

강력한 오픈 가중치 언어 모델을 탐구하는 개발자들은 공통적인 질문에 직면합니다: 이 모델을 실제로 어떻게 사용하기 시작할까? Qwen3.5-397B-A17B는 세 가지 뚜렷한 접근 경로를 제공합니다: 테스트를 위한 즉시 웹 채팅, 프로덕션 애플리케이션을 위한 관리형 API, 그리고 완전한 제어를 위한 자체 호스팅 배포. 각 방법은 빠른 프로토타이핑부터 엔터프라이즈 규모 추론까지 다양한 시나리오에 적합합니다.
이 가이드는 설정 지침, 실제 가격 데이터, 하드웨어 요구 사항과 함께 모든 접근 방법을 안내합니다. 어떤 경로가 사용 사례에 적합한지, 그리고 몇 분 안에 시작하는 방법을 배우게 됩니다.
Qwen3.5-397B-A17B란 무엇인가?
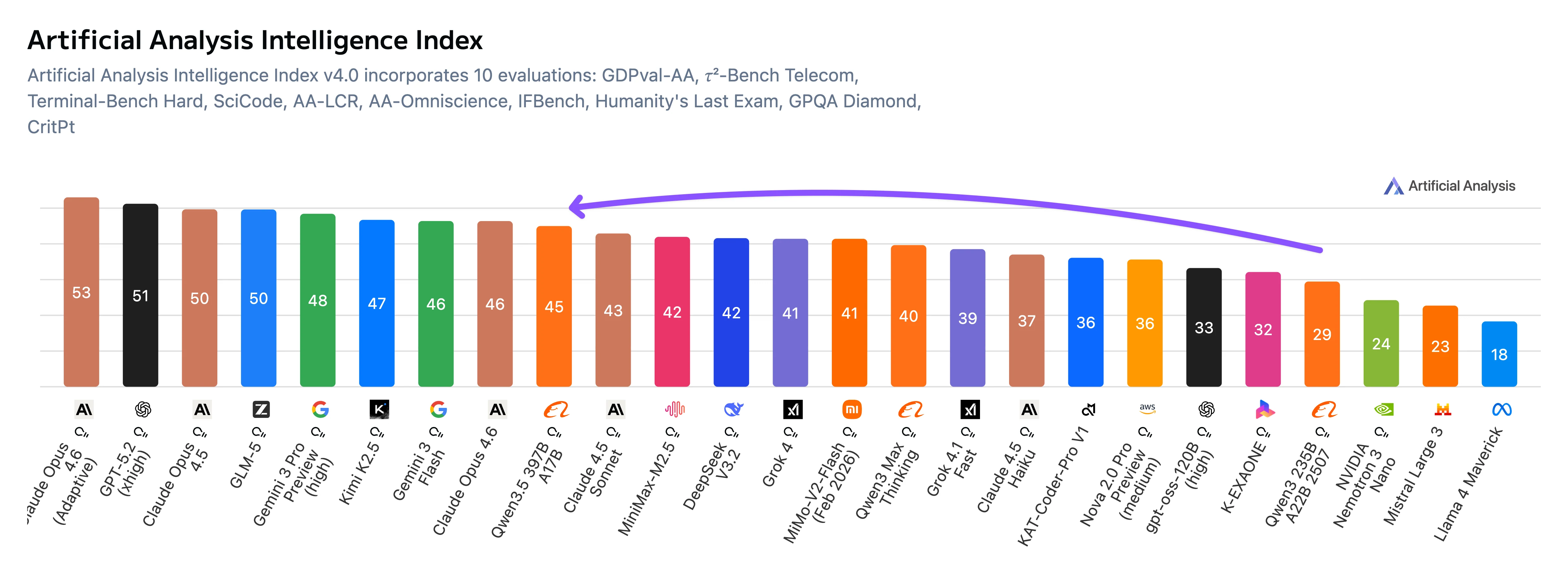
Qwen3.5-397B-A17B는 알리바바 클라우드의 주력 오픈 가중치 Mixture-of-Experts (MoE) 언어 모델로, 총 4030억 개의 파라미터와 토큰당 170억 개의 활성 파라미터를 가지고 있습니다. 이 모델은 262,144 토큰의 컨텍스트(256k 컨텍스트 윈도우)를 처리하며 텍스트와 이미지를 포함한 네이티브 멀티모달 입력을 지원합니다. Artificial Analysis 벤치마크에 따르면, Qwen3.5-397B-A17B는 GDPval-AA ELO 점수 1,221을 달성하여 이전 Qwen3 235B 모델(860)보다 361포인트 상승했습니다. 이 모델은 코딩, 추론, 에이전트 작업에서 특히 강점을 보이면서 MoE 아키텍처를 통해 비용 효율성을 유지합니다.
Qwen3.5-397B-A17B 벤치마크 개요
| 카테고리 | 벤치마크 | 점수 | 선도 모델 |
|---|---|---|---|
| 명령 수행 | IFBench | 76.5 | Qwen3.5 |
| 복잡한 작업 | MultiChallenge | 67.6 | Qwen3.5 |
| 에이전트 / 브라우징 | BrowseComp | 78.6 | Qwen3.5 |
| 과학적 추론 | GPQA Diamond | 88.4 | Qwen3.5 (오픈 모델) |
| 지식 | MMLU-Pro | 87.8 | Gemini |
| 지식 | MMLU-Redux | 94.9 | Gemini |
| 지식 | C-Eval | 93.0 | 경쟁적 |
| 코딩 | LiveCodeBench v6 | 83.6 | Gemini / GPT |
| 멀티모달 | MMMU | 85.0 | 경쟁적 |
| 멀티모달 | MathVision | 88.6 | 경쟁적 |
| 멀티모달 | OCRBench | 93.1 | 경쟁적 |
| 멀티모달 | Video-MME | 87.5 | 경쟁적 |
Qwen3.5-397B는 IFBench, MultiChallenge, BrowseComp를 포함한 명령 수행 및 에이전트 지향 벤치마크에서 가장 강력한 결과를 보여주며, 경쟁 모델을 앞서고 있습니다. 또한 GPQA Diamond에서 오픈 모델 중 최고 수준에 도달하여 강력한 과학적 추론 능력을 나타냅니다.
MMLU-Pro 및 MMLU-Redux와 같은 광범위한 지식 벤치마크에서는 성능이 높지만 일반적으로 선도적인 독점 모델에 비해 약간 뒤쳐집니다. 코딩 벤치마크는 경쟁력 있는 결과를 보여주지만 분야를 선도하지는 않습니다.
전반적으로 벤치마크 프로필은 Qwen3.5가 코딩이나 지식 회상과 같은 전통적인 학술 벤치마크를 순수하게 최대화하기보다는 복잡한 명령, 도구 사용, 에이전트 워크플로에 최적화되어 있음을 시사합니다.
방법 1: 웹 채팅 접근 (가장 빠름)
적합한 대상: API 키나 인프라 없이 즉시 접근이 필요한 빠른 테스트, 실험, 데모 및 비프로덕션 사용 사례.
설정 시간: 1분 미만
공식 Qwen 채팅 인터페이스는 브라우저를 통해 Qwen3.5-397B-A17B에 즉시 접근할 수 있도록 제공합니다:
- Novita AI로 이동
- 모델 드롭다운 메뉴에서 Qwen3.5-397B-A17B 선택
- 심층 추론 작업을 위해 “Thinking” 모드 중에서 선택
- 즉시 채팅 시작 — 계정 생성이나 API 키 불필요
제한 사항
- 프로그래밍 방식 접근 불가 — 웹 UI만 가능, API 통합 없음
- 속도 제한 적용 — 대화형 사용을 위해 설계, 배치 처리 불가
- 파인튜닝 불가 — 기본 모델을 그대로 사용
- 제한된 컨텍스트 지속성 — 대화 기록은 인터페이스에서 관리
방법 2: Novita AI를 통한 API 접근 (프로덕션)
적합한 대상: 프로덕션 애플리케이션, 사용자 정의 통합, 프로그래밍 방식 접근, 확장 가능한 추론, OpenAI 호환 API 형식이 필요한 애플리케이션.
설정 시간: 5분
Novita AI는 주요 제공업체 중 경쟁력 있는 가격으로 Qwen3.5-397B-A17B에 대한 관리형 API 접근을 제공합니다: 입력 토큰 100만 개당 $0.60, 출력 토큰 100만 개당 $3.60. 이 서비스는 OpenAI 호환 엔드포인트를 제공하여 이미 OpenAI SDK에 익숙한 개발자에게 통합을 간단하게 만듭니다.

출처: HuggingFace
단계별 설정
1단계: 로그인 및 모델 라이브러리 접근
계정에 로그인하고 Model Library 버튼을 클릭하세요.

2단계: 모델 선택
사용 가능한 옵션을 살펴보고 필요에 맞는 모델을 선택하세요.

3단계: 무료 체험 시작
선택한 모델의 기능을 탐색하기 위해 무료 체험을 시작하세요.
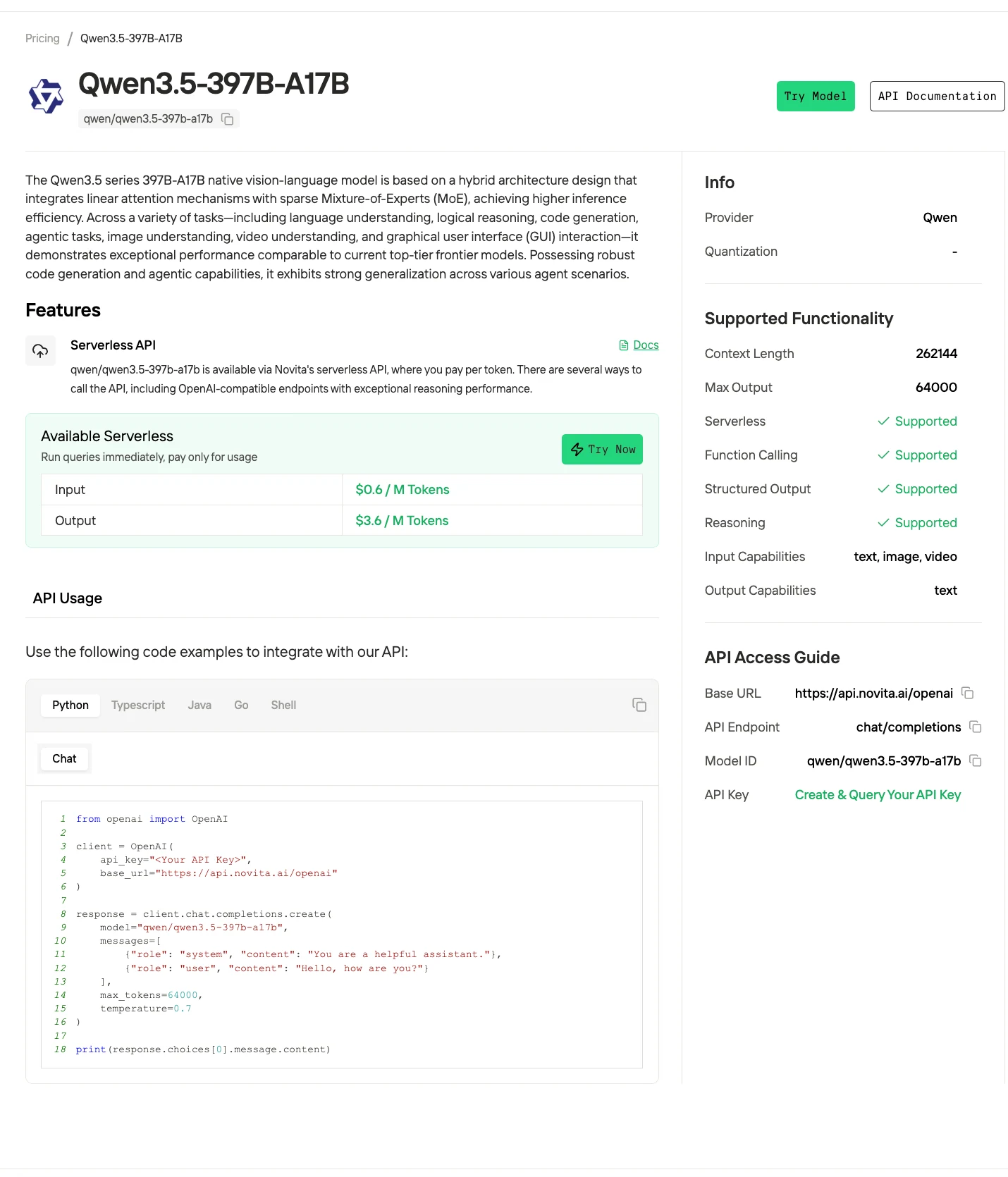
4단계: API 키 받기
API 인증을 위해 새로운 API 키를 제공합니다. “Settings” 페이지에 들어가면 이미지에 표시된 대로 API 키를 복사할 수 있습니다.

5단계: API 설치
프로그래밍 언어에 맞는 패키지 관리자를 사용하여 API를 설치하세요. Novita AI 설정 페이지에서 API 키를 관리할 수 있습니다.
설치 후 필요한 라이브러리를 개발 환경에 가져오세요. API 키로 API를 초기화하여 Novita AI LLM과 상호 작용을 시작하세요. 다음은 Python 사용자를 위한 채팅 완성 API 사용 예제입니다.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3.5-397b-a17b",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=64000,
temperature=0.7
)
print(response.choices[0].message.content)
API 기능
| 기능 | 가용성 |
|---|---|
| OpenAI 호환성 | ✅ 완전 지원 |
| 스트리밍 응답 | ✅ 지원 |
| 함수 호출 | ✅ 지원 |
| 컨텍스트 윈도우 | 262,144 토큰 |
| 멀티모달 입력 | ✅ 텍스트 + 이미지 |
| SLA/가동 시간 | 엔터프라이즈급 인프라 |
Novita AI의 Qwen3.5-397B-A17B 가격은 시장에서 가장 경쟁력 있는 수준입니다. OpenAI 호환 API는 기본 URL과 API 키만 변경하면 기존 애플리케이션에 통합할 수 있음을 의미합니다 — 코드 리팩토링이 필요 없습니다.
개발 도구와의 통합
Novita AI의 통합 REST API를 통해 Qwen 3를 애플리케이션, 워크플로 또는 챗봇에 원활하게 연결하세요 — 모델 가중치나 인프라를 관리할 필요가 없습니다. Novita AI는 다국어 SDK(Python, Node.js, cURL 등)와 고급 사용자를 위한 고급 매개변수 제어를 제공합니다.
Claude Code 통합
Claude Code는 환경 변수를 사용하여 사용자 정의 모델 엔드포인트로 요청을 라우팅합니다. Claude Code를 시작하기 전에 다음 네 가지 변수를 설정하세요:
macOS/Linux:
# Set the Anthropic SDK compatible API endpoint provided by Novita.
export ANTHROPIC_BASE_URL="https://api.novita.ai/anthropic"
export ANTHROPIC_AUTH_TOKEN="<Novita API Key>"
# Set the model provided by Novita.
export ANTHROPIC_MODEL="qwen/qwen3.5-397b-a17b"
export ANTHROPIC_SMALL_FAST_MODEL="qwen/qwen3.5-397b-a17b"
Windows (PowerShell):
$env:ANTHROPIC_BASE_URL = "https://api.novita.ai/anthropic"
$env:ANTHROPIC_AUTH_TOKEN = "Novita API Key"
$env:ANTHROPIC_MODEL = "qwen/qwen3.5-397b-a17b"
$env:ANTHROPIC_SMALL_FAST_MODEL = "qwen/qwen3.5-397b-a17b"
Trae IDE 통합
- Trae를 열고 AI 사이드 바를 토글
- AI 관리 → 모델로 이동
- 사용자 정의 모델 추가 클릭
- 제공업체로 Novita AI 선택
- API 키를 입력하고 qwen/qwen3.5-397b-a17b 선택
- 구성 저장 후 코딩 시작
OpenCode CLI 통합
# Launch OpenCode
opencode
# Connect to Novita AI
/connect
# Select Novita AI as provider, paste API key
# Choose qwen/qwen3.5-397b-a17b from model list
방법 3: 로컬 배포 (완전한 제어)
적합한 대상: 데이터 개인정보 보호 요구사항, 오프라인 추론, 사용자 정의 추론 파이프라인, 연구 환경, 또는 모델 실행에 대한 완전한 제어가 필요한 시나리오.
설정 시간: 1-2시간
로컬 배포는 완전한 제어를 제공하지만 상당한 하드웨어 리소스가 필요합니다. 전체 모델 가중치는 전체 정밀도에서 약 807GB의 디스크 공간을 차지합니다.
하드웨어 요구 사항
| 정밀도 수준 | 필요 VRAM/RAM | 권장 하드웨어 |
|---|---|---|
| 8비트 양자화 | 약 420GB | 5× H100 80GB 또는 동급 |
| 4비트 양자화 | 약 200GB | M3 Ultra Mac (256GB 통합 메모리) 또는 1×24GB GPU + 256GB 시스템 RAM |
Unsloth의 배포 가이드에 따르면, 4비트 양자화 버전은 MoE 오프로딩 기술을 사용하여 24GB GPU와 256GB 시스템 RAM을 갖춘 시스템에서 초당 25+ 토큰을 달성합니다. 이는 4비트 양자화를 고급 소비자 또는 소규모 비즈니스 배포에 가장 실용적인 옵션으로 만듭니다.
로컬 배포를 위한 클라우드 GPU 임대
하드웨어가 부족하지만 여전히 자체 호스팅 배포를 원한다면, 클라우드 GPU 인스턴스가 중간 지점을 제공합니다. Novita AI GPU 인스턴스 가격 기준:
| 구성 | 시간당 비용 (온디맨드) | 시간당 비용 (스팟) | 사용 사례 |
|---|---|---|---|
| 5× H100 80GB | $12.95/시간 | $6.5/시간 | 8비트 양자화, 프로덕션급 |
| 1× RTX 4090 24GB | $0.73/시간 | $0.37/시간 | 4비트 양자화, 비용 효율적 |
Novita AI의 스팟 모드는 플랫폼의 유휴 또는 사용되지 않는 GPU 용량을 활용하는 비용 최적화 GPU 임대 시스템입니다. 안정적이고 지속적인 사용을 위해 전용 하드웨어를 예약하는 온디맨드 인스턴스와 달리, 스팟 인스턴스는 중단 가능합니다 — GPU가 시스템에 의해 회수되면 작업이 일시 중지되거나 종료될 수 있습니다. 스팟 모드는 그렇지 않으면 사용되지 않는 GPU 리소스를 재할당하기 때문에 일반적으로 온디맨드 가격보다 40~60% 저렴합니다.
방법 비교 표
| 방법 | 설정 시간 | 비용 | 적합한 대상 |
|---|---|---|---|
| 웹 채팅 (Novita AI LLM Playground) | <1분 | 무료 (속도 제한 있음) | 빠른 테스트, 데모, 실험 |
| Novita AI를 통한 API | 5분 | 토큰 100만 개당 $0.60/$3.60 | 프로덕션 앱, 확장 가능한 추론, 사용자 정의 통합 |
| 로컬 배포 (INT4) | 1-2시간 | 하드웨어 비용 및 256GB RAM 시스템 | 데이터 개인정보 보호, 오프라인 사용, 완전한 제어 |
| 클라우드 GPU 임대(INT4) | 30분 | $0.37/시간 | 대량 추론 |
Qwen3.5-397B-A17B는 다양한 배포 시나리오에 맞는 유연한 접근 경로를 제공합니다. 즉시 테스트를 위해 Novita AI LLM Playground는 설정이 필요 없으며 추론 및 빠른 모드 모두에 즉시 접근할 수 있습니다. 프로그래밍 방식 접근이 필요한 프로덕션 애플리케이션의 경우, Novita AI의 API는 기존 코드베이스에 원활하게 통합되는 OpenAI 호환 엔드포인트와 함께 입력/출력 토큰 100만 개당 $0.60/$3.60의 최고의 비용-성능 균형을 제공합니다.
로컬 배포는 특정 개인정보 보호 요구사항이나 매우 높은 볼륨의 추론이 필요한 팀에게 여전히 실행 가능합니다. INT4 양자화 버전은 256GB RAM을 갖춘 고급 소비자 하드웨어에서 실행되어 초당 25+ 토큰을 달성할 수 있습니다. 그러나 대부분의 개발자와 중소기업의 경우, 관리형 API 접근은 인프라 복잡성을 제거하면서 엔터프라이즈급 안정성을 제공합니다.
자주 묻는 질문
Qwen3.5-397B-A17B를 API로 사용하는 비용은 얼마인가요?
Novita AI는 Qwen3.5-397B-A17B에 대해 입력 토큰 100만 개당 $0.60, 출력 토큰 100만 개당 $3.60를 청구합니다 — 가장 경쟁력 있는 요금 중 하나입니다.
Qwen3.5-397B-A17B를 소비자 하드웨어에서 실행할 수 있나요?
네, INT4 양자화를 사용하면 Qwen3.5-397B-A17B는 256GB RAM(예: M3 Ultra Mac)이 있는 시스템에서 초당 25+ 토큰으로 실행되며, 약 214GB의 디스크 공간이 필요합니다.
Qwen3.5-397B-A17B는 함수 호출을 지원하나요?
네, Qwen3.5-397B-A17B는 OpenAI 호환 엔드포인트를 사용하여 Novita AI와 같은 API 제공업체를 통해 접근할 때 함수 호출을 지원합니다.
Novita AI는 개발자와 스타트업이 고성능, 안정성, 비용 효율성으로 모델과 에이전트 애플리케이션을 구축, 배포, 확장할 수 있도록 지원하는 AI 및 에이전트 클라우드 플랫폼입니다.
추천 자료



