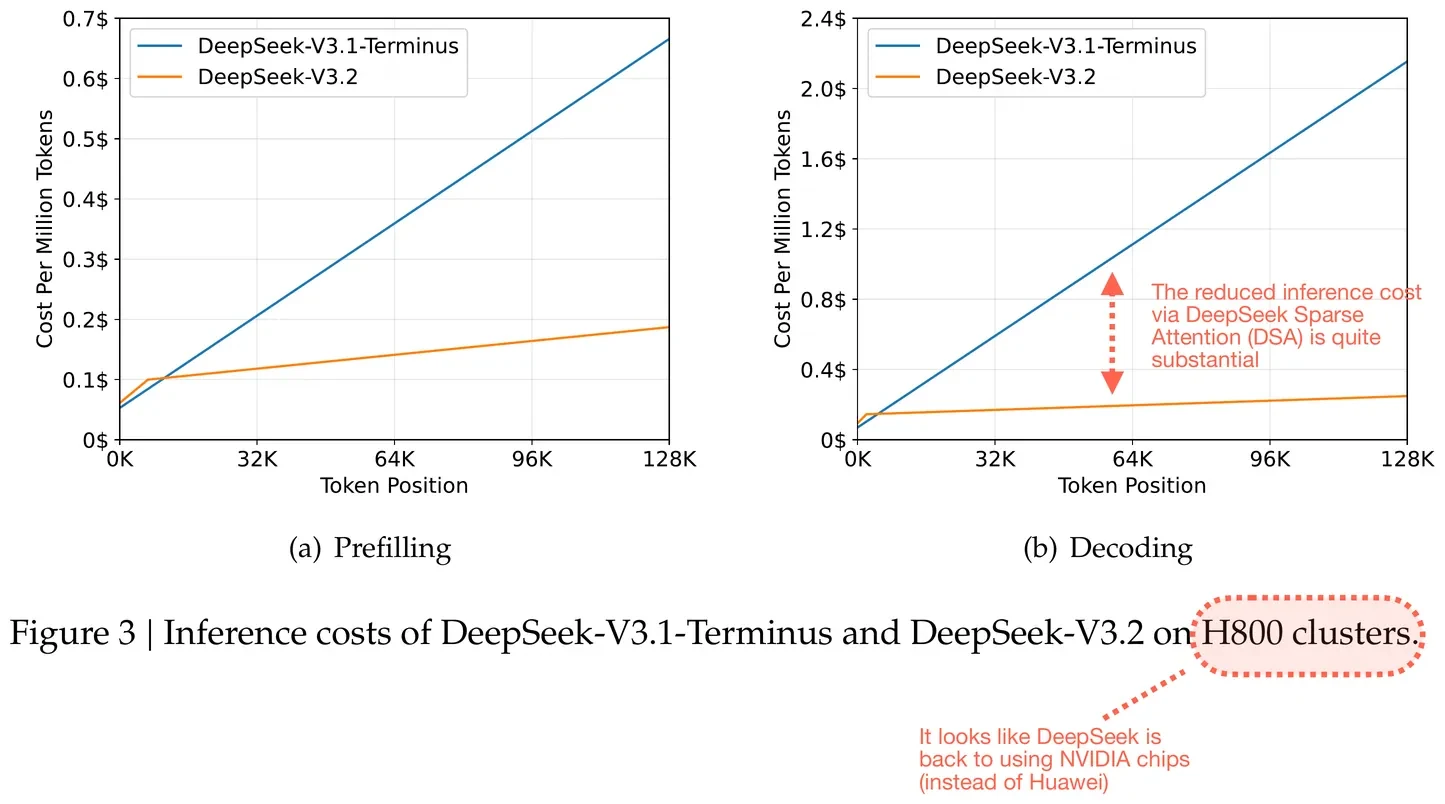
Экономия затрат на вывод благодаря DeepSeek Sparse Attention (DSA). Аннотированный рисунок из отчета DeepSeek V3.2
Попробуйте DeepSeek V3.2 сейчас!
Почему DeepSeek V3.2 на Novita AI?
Novita AI предоставляет высокопроизводительное, экономически эффективное продакшен-развертывание для DeepSeek V3.2, с конкурентоспособным ценообразованием. DeepSeek V3.2 на Novita AI обеспечивает производительность рассуждений уровня золотой медали IMO/IOI для разработчиков по цене $0,269/$0,40 за 1M входных/выходных токенов.
Для DeepSeek V3.2 на Novita AI чтение из кэша тарифицируется по $0,1345 за 1M токенов.
Чтение из кэша относится к стоимости чтения токенов, которые ранее были сохранены в кэше промптов. Когда одно и то же содержимое промпта повторно используется в нескольких запросах, модель получает эти токены напрямую из кэша вместо повторной обработки с нуля. Это снижает как задержку вывода, так и стоимость.
Попробуйте DeepSeek V3.2 сейчас!
6 причин выбрать Novita AI
1. Совместимость с OpenAI и Anthropic: Готовая замена, требующая только изменения базового URL. Существующий код на SDK OpenAI работает мгновенно — без переписывания, без кривой обучения.
2. Бессерверное автоматическое масштабирование: Обрабатывайте всплески трафика от 10 до 10 000 запросов в минуту без выделения ресурсов. Платите только за использованные токены — без затрат на простаивающие GPU.
3. Надежность корпоративного уровня: Инфраструктура, соответствующая стандарту SOC 2, с избыточностью в нескольких регионах. Гарантированное время доступности 99,5% для продакшен-рабочих нагрузок.
4. Экосистема из 200+ моделей: Доступ к GLM-5, Qwen3-Coder-Next, MiniMax M2.5 и другим передовым моделям через единый API — тестируйте альтернативы без изменения инфраструктуры.
5. Прозрачное биллингование: Тарификация за токен без скрытых сборов. Панель управления в реальном времени показывает точную стоимость каждого запроса — планируйте бюджет с уверенностью.

Попробуйте DeepSeek V3.2 сейчас!
Как получить доступ к DeepSeek V3.2 на Novita AI
Три метода развертывания: от 2-минутного быстрого старта до продакшен-конвейеров:
Метод 1: Быстрый старт API (2 минуты)
Подходит для: тестирования, прототипов, существующих приложений на базе OpenAI
Шаги настройки:
- Зарегистрируйтесь на novita.ai (бесплатный тариф включает кредиты)
- Перейдите в Dashboard → Управление API-ключами → Создайте новый ключ
- Обновите ваш код с использованием эндпоинта Novita:
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="deepseek/deepseek-v3.2",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].message.content)
Метод 2: Интеграция с Hugging Face (5 минут)
Подходит для: ML-конвейеров, рабочих процессов на базе Transformers
from huggingface_hub import InferenceClient
client = InferenceClient(
provider="novita",
api_key="sk_...YxTc",
)
completion = client.chat.completions.create(
model="deepseek-ai/DeepSeek-V3.2",
messages=[
{
"role": "user",
"content": "What is the capital of France?"
}
],
)
print(completion.choices[0].message)
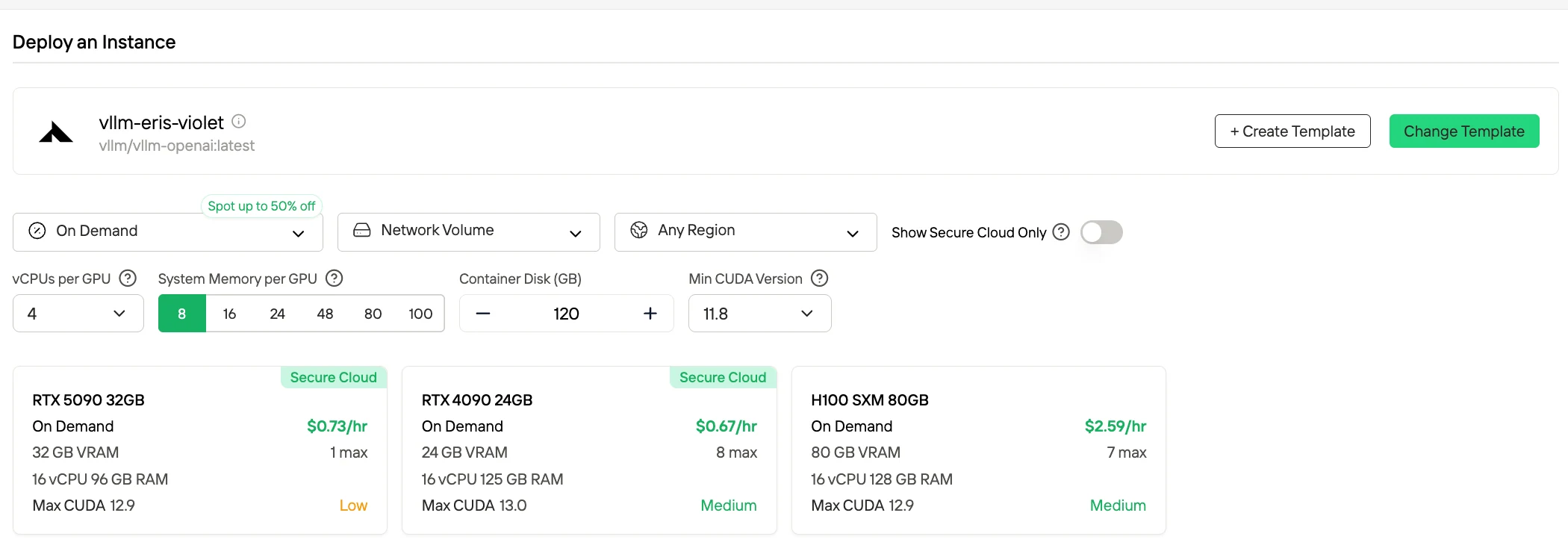
Метод 3: Продакшен-развертывание (Опция самостоятельного хостинга)
Подходит для: нагрузок с высоким объемом запросов, требования к суверенитету данных
При стандартном развертывании в полной точности (FP16/BF16) вывод с DeepSeek-V3.2 требует чрезвычайно высоких требований к оборудованию, так как совокупный объем памяти GPU, необходимый для весов модели и выполнения во время вывода, превышает примерно 1,3 ТБ. Для сценариев BF16/FP16 обычно используются конфигурации из 16 GPU класса H100 с 80 ГБ VRAM каждая, что в сумме дает общую емкость памяти GPU почти 1,3 ТБ.
| Уровень квантования | Примерный объем памяти |
|---|---|
| FP16 / BF16 | 1,3 ТБ всего |
| 8-бит | 780 ГБ всего |
| 4-бит | 380 ГБ всего |
Попробуйте быстрые и дешевые GPU сейчас!
Novita AI также предлагает режим Spot — система аренды GPU с оптимизацией стоимости, которая использует простаивающие или неиспользуемые ресурсы GPU платформы. В отличие от инстансов по запросу, которые резервируют выделенное оборудование для стабильного непрерывного использования, Spot-инстансы являются прерываемыми — ваша задача может быть приостановлена или завершена, если GPU будет возвращен в систему. Поскольку режим Spot перераспределяет в противном случае простаивающие ресурсы GPU, он обычно на 40–60% дешевле тарифов по запросу.
Реальные варианты использования и стратегии промптинга
DeepSeek V3.2 отлично подходит для сценариев, требующих многошагового рассуждения, интеграции с инструментами и понимания длинного контекста.
Вариант использования 1: Агентное кодирование
DeepSeek V3.2 отлично подходит для AI-ассистентов по кодированию, таких как OpenCode или Cursor, где он генерирует pull-запросы через интегрированный вызов инструментов. Настройте его через OpenAI-совместимый API (например, Novita.ai), предоставив системные промпты для экспертного кодирования и инструменты для чтения/записи файлов и запуска тестов. Запрос пользователя на рефакторинг аутентификации из сессий в JWT запускает пошаговое рассуждение, генерируя точные изменения кода с низкой температурой (0,2) для обеспечения точности.
Легко подключите Novita AI к партнерским платформам, таким как Claude Code, Trae, Continue, Codex, OpenCode, AnythingLLM, LangChain, Dify, Langflow и OpenClaw с использованием API-интеграций и пошаговых руководств по настройке.
Вариант использования 2: Генерация математических доказательств
Для математических доказательств, таких как доказательство иррациональности √2, используйте структурированный промпт, который инструктирует выполнять пошаговое рассуждение: укажите стратегию доказательства (например, от противного), покажите промежуточные шаги и проверьте выводы. Вызовите модель с температурой 0,1 для детерминированного рассуждения и высоким значением max_tokens (4096), чтобы разрешить подробные объяснения, используя продвинутое обучение с подкреплением V3.2 для достижения производительности на уровне IMO по математике.
Вариант использования 3: Анализ документов с длинным контекстом
Окно контекста V3.2 на 163K токенов обрабатывает ~120-страничные юридические контракты (~150K токенов). Загрузите полный текст документа, затем запросите анализ конкретных пунктов, таких как риски ответственности. Используйте умеренную температуру (0,3) и max_tokens (8192) для всеобъемлющего вывода, размещая ключевые инструкции в начале и в конце, чтобы оптимизировать разреженное внимание для точного извлечения информации из длинного контекста.
DeepSeek V3.2 против альтернатив на Novita
Когда выбирать V3.2 вместо других моделей в каталоге Novita:
| Сравнение | Выбирайте DeepSeek V3.2, когда… | Выбирайте альтернативу, когда… |
|---|---|---|
| vs. GLM-5 | Бюджетные рабочие нагрузки, требующие крупномасштабных рассуждений. | Вы отдаете приоритет стабильности фактов и более низкому уровню галлюцинаций, а не сырой производительности рассуждений. |
| vs. Qwen3-Coder-Next | Агентные рабочие процессы, сочетающие математику, кодирование и использование инструментов. | Вам нужны только задачи чистого кодирования по более низкой цене. |
| vs. Kimi K2.5 | Высоконагруженный вывод или пакетные рабочие нагрузки, где важна стоимость вывода. | Вам требуется поддержка корпоративного уровня или интеграции с экосистемой. |
DeepSeek V3.2 на Novita AI обеспечивает продвинутую производительность рассуждений по цене $0,269/$0,40 за 1M токенов с революционной эффективностью DSA для задач с длинным контекстом. Для разработчиков, создающих агентные системы кодирования, математические решатели или конвейеры анализа документов, OpenAI-совместимый API Novita позволяет развернуть модель за 2 минуты с ведущей в отрасли задержкой.
Заключение
DeepSeek V3.2 на Novita AI сочетает архитектуру MoE на 685B параметров с разреженным вниманием DeepSeek, чтобы обеспечить продвинутую производительность рассуждений по конкурентной цене. Неважно, нужна ли вам 2-минутная API-интеграция, конвейер Hugging Face или самостоятельный многопроцессорный кластер, Novita предоставляет гибкий путь к продакшену.
Ключевой вывод: Для разработчиков, создающих агентные системы кодирования, математические решатели или конвейеры анализа документов с длинным контекстом, DeepSeek V3.2 через OpenAI-совместимый API Novita AI является практическим, экономически эффективным выбором. Попробуйте DeepSeek V3.2 на Novita AI и начните создавать за несколько минут.
Часто задаваемые вопросы
В чем разница между DeepSeek V3.2 и V3.2-Exp?
V3.2-Exp был экспериментальным предшественником, в котором был представлен DSA. Стандартная V3.2 — это продакшен-модель со сбалансированными возможностями рассуждений и использования инструментов. V3.2-Speciale — это исследовательский вариант с высокой вычислительной мощностью, не поддерживающий вызовы инструментов.
Как переключиться с OpenAI на DeepSeek V3.2 на Novita?
Измените две строки: обновите base_url="https://api.novita.ai/openai" и model="deepseek/deepseek-v3.2". Ваш существующий код на SDK OpenAI будет работать без изменений, и получите ваш API-ключ!
Какая оптимальная температура для DeepSeek V3.2?
Используйте 0,1–0,3 для задач по математике, кодированию и рассуждениям, где важна точность. Используйте 0,5–0,7 для креативного письма или мозгового штурма. Более низкие температуры используют сильные стороны детерминированного рассуждения V3.2.
Novita AI — это облачная платформа для ИИ и агентов, которая помогает разработчикам и стартапам создавать, развертывать и масштабировать модели и агентные приложения с высокой производительностью, надежностью и экономической эффективностью.
Рекомендуемые материалы для чтения
GLM-5 в OpenCode: Открытый альтернатива для Claude Code
Требования к VRAM для ERNIE-4.5-VL-A3B: Запускайте мультимодальные модели по более низкой цене
Qwen3 Embedding 8B: Мощный поиск, гибкая кастомизация и многоязычность



