

Los desarrolladores que exploran potentes modelos de lenguaje de peso abierto se enfrentan a una pregunta común: ¿cómo empiezo realmente a usar este modelo? Qwen3.5-397B-A17B ofrece tres rutas de acceso diferenciadas: chat web instantáneo para pruebas, APIs gestionadas para aplicaciones de producción y despliegue autogestionado para control total. Cada método se adapta a diferentes escenarios, desde prototipado rápido hasta inferencia a escala empresarial.
Esta guía recorre todos los métodos de acceso con instrucciones de configuración, datos de precios reales y requisitos de hardware. Aprenderás qué ruta se adapta a tu caso de uso y cómo empezar en cuestión de minutos.
¿Qué es Qwen3.5-397B-A17B?
Qwen3.5-397B-A17B es el modelo de lenguaje insignia de peso abierto de Alibaba Cloud, basado en una arquitectura Mixture-of-Experts (MoE) con 403 mil millones de parámetros totales y 17 mil millones de parámetros activos por token. El modelo maneja 262,144 tokens de contexto (ventana de contexto de 256k) y admite entradas multimodales nativas, incluyendo texto e imágenes. Según los benchmarks de Artificial Analysis, Qwen3.5-397B-A17B alcanza una puntuación GDPval-AA ELO de 1,221, lo que representa un aumento de 361 puntos respecto al modelo anterior Qwen3 235B (860). El modelo muestra particular fortaleza en tareas de codificación, razonamiento y agentes, manteniendo al mismo tiempo la eficiencia de costes gracias a su arquitectura MoE.
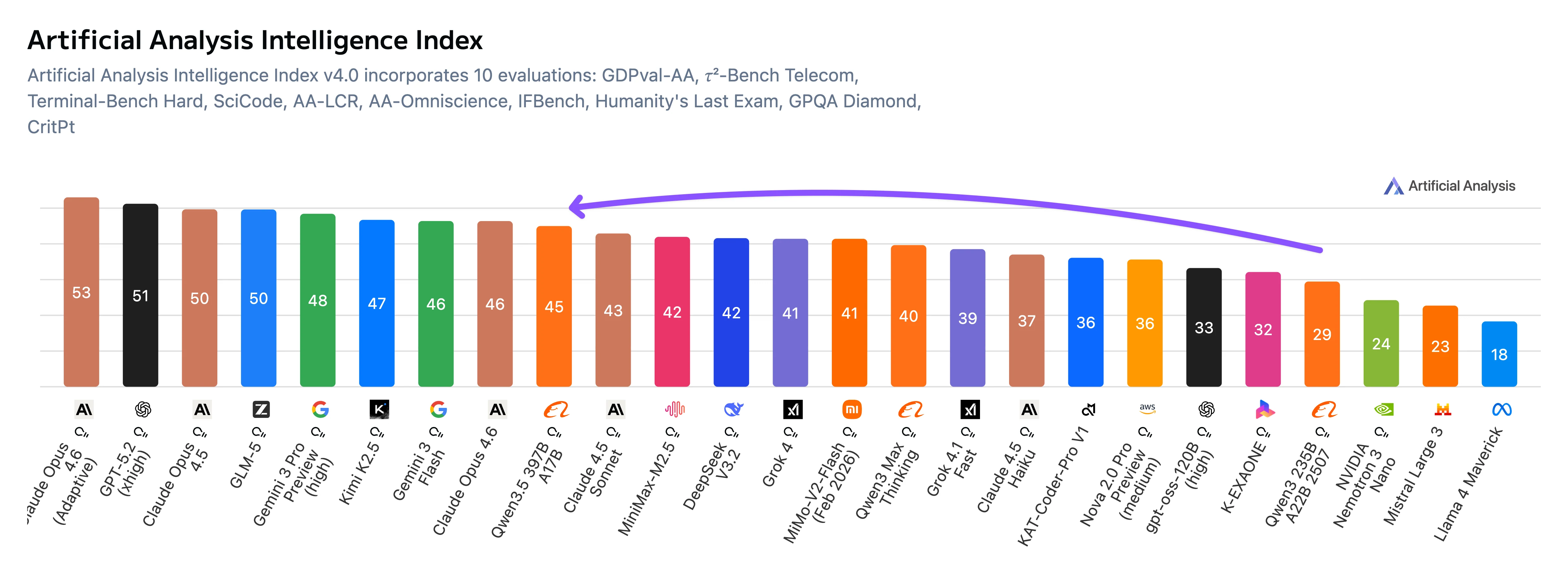
Resumen de benchmarks de Qwen3.5-397B-A17B
| Categoría | Benchmark | Puntuación | Modelo líder |
|---|---|---|---|
| Seguimiento de instrucciones | IFBench | 76.5 | Qwen3.5 |
| Tareas complejas | MultiChallenge | 67.6 | Qwen3.5 |
| Agente / Navegación | BrowseComp | 78.6 | Qwen3.5 |
| Razonamiento científico | GPQA Diamond | 88.4 | Qwen3.5 (modelos abiertos) |
| Conocimiento | MMLU-Pro | 87.8 | Gemini |
| Conocimiento | MMLU-Redux | 94.9 | Gemini |
| Conocimiento | C-Eval | 93.0 | Competitivo |
| Codificación | LiveCodeBench v6 | 83.6 | Gemini / GPT |
| Multimodal | MMMU | 85.0 | Competitivo |
| Multimodal | MathVision | 88.6 | Competitivo |
| Multimodal | OCRBench | 93.1 | Competitivo |
| Multimodal | Video-MME | 87.5 | Competitivo |
Qwen3.5-397B obtiene sus mejores resultados en benchmarks de seguimiento de instrucciones y orientados a agentes, incluyendo IFBench, MultiChallenge y BrowseComp, donde lidera frente a otros modelos competidores. También alcanza un estado del arte entre los modelos abiertos en GPQA Diamond, lo que indica una sólida capacidad de razonamiento científico.
En benchmarks de conocimiento más amplios como MMLU-Pro y MMLU-Redux, el rendimiento es alto pero generalmente ligeramente por detrás de los modelos propietarios líderes. Los benchmarks de codificación muestran resultados competitivos sin liderar el campo.
En general, el perfil de benchmarks sugiere que Qwen3.5 está optimizado para instrucciones complejas, uso de herramientas y flujos de trabajo de agentes, en lugar de maximizar puramente los benchmarks académicos tradicionales como la codificación o la recuperación de conocimiento.
Método 1: Acceso por chat web (el más rápido)
Ideal para: Pruebas rápidas, experimentación, demostraciones y casos de uso no productivos donde necesitas acceso inmediato sin claves API ni infraestructura.
Tiempo de configuración: Menos de 1 minuto
La interfaz de chat oficial de Qwen proporciona acceso instantáneo a Qwen3.5-397B-A17B a través de tu navegador:
- Navega a Novita AI
- Selecciona Qwen3.5-397B-A17B del menú desplegable de modelos
- Elige entre el modo “Thinking” para tareas de razonamiento profundo
- Empieza a chatear inmediatamente — sin necesidad de crear cuenta ni claves API
Limitaciones
- Sin acceso programático — solo interfaz web, sin integración API
- Límites de velocidad aplicables — diseñado para uso interactivo, no para procesamiento por lotes
- Sin ajuste fino — utilizas el modelo base tal cual
- Persistencia de contexto limitada — el historial de la conversación es gestionado por la interfaz
Método 2: Acceso API a través de Novita AI (Producción)
Ideal para: Aplicaciones de producción, integraciones personalizadas, acceso programático, inferencia escalable y aplicaciones que requieren un formato de API compatible con OpenAI.
Tiempo de configuración: 5 minutos
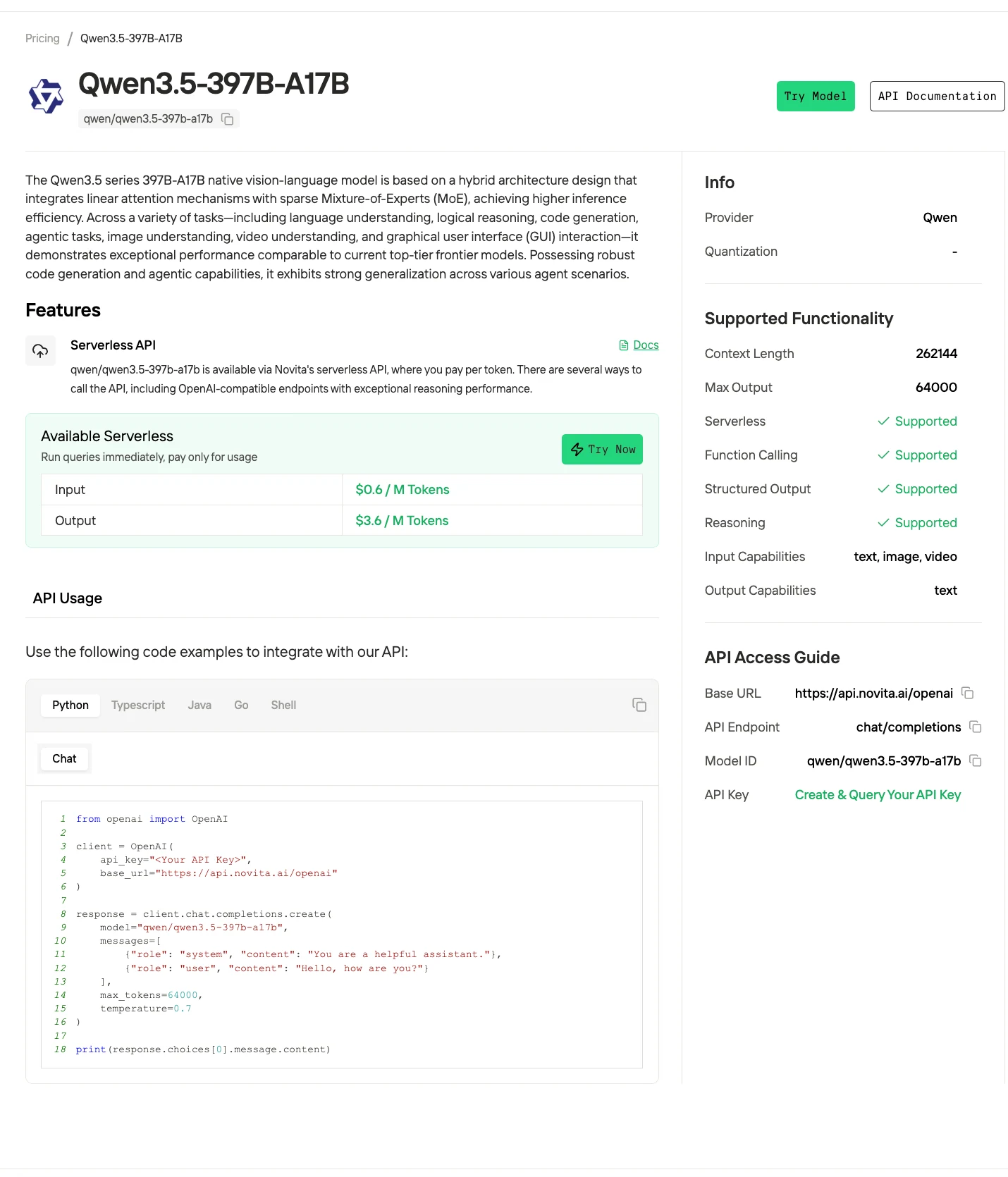
Novita AI proporciona acceso API gestionado a Qwen3.5-397B-A17B con precios competitivos entre los principales proveedores: $0.60 por 1M de tokens de entrada y $3.60 por 1M de tokens de salida. El servicio ofrece endpoints compatibles con OpenAI, lo que facilita la integración para desarrolladores ya familiarizados con el SDK de OpenAI.

De HuggingFace
Configuración paso a paso
Paso 1: Inicia sesión y accede a la biblioteca de modelos
Inicia sesión en tu cuenta y haz clic en el botón Model Library.

Paso 2: Elige tu modelo
Navega por las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.

Paso 3: Comienza tu prueba gratuita
Inicia tu prueba gratuita para explorar las capacidades del modelo seleccionado.
Paso 4: Obtén tu clave API
Para autenticarte con la API, te proporcionaremos una nueva clave API. Entra en la página de “Settings”, puedes copiar la clave API como se indica en la imagen.

Paso 5: Instala la API
Instala la API usando el gestor de paquetes específico de tu lenguaje de programación. Puedes gestionar tus claves API desde la página de Settings de Novita AI.
Después de la instalación, importa las bibliotecas necesarias en tu entorno de desarrollo. Inicializa la API con tu clave API para empezar a interactuar con Novita AI LLM. Este es un ejemplo de uso de la API de completado de chat para usuarios de Python.
from openai import OpenAI
client = OpenAI(
api_key="<Tu clave API>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3.5-397b-a17b",
messages=[
{"role": "system", "content": "Eres un asistente útil."},
{"role": "user", "content": "Hola, ¿cómo estás?"}
],
max_tokens=64000,
temperature=0.7
)
print(response.choices[0].message.content)
Características de la API
| Característica | Disponibilidad |
|---|---|
| Compatibilidad con OpenAI | ✅ Soporte completo |
| Respuestas en streaming | ✅ Compatible |
| Llamadas a funciones | ✅ Compatible |
| Ventana de contexto | 262,144 tokens |
| Entrada multimodal | ✅ Texto + Imágenes |
| SLA/Tiempo de actividad | Infraestructura de nivel empresarial |
El precio de Novita AI para Qwen3.5-397B-A17B se encuentra entre los más competitivos del mercado. La API compatible con OpenAI significa que puedes integrarla en aplicaciones existentes cambiando solo la URL base y la clave API — sin necesidad de refactorizar código.
Integración con herramientas de desarrollo
Conecta Qwen 3 sin problemas a tus aplicaciones, flujos de trabajo o chatbots con la API REST unificada de Novita AI — sin necesidad de gestionar pesos de modelos ni infraestructura. Novita AI ofrece SDKs multilingües (Python, Node.js, cURL y más) y controles avanzados de parámetros para usuarios avanzados.
Integración con Claude Code
Claude Code utiliza variables de entorno para enrutar solicitudes a endpoints de modelos personalizados. Establece estas cuatro variables antes de iniciar Claude Code:
Para macOS/Linux:
# Establece el endpoint de API compatible con Anthropic SDK proporcionado por Novita.
export ANTHROPIC_BASE_URL="https://api.novita.ai/anthropic"
export ANTHROPIC_AUTH_TOKEN="<Clave API de Novita>"
# Establece el modelo proporcionado por Novita.
export ANTHROPIC_MODEL="qwen/qwen3.5-397b-a17b"
export ANTHROPIC_SMALL_FAST_MODEL="qwen/qwen3.5-397b-a17b"
Para Windows (PowerShell):
$env:ANTHROPIC_BASE_URL = "https://api.novita.ai/anthropic"
$env:ANTHROPIC_AUTH_TOKEN = "Clave API de Novita"
$env:ANTHROPIC_MODEL = "qwen/qwen3.5-397b-a17b"
$env:ANTHROPIC_SMALL_FAST_MODEL = "qwen/qwen3.5-397b-a17b"
Integración con Trae IDE
- Abre Trae y activa la Barra lateral de IA
- Navega a AI Management → Models
- Haz clic en Add Custom Model
- Selecciona Novita AI como proveedor
- Ingresa tu clave API y selecciona qwen/qwen3.5-397b-a17b
- Guarda la configuración y empieza a codificar
Integración con OpenCode CLI
# Lanza OpenCode
opencode
# Conéctate a Novita AI
/connect
# Selecciona Novita AI como proveedor, pega la clave API
# Elige qwen/qwen3.5-397b-a17b de la lista de modelos
Método 3: Despliegue local (Control total)
Ideal para: Requisitos de privacidad de datos, inferencia sin conexión, tuberías de inferencia personalizadas, entornos de investigación o escenarios donde necesitas control completo sobre la ejecución del modelo.
Tiempo de configuración: 1-2 horas
El despliegue local te da control total pero requiere recursos de hardware significativos. Los pesos completos del modelo ocupan aproximadamente 807 GB de espacio en disco en precisión completa.
Requisitos de hardware
| Nivel de precisión | VRAM/RAM requerida | Hardware recomendado |
|---|---|---|
| Cuantización de 8 bits | Alrededor de 420 GB | 5× H100 80GB o equivalente |
| Cuantización de 4 bits | Alrededor de 200 GB | M3 Ultra Mac (256 GB de memoria unificada) o 1×GPU 24GB + 256 GB de RAM del sistema |
Según la guía de despliegue de Unsloth, la versión cuantizada a 4 bits alcanza más de 25 tokens por segundo en un sistema con una GPU de 24 GB y 256 GB de RAM del sistema utilizando técnicas de descarga de MoE. Esto hace que la cuantización de 4 bits sea la opción más práctica para implementaciones en consumidores de alta gama o pequeñas empresas.
Alquiler de GPU en la nube para despliegue local
Si careces del hardware pero aún deseas un despliegue autogestionado, las instancias de GPU en la nube ofrecen un punto intermedio. Basado en los precios de instancias GPU de Novita AI:
| Configuración | Coste por hora (bajo demanda) | Coste por hora (Spot) | Caso de uso |
|---|---|---|---|
| 5× H100 80GB | $12.95/hora | $6.5/hora | Cuantización de 8 bits, nivel de producción |
| 1× RTX 4090 24GB | $0.73/hora | $0.37/hora | Cuantización de 4 bits, rentable |
El modo Spot de Novita AI es un sistema de alquiler de GPU optimizado en costes que aprovecha la capacidad inactiva o no utilizada de la plataforma. A diferencia de las instancias bajo demanda, que reservan hardware dedicado para un uso estable y continuo, las instancias Spot son interrumpibles: tu trabajo puede pausarse o terminarse si la GPU es reclamada por el sistema. Debido a que el modo Spot reasigna recursos GPU que de otro modo no se usarían, suele ser un 40-60% más barato que el precio bajo demanda.
Tabla comparativa de métodos
| Método | Tiempo de configuración | Coste | Ideal para |
|---|---|---|---|
| Chat web (Novita AI LLM Playground) | <1 minuto | Gratis (con límites de velocidad) | Pruebas rápidas, demostraciones, experimentación |
| API a través de Novita AI | 5 minutos | $0.60/$3.60 por 1M de tokens | Aplicaciones de producción, inferencia escalable, integraciones personalizadas |
| Despliegue local (INT4) | 1-2 horas | Coste de hardware y sistema con 256 GB de RAM | Privacidad de datos, uso sin conexión, control total |
| Alquiler de GPU en la nube (INT4) | 30 minutos | $0.37/hora | Inferencia de alto volumen |
Qwen3.5-397B-A17B ofrece rutas de acceso flexibles para diferentes escenarios de despliegue. Para pruebas inmediatas, el Novita AI LLM Playground no requiere configuración y proporciona acceso instantáneo tanto al modo de razonamiento como al modo rápido. Para aplicaciones de producción que requieren acceso programático, la API de Novita AI ofrece el mejor equilibrio coste-rendimiento a $0.60/$3.60 por 1M de tokens de entrada/salida con endpoints compatibles con OpenAI que se integran perfectamente en bases de código existentes.
El despliegue local sigue siendo viable para equipos con requisitos específicos de privacidad o necesidades de inferencia de volumen extremadamente alto. La versión cuantizada INT4 puede ejecutarse en hardware de consumo de gama alta con 256 GB de RAM, alcanzando más de 25 tokens por segundo. Sin embargo, para la mayoría de los desarrolladores y pequeñas y medianas empresas, el acceso API gestionado elimina la complejidad de la infraestructura a la vez que ofrece fiabilidad de nivel empresarial.
Preguntas frecuentes
¿Cuánto cuesta Qwen3.5-397B-A17B a través de API?
Novita AI cobra $0.60 por 1M de tokens de entrada y $3.60 por 1M de tokens de salida para Qwen3.5-397B-A17B — entre las tarifas más competitivas disponibles.
¿Puedo ejecutar Qwen3.5-397B-A17B en hardware de consumo?
Sí, con cuantización INT4, Qwen3.5-397B-A17B se ejecuta en sistemas con 256 GB de RAM (como M3 Ultra Mac) a más de 25 tokens/s, requiriendo aproximadamente 214 GB de espacio en disco.
¿Qwen3.5-397B-A17B soporta llamadas a funciones?
Sí, Qwen3.5-397B-A17B soporta llamadas a funciones cuando se accede a través de proveedores de API como Novita AI utilizando endpoints compatibles con OpenAI.
Novita AI es una plataforma en la nube de IA y agentes que ayuda a desarrolladores y startups a construir, desplegar y escalar modelos y aplicaciones de agentes con alto rendimiento, fiabilidad y eficiencia de costes.
Lecturas recomendadas



