

正在探索强大开源权重语言模型的开发者们面临一个常见问题:我到底该如何开始使用这个模型?Qwen3.5-397B-A17B 提供三种不同的访问路径:用于测试的即时网页聊天、用于生产环境的托管 API,以及用于完全控制的自托管部署。每种方法适用于不同的场景——从快速原型开发到企业级推理。
本指南将介绍所有访问方法,并提供设置说明、实际定价数据和硬件要求。你将了解哪种路径适合你的用例,以及如何快速上手。
什么是 Qwen3.5-397B-A17B?
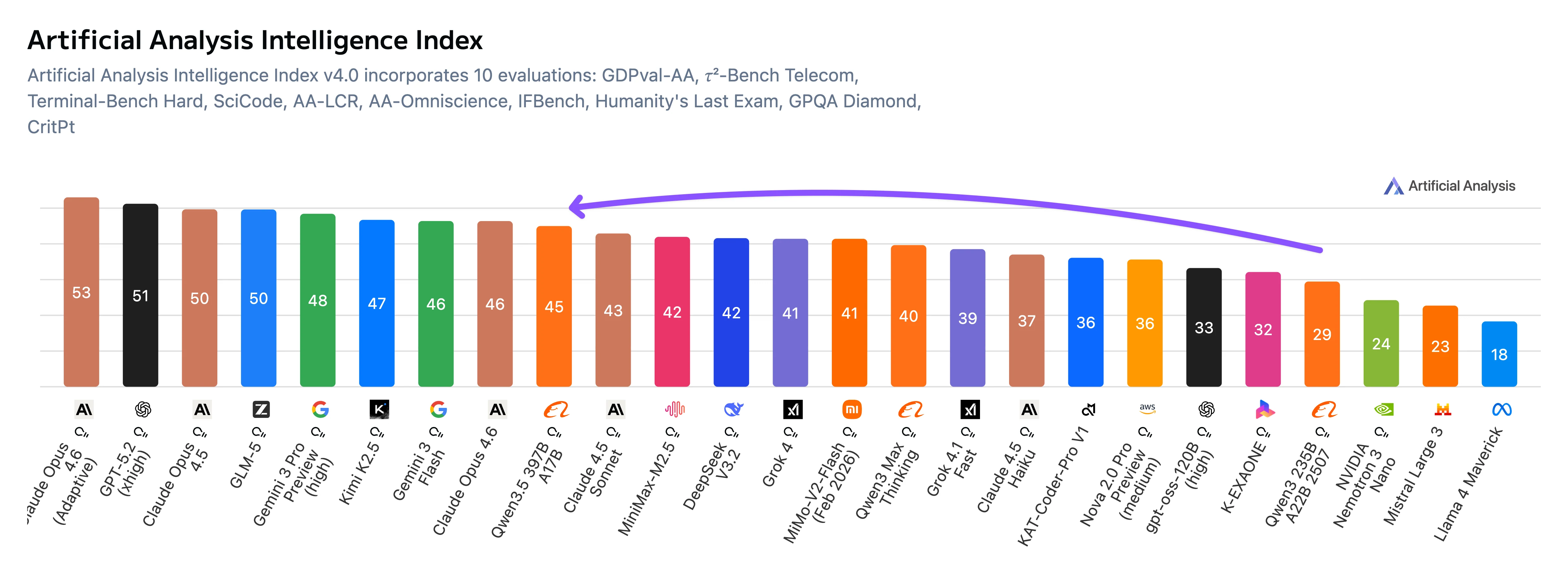
Qwen3.5-397B-A17B 是阿里云推出的旗舰级开源权重混合专家(MoE)语言模型,拥有 4030 亿总参数,每个 token 激活 170 亿参数。该模型支持 262,144 个 token 的上下文(256k 上下文窗口),并且原生支持文本和图像等多模态输入。根据 Artificial Analysis 基准测试,Qwen3.5-397B-A17B 在 GDPval-AA 排行榜上得分 1,221,相比之前的 Qwen3 235B 模型(860 分)提升了 361 分。该模型在编程、推理和 Agent 任务上表现尤为出色,同时通过 MoE 架构保持了成本效率。
Qwen3.5-397B-A17B 基准测试概览
| 类别 | 基准测试 | 得分 | 领先模型 |
|---|---|---|---|
| 指令遵循 | IFBench | 76.5 | Qwen3.5 |
| 复杂任务 | MultiChallenge | 67.6 | Qwen3.5 |
| Agent / 浏览 | BrowseComp | 78.6 | Qwen3.5 |
| 科学推理 | GPQA Diamond | 88.4 | Qwen3.5(开源模型) |
| 知识 | MMLU-Pro | 87.8 | Gemini |
| 知识 | MMLU-Redux | 94.9 | Gemini |
| 知识 | C-Eval | 93.0 | 有竞争力 |
| 编程 | LiveCodeBench v6 | 83.6 | Gemini / GPT |
| 多模态 | MMMU | 85.0 | 有竞争力 |
| 多模态 | MathVision | 88.6 | 有竞争力 |
| 多模态 | OCRBench | 93.1 | 有竞争力 |
| 多模态 | Video-MME | 87.5 | 有竞争力 |
Qwen3.5-397B 在指令遵循和面向 Agent 的基准测试中取得了最强成绩,包括 IFBench、MultiChallenge 和 BrowseComp,领先于其他竞争模型。同时,它在 GPQA Diamond 上达到了开源模型中的最佳水平,显示出强大的科学推理能力。
在更广泛的知识基准测试(如 MMLU-Pro 和 MMLU-Redux)上,虽然性能较高,但通常略落后于领先的专有模型。编程基准测试显示出有竞争力的结果,但未达到领先地位。
总体而言,基准测试结果表明 Qwen3.5 针对复杂指令、工具使用和 Agent 工作流进行了优化,而不是纯粹追求传统学术基准测试(如编程或知识回忆)的最大化。
方法一:网页聊天访问(最快)
适用场景: 快速测试、实验、演示以及无需 API 密钥或基础设施即可立即访问的非生产用例。
设置时间:少于 1 分钟
官方 Qwen 聊天界面通过浏览器提供对 Qwen3.5-397B-A17B 的即时访问:
- 导航到 Novita AI
- 从模型下拉菜单中选择 Qwen3.5-397B-A17B
- 针对深度推理任务选择 “思考” 模式
- 立即开始聊天——无需创建账户或 API 密钥
局限性
- 无程序化访问——仅限网页 UI,无 API 集成
- 存在速率限制——专为交互式使用设计,不适用于批处理
- 无法微调——你使用的是基础模型本身
- 有限的上下文持久性——对话历史由界面管理
方法二:通过 Novita AI 的 API 访问(生产环境)
适用场景: 生产应用程序、自定义集成、程序化访问、可扩展推理,以及需要 OpenAI 兼容 API 格式的应用程序。
设置时间:5 分钟
Novita AI 提供对 Qwen3.5-397B-A17B 的托管 API 访问,定价在主要提供商中具有竞争力:每 100 万个输入 token 0.60 美元,每 100 万个输出 token 3.60 美元。该服务提供与 OpenAI 兼容的端点,使已熟悉 OpenAI SDK 的开发人员能够轻松集成。

来自 HuggingFace
分步设置
步骤 1:登录并访问模型库
登录你的账户,点击 模型库 按钮。

步骤 2:选择模型
浏览可用选项,选择适合你需求的模型。

步骤 3:开始免费试用
开始免费试用,探索所选模型的功能。
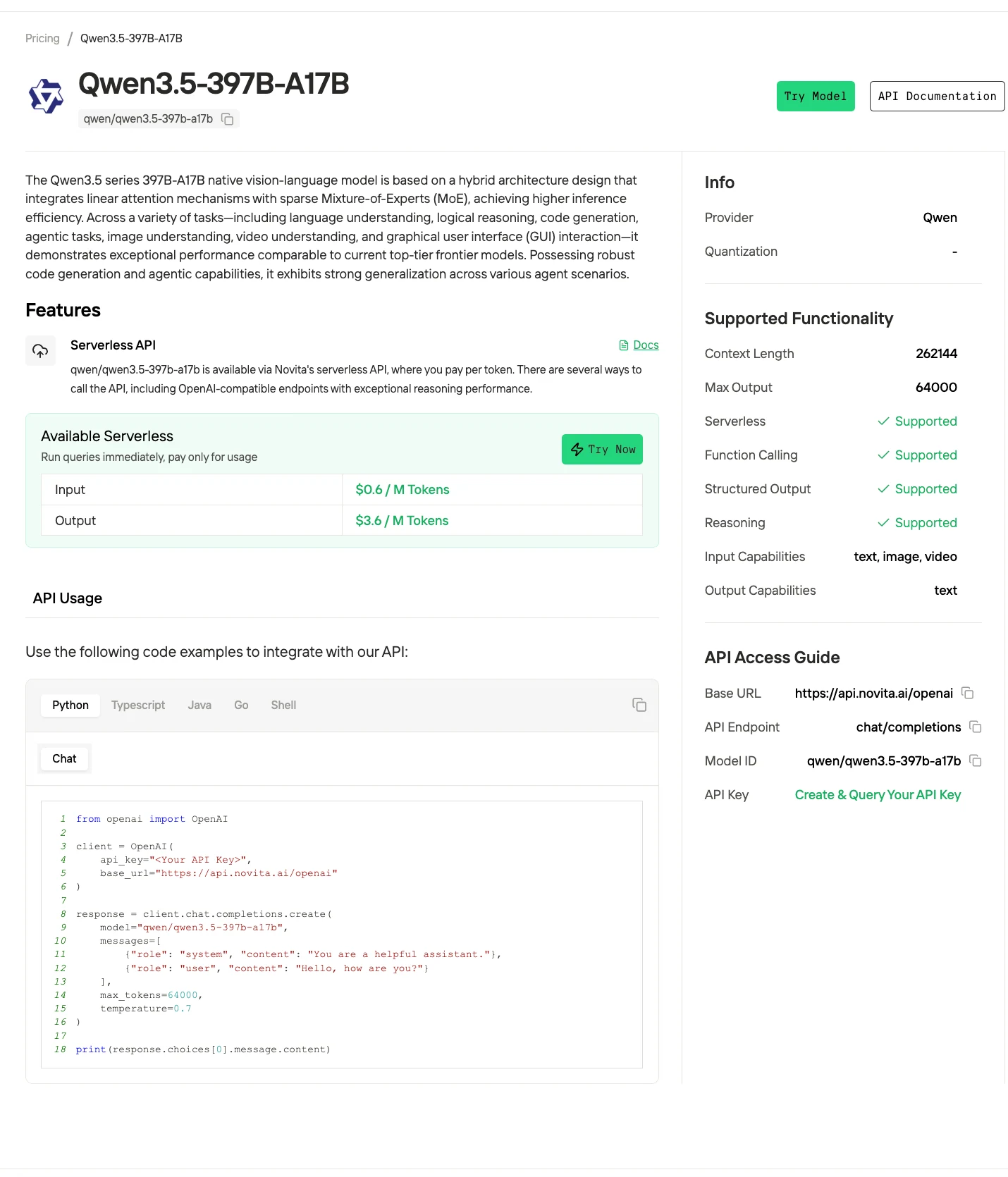
步骤 4:获取 API 密钥
为了通过 API 进行身份验证,我们将为你提供一个新的 API 密钥。进入“设置”页面,你可以按照图像所示复制 API 密钥。

步骤 5:安装 API
使用你的编程语言特定的包管理工具安装 API。你可以从 Novita AI 设置页面 管理 API 密钥。
安装后,将必要的库导入到你的开发环境中。使用你的 API 密钥初始化 API,开始与 Novita AI LLM 交互。以下是为 Python 用户提供的聊天补全 API 示例。
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3.5-397b-a17b",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=64000,
temperature=0.7
)
print(response.choices[0].message.content)
API 功能
| 功能 | 可用性 |
|---|---|
| OpenAI 兼容性 | ✅ 完全支持 |
| 流式响应 | ✅ 支持 |
| 函数调用 | ✅ 支持 |
| 上下文窗口 | 262,144 token |
| 多模态输入 | ✅ 文本 + 图像 |
| SLA/正常运行时间 | 企业级基础设施 |
Novita AI 针对 Qwen3.5-397B-A17B 的定价在市场上具有极强的竞争力。OpenAI 兼容的 API 意味着你只需更改基础 URL 和 API 密钥即可将其集成到现有应用程序中——无需重构代码。
与开发工具集成
通过 Novita AI 的统一 REST API,无需管理模型权重或基础设施,即可无缝地将 Qwen 3 连接到你的应用程序、工作流或聊天机器人。Novita AI 提供多语言 SDK(Python、Node.js、cURL 等)以及面向高级用户的高级参数控制。
Claude Code 集成
Claude Code 使用环境变量将请求路由到自定义模型端点。在启动 Claude Code 之前设置以下四个变量:
对于 macOS/Linux:
# 设置由 Novita 提供的 Anthropic SDK 兼容 API 端点。
export ANTHROPIC_BASE_URL="https://api.novita.ai/anthropic"
export ANTHROPIC_AUTH_TOKEN="<Novita API Key>"
# 设置由 Novita 提供的模型。
export ANTHROPIC_MODEL="qwen/qwen3.5-397b-a17b"
export ANTHROPIC_SMALL_FAST_MODEL="qwen/qwen3.5-397b-a17b"
对于 Windows (PowerShell):
$env:ANTHROPIC_BASE_URL = "https://api.novita.ai/anthropic"
$env:ANTHROPIC_AUTH_TOKEN = "Novita API Key"
$env:ANTHROPIC_MODEL = "qwen/qwen3.5-397b-a17b"
$env:ANTHROPIC_SMALL_FAST_MODEL = "qwen/qwen3.5-397b-a17b"
Trae IDE 集成
- 打开 Trae 并切换 AI 侧边栏
- 导航到 AI 管理 → 模型
- 点击 添加自定义模型
- 选择 Novita AI 作为提供商
- 输入你的 API 密钥并选择 qwen/qwen3.5-397b-a17b
- 保存配置并开始编程
OpenCode CLI 集成
# 启动 OpenCode
opencode
# 连接到 Novita AI
/connect
# 选择 Novita AI 作为提供商,粘贴 API 密钥
# 从模型列表中选择 qwen/qwen3.5-397b-a17b
方法三:本地部署(完全控制)
适用场景: 数据隐私要求、离线推理、自定义推理管道、研究环境,或需要完全控制模型执行的场景。
设置时间:1-2 小时
本地部署提供了完全控制权,但需要显著的硬件资源。完整模型权重在全精度下占用约 807GB 磁盘空间。
硬件要求
| 精度级别 | 所需 VRAM/RAM | 推荐硬件 |
|---|---|---|
| 8-bit 量化 | 约 420GB | 5× H100 80GB 或同等配置 |
| 4-bit 量化 | 约 200GB | M3 Ultra Mac(256GB 统一内存)或 1×24GB GPU + 256GB 系统内存 |
根据 Unsloth 的部署指南,在配备 24GB GPU 和 256GB 系统内存的系统上,使用 MoE 卸载技术,4-bit 量化版本可实现 每秒 25 个 token 以上 的速度。这使得 4-bit 量化成为高端消费者或小型企业部署中最实用的选择。
用于本地部署的云 GPU 租赁
如果你缺乏硬件但仍希望自行托管部署,云 GPU 实例提供了一种折中方案。根据 Novita AI GPU 实例定价:
| 配置 | 按需每小时成本 | 竞价实例每小时成本 | 用例 |
|---|---|---|---|
| 5× H100 80GB | $12.95/小时 | $6.5/小时 | 8-bit 量化,生产级 |
| 1× RTX 4090 24GB | $0.73/小时 | $0.37/小时 | 4-bit 量化,成本效益高 |
Novita AI 的竞价模式是一种成本优化的 GPU 租赁系统,利用平台空闲或未使用的 GPU 容量。与按需实例(预留专用硬件以获得稳定、连续使用)不同,竞价实例是可中断的——如果 GPU 被系统回收,你的任务可能会被暂停或终止。由于竞价模式重新分配原本未使用的 GPU 资源,其价格通常比按需定价便宜 40-60%。
方法对比表
| 方法 | 设置时间 | 成本 | 适用场景 |
|---|---|---|---|
| 网页聊天 (Novita AI LLM Playground) | <1 分钟 | 免费(有速率限制) | 快速测试、演示、实验 |
| 通过 Novita AI 的 API | 5 分钟 | 每 100 万 token $0.60/$3.60 | 生产应用、可扩展推理、自定义集成 |
| 本地部署 (INT4) | 1-2 小时 | 硬件成本 + 256GB 内存系统 | 数据隐私、离线使用、完全控制 |
| 云 GPU 租赁 (INT4) | 30 分钟 | $0.37/小时 | 高吞吐量推理 |
Qwen3.5-397B-A17B 为不同的部署场景提供了灵活的访问路径。对于即时测试,Novita AI LLM Playground 无需任何设置,即可即时访问推理和快速两种模式。对于需要程序化访问的生产应用,Novita AI 的 API 以每 100 万输入/输出 token $0.60/$3.60 的价格提供了最佳性价比,并且具有 OpenAI 兼容端点,可无缝集成到现有代码库中。
对于具有特定隐私要求或极高吞吐量推理需求的团队,本地部署仍然是可行的选择。INT4 量化版本可以在配备 256GB 内存的高端消费级硬件上运行,实现每秒 25 个 token 以上的速度。然而,对于大多数开发者和中小型企业来说,托管 API 访问消除了基础设施的复杂性,同时提供了企业级的可靠性。
常见问题
通过 API 使用 Qwen3.5-397B-A17B 的费用是多少?
Novita AI 对 Qwen3.5-397B-A17B 收取每 100 万输入 token 0.60 美元、每 100 万输出 token 3.60 美元的费用——这是最具竞争力的费率之一。
我能在消费级硬件上运行 Qwen3.5-397B-A17B 吗?
是的,通过 INT4 量化,Qwen3.5-397B-A17B 可以在配备 256GB 内存(如 M3 Ultra Mac)的系统上以每秒 25+ token 的速度运行,需要约 214GB 磁盘空间。
Qwen3.5-397B-A17B 支持函数调用吗?
是的,当通过像 Novita AI 这样使用 OpenAI 兼容端点的 API 提供商访问时,Qwen3.5-397B-A17B 支持函数调用。
Novita AI 是一个 AI 与 Agent 云平台,帮助开发者和初创公司以高性能、高可靠性和高成本效益的方式构建、部署和扩展模型及 Agent 应用。
推荐阅读



