

Entwickler, die leistungsstarke Open-Weight-Sprachmodelle erkunden, stehen vor einer häufigen Frage: Wie nutze ich dieses Modell überhaupt? Qwen3.5-397B-A17B bietet drei unterschiedliche Zugriffspfade: Sofortiger Web-Chat zum Testen, verwaltete APIs für Produktionsanwendungen und selbst gehostete Bereitstellung für volle Kontrolle. Jede Methode eignet sich für unterschiedliche Szenarien – von schnellem Prototyping bis hin zu unternehmensweiter Inferenz.
Dieser Leitfaden behandelt alle Zugriffsmethoden mit Einrichtungsanweisungen, echten Preisdaten und Hardwareanforderungen. Sie erfahren, welcher Pfad zu Ihrem Anwendungsfall passt und wie Sie in wenigen Minuten loslegen können.
Was ist Qwen3.5-397B-A17B?
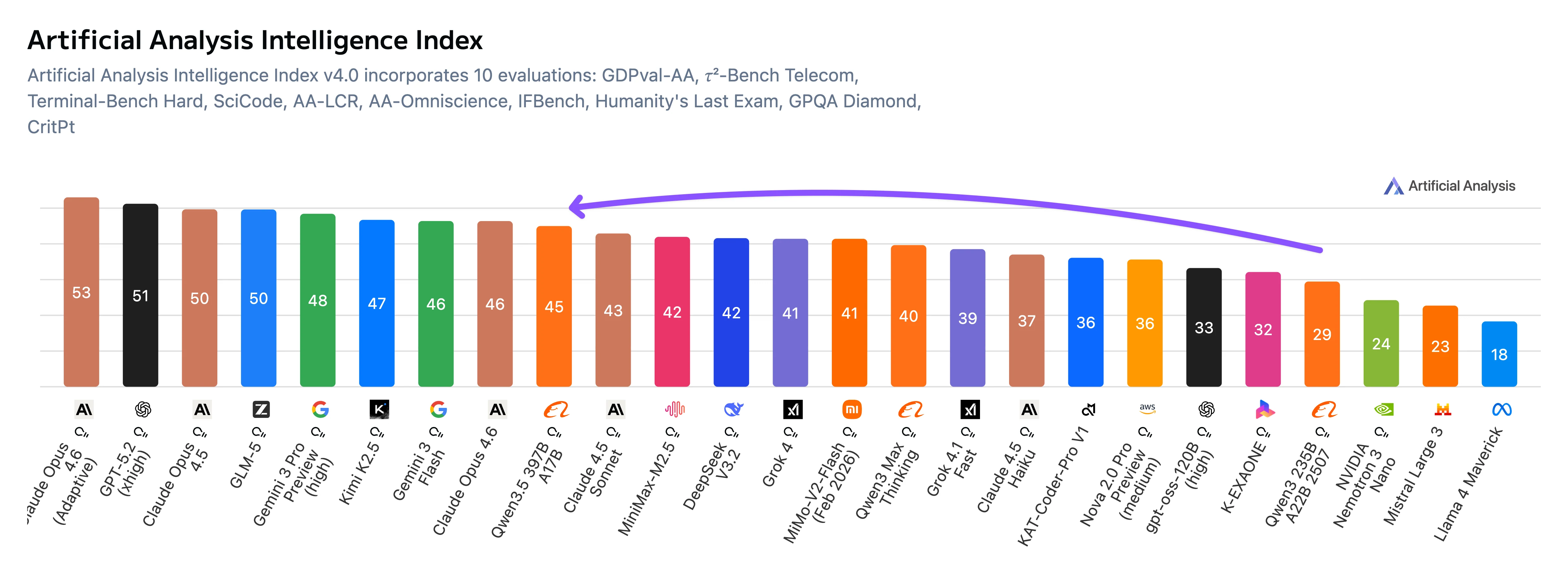
Qwen3.5-397B-A17B ist Alibaba Clouds Flaggschiff-Open-Weight-Mixture-of-Experts (MoE)-Sprachmodell mit 403 Milliarden Gesamtparametern und 17 Milliarden aktiven Parametern pro Token. Das Modell verarbeitet 262.144 Token Kontext (256K-Kontextfenster) und unterstützt native multimodale Eingaben einschließlich Text und Bildern. Laut Benchmarks von Artificial Analysis erreicht Qwen3.5-397B-A17B einen GDPval-AA-ELO-Score von 1.221, was einer Steigerung von 361 Punkten gegenüber dem vorherigen Qwen3 235B-Modell (860) entspricht. Das Modell zeigt besondere Stärken bei Programmier-, Reasoning- und Agent-Aufgaben, während es durch seine MoE-Architektur kosteneffizient bleibt.
Quelle: Artificial Analysis
Testen Sie das hervorragende Qwen 3.5
Übersicht der Benchmarks von Qwen3.5-397B-A17B
| Kategorie | Benchmark | Punktzahl | Führendes Modell |
|---|---|---|---|
| Anweisungsbefolgung | IFBench | 76.5 | Qwen3.5 |
| Komplexe Aufgaben | MultiChallenge | 67.6 | Qwen3.5 |
| Agent / Browsen | BrowseComp | 78.6 | Qwen3.5 |
| Wissenschaftliches Reasoning | GPQA Diamond | 88.4 | Qwen3.5 (Open-Modelle) |
| Wissen | MMLU-Pro | 87.8 | Gemini |
| Wissen | MMLU-Redux | 94.9 | Gemini |
| Wissen | C-Eval | 93.0 | Wettbewerbsfähig |
| Programmierung | LiveCodeBench v6 | 83.6 | Gemini / GPT |
| Multimodal | MMMU | 85.0 | Wettbewerbsfähig |
| Multimodal | MathVision | 88.6 | Wettbewerbsfähig |
| Multimodal | OCRBench | 93.1 | Wettbewerbsfähig |
| Multimodal | Video-MME | 87.5 | Wettbewerbsfähig |
Qwen3.5-397B erzielt seine besten Ergebnisse bei Benchmarks zur Anweisungsbefolgung und Agentenausrichtung, darunter IFBench, MultiChallenge und BrowseComp, wo es führende Modelle übertrifft. Es erreicht zudem den State-of-the-Art unter Open-Modellen bei GPQA Diamond, was auf starke Fähigkeiten im wissenschaftlichen Reasoning hindeutet.
Bei breiteren Wissens-Benchmarks wie MMLU-Pro und MMLU-Redux ist die Leistung hoch, liegt aber in der Regel leicht hinter führenden proprietären Modellen. Programmier-Benchmarks zeigen wettbewerbsfähige Ergebnisse, ohne das Feld anzuführen.
Insgesamt deutet das Benchmark-Profil darauf hin, dass Qwen3.5 für komplexe Anweisungen, Tool-Nutzung und Agenten-Workflows optimiert ist, anstatt traditionelle akademische Benchmarks wie Programmierung oder Wissensabfrage rein zu maximieren.
Methode 1: Web-Chat-Zugriff (Am schnellsten)
Ideal für: Schnelle Tests, Experimente, Demos und nicht-produktive Anwendungsfälle, bei denen Sie sofortigen Zugriff ohne API-Schlüssel oder Infrastruktur benötigen.
Einrichtungsdauer: Weniger als 1 Minute
Die offizielle Qwen-Chat-Oberfläche bietet sofortigen Zugriff auf Qwen3.5-397B-A17B über Ihren Browser:
- Navigieren Sie zu Novita AI
- Wählen Sie Qwen3.5-397B-A17B aus dem Modell-Dropdown-Menü aus
- Wählen Sie den “Thinking”-Modus für tiefgehende Reasoning-Aufgaben
- Starten Sie sofort den Chat – keine Kontenerstellung oder API-Schlüssel erforderlich
Einschränkungen
- Kein programmatischer Zugriff – Nur Web-UI, keine API-Integration
- Rate Limits gelten – Für interaktive Nutzung konzipiert, nicht für Stapelverarbeitung
- Kein Fine-Tuning – Sie nutzen das Basismodell unverändert
- Eingeschränkte Kontextpersistenz – Gesprächsverlauf wird von der Oberfläche verwaltet
Testen Sie das hervorragende Qwen 3.5
Methode 2: API-Zugriff über Novita AI (Produktiv)
Ideal für: Produktionsanwendungen, benutzerdefinierte Integrationen, programmatischen Zugriff, skalierbare Inferenz und Anwendungen, die ein OpenAI-kompatibles API-Format erfordern.
Einrichtungsdauer: 5 Minuten
Novita AI bietet verwalteten API-Zugriff auf Qwen3.5-397B-A17B mit wettbewerbsfähigen Preisen im Vergleich zu anderen großen Anbietern: 0,60 $ pro 1M Eingabe-Token und 3,60 $ pro 1M Ausgabe-Token. Der Dienst bietet OpenAI-kompatible Endpunkte, sodass die Integration für Entwickler, die bereits mit dem OpenAI SDK vertraut sind, unkompliziert ist.

Quelle: HuggingFace
Schritt-für-Schritt-Einrichtung
Schritt 1: Anmelden und auf die Modellbibliothek zugreifen
Melden Sie sich bei Ihrem Konto an und klicken Sie auf die Schaltfläche Modellbibliothek.

Schritt 2: Wählen Sie Ihr Modell
Durchsuchen Sie die verfügbaren Optionen und wählen Sie das Modell, das Ihren Anforderungen entspricht.

Schritt 3: Starten Sie Ihre kostenlose Testversion
Starten Sie Ihre kostenlose Testversion, um die Funktionen des ausgewählten Modells kennenzulernen.
Testen Sie das hervorragende Qwen 3.5
Schritt 4: Holen Sie sich Ihren API-Schlüssel
Zur Authentifizierung bei der API stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Auf der Seite „Einstellungen“ können Sie den API-Schlüssel wie in der Abbildung gezeigt kopieren.

Schritt 5: Installieren Sie die API
Installieren Sie die API über den für Ihre Programmiersprache spezifischen Paketmanager. Sie können Ihre API-Schlüssel auf der Novita AI-Einstellungsseite verwalten.
Importieren Sie nach der Installation die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Nutzung der Chat-Completions-API für Python-Nutzer.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3.5-397b-a17b",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=64000,
temperature=0.7
)
print(response.choices[0].message.content)
API-Funktionen
| Funktion | Verfügbarkeit |
|---|---|
| OpenAI-Kompatibilität | ✅ Vollständig unterstützt |
| Streaming-Antworten | ✅ Unterstützt |
| Funktionsaufrufe | ✅ Unterstützt |
| Kontextfenster | 262.144 Token |
| Multimodale Eingabe | ✅ Text + Bilder |
| SLA/Uptime | Unternehmensgrade Infrastruktur |
Die Preise von Novita AI für Qwen3.5-397B-A17B gehören zu den wettbewerbsfähigsten auf dem Markt. Die OpenAI-kompatible API bedeutet, dass Sie sie in bestehende Anwendungen integrieren können, indem Sie nur die Basis-URL und den API-Schlüssel ändern – keine Code-Refaktorierung erforderlich.
Integration mit Entwicklungstools
Verbinden Sie Qwen 3 nahtlos mit Ihren Anwendungen, Workflows oder Chatbots über die einheitliche REST-API von Novita AI – Sie müssen keine Modellgewichte oder Infrastruktur verwalten. Novita AI bietet mehrsprachige SDKs (Python, Node.js, cURL und mehr) und erweiterte Parametersteuerungen für Power-User.
Claude-Code-Integration
Claude Code verwendet Umgebungsvariablen, um Anfragen an benutzerdefinierte Modellendpunkte weiterzuleiten. Legen Sie diese vier Variablen fest, bevor Sie Claude Code starten:
Für macOS/Linux:
# Set the Anthropic SDK compatible API endpoint provided by Novita.
export ANTHROPIC_BASE_URL="https://api.novita.ai/anthropic"
export ANTHROPIC_AUTH_TOKEN="<Novita API Key>"
# Set the model provided by Novita.
export ANTHROPIC_MODEL="qwen/qwen3.5-397b-a17b"
export ANTHROPIC_SMALL_FAST_MODEL="qwen/qwen3.5-397b-a17b"
Für Windows (PowerShell):
$env:ANTHROPIC_BASE_URL = "https://api.novita.ai/anthropic"
$env:ANTHROPIC_AUTH_TOKEN = "Novita API Key"
$env:ANTHROPIC_MODEL = "qwen/qwen3.5-397b-a17b"
$env:ANTHROPIC_SMALL_FAST_MODEL = "qwen/qwen3.5-397b-a17b"
Trae-IDE-Integration
- Öffnen Sie Trae und schalten Sie die AI Side Bar um
- Navigieren Sie zu AI Management → Models
- Klicken Sie auf Add Custom Model
- Wählen Sie Novita AI als Anbieter aus
- Geben Sie Ihren API-Schlüssel ein und wählen Sie qwen/qwen3.5-397b-a17b
- Speichern Sie die Konfiguration und beginnen Sie mit der Codierung
OpenCode-CLI-Integration
# Launch OpenCode
opencode
# Connect to Novita AI
/connect
# Select Novita AI as provider, paste API key
# Choose qwen/qwen3.5-397b-a17b from model list
Methode 3: Lokale Bereitstellung (Volle Kontrolle)
Ideal für: Datenschutzanforderungen, Offline-Inferenz, benutzerdefinierte Inferenz-Pipelines, Forschungsumgebungen oder Szenarien, in denen Sie volle Kontrolle über die Modellausführung benötigen.
Einrichtungsdauer: 1–2 Stunden
Lokale Bereitstellung gibt Ihnen volle Kontrolle, erfordert aber erhebliche Hardware-Ressourcen. Die vollständigen Modellgewichte belegen bei voller Präzision etwa 807 GB Festplattenspeicher.
Hardwareanforderungen
| Präzisionsstufe | Erforderlicher VRAM/RAM | Empfohlene Hardware |
|---|---|---|
| 8-Bit-Quantisierung | Ca. 420 GB | 5× H100 80GB oder vergleichbar |
| 4-Bit-Quantisierung | Ca. 200 GB | M3 Ultra Mac (256 GB gemeinsamer Speicher) oder 1× 24GB GPU + 256 GB Systemspeicher |
Laut Unsloths Bereitstellungsleitfaden erreicht die 4-Bit-quantisierte Version 25+ Token pro Sekunde auf einem System mit 24 GB GPU und 256 GB Systemspeicher unter Verwendung von MoE-Offloading-Techniken. Dies macht die 4-Bit-Quantisierung zur praktischsten Option für High-End-Consumer- oder Kleinunternehmensbereitstellungen.
Cloud-GPU-Miete für lokale Bereitstellung
Wenn Ihnen die Hardware fehlt, Sie aber dennoch eine selbst gehostete Bereitstellung wünschen, bieten Cloud-GPU-Instanzen einen Mittelweg. Basierend auf den Preisen von Novita AI für GPU-Instanzen:
| Konfiguration | Stündliche Kosten (On-Demand) | Stündliche Kosten (Spot) | Anwendungsfall |
|---|---|---|---|
| 5× H100 80GB | 12,95 $/h | 6,5 $/h | 8-Bit-Quantisierung, produktionsgerecht |
| 1× RTX 4090 24GB | 0,73 $/h | 0,37 $/h | 4-Bit-Quantisierung, kosteneffizient |
Der Spot-Modus von Novita AI ist ein kostenoptimiertes GPU-Miet system, das die ungenutzte oder freie GPU-Kapazität der Plattform nutzt. Im Gegensatz zu On-Demand-Instanzen, die dedizierte Hardware für stabile, kontinuierliche Nutzung reservieren, sind Spot-Instanzen unterbrechbar – Ihr Auftrag kann pausiert oder beendet werden, wenn die GPU vom System zurückgefordert wird. Da der Spot-Modus ansonsten ungenutzte GPU-Ressourcen neu zuweist, ist er in der Regel 40–60 % günstiger als On-Demand-Preise.
Testen Sie jetzt kosteneffiziente GPUs!
Vergleichstabelle der Methoden
| Methode | Einrichtungsdauer | Kosten | Ideal für |
|---|---|---|---|
| Web-Chat (Novita AI LLM Playground) | <1 Minute | Kostenlos (mit Rate Limits) | Schnelle Tests, Demos, Experimente |
| API über Novita AI | 5 Minuten | 0,60 $ / 3,60 $ pro 1M Token | Produktionsanwendungen, skalierbare Inferenz, benutzerdefinierte Integrationen |
| Lokale Bereitstellung (INT4) | 1–2 Stunden | Hardwarekosten und 256 GB RAM-System | Datenschutz, Offline-Nutzung, volle Kontrolle |
| Cloud-GPU-Miete (INT4) | 30 Minuten | 0,37 $/h | Hochvolumige Inferenz |
Qwen3.5-397B-A17B bietet flexible Zugriffspfade für unterschiedliche Bereitstellungsszenarien. Für sofortige Tests erfordert das Novita AI LLM Playground keine Einrichtung und bietet sofortigen Zugriff auf sowohl Reasoning- als auch Schnellmodi. Für Produktionsanwendungen, die programmatischen Zugriff erfordern, bietet die API von Novita AI das beste Preis-Leistungs-Verhältnis mit 0,60 $ / 3,60 $ pro 1M Ein-/Ausgabe-Token und OpenAI-kompatiblen Endpunkten, die sich nahtlos in bestehende Codebasen integrieren lassen.
Lokale Bereitstellung bleibt für Teams mit spezifischen Datenschutzanforderungen oder extrem hohem Inferenz-Volumen eine praktikable Option. Die INT4-quantisierte Version kann auf High-End-Consumer-Hardware mit 256 GB RAM laufen und erreicht 25+ Token pro Sekunde. Für die meisten Entwickler und kleine bis mittlere Unternehmen eliminiert der verwaltete API-Zugriff jedoch die Infrastrukturkomplexität und bietet gleichzeitig unternehmensgrade Zuverlässigkeit.
Häufig gestellte Fragen
Wie viel kostet Qwen3.5-397B-A17B über die API? Novita AI berechnet 0,60 $ pro 1M Eingabe-Token und 3,60 $ pro 1M Ausgabe-Token für Qwen3.5-397B-A17B – das gehört zu den wettbewerbsfähigsten Preisen auf dem Markt.
Kann ich Qwen3.5-397B-A17B auf Consumer-Hardware ausführen? Ja, mit INT4-Quantisierung läuft Qwen3.5-397B-A17B auf Systemen mit 256 GB RAM (wie dem M3 Ultra Mac) mit 25+ Token/s und benötigt ca. 214 GB Festplattenspeicher.
Unterstützt Qwen3.5-397B-A17B Funktionsaufrufe? Ja, Qwen3.5-397B-A17B unterstützt Funktionsaufrufe, wenn es über API-Anbieter wie Novita AI mit OpenAI-kompatiblen Endpunkten abgerufen wird.
Novita AI ist eine KI- & Agenten-Cloud-Plattform, die Entwicklern und Startups hilft, Modelle und agentische Anwendungen mit hoher Leistung, Zuverlässigkeit und Kosteneffizienz zu erstellen, bereitzustellen und zu skalieren.
Empfohlene Lektüre



