

Les développeurs qui explorent des modèles de langage open-weight puissants se posent souvent la même question : comment puis-je réellement commencer à utiliser ce modèle ? Qwen3.5-397B-A17B propose trois voies d’accès distinctes : chat web instantané pour les tests, API gérées pour les applications en production, et déploiement auto-hébergé pour un contrôle total. Chaque méthode s’adapte à des scénarios différents — du prototypage rapide à l’inférence à l’échelle entreprise.
Ce guide passe en revue toutes les méthodes d’accès avec des instructions de configuration, des données de tarification réelles et les exigences matérielles. Vous apprendrez quelle voie correspond à votre cas d’usage et comment démarrer en quelques minutes.
Qu’est-ce que Qwen3.5-397B-A17B ?
Qwen3.5-397B-A17B est le modèle de langage phare open-weight de type Mixture-of-Experts (MoE) d’Alibaba Cloud, avec 403 milliards de paramètres totaux et 17 milliards de paramètres actifs par jeton. Le modèle prend en charge un contexte de 262 144 jetons (fenêtre de contexte de 256k) et supporte nativement les entrées multimodales incluant texte et images. Selon les benchmarks d’Artificial Analysis, Qwen3.5-397B-A17B atteint un score ELO GDPval-AA de 1 221, soit une augmentation de 361 points par rapport au précédent modèle Qwen3 235B (860). Le modèle démontre une force particulière dans les tâches de codage, de raisonnement et d’agent, tout en maintenant une efficacité coût grâce à son architecture MoE.
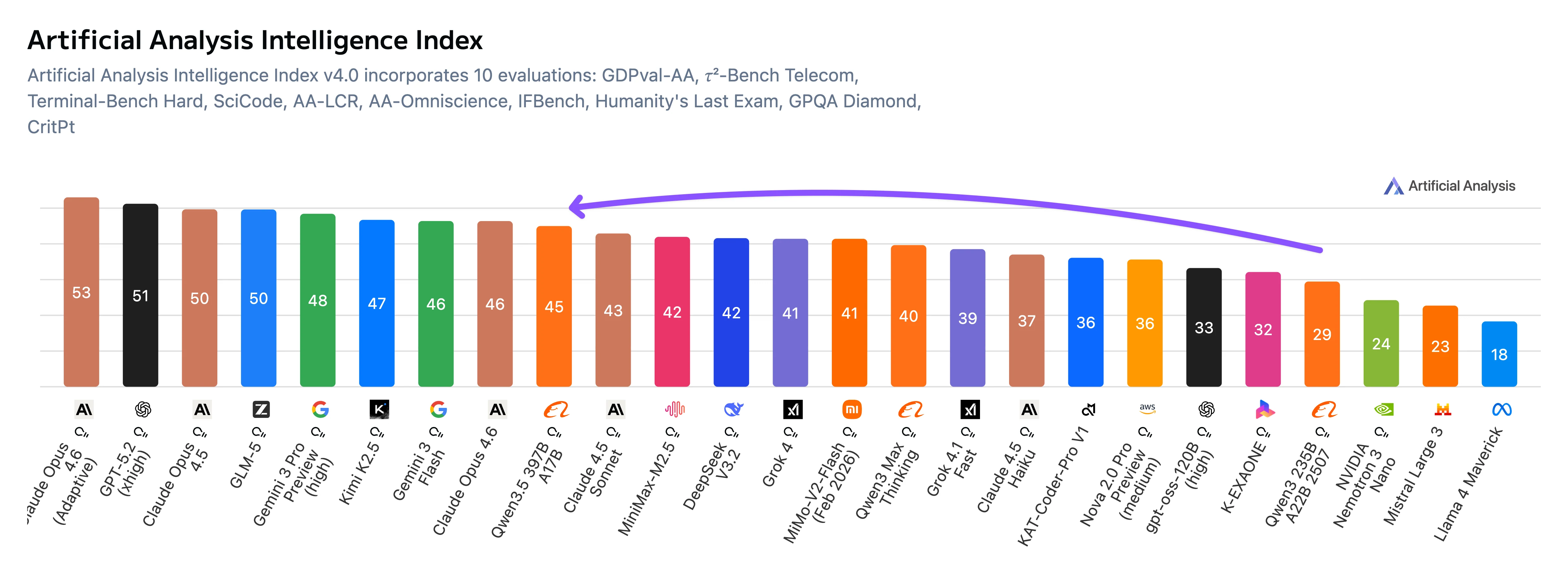
Depuis Artificial Analysis
Aperçu des benchmarks de Qwen3.5-397B-A17B
| Catégorie | Benchmark | Score | Modèle leader |
|---|---|---|---|
| Suivi des instructions | IFBench | 76.5 | Qwen3.5 |
| Tâches complexes | MultiChallenge | 67.6 | Qwen3.5 |
| Agent / Navigation web | BrowseComp | 78.6 | Qwen3.5 |
| Raisonnement scientifique | GPQA Diamond | 88.4 | Qwen3.5 (modèles open source) |
| Connaissances | MMLU-Pro | 87.8 | Gemini |
| Connaissances | MMLU-Redux | 94.9 | Gemini |
| Connaissances | C-Eval | 93.0 | Concurrentiel |
| Codage | LiveCodeBench v6 | 83.6 | Gemini / GPT |
| Multimodal | MMMU | 85.0 | Concurrentiel |
| Multimodal | MathVision | 88.6 | Concurrentiel |
| Multimodal | OCRBench | 93.1 | Concurrentiel |
| Multimodal | Video-MME | 87.5 | Concurrentiel |
Qwen3.5-397B obtient ses meilleurs résultats sur les benchmarks de suivi des instructions et orientés agent, notamment IFBench, MultiChallenge et BrowseComp, où il devance les modèles concurrents. Il atteint également l’état de l’art parmi les modèles open source sur GPQA Diamond, ce qui indique une forte capacité de raisonnement scientifique.
Sur des benchmarks de connaissances plus larges tels que MMLU-Pro et MMLU-Redux, les performances sont élevées mais généralement légèrement inférieures à celles des modèles propriétaires leaders. Les benchmarks de codage affichent des résultats concurrentiels sans pour autant devancer le domaine.
Dans l’ensemble, le profil de benchmark suggère que Qwen3.5 est optimisé pour les instructions complexes, l’utilisation d’outils et les workflows d’agent, plutôt que pour maximiser uniquement les benchmarks académiques traditionnels comme le codage ou la mémorisation de connaissances.
Méthode 1 : Accès par chat web (le plus rapide)
Idéal pour : Tests rapides, expérimentation, démos et cas d’usage non production où vous avez besoin d’un accès immédiat sans clés API ni infrastructure.
Temps de configuration : moins d’1 minute
L’interface de chat officielle de Qwen offre un accès instantané à Qwen3.5-397B-A17B via votre navigateur :
- Accédez à Novita AI
- Sélectionnez Qwen3.5-397B-A17B dans le menu déroulant des modèles
- Choisissez entre le mode « Réflexion » pour les tâches de raisonnement approfondi
- Commencez à discuter immédiatement — aucune création de compte ni clé API requise
Limites
- Aucun accès programmatique — interface web uniquement, pas d’intégration API
- Des limites de débit s’appliquent — conçu pour une utilisation interactive, pas pour le traitement par lots
- Pas de fine-tuning — vous utilisez le modèle de base tel quel
- Persistance de contexte limitée — l’historique des conversations est géré par l’interface
Méthode 2 : Accès via API Novita AI (Production)
Idéal pour : Applications en production, intégrations personnalisées, accès programmatique, inférence scalable et applications nécessitant un format d’API compatible OpenAI.
Temps de configuration : 5 minutes
Novita AI propose un accès API géré à Qwen3.5-397B-A17B avec des tarifs compétitifs parmi les principaux fournisseurs : 0,60 $ par million de jetons d’entrée et 3,60 $ par million de jetons de sortie. Le service propose des endpoints compatibles OpenAI, ce qui rend l’intégration très simple pour les développeurs déjà familiers avec le SDK OpenAI.

Depuis HuggingFace
Configuration étape par étape
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Bibliothèque de modèles.

Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.

Étape 3 : Démarrez votre essai gratuit
Commencez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Étape 4 : Récupérez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. En accédant à la page « Paramètres », vous pouvez copier la clé API comme indiqué sur l’image.

Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation. Vous pouvez gérer vos clés API depuis la page Paramètres de Novita AI.
Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec les LLM de Novita AI. Voici un exemple d’utilisation de l’API de complétion de chat pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3.5-397b-a17b",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=64000,
temperature=0.7
)
print(response.choices[0].message.content)
Fonctionnalités de l’API
| Fonctionnalité | Disponibilité |
|---|---|
| Compatibilité OpenAI | ✅ Prise en charge complète |
| Réponses en streaming | ✅ Prise en charge |
| Appel de fonctions | ✅ Prise en charge |
| Fenêtre de contexte | 262 144 jetons |
| Entrée multimodale | ✅ Texte + Images |
| SLA/Disponibilité | Infrastructure de niveau entreprise |
Les tarifs de Novita AI pour Qwen3.5-397B-A17B sont parmi les plus compétitifs du marché. L’API compatible OpenAI signifie que vous pouvez l’intégrer dans des applications existantes en modifiant simplement l’URL de base et la clé API — aucune refactorisation de code n’est requise.
Intégration avec les outils de développement
Connectez Qwen 3 de manière transparente à vos applications, workflows ou chatbots avec l’API REST unifiée de Novita AI — pas besoin de gérer les poids du modèle ou l’infrastructure. Novita AI propose des SDK multilingues (Python, Node.js, cURL et plus encore) et des contrôles de paramètres avancés pour les utilisateurs expérimentés.
Intégration avec Claude Code
Claude Code utilise des variables d’environnement pour acheminer les requêtes vers des endpoints de modèle personnalisés. Définissez ces quatre variables avant de démarrer Claude Code :
Pour macOS/Linux :
# Définir l'endpoint d'API compatible Anthropic fourni par Novita.
export ANTHROPIC_BASE_URL="https://api.novita.ai/anthropic"
export ANTHROPIC_AUTH_TOKEN="<Novita API Key>"
# Définir le modèle fourni par Novita.
export ANTHROPIC_MODEL="qwen/qwen3.5-397b-a17b"
export ANTHROPIC_SMALL_FAST_MODEL="qwen/qwen3.5-397b-a17b"
Pour Windows (PowerShell) :
$env:ANTHROPIC_BASE_URL = "https://api.novita.ai/anthropic"
$env:ANTHROPIC_AUTH_TOKEN = "Novita API Key"
$env:ANTHROPIC_MODEL = "qwen/qwen3.5-397b-a17b"
$env:ANTHROPIC_SMALL_FAST_MODEL = "qwen/qwen3.5-397b-a17b"
Intégration avec l’IDE Trae
- Ouvrez Trae et activez la barre latérale IA
- Accédez à Gestion IA → Modèles
- Cliquez sur Ajouter un modèle personnalisé
- Sélectionnez Novita AI comme fournisseur
- Entrez votre clé API et sélectionnez qwen/qwen3.5-397b-a17b
- Enregistrez la configuration et commencez à coder
Intégration avec l’interface en ligne de commande OpenCode
# Lancer OpenCode
opencode
# Se connecter à Novita AI
/connect
# Sélectionner Novita AI comme fournisseur, coller la clé API
# Choisir qwen/qwen3.5-397b-a17b dans la liste des modèles
Méthode 3 : Déploiement local (contrôle total)
Idéal pour : Exigences de confidentialité des données, inférence hors ligne, pipelines d’inférence personnalisés, environnements de recherche ou scénarios où vous avez besoin d’un contrôle total sur l’exécution du modèle.
Temps de configuration : 1 à 2 heures
Le déploiement local vous donne un contrôle total mais nécessite des ressources matérielles importantes. Les poids complets du modèle occupent environ 807 Go d’espace disque en précision complète.
Exigences matérielles
| Niveau de précision | VRAM/RAM requise | Matériel recommandé |
|---|---|---|
| Quantification 8 bits | Environ 420 Go | 5× H100 80Go ou équivalent |
| Quantification 4 bits | Environ 200 Go | Mac M3 Ultra (mémoire unifiée de 256 Go) ou 1× GPU 24 Go + 256 Go de RAM système |
Selon le guide de déploiement d’Unsloth, la version quantifiée en 4 bits atteint plus de 25 jetons par seconde sur un système avec un GPU de 24 Go et 256 Go de RAM système en utilisant des techniques de déchargement MoE. Cela fait de la quantification 4 bits l’option la plus pratique pour les déploiements grand public ou pour les petites entreprises.
Location de GPU cloud pour le déploiement local
Si vous n’avez pas le matériel mais que vous souhaitez tout de même un déploiement auto-hébergé, les instances de GPU cloud offrent un compromis. Sur la base des tarifs d’instance GPU de Novita AI :
| Configuration | Coût horaire (à la demande) | Coût horaire (Spot) | Cas d’usage |
|---|---|---|---|
| 5× H100 80Go | 12,95 $/h | 6,5 $/h | Quantification 8 bits, niveau production |
| 1× RTX 4090 24Go | 0,73 $/h | 0,37 $/h | Quantification 4 bits, rentable |
Le mode Spot de Novita AI est un système de location de GPU optimisé pour les coûts qui exploite la capacité GPU idle ou inutilisée de la plateforme. Contrairement aux instances à la demande, qui réservent du matériel dédié pour une utilisation continue et stable, les instances Spot sont interruptibles — votre travail peut être mis en pause ou terminé si le GPU est récupéré par le système. Comme le mode Spot réalloue des ressources GPU autrement inutilisées, il est généralement 40 à 60 % moins cher que les tarifs à la demande.
Essayer des GPU rentables maintenant !
Tableau comparatif des méthodes
| Méthode | Temps de configuration | Coût | Idéal pour |
|---|---|---|---|
| Chat web (Novita AI LLM Playground) | <1 minute | Gratuit (avec limites de débit) | Tests rapides, démos, expérimentation |
| API via Novita AI | 5 minutes | 0,60 $/3,60 $ par million de jetons | Applications en production, inférence scalable, intégrations personnalisées |
| Déploiement local (INT4) | 1 à 2 heures | Coût du matériel et système avec 256 Go de RAM | Confidentialité des données, utilisation hors ligne, contrôle total |
| Location de GPU cloud (INT4) | 30 minutes | 0,37 $/h | Inférence à haut volume |
Qwen3.5-397B-A17B propose des voies d’accès flexibles pour différents scénarios de déploiement. Pour des tests immédiats, le Novita AI LLM Playground ne nécessite aucune configuration et offre un accès instantané aux modes raisonnement et rapide. Pour les applications en production nécessitant un accès programmatique, l’API de Novita AI offre le meilleur rapport coût/performance à 0,60 $/3,60 $ par million de jetons d’entrée/sortie, avec des endpoints compatibles OpenAI qui s’intègrent parfaitement dans les bases de code existantes.
Le déploiement local reste viable pour les équipes ayant des exigences spécifiques en matière de confidentialité ou des besoins d’inférence à très haut volume. La version quantifiée en INT4 peut fonctionner sur du matériel grand public haut de gamme avec 256 Go de RAM, atteignant plus de 25 jetons par seconde. Cependant, pour la plupart des développeurs et des petites et moyennes entreprises, l’accès via API gérée élimine la complexité de l’infrastructure tout en offrant une fiabilité de niveau entreprise.
Questions fréquemment posées
Combien coûte Qwen3.5-397B-A17B via API ?
Novita AI facture 0,60 $ par million de jetons d’entrée et 3,60 $ par million de jetons de sortie pour Qwen3.5-397B-A17B — parmi les tarifs les plus compétitifs du marché.
Puis-je exécuter Qwen3.5-397B-A17B sur du matériel grand public ?
Oui, avec la quantification INT4, Qwen3.5-397B-A17B fonctionne sur des systèmes avec 256 Go de RAM (comme le Mac M3 Ultra) à plus de 25 jetons/s, nécessitant environ 214 Go d’espace disque.
Qwen3.5-397B-A17B prend-il en charge l’appel de fonctions ?
Oui, Qwen3.5-397B-A17B prend en charge l’appel de fonctions lorsqu’il est accessible via des fournisseurs d’API comme Novita AI en utilisant des endpoints compatibles OpenAI.
Novita AI est une plateforme cloud IA et agent qui aide les développeurs et les startups à créer, déployer et mettre à l’échelle des modèles et des applications agentiques avec des performances élevées, une fiabilité et une efficacité coût.



