

本地运行AI编码助手已成为开发者追求隐私、成本控制和无限使用的优先选择。但寻找一个既能提供强大性能又兼容消费级硬件的模型仍然充满挑战。Qwen3-Coder-Next于2026年发布,拥有800亿总参数,但每个Token仅激活30亿参数——这使得它能在高端消费级GPU上运行,同时在基准测试中击败激活参数多10-20倍的模型。
本指南涵盖三种主要访问Qwen3-Coder-Next的方法:通过Hugging Face/Transformers本地部署、使用llama.cpp/Unsloth进行量化推理、以及通过Novita AI的API访问。我们将探讨真实用户的使用体验、不同量化级别下的硬件要求,以及为代理式编码任务提供最佳性能的具体配置。
模型规格:Qwen3-Coder-Next有何不同
| 规格 | 详情 |
|---|---|
| 总参数量 | 800亿 |
| 每Token激活参数量 | 30亿 |
| 上下文长度 | 256K tokens(原生) |
| 架构 | 混合MoE |
| 许可证 | 开放权重 |
| 训练重点 | 代理式编码(长程推理、工具使用、执行失败恢复) |
基准性能:Qwen3-Coder-Next对比其他模型
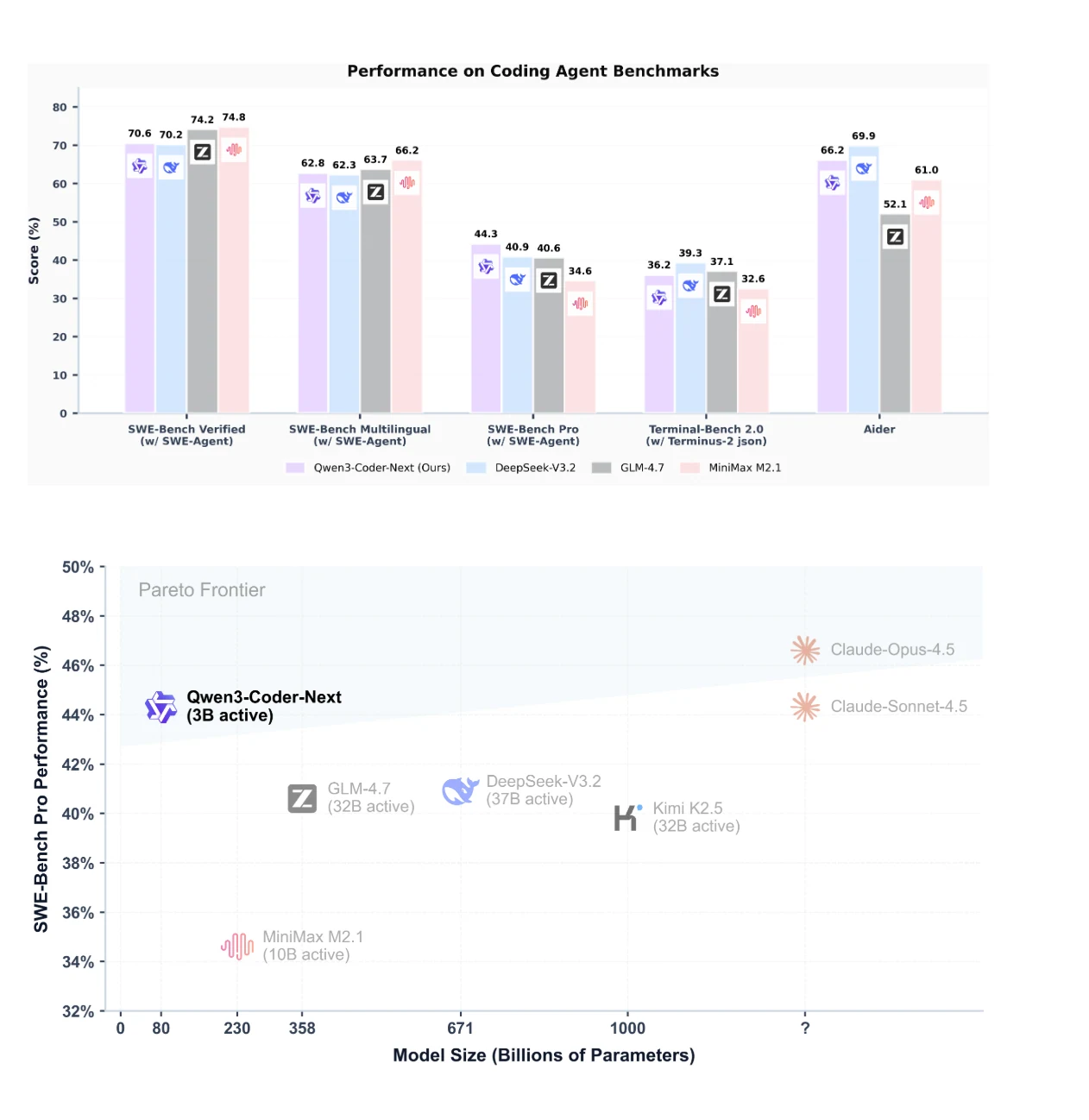
Qwen3-Coder-Next 在 SWE-Bench Pro 上取得领先性能,展示了出色的性能-参数效率权衡。
方法一:通过Novita API高效调用API
以下情况适合使用API访问:
- 你缺乏拥有35GB以上显存的硬件
- 你需要即时可用性,无需设置时间
- 你的使用是间歇性的而非连续性的
- 你希望避免基础设施维护
第1步:登录并访问模型库
登录你的账户,点击模型库按钮。

第2步:选择你的模型
浏览可用选项,选择符合需求的模型。

第3步:开始免费试用
开始免费试用,探索所选模型的能力。
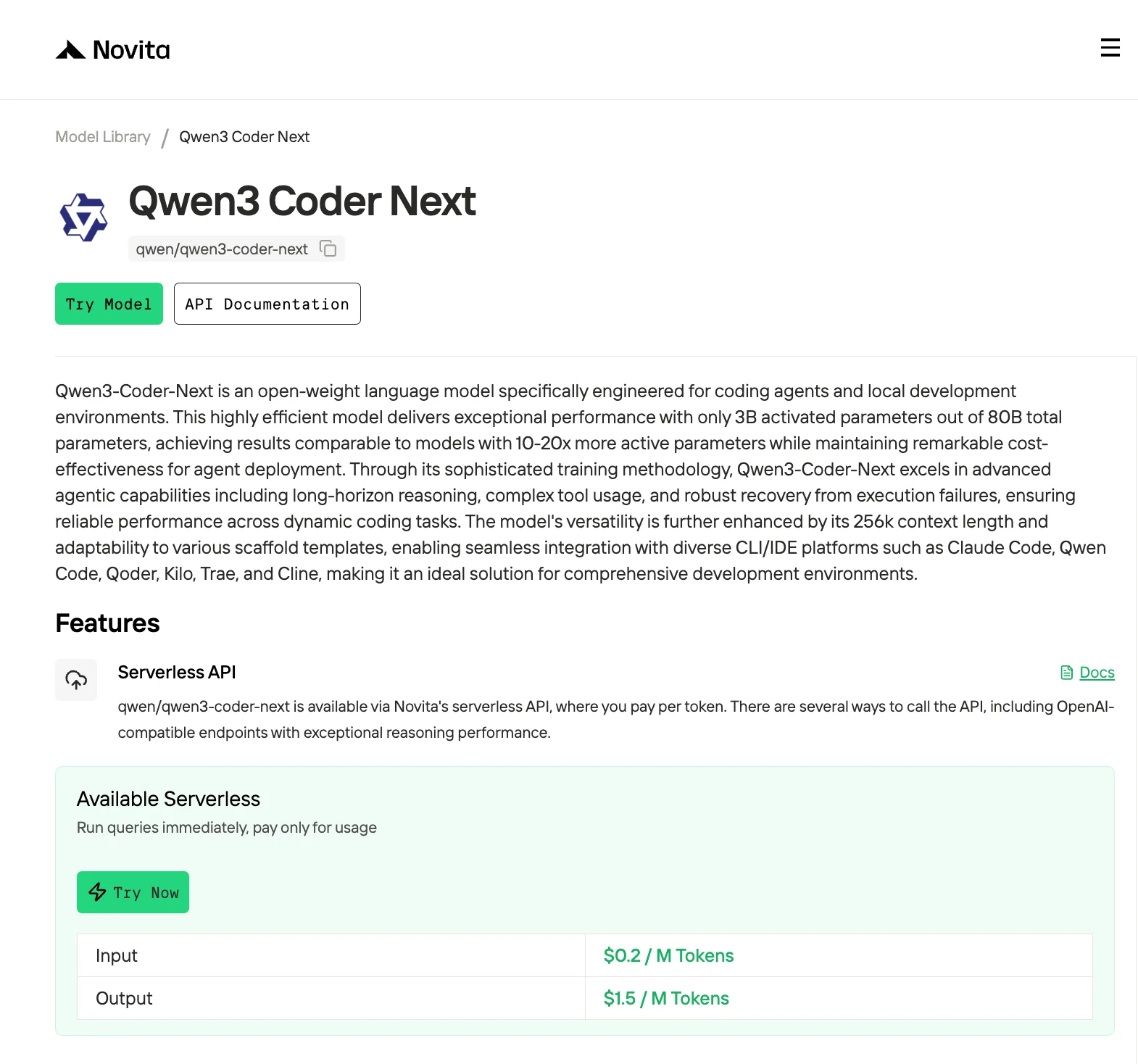
第4步:获取API密钥
为了通过API进行身份验证,我们将为你提供一个新的API密钥。进入“设置”页面,你可以按图中所示复制API密钥。

第5步:安装API
使用你编程语言对应的包管理器安装API。
安装后,将必要的库导入到你的开发环境。使用你的API密钥初始化API,开始与Novita AI LLM交互。以下是为Python用户使用聊天补全API的示例。
from openai import OpenAI
client = OpenAI(
api_key="<你的API密钥>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3-coder-next",
messages=[
{"role": "system", "content": "你是一个有用的助手。"},
{"role": "user", "content": "你好,你怎么样?"}
],
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].message.content)
方法二:通过Hugging Face Transformers本地部署
硬件要求:
- 从 HuggingFace 或 ModelScope 下载模型权重
- 选择推理框架:支持 vLLM 或 SGLang
- 参照官方GitHub仓库中的部署指南进行操作
当你需要稳定高性能推理、自定义模型控制,以及在持续或高负载下降低成本,而不是维护本地GPU和基础设施时,你会选择专用端点。
推荐生成参数
Qwen3-Coder-Next的最佳设置与典型编码模型不同:
- Temperature:1.0(高于典型编码模型)
- Top_P:0.95
- Top_K:40
- Min_P:0.01
这些设置使模型能够启用非推理模式以快速响应代码,同时保持质量。
方法三:LLM推理框架
llama.cpp 是一个轻量级C/C++ LLM推理框架,主要设计用于在CPU或低显存设备上高效运行GGUF量化模型。其主要优点是设置简单、CPU性能强劲、对macOS Apple Silicon支持优秀以及灵活的量化选项,不足之处在于高并发下吞吐量较低,且与现代化GPU服务框架相比GPU扩展性较弱。
# macOS 使用 Homebrew
brew install llama.cpp
# 或者从源码构建
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
make
# 使用 Hugging Face CLI(推荐)
llama-cli -hf unsloth/Qwen3-Coder-Next-GGUF:UD-Q4_K_XL
# 或者手动下载,地址:
# https://huggingface.co/unsloth/Qwen3-Coder-Next-GGUF
llama-server \
-hf unsloth/Qwen3-Coder-Next-GGUF:UD-Q4_K_XL \
--fit on \
--seed 3407 \
--temp 1.0 \
--top-p 0.95 \
--min-p 0.01 \
--top-k 40 \
--jinja \
--port 8080
Ollama 是一个对新手友好的LLM运行时和服务框架,它将推理后端(通常是llama.cpp)封装成简单的“拉取并运行”工作流。其优点是安装极其简单、自动管理模型、开箱即用的本地API服务器,不足之处是对底层推理参数的控制较少、调优灵活性有限,并且依赖Ollama模型打包生态系统。
# 安装 Ollama
curl -fsSL https://ollama.com/install.sh | sh
# 拉取并运行模型
ollama pull qwen3-coder-next
ollama run qwen3-coder-next
vLLM 是一个生产级GPU推理和服务框架,专为高吞吐量和多用户并发优化,主要由高效的KV缓存管理(PagedAttention)驱动。其优点是出色的服务性能、良好的GPU扩展性以及成熟的部署能力,不足之处在于系统复杂性较高、GPU/显存要求更重,并且不太适合纯CPU环境。
# 安装 vLLM
pip install 'vllm>=0.15.0'
# 启动服务
vllm serve Qwen/Qwen3-Coder-Next \
--port 8000 \
--tensor-parallel-size 2 \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder
SGLang 是一个高性能LLM推理和服务框架,专为快速解码和复杂执行流程(尤其是工具调用和代理风格工作流)优化。其优势在于激进的性能优化以及对高级多步生成管道的强力支持,不足之处是设置复杂度较高、生态系统不如vLLM成熟,并且为了获得最佳结果更依赖GPU基础设施。
# 安装 SGLang
pip install 'sglang[all]>=v0.5.8'
# 启动服务
python -m sglang.launch_server \
--model Qwen/Qwen3-Coder-Next \
--port 30000 \
--tp-size 2 \
--tool-call-parser qwen3_coder
方法四:集成代码代理工具
通过官方连接器和分步集成指南,轻松将Novita AI与合作伙伴平台(如Claude code、Cursor、Trae、Continue、Codex、OpenCode、AnythingLLM、LangChain、Dify和Langflow)连接。
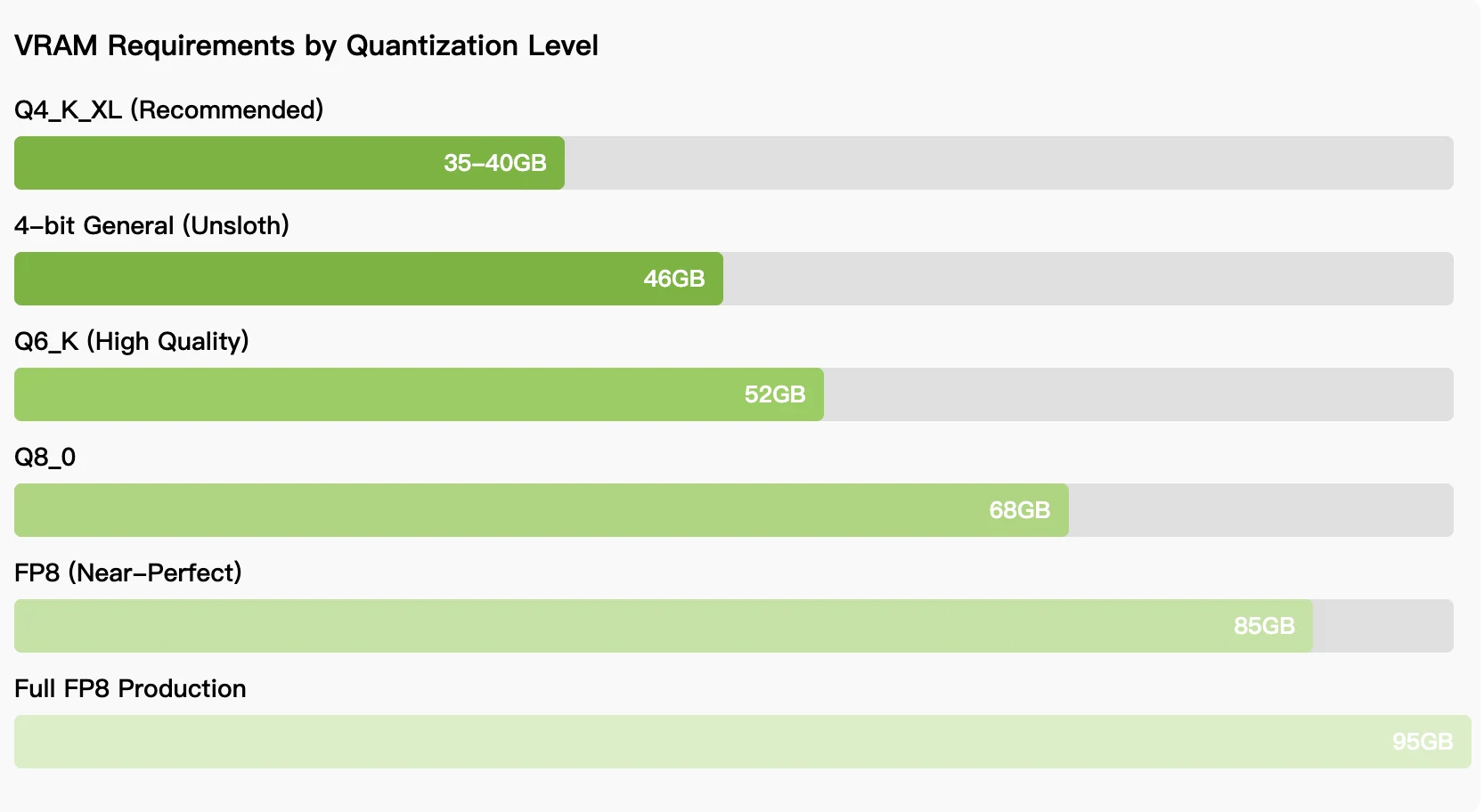
对于优先考虑成本控制和无限使用的团队而言,量化推理所需的35-46GB显存使得模型能够运行在RTX 5090、AMD Instinct GPU或64GB MacBook上。本地部署与API部署之间的选择取决于使用模式:持续开发工作倾向于本地部署,尽管设置复杂;而间歇性使用则受益于无服务器访问。随着模型成熟和量化技术改进,本地与托管性能之间的差距不断缩小,使Qwen3-Coder-Next成为寻求替代专有编码助手的开发者的可行选择。
常见问题解答
本地运行Qwen3-Coder-Next需要什么硬件?
4位量化需要35-46GB显存,可通过RTX 5090、AMD Radeon 7900 XTX、AMD Instinct GPU或具有统一内存的64GB MacBook实现。全精度需要85-95GB显存。
Qwen3-Coder-Next与更大模型相比表现如何?
它在代理式编码基准测试中优于激活参数多10-20倍的模型(如DeepSeek-V3.2),在SWE-Bench Verified上达到74.2%,在Aider上达到69.9%。
Qwen3-Coder-Next的推荐生成设置是什么?
使用temperature=1.0、top_p=0.95、top_k=40和min_p=0.01可获得最佳代码生成效果。这些设置可启用非推理模式以快速响应,同时保持质量。
Novita AI 是一个AI云平台,为开发者提供通过简单API部署AI模型的简便方式,同时提供经济可靠的GPU云,用于构建和扩展。
推荐阅读



