

- The Challenge: Building Reliable AI Agents Is Still Too Hard
- The Solution: MiniMax M2.7’s Self-Evolution Architecture
- Technical Specifications & Performance
- Pricing on Novita AI
- Why Choose Novita AI for MiniMax M2.7?
- How to Get Started with MiniMax M2.7 on Novita AI
- What MiniMax M2.7 Can Do: Real-World Showcases
- Conclusion
MiniMax M2.7 is now available on Novita AI, bringing production-grade AI agent capabilities with exceptional cost efficiency. This self-evolving reasoning model achieves an Intelligence Index of 50 (matching GLM-5) while costing 3x less to run. With 97% skill adherence across 40+ complex tools, native Agent Teams support, and industry-leading real-world task performance (GDPval-AA Elo 1495), M2.7 is built for developers who need reliable agentic AI without breaking the bank.
Pricing: $0.3/Mt input, $1.2/Mt output (Cache Read $0.06/Mt) Context Window: 204,800 tokens
Try It Now in Novita AI Playground!
The Challenge: Building Reliable AI Agents Is Still Too Hard
Most large language models claim “agentic capabilities,” but real-world deployment tells a different story:
- Tool-calling failures: Models misunderstand function signatures, skip required parameters, or hallucinate non-existent tools
- Context collapse: Long-running agent sessions hit token limits or lose critical context mid-task
- Unreliable execution: Works in demos, fails in production when handling 40+ skills simultaneously
- Cost explosion: Running frontier reasoning models like Claude Opus 4.6 or GPT-5.4 adds up fast
You need a model that actually works in production agent systems—not just one that looks good in benchmarks.
The Solution: MiniMax M2.7’s Self-Evolution Architecture
MiniMax M2.7 is the company’s first model that participated in its own development—literally debugging its training process, building evaluation harnesses, and optimizing its own scaffolding. This self-evolution loop produced a model uniquely suited for real-world agentic tasks.
What Makes M2.7 Different
1. Production-Ready Software Engineering
M2.7 doesn’t just write code—it debugs live systems. When a production alert fires, it correlates monitoring metrics with deployment timelines, performs statistical trace analysis, connects to databases to verify hypotheses, pinpoints missing index migration files, and knows to use non-blocking index creation to stop the bleeding before submitting the fix.
2. Native Agent Teams Support
Unlike models that simulate multi-agent workflows through prompting, M2.7 has role boundaries, adversarial reasoning, and behavioral differentiation baked in at the model level. It can:
- Stably anchor its role identity in multi-agent scenarios
- Proactively challenge teammates’ logical blind spots
- Make autonomous decisions within complex state machines
3. 97% Skill Adherence
Most models break down when handling more than a handful of tools. M2.7 maintains 97% skill-following accuracy even with 40+ complex skills, each exceeding 2,000 tokens. It understands long, intricate function definitions and uses them correctly in extended interactions.
4. Professional Workspace Excellence
- GDPval-AA Elo: 1495 (highest among open-source models, ahead of MiMo-V2-Pro and Kimi K2.5)
- High-fidelity Office editing: Multi-turn revisions in Excel, PowerPoint, and Word
- Real-world tasks: Reads annual reports, designs revenue models, generates PPTs from templates—like a junior analyst who self-corrects through feedback
5. Intelligence with Emotional IQ
M2.7 breaks the “cold tool” stereotype with high emotional intelligence and character consistency, enabling natural, human-like interactions beyond pure productivity tasks.
Try It Now in Novita AI Playground!
Technical Specifications & Performance
Technical Specifications
| Parameter | Value |
| Context Window | 204,800 tokens |
| Max Output | 131,072 tokens |
| Quantization | FP8 |
| Input Modalities | Text |
| Output Modalities | Text |
| Supported Features | Tools, JSON mode, Structured outputs, Reasoning |
| Sampling Parameters | temperature, top_p, top_k, repetition_penalty, frequency_penalty, presence_penalty, stop, seed |
Benchmark Performance Overview
MiniMax M2.7 demonstrates leading performance across real-world agentic tasks, outperforming or matching frontier models in key benchmarks:
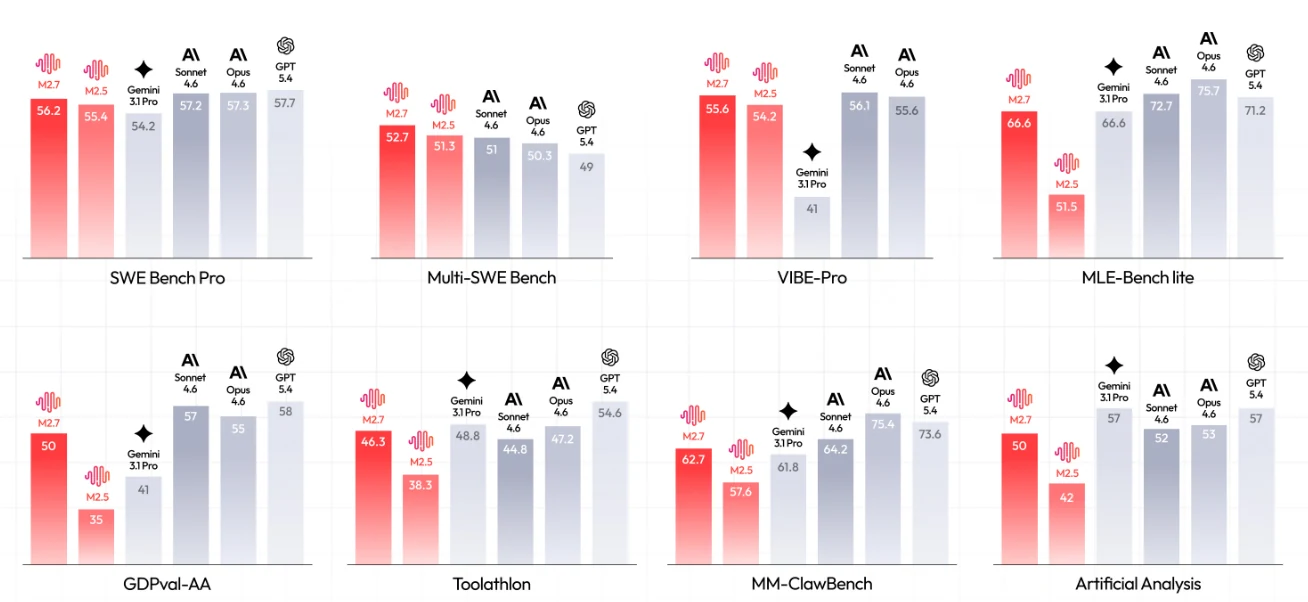
M2.7 (red bars) vs. competing models across 8 critical benchmarks. [Source: MiniMax Official]
Key Insights:
- SWE capabilities: 56.2% on SWE Bench Pro, approaching frontier models (GPT-5.4 at 57.7%)
- Multi-language edge: 52.7 on Multi-SWE Bench, outperforming all competitors including GPT-5.4 (49)
- ML automation: 66.6% on MLE-Bench lite, tied with Gemini 3.1 Pro and trailing only Opus 4.6 (75.7%) and GPT-5.4 (71.2%)
- Agentic excellence: GDPval-AA Intelligence Index 50, matching the benchmark’s baseline for production-ready performance
Intelligence vs. Cost: Best-in-Class Efficiency
M2.7 stands out not just for performance, but for delivering frontier-level intelligence at a fraction of the cost:
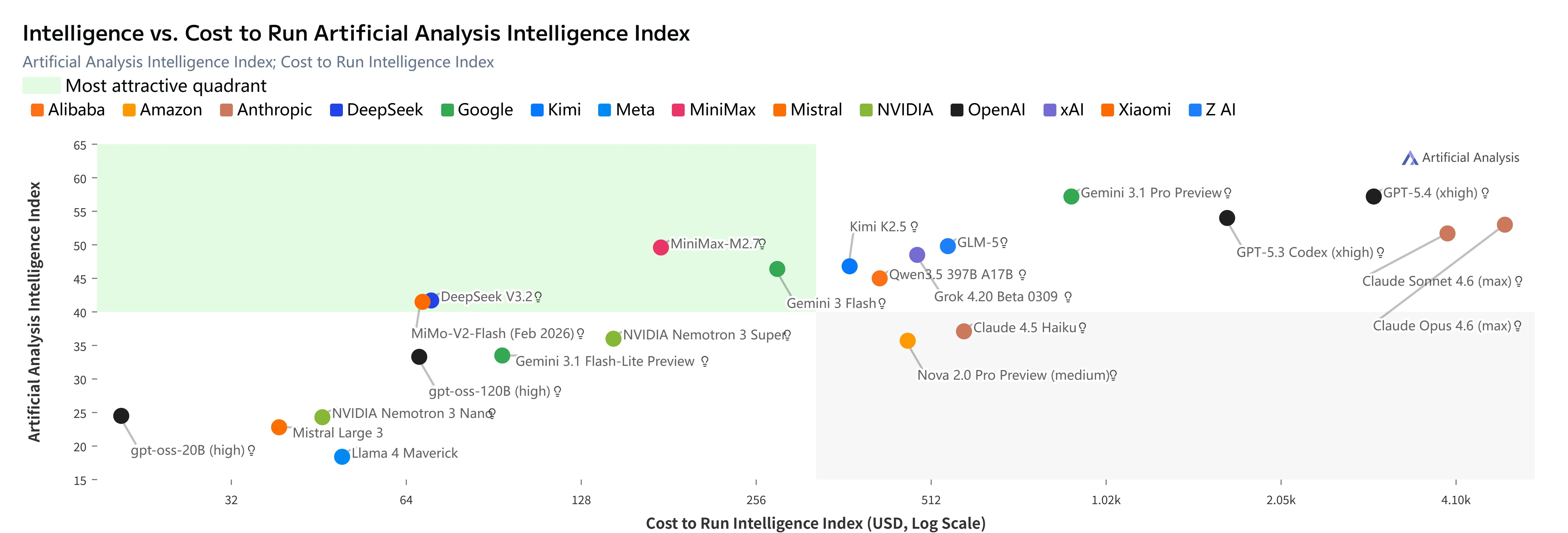
MiniMax M2.7 (red dot) in the “Most attractive quadrant” of Artificial Analysis Intelligence Index vs. Cost. [Source: Artificial Analysis]
Key Insights:
- GLM-5-level intelligence at almost 2/3 lower cost
- 3x cheaper than Kimi K2.5 with higher intelligence
- 23x cheaper than Claude Opus 4.6 with only 5-point intelligence gap
- Lowest cost per intelligence point among all models with Index ≥47
Hallucination Mitigation
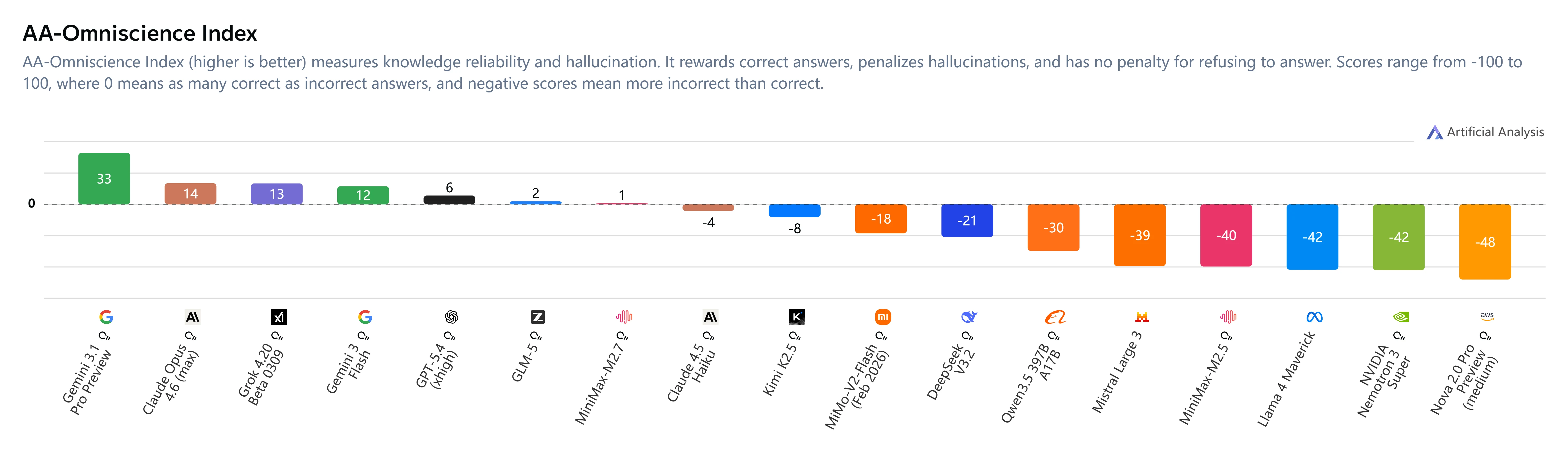
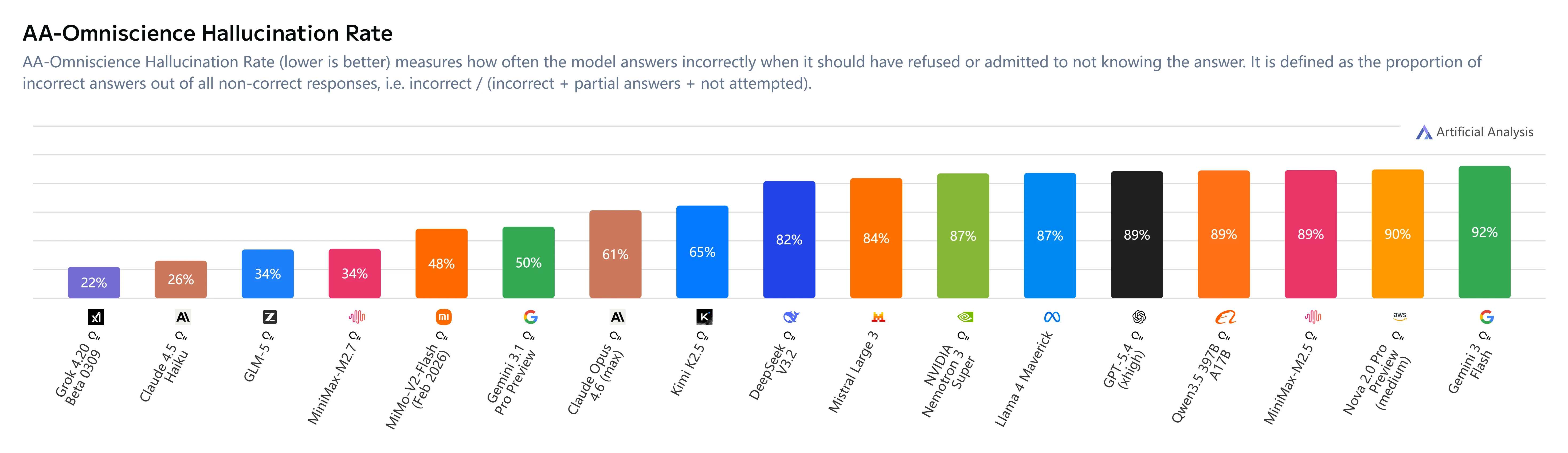
Key Insights:
- AA-Omniscience Index: +1 (up from M2.5’s -40)
- Hallucination rate: 34% (lower than Claude Sonnet 4.6 at 46% and Gemini 3.1 Pro at 50%)
- Behavior change: MiniMax M2.7 abstains when uncertain rather than guessing, significantly improving reliability
Pricing on Novita AI
| Parameter | MiniMax M2.7 | GLM-5 | Kimi K2.5 |
| Input | $0.3/Mt | $1.0/Mt | $0.6/Mt |
| Output | $1.2/Mt | $3.2/Mt | $3.0/Mt |
| Cache Read | $0.06/Mt | $0.2/Mt | $0.1/Mt |
| Context Window | 204,800 tokens | 202,800 tokens | 262,144 tokens |
Why Choose Novita AI for MiniMax M2.7?
- Competitive Pricing: $0.3/Mt input vs. higher rates on other platforms
- Prompt Caching: 80% cost reduction on repeated context with $0.06/Mt cache reads
- Serverless Deployment: No infrastructure management required
- Unified API: OpenAI-compatible endpoint—switch models with one line
- Global Edge Network: Low-latency inference from US datacenters
How to Get Started with MiniMax M2.7 on Novita AI
Prerequisites
- Create a Novita AI account (free sign-up)
- Get an API key
Create your Account and Get API Key
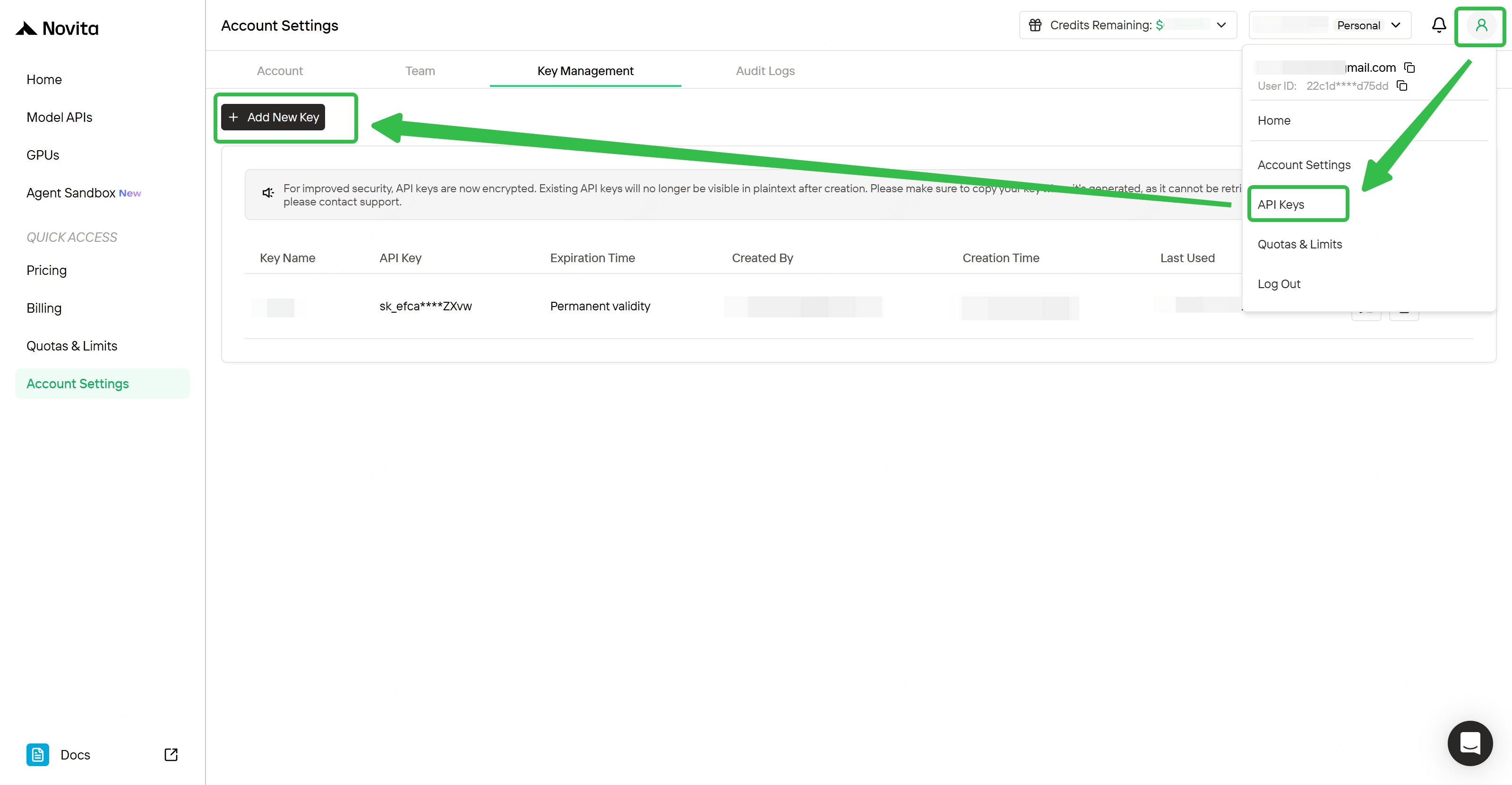
How to Get API Key
API Usage (Python)
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="minimax/minimax-m2.7",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)What MiniMax M2.7 Can Do: Real-World Showcases
MiniMax M2.7 excels at complex, production-ready tasks across multiple domains:
Full-Stack Web Development: Generate complete, single-shot websites with interactive features, responsive layouts, and functional UI components—from music libraries to e-commerce platforms.
Production Debugging & SRE: Achieve 3-minute incident recovery through automated log analysis, database verification, and proactive fix deployment. M2.7 handles root cause analysis, non-blocking migrations, and security audits autonomously.
Autonomous Software Development: Deliver end-to-end projects (Web, Android, iOS) from requirements to deployment. Includes multi-file refactoring, ML experiment automation, and self-improvement—M2.7 optimized its own training by 30% through iterative debugging.
Professional Office Automation: Read annual reports, design financial models, and generate PPTs—all with multi-turn editing across Excel, PowerPoint, and Word. Perfect for research reports and complex data workflows.
AI-Native Applications: Integrate seamlessly with OpenClaw, Claude Code, Cursor, and other agent frameworks via OpenAI/Anthropic-compatible API. Ideal for customer support bots, research assistants, and creative tools requiring 97% tool adherence.
Conclusion
MiniMax M2.7 brings production-grade AI agent capabilities to developers at a fraction of the cost of frontier reasoning models. With 97% tool adherence, native Agent Teams support, and exceptional real-world performance across 8 critical benchmarks, it’s built for reliable agentic deployment—not just demos.
At $0.3/Mt input and $1.2/Mt output on Novita AI, M2.7 delivers competitive intelligence for one-third the price of GLM-5. Whether you’re building SRE automation, full-stack web projects, professional workspace tools, or AI-powered development environments, M2.7 is a cost-efficient, battle-tested choice.
👉Get started: Try MiniMax M2.7 on Novita AI
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing an affordable and reliable GPU cloud for building and scaling.
Frequently Asked Questions
What’s the difference between M2.7 and M2.5?
M2.7 improves on M2.5 across all benchmarks: (1) SWE Bench Pro: +4 points (52.2 → 56.2), (2) GDPval-AA: +15 points (35 → 50), (3) MLE-Bench lite: +35 points (31.5 → 66.6), and (4) hallucination rate dropped from -40 to +1 on AA-Omniscience Index. M2.7 is also the first MiniMax model trained via self-evolution.
Does M2.7 support vision or audio inputs?
Not yet. The current version (M2.7) is text-only. MiniMax has separate multimodal models (Hailuo for video, Speech for audio), but M2.7 focuses on text-based reasoning and agentic execution.
How does the 97% skill adherence work in practice?
M2.7 was trained to maintain role boundaries and tool protocol adherence even in long, complex sessions. In testing with 40+ tools (each >2,000 tokens), it correctly invoked functions with proper parameters 97% of the time—significantly higher than models that degrade with tool proliferation.
Recommended Articles
Qwen 3.5 Medium Model Series on Novita AI: Frontier Intelligence at a Fraction of the Cost
Three new Qwen 3.5 Medium models bring frontier-level agentic reasoning to Novita AI—open-weight, 262K context, ready for production. Explore how these models deliver GPT-4-class performance at a fraction of the cost.
Build Cost-Efficient AI Agents: Use MiniMax M2.5 in OpenClaw via Novita AI
Integrate MiniMax M2.5 into OpenClaw (Clawdbolt) with Novita AI. Build scalable, cost-efficient AI agents in minutes with this step-by-step guide to multi-channel agent deployment.
Optimizing GLM4-MoE for Production: 65% Faster TTFT with SGLang
Learn how Novita AI optimized GLM 4.7 for production with SGLang, achieving 65% faster time-to-first-token. Essential reading for deploying large MoE models at scale



