

- El desafío: construir agentes de IA fiables sigue siendo demasiado difícil
- La solución: la arquitectura de auto-evolución de MiniMax M2.7
- Especificaciones técnicas y rendimiento
- Precios en Novita AI
- ¿Por qué elegir Novita AI para MiniMax M2.7?
- Cómo empezar con MiniMax M2.7 en Novita AI
- Lo que MiniMax M2.7 puede hacer: Demostraciones del mundo real
- Conclusión
MiniMax M2.7 ya está disponible en Novita AI, ofreciendo capacidades de agente de IA de nivel productivo con una eficiencia de costes excepcional. Este modelo de razonamiento auto-evolutivo alcanza un Índice de Inteligencia de 50 (igualando a GLM-5) mientras cuesta 3 veces menos de ejecutar. Con un 97% de fidelidad en el uso de habilidades entre más de 40 herramientas complejas, soporte nativo para Equipos de Agentes y un rendimiento líder en tareas del mundo real (GDPval-AA Elo 1495), M2.7 está diseñado para desarrolladores que necesitan IA agéntica fiable sin arruinarse.
Precios: $0.3/Mt entrada, $1.2/Mt salida (Lectura de caché $0.06/Mt) Ventana de contexto: 204,800 tokens
¡Pruébalo ahora en Novita AI Playground!
El desafío: construir agentes de IA fiables sigue siendo demasiado difícil
La mayoría de los grandes modelos de lenguaje afirman tener “capacidades agénticas”, pero el despliegue real cuenta una historia diferente:
- Fallos en el uso de herramientas: los modelos malinterpretan las firmas de funciones, omiten parámetros requeridos o alucinan herramientas inexistentes
- Colapso de contexto: las sesiones largas de agentes alcanzan límites de tokens o pierden contexto crítico a mitad de la tarea
- Ejecución poco fiable: funciona en demos, falla en producción al manejar más de 40 habilidades simultáneamente
- Explosión de costes: ejecutar modelos de razonamiento de frontera como Claude Opus 4.6 o GPT-5.4 se acumula rápido
Necesitas un modelo que realmente funcione en sistemas de agentes en producción, no solo uno que luzca bien en benchmarks.
La solución: la arquitectura de auto-evolución de MiniMax M2.7
MiniMax M2.7 es el primer modelo de la empresa que participó en su propio desarrollo —literalmente depurando su proceso de entrenamiento, construyendo arneses de evaluación y optimizando su propio andamiaje. Este bucle de auto-evolución produjo un modelo especialmente adecuado para tareas agénticas del mundo real.
¿Qué hace diferente a M2.7?
1. Ingeniería de software lista para producción
M2.7 no solo escribe código: depura sistemas en vivo. Cuando salta una alerta de producción, correlaciona métricas de monitoreo con cronogramas de despliegue, realiza análisis estadístico de trazas, se conecta a bases de datos para verificar hipótesis, localiza archivos de migración de índices faltantes y sabe usar creación de índices no bloqueante para detener la hemorragia antes de enviar la corrección.
2. Soporte nativo para Equipos de Agentes
A diferencia de los modelos que simulan flujos multi-agente mediante indicaciones, M2.7 tiene límites de rol, razonamiento adversarial y diferenciación de comportamiento integrados a nivel del modelo. Puede:
- Anclar de forma estable su identidad de rol en escenarios multi-agente
- Desafiar proactivamente los puntos ciegos lógicos de sus compañeros
- Tomar decisiones autónomas dentro de máquinas de estado complejas
3. 97% de adherencia a habilidades
La mayoría de los modelos se degradan al manejar más de un puñado de herramientas. M2.7 mantiene un 97% de precisión en el seguimiento de habilidades incluso con más de 40 habilidades complejas, cada una superando los 2,000 tokens. Comprende definiciones de funciones largas e intrincadas y las usa correctamente en interacciones prolongadas.
4. Excelencia en el espacio de trabajo profesional
- GDPval-AA Elo: 1495 (el más alto entre modelos de código abierto, superando a MiMo-V2-Pro y Kimi K2.5)
- Edición ofimática de alta fidelidad: revisiones multi-turno en Excel, PowerPoint y Word
- Tareas del mundo real: lee informes anuales, diseña modelos de ingresos, genera PPTs a partir de plantillas —como un analista junior que se autocorrige mediante retroalimentación
5. Inteligencia con inteligencia emocional
M2.7 rompe el estereotipo de “herramienta fría” con alta inteligencia emocional y consistencia de carácter, permitiendo interacciones naturales y humanas más allá de tareas puramente productivas.
¡Pruébalo ahora en Novita AI Playground!
Especificaciones técnicas y rendimiento
Especificaciones técnicas
| Parámetro | Valor |
| Ventana de contexto | 204,800 tokens |
| Salida máxima | 131,072 tokens |
| Cuantización | FP8 |
| Modalidades de entrada | Texto |
| Modalidades de salida | Texto |
| Funciones compatibles | Herramientas, modo JSON, salidas estructuradas, Razonamiento |
| Parámetros de muestreo | temperature, top_p, top_k, repetition_penalty, frequency_penalty, presence_penalty, stop, seed |
Más información sobre MiniMax M2.7!
Resumen de rendimiento en benchmarks
MiniMax M2.7 demuestra un rendimiento líder en tareas agénticas del mundo real, superando o igualando a modelos de frontera en benchmarks clave:
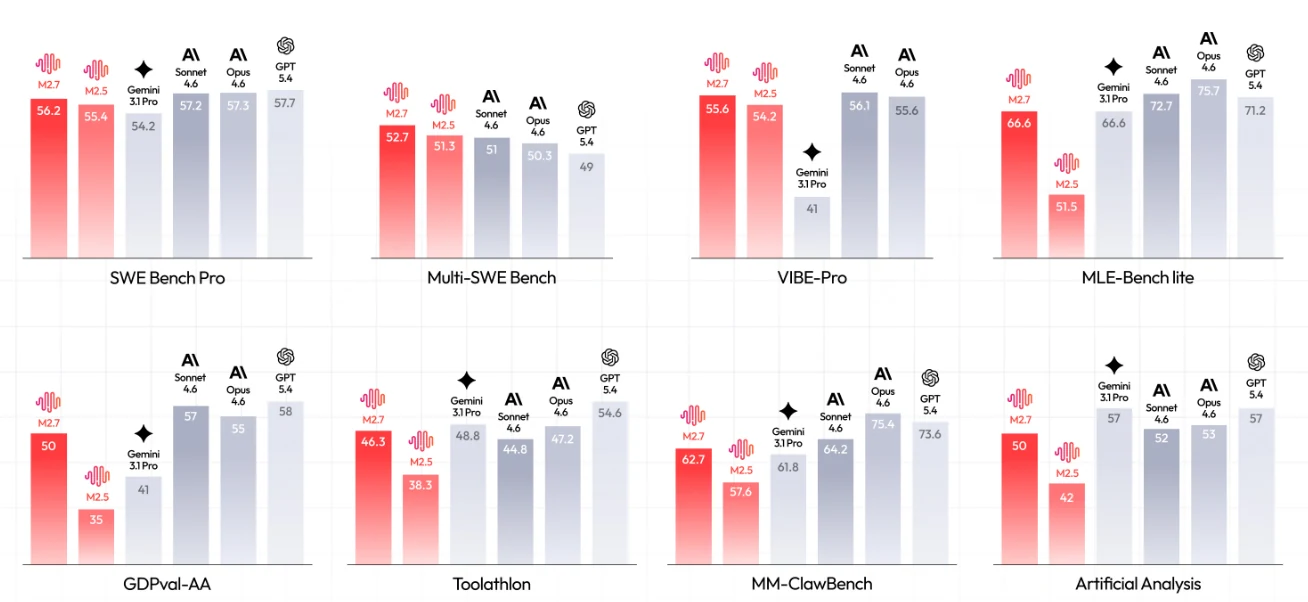
M2.7 (barras rojas) vs. modelos competidores en 8 benchmarks críticos. [Fuente: MiniMax Oficial]
Conclusiones clave:
- Capacidades SWE: 56.2% en SWE Bench Pro, acercándose a modelos de frontera (GPT-5.4 con 57.7%)
- Ventaja multilingüe: 52.7 en Multi-SWE Bench, superando a todos los competidores, incluido GPT-5.4 (49)
- Automatización ML: 66.6% en MLE-Bench lite, empatado con Gemini 3.1 Pro y solo por detrás de Opus 4.6 (75.7%) y GPT-5.4 (71.2%)
- Excelencia agéntica: GDPval-AA Índice de Inteligencia 50, igualando la línea base del benchmark para rendimiento listo para producción
Inteligencia vs. Coste: eficiencia de primera clase
M2.7 destaca no solo por su rendimiento, sino por ofrecer inteligencia de nivel frontera a una fracción del coste:
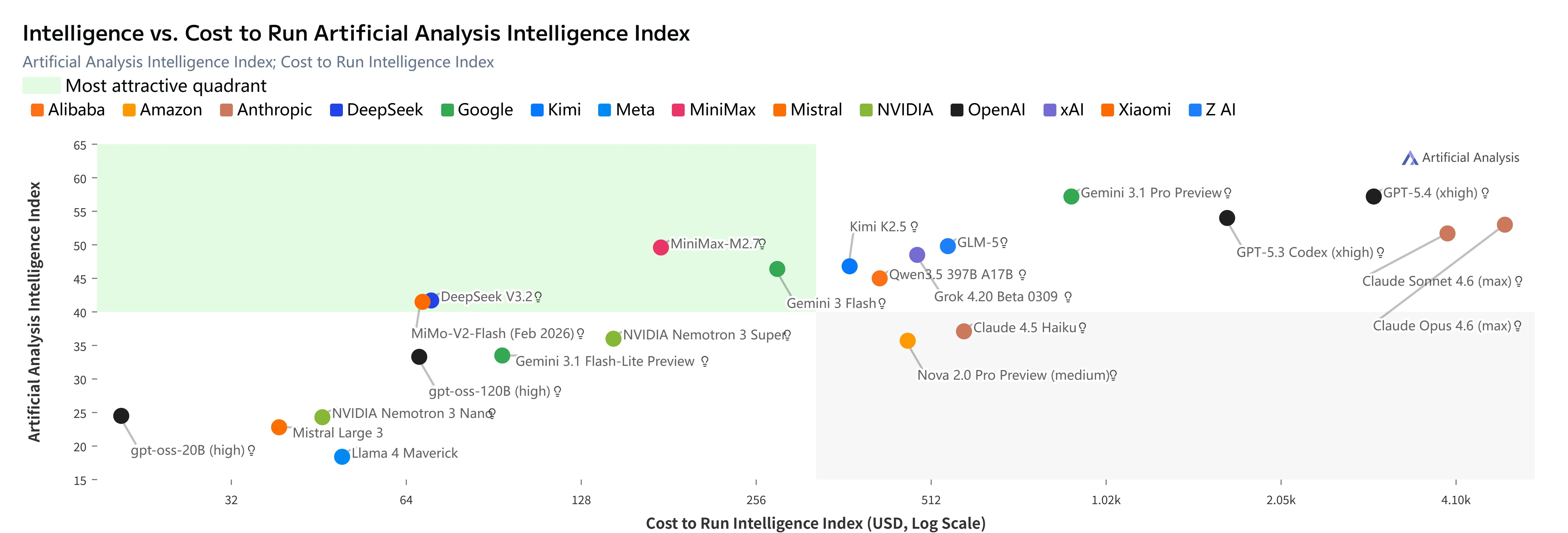
MiniMax M2.7 (punto rojo) en el “Cuadrante más atractivo” del Índice de Inteligencia vs. Coste de Artificial Analysis. [Fuente: Artificial Analysis]
Conclusiones clave:
- Inteligencia de nivel GLM-5 a casi 2/3 de coste inferior
- 3 veces más barato que Kimi K2.5 con mayor inteligencia
- 23 veces más barato que Claude Opus 4.6 con solo 5 puntos de diferencia en inteligencia
- Coste por punto de inteligencia más bajo entre todos los modelos con Índice ≥47
Mitigación de alucinaciones
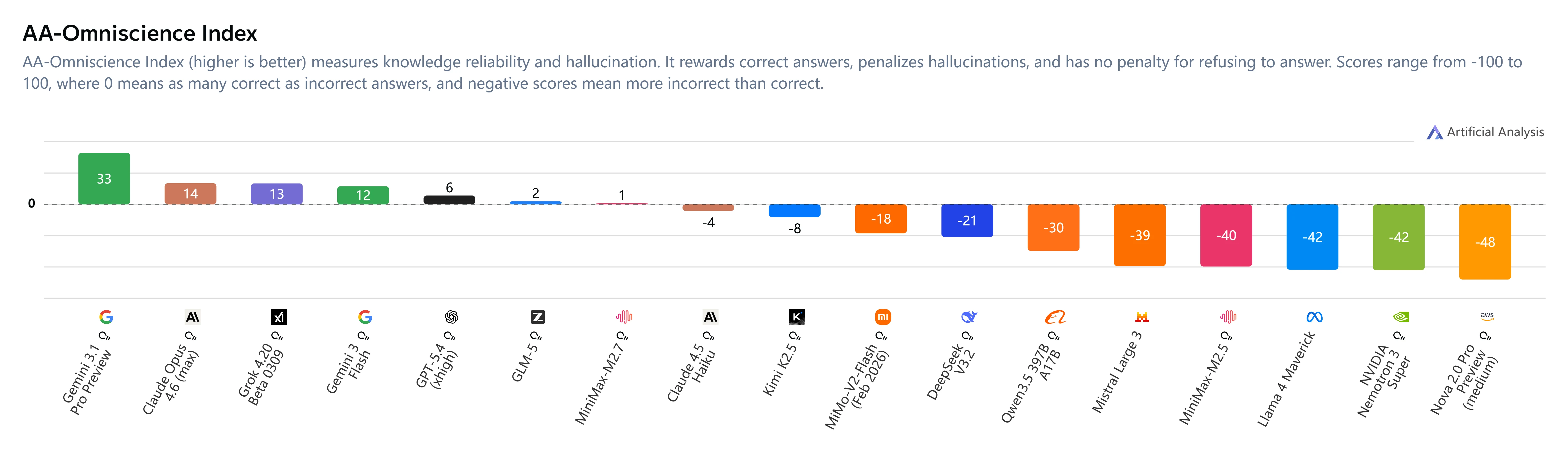
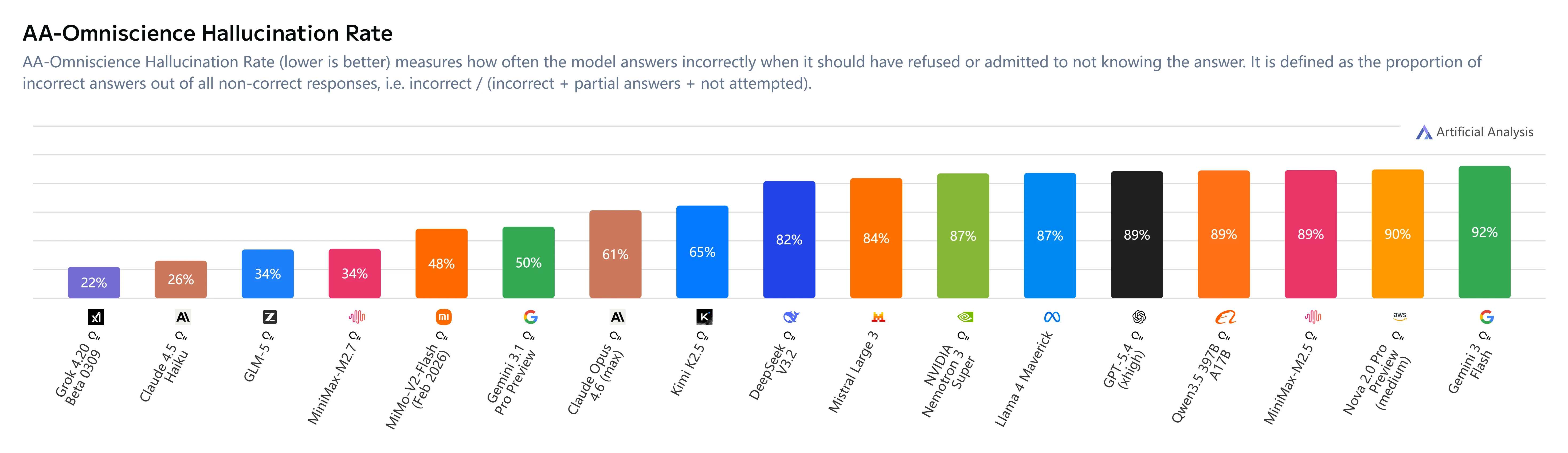
Conclusiones clave:
- Índice AA-Omniscience: +1 (frente al -40 de M2.5)
- Tasa de alucinaciones: 34% (menor que Claude Sonnet 4.6 con 46% y Gemini 3.1 Pro con 50%)
- Cambio de comportamiento: MiniMax M2.7 se abstiene cuando no está seguro en lugar de adivinar, mejorando significativamente la fiabilidad
Precios en Novita AI
| Parámetro | MiniMax M2.7 | GLM-5 | Kimi K2.5 |
| Entrada | $0.3/Mt | $1.0/Mt | $0.6/Mt |
| Salida | $1.2/Mt | $3.2/Mt | $3.0/Mt |
| Lectura de caché | $0.06/Mt | $0.2/Mt | $0.1/Mt |
| Ventana de contexto | 204,800 tokens | 202,800 tokens | 262,144 tokens |
¿Por qué elegir Novita AI para MiniMax M2.7?
- Precios competitivos: $0.3/Mt de entrada frente a tarifas más altas en otras plataformas
- Caché de indicaciones: 80% de reducción de costes en contexto repetido con lecturas de caché a $0.06/Mt
- Despliegue sin servidor: no se requiere gestión de infraestructura
- API unificada: endpoint compatible con OpenAI: cambia de modelo con una sola línea
- Red global de borde: inferencia de baja latencia desde centros de datos en EE.UU.
Cómo empezar con MiniMax M2.7 en Novita AI
Prerrequisitos
- Crea una cuenta de Novita AI (registro gratuito)
- Obtén una clave API
Crea tu cuenta y obtén una clave API
Cómo obtener la clave API
Uso de la API (Python)
from openai import OpenAI
client = OpenAI(
api_key="<Tu Clave API>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="minimax/minimax-m2.7",
messages=[
{"role": "system", "content": "Eres un asistente útil."},
{"role": "user", "content": "Hola, ¿cómo estás?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
Lo que MiniMax M2.7 puede hacer: Demostraciones del mundo real
MiniMax M2.7 sobresale en tareas complejas y listas para producción en múltiples dominios:
Desarrollo web full-stack: genera sitios web completos de una sola vez con características interactivas, diseños responsivos y componentes de interfaz funcionales, desde bibliotecas musicales hasta plataformas de comercio electrónico.
Depuración en producción y SRE: logra recuperación de incidentes en 3 minutos mediante análisis automatizado de registros, verificación en bases de datos y despliegue proactivo de correcciones. M2.7 maneja análisis de causa raíz, migraciones no bloqueantes y auditorías de seguridad de forma autónoma.
Desarrollo de software autónomo: entrega proyectos completos (Web, Android, iOS) desde requisitos hasta despliegue. Incluye refactorización multi-archivo, automatización de experimentos de ML y auto-mejora: M2.7 optimizó su propio entrenamiento en un 30% mediante depuración iterativa.
Automatización ofimática profesional: lee informes anuales, diseña modelos financieros y genera PPTs, todo con edición multi-turno en Excel, PowerPoint y Word. Perfecto para informes de investigación y flujos de trabajo de datos complejos.
Aplicaciones nativas de IA: se integra sin problemas con OpenClaw, Claude Code, Cursor y otros marcos de agentes mediante API compatible con OpenAI/Anthropic. Ideal para bots de atención al cliente, asistentes de investigación y herramientas creativas que requieren un 97% de adherencia a herramientas.
Conclusión
MiniMax M2.7 ofrece capacidades de agente de IA de nivel productivo a los desarrolladores a una fracción del coste de los modelos de razonamiento de frontera. Con un 97% de adherencia a herramientas, soporte nativo para Equipos de Agentes y un rendimiento excepcional en el mundo real en 8 benchmarks críticos, está diseñado para un despliegue agéntico fiable, no solo para demos.
A $0.3/Mt de entrada y $1.2/Mt de salida en Novita AI, M2.7 ofrece inteligencia competitiva por un tercio del precio de GLM-5. Ya sea que estés construyendo automatización SRE, proyectos web full-stack, herramientas de espacio de trabajo profesional o entornos de desarrollo impulsados por IA, M2.7 es una elección rentable y probada en batalla.
👉Comienza ahora: Prueba MiniMax M2.7 en Novita AI
Novita AI es una plataforma de nube de IA que ofrece a los desarrolladores una forma sencilla de desplegar modelos de IA utilizando nuestra API simple, al mismo tiempo que proporciona una GPU en la nube asequible y fiable para construir y escalar.
Preguntas frecuentes
¿Cuál es la diferencia entre M2.7 y M2.5?
M2.7 mejora a M2.5 en todos los benchmarks: (1) SWE Bench Pro: +4 puntos (52.2 → 56.2), (2) GDPval-AA: +15 puntos (35 → 50), (3) MLE-Bench lite: +35 puntos (31.5 → 66.6) y (4) la tasa de alucinaciones pasó de -40 a +1 en el índice AA-Omniscience. M2.7 es también el primer modelo MiniMax entrenado mediante auto-evolución.
¿M2.7 admite entradas de visión o audio?
Todavía no. La versión actual (M2.7) solo admite texto. MiniMax tiene modelos multimodales separados (Hailuo para video, Speech para audio), pero M2.7 se centra en razonamiento basado en texto y ejecución agéntica.
¿Cómo funciona en la práctica el 97% de adherencia a habilidades?
M2.7 fue entrenado para mantener límites de rol y adherencia a protocolos de herramientas incluso en sesiones largas y complejas. En pruebas con más de 40 herramientas (cada una >2,000 tokens), invocó funciones con los parámetros correctos el 97% de las veces, significativamente más alto que los modelos que se degradan con la proliferación de herramientas.
Artículos recomendados
Serie de modelos Qwen 3.5 Medium en Novita AI: Inteligencia de frontera a una fracción del coste
Tres nuevos modelos Qwen 3.5 Medium traen razonamiento agéntico de nivel frontera a Novita AI: pesos abiertos, contexto de 262K, listos para producción. Descubre cómo estos modelos ofrecen rendimiento de clase GPT-4 a una fracción del coste.
Construye agentes de IA rentables: usa MiniMax M2.5 en OpenClaw a través de Novita AI
Integra MiniMax M2.5 en OpenClaw (Clawdbolt) con Novita AI. Construye agentes de IA escalables y rentables en minutos con esta guía paso a paso para el despliegue de agentes multicanal.
Optimizando GLM4-MoE para producción: 65% más rápido en TTFT con SGLang
Aprende cómo Novita AI optimizó GLM 4.7 para producción con SGLang, logrando un tiempo hasta el primer token un 65% más rápido. Lectura esencial para desplegar modelos MoE grandes a escala.



