

يطرح المطورون الذين يستكشفون نماذج لغة مفتوحة الوزن قوية سؤالاً شائعاً: كيف أبدأ فعلاً في استخدام هذا النموذج؟ يوفر Qwen3.5-397B-A17B ثلاث طرق وصول متميزة: محادثة ويب فورية للاختبار، واجهات برمجة تطبيقات (APIs) مُدارة لتطبيقات الإنتاج، ونشر مستضاف ذاتياً للتحكم الكامل. كل طريقة تناسب سيناريوهات مختلفة — من النماذج الأولية السريعة إلى الاستدلال على نطاق المؤسسات.
يشرح هذا الدليل جميع طرق الوصول مع تعليمات الإعداد، وأسعار حقيقية، ومتطلبات الأجهزة. ستتعرف أي طريقة تناسب حالة الاستخدام الخاصة بك وكيف تبدأ في دقائق.
ما هو Qwen3.5-397B-A17B؟
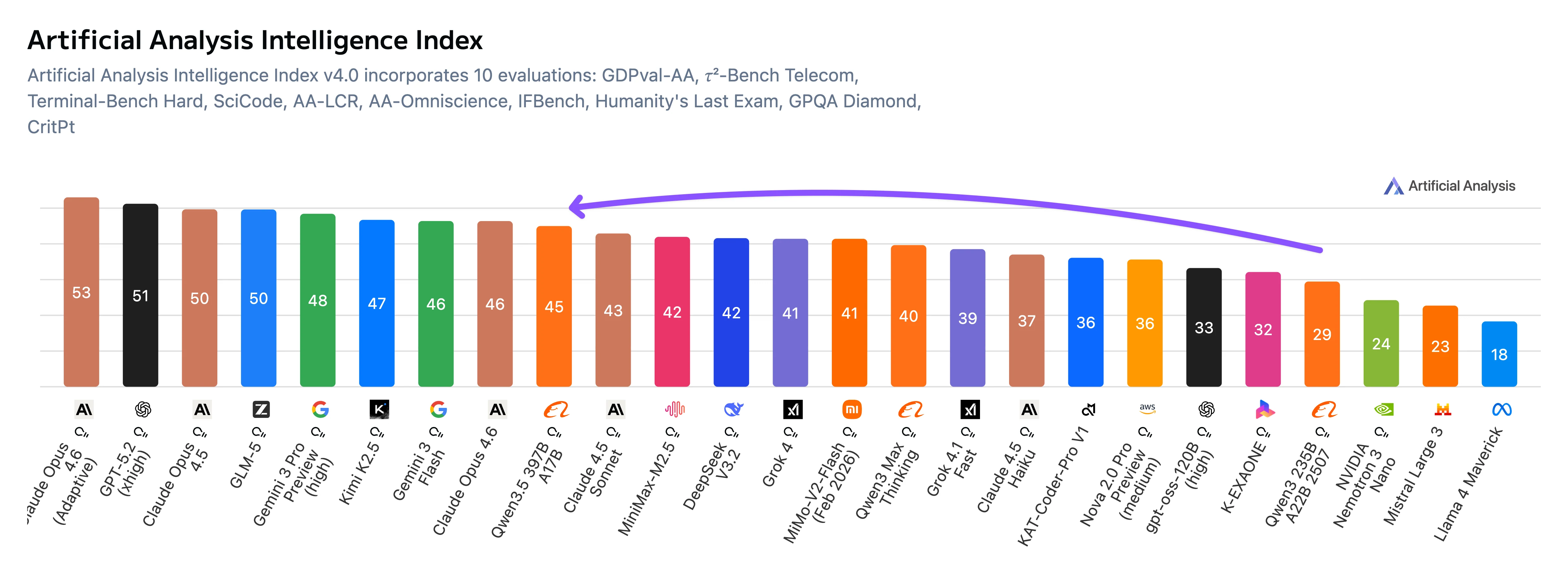
Qwen3.5-397B-A17B هو نموذج لغة مفتوح الوزن من Alibaba Cloud من فئة Mixture-of-Experts (MoE) الرائد، مع 403 مليار معامل إجمالي و 17 مليار معامل نشط لكل رمز. يتعامل النموذج مع 262,144 رمز من السياق (نافذة سياق 256k) ويدعم المدخلات متعددة الوسائط الأصلية بما في ذلك النصوص والصور. وفقاً لمعايير Artificial Analysis، يحقق Qwen3.5-397B-A17B درجة ELO من GDPval-AA تبلغ 1,221، مما يمثل زيادة قدرها 361 نقطة عن النموذج السابق Qwen3 235B (860). يظهر النموذج قوة خاصة في مهام البرمجة والاستدلال والوكلاء مع الحفاظ على الكفاءة من حيث التكلفة من خلال بنيته MoE.
نظرة عامة على معايير Qwen3.5-397B-A17B
| الفئة | المعيار | الدرجة | النموذج الرائد |
|---|---|---|---|
| متابعة التعليمات | IFBench | 76.5 | Qwen3.5 |
| المهام المعقدة | MultiChallenge | 67.6 | Qwen3.5 |
| الوكيل / التصفح | BrowseComp | 78.6 | Qwen3.5 |
| الاستدلال العلمي | GPQA Diamond | 88.4 | Qwen3.5 (النماذج المفتوحة) |
| المعرفة | MMLU-Pro | 87.8 | Gemini |
| المعرفة | MMLU-Redux | 94.9 | Gemini |
| المعرفة | C-Eval | 93.0 | تنافسي |
| البرمجة | LiveCodeBench v6 | 83.6 | Gemini / GPT |
| متعدد الوسائط | MMMU | 85.0 | تنافسي |
| متعدد الوسائط | MathVision | 88.6 | تنافسي |
| متعدد الوسائط | OCRBench | 93.1 | تنافسي |
| متعدد الوسائط | Video-MME | 87.5 | تنافسي |
يحقق Qwen3.5-397B أفضل نتائجه على معايير متابعة التعليمات والموجهة للوكلاء، بما في ذلك IFBench و MultiChallenge و BrowseComp، حيث يتفوق على النماذج المنافسة. كما يصل إلى حالة متقدمة بين النماذج المفتوحة في GPQA Diamond، مما يدل على قدرة استدلال علمي قوية.
على معايير المعرفة الأوسع مثل MMLU-Pro و MMLU-Redux، الأداء مرتفع ولكنه عادة ما يكون أقل قليلاً من النماذج المملوكة الرائدة. تظهر معايير البرمجة نتائج تنافسية دون أن تتقدم على المجال.
بشكل عام، تشير ملف المعايير إلى أن Qwen3.5 مُحسّن للتعليمات المعقدة واستخدام الأدوات وسير عمل الوكلاء، بدلاً من تعظيم المعايير الأكاديمية التقليدية مثل البرمجة أو استدعاء المعرفة بحتة.
الطريقة 1: الوصول عبر محادثة الويب (الأسرع)
الأفضل لـ: الاختبار السريع، والتجارب، والعروض التوضيحية، وحالات الاستخدام غير الإنتاجية التي تحتاج فيها إلى وصول فوري بدون مفاتيح API أو بنية تحتية.
وقت الإعداد: أقل من دقيقة واحدة
توفر واجهة المحادثة الرسمية لـ Qwen وصولاً فورياً إلى Qwen3.5-397B-A17B من خلال متصفحك:
- انتقل إلى Novita AI
- اختر Qwen3.5-397B-A17B من القائمة المنسدلة للنماذج
- اختر بين وضع “التفكير” لمهام الاستدلال العميق
- ابدأ المحادثة فوراً — لا حاجة لإنشاء حساب أو مفاتيح API
القيود
- لا يوجد وصول برمجي — واجهة ويب فقط، لا تكامل مع API
- تطبق حدود معدل الاستخدام — مصمم للاستخدام التفاعلي، وليس للمعالجة الدفعية
- لا يوجد ضبط دقيق — تستخدم النموذج الأساسي كما هو
- استمرارية سياق محدودة — سجل المحادثات تديره الواجهة
الطريقة 2: الوصول عبر API من خلال Novita AI (للإنتاج)
الأفضل لـ: تطبيقات الإنتاج، التكاملات المخصصة، الوصول البرمجي، الاستدلال القابل للتطوير، والتطبيقات التي تتطلب تنسيق API متوافق مع OpenAI.
وقت الإعداد: 5 دقائق
يوفر Novita AI وصولاً مُداراً عبر API إلى Qwen3.5-397B-A17B مع أسعار تنافسية بين كبار المزودين: 0.60 دولار لكل 1M رمز إدخال و 3.60 دولار لكل 1M رمز إخراج. تقدم الخدمة نقاط نهاية متوافقة مع OpenAI، مما يجعل التكامل بسيطاً للمطورين المعتادين بالفعل على حزمة تطوير البرامج (SDK) الخاصة بـ OpenAI.

من HuggingFace
إعداد خطوة بخطوة
الخطوة 1: تسجيل الدخول والوصول إلى مكتبة النماذج
سجل الدخول إلى حسابك وانقر على زر مكتبة النماذج.

الخطوة 2: اختر النموذج الخاص بك
تصفح الخيارات المتاحة واختر النموذج الذي يناسب احتياجاتك.

الخطوة 3: ابدأ تجربتك المجانية
ابدأ تجربتك المجانية لاستكشاف قدرات النموذج المحدد.
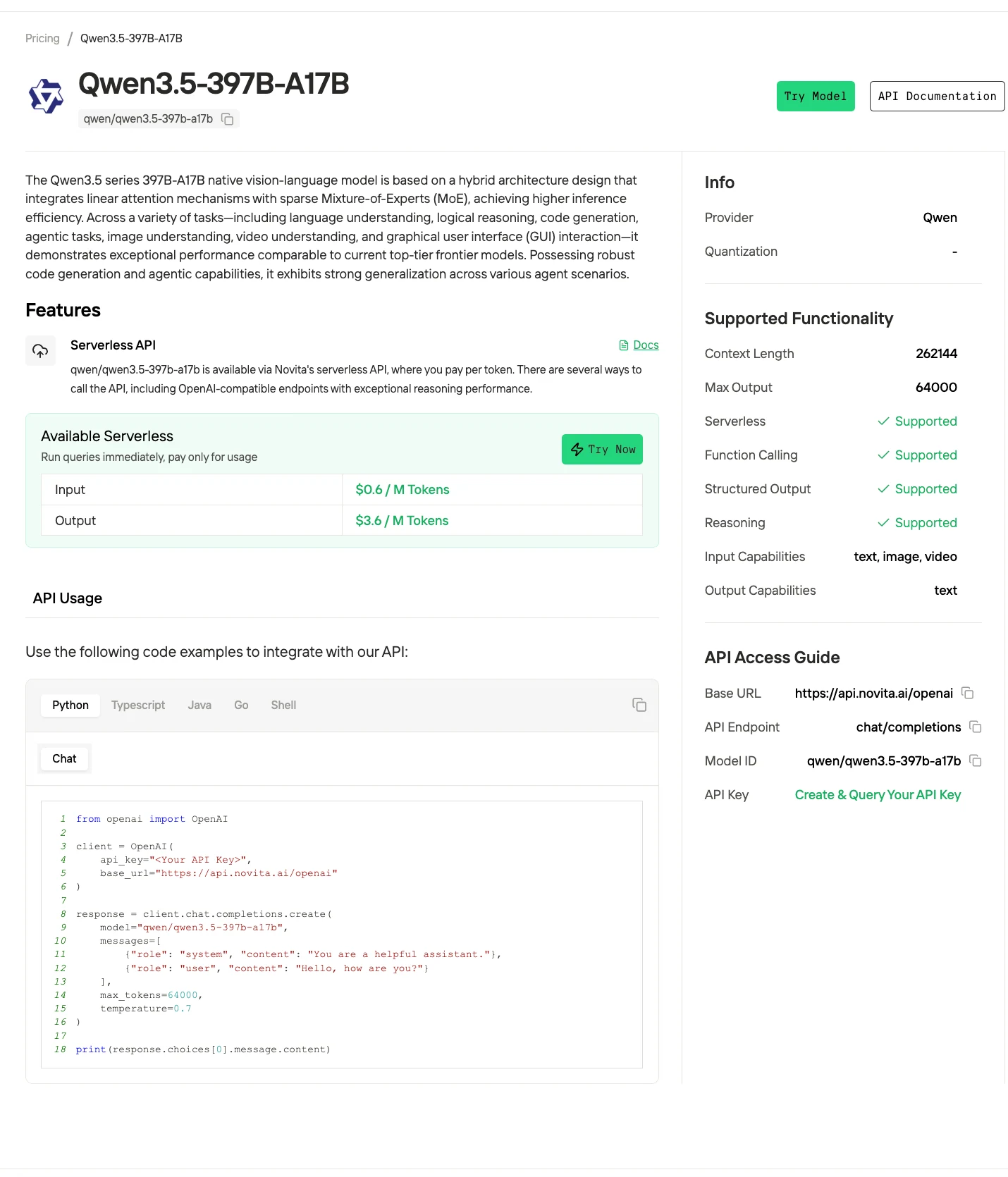
الخطوة 4: احصل على مفتاح API الخاص بك
للمصادقة مع API، سنزودك بمفتاح API جديد. عند الدخول إلى صفحة “الإعدادات”، يمكنك نسخ مفتاح API كما هو موضح في الصورة.

الخطوة 5: تثبيت API
ثبت API باستخدام مدير الحزم الخاص بلغة البرمجة الخاصة بك. يمكنك إدارة مفاتيح API الخاصة بك من صفحة إعدادات Novita AI.
بعد التثبيت، استورد المكتبات اللازمة إلى بيئة التطوير الخاصة بك. قم بتهيئة API بمفتاح API الخاص بك لبدء التفاعل مع Novita AI LLM. هذا مثال على استخدام API لإكمال المحادثات لمستخدمي بايثون.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3.5-397b-a17b",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=64000,
temperature=0.7
)
print(response.choices[0].message.content)
ميزات API
| الميزة | التوفر |
|---|---|
| التوافق مع OpenAI | ✅ دعم كامل |
| الاستجابات المتدفقة | ✅ مدعوم |
| استدعاء الوظائف | ✅ مدعوم |
| نافذة السياق | 262,144 رمز |
| المدخلات متعددة الوسائط | ✅ نصوص + صور |
| SLA/وقت التشغيل | بنية تحتية على مستوى المؤسسات |
أسعار Novita AI لـ Qwen3.5-397B-A17B من بين الأكثر تنافسية في السوق. يعني API المتوافق مع OpenAI أنه يمكنك دمجه في التطبيقات الحالية عن طريق تغيير عنوان URL الأساسي ومفتاح API فقط — لا حاجة لإعادة هيكلة الكود.
التكامل مع أدوات التطوير
اربط Qwen 3 بسلاسة بتطبيقاتك أو سير عملك أو روبوتات المحادثة الخاصة بك باستخدام REST API الموحد لـ Novita AI — لا حاجة لإدارة أوزان النموذج أو البنية التحتية. تقدم Novita AI حزم تطوير برامج (SDKs) متعددة اللغات (بايثون، Node.js، cURL، والمزيد) وضوابط معلمات متقدمة للمستخدمين المتقدمين.
تكامل مع Claude Code
يستخدم Claude Code متغيرات البيئة لتوجيه الطلبات إلى نقاط نهاية النماذج المخصصة. اضبط هذه المتغيرات الأربعة قبل بدء تشغيل Claude Code:
لنظام macOS/Linux:
# Set the Anthropic SDK compatible API endpoint provided by Novita.
export ANTHROPIC_BASE_URL="https://api.novita.ai/anthropic"
export ANTHROPIC_AUTH_TOKEN="<Novita API Key>"
# Set the model provided by Novita.
export ANTHROPIC_MODEL="qwen/qwen3.5-397b-a17b"
export ANTHROPIC_SMALL_FAST_MODEL="qwen/qwen3.5-397b-a17b"
لنظام Windows (PowerShell):
$env:ANTHROPIC_BASE_URL = "https://api.novita.ai/anthropic"
$env:ANTHROPIC_AUTH_TOKEN = "Novita API Key"
$env:ANTHROPIC_MODEL = "qwen/qwen3.5-397b-a17b"
$env:ANTHROPIC_SMALL_FAST_MODEL = "qwen/qwen3.5-397b-a17b"
تكامل مع بيئة التطوير Trae IDE
- افتح Trae وقم بتبديل الشريط الجانبي للذكاء الاصطناعي
- انتقل إلى إدارة الذكاء الاصطناعي → النماذج
- انقر على إضافة نموذج مخصص
- اختر Novita AI كمزود
- أدخل مفتاح API الخاص بك واختر qwen/qwen3.5-397b-a17b
- احفظ التكوين وابدأ البرمجة
تكامل مع OpenCode CLI
# Launch OpenCode
opencode
# Connect to Novita AI
/connect
# Select Novita AI as provider, paste API key
# Choose qwen/qwen3.5-397b-a17b from model list
الطريقة 3: النشر المحلي (تحكم كامل)
الأفضل لـ: متطلبات خصوصية البيانات، الاستدلال بدون اتصال بالإنترنت، خطوط أنابيب استدلال مخصصة، بيئات بحثية، أو السيناريوهات التي تحتاج فيها إلى تحكم كامل في تنفيذ النموذج.
وقت الإعداد: 1-2 ساعة
يمنحك النشر المحلي تحكماً كاملاً ولكنه يتطلب موارد أجهزة كبيرة. تشغل أوزان النموذج الكاملة مساحة قرص تبلغ حوالي 807 جيجابايت عند الدقة الكاملة.
متطلبات الأجهزة
| مستوى الدقة | ذاكرة الوصول العشوائي للفيديو/الذاكرة المطلوبة | الأجهزة الموصى بها |
|---|---|---|
| الكمية 8 بت | حوالي 420 جيجابايت | 5× H100 80GB أو ما يعادلها |
| الكمية 4 بت | حوالي 200 جيجابايت | M3 Ultra Mac (ذاكرة موحدة 256 جيجابايت) أو 1×24GB GPU + 256 جيجابايت ذاكرة نظام |
وفقاً لدليل النشر الخاص بـ Unsloth، يحقق الإنامج المُكمم ب 4 بت أكثر من 25 رمز في الثانية على نظام يحتوي على GPU سعة 24 جيجابايت وذاكرة نظام سعة 256 جيجابايت باستخدام تقنيات إلغاء تحميل MoE. يجعل الكمية 4 بت الخيار الأكثر عملية لنشر المستهلكين الراقي أو الشركات الصغيرة.
تأجير GPU سحابي للنشر المحلي
إذا كنت تفتقر إلى الأجهزة ولكنك لا تزال تريد النشر المستضاف ذاتياً، فإن مثيلات GPU السحابية تقدم حلاً وسطاً. بناءً على أسعار مثيلات GPU من Novita AI:
| التكوين | التكلفة بالساعة (عند الطلب) | التكلفة بالساعة (Spot) | حالة الاستخدام |
|---|---|---|---|
| 5× H100 80GB | 12.95 دولار/ساعة | 6.5 دولار/ساعة | كمية 8 بت، على مستوى الإنتاج |
| 1× RTX 4090 24GB | 0.73 دولار/ساعة | 0.37 دولار/ساعة | كمية 4 بت، فعال من حيث التكلفة |
وضع Spot من Novita AI هو نظام تأجير GPU مُحسّن من حيث التكلفة يستخدم سعة GPU الخاملة أو غير المستخدمة للمنصة. على عكس المثيلات عند الطلب، التي تحجز أجهزة مخصصة للاستخدام المستقر والمستمر، فإن مثيلات Spot قابلة للقطع — قد يتم إيقاف مهمتك أو إنهاؤها إذا استعاد النظام الـ GPU. وبما أن وضع Spot يعيد تخصيص موارد GPU التي كانت ستكون غير مستخدمة، فهو عادة ما يكون أرخص بنسبة 40-60% من أسعار الطلب عند الطلب.
جرّب GPU الفعال من حيث التكلفة الآن!
جدول مقارنة الطرق
| الطريقة | وقت الإعداد | التكلفة | الأفضل لـ |
|---|---|---|---|
| محادثة الويب (ملعب Novita AI LLM) | <1 دقيقة | مجانية (مع حدود معدل الاستخدام) | الاختبار السريع، العروض التوضيحية، التجارب |
| API عبر Novita AI | 5 دقائق | 0.60/3.60 دولار لكل 1M رمز | تطبيقات الإنتاج، الاستدلال القابل للتطوير، التكاملات المخصصة |
| النشر المحلي (INT4) | 1-2 ساعة | تكلفة الأجهزة ونظام ذاكرة 256 جيجابايت | خصوصية البيانات، الاستخدام بدون اتصال، تحكم كامل |
| تأجير GPU سحابي (INT4) | 30 دقيقة | 0.37 دولار/ساعة | استدلال عالي الحجم |
يوفر Qwen3.5-397B-A17B طرق وصول مرنة لسيناريوهات النشر المختلفة. للاختبار الفوري، لا يتطلب ملعب Novita AI LLM أي إعداد ويوفر وصولاً فورياً إلى وضعي الاستدلال والسريع. للتطبيقات الإنتاجية التي تتطلب وصولاً برمجياً، يقدم API الخاص بـ Novita AI أفضل توازن بين التكلفة والأداء بسعر 0.60/3.60 دولار لكل 1M رمز إدخال/إخراج مع نقاط نهاية متوافقة مع OpenAI تندمج بسلاسة في قواعد الكود الحالية.
يبقى النشر المحلي خياراً قابلاً للتطبيق للفرق ذات متطلبات الخصوصية المحددة أو احتياجات الاستدلال ذات الحجم الكبير جداً. يمكن تشغيل الإصدار المُكمم بـ INT4 على أجهزة المستهلك الراقية ذات ذاكرة RAM سعة 256 جيجابايت، تحقيق أكثر من 25 رمز في الثانية. ومع ذلك، بالنسبة لمعظم المطورين والشركات الصغيرة والمتوسطة، يلغي الوصول المُدار عبر API تعقيد البنية التحتية مع تقديم موثوقية على مستوى المؤسسات.
الأسئلة الشائعة
كم تكلفة الوصول إلى Qwen3.5-397B-A17B عبر API؟ تفرض Novita AI رسوماً قدرها 0.60 دولار لكل 1M رمز إدخال و 3.60 دولار لكل 1M رمز إخراج لـ Qwen3.5-397B-A17B — من بين الأسعار الأكثر تنافسية المتاحة.
هل يمكنني تشغيل Qwen3.5-397B-A17B على أجهزة المستهلك؟ نعم، مع الكمية INT4، يمكن تشغيل Qwen3.5-397B-A17B على أنظمة ذات ذاكرة RAM سعة 256 جيجابايت (مثل M3 Ultra Mac) بسرعة تزيد عن 25 رمز/ثانية، مع الحاجة إلى مساحة قرص تبلغ حوالي 214 جيجابايت.
هل يدعم Qwen3.5-397B-A17B استدعاء الوظائف؟ نعم، يدعم Qwen3.5-397B-A17B استدعاء الوظائف عند الوصول إليه عبر مزودي API مثل Novita AI باستخدام نقاط نهاية متوافقة مع OpenAI.
Novita AI هي منصة سحابية للذكاء الاصطناعي والوكلاء تساعد المطورين والشركات الناشئة على بناء ونشر وتوسيع نطاق النماذج والتطبيقات الوكيلة بأداء عالٍ وموثوقية وكفاءة من حيث التكلفة.
قراءات موصى بها



