

أصبح تشغيل مساعدي البرمجة بالذكاء الاصطناعي محليًا أولوية للمطورين الذين يسعون إلى الخصوصية والتحكم في التكاليف والاستخدام غير المحدود. لكن العثور على نموذج يحقق التوازن بين القوة وسهولة الوصول إلى أجهزة المستهلكين لا يزال تحديًا. يعد نموذج Qwen3-Coder-Next، الذي تم إصداره في عام 2026، حلاً لهذه المشكلة حيث يحتوي على 80 مليار معامل إجمالي، لكن يتم تفعيل 3 مليارات فقط منها لكل رمز، مما يجعله قابلاً للتشغيل على وحدات معالجة الرسومات عالية الأداء للمستهلكين، مع تقديم نتائج في اختبارات الأداء تنافس النماذج التي تحتوي على 10 إلى 20 ضعفًا من المعاملات المفعلة.
يغطي هذا الدليل الطرق الأساسية الثلاث للوصول إلى Qwen3-Coder-Next: النشر المحلي عبر Hugging Face/Transformers، الاستدلال الكمي باستخدام llama.cpp/Unsloth، والوصول عبر واجهة برمجة التطبيقات (API) من خلال Novita AI. سنستكشف تجارب المستخدمين الواقعية من المطورين الذين اختبروا النموذج، ومتطلبات الأجهزة عبر مستويات الكمية المختلفة، والتكوينات المحددة التي تقدم أداءً مثاليًا لمهام البرمجة الوكيلية.
مواصفات النموذج: ما الذي يجعل Qwen3-Coder-Next مختلفًا؟
| المواصفة | التفاصيل |
|---|---|
| إجمالي المعاملات | 80 مليار |
| المعاملات المفعلة | 3 مليارات لكل رمز/استدلال |
| طول السياق | 256 ألف رمز أصلي |
| الهيكلية | MoE هجين |
| الترخيص | أوزان مفتوحة |
| مجال التدريب | البرمجة الوكيلية (الاستدلال طويل الأمد، استخدام الأدوات، التعافي من أخطاء التنفيذ) |
أداء اختبارات المقارنة: كيف يتنافس Qwen3-Coder-Next مع النماذج الأخرى
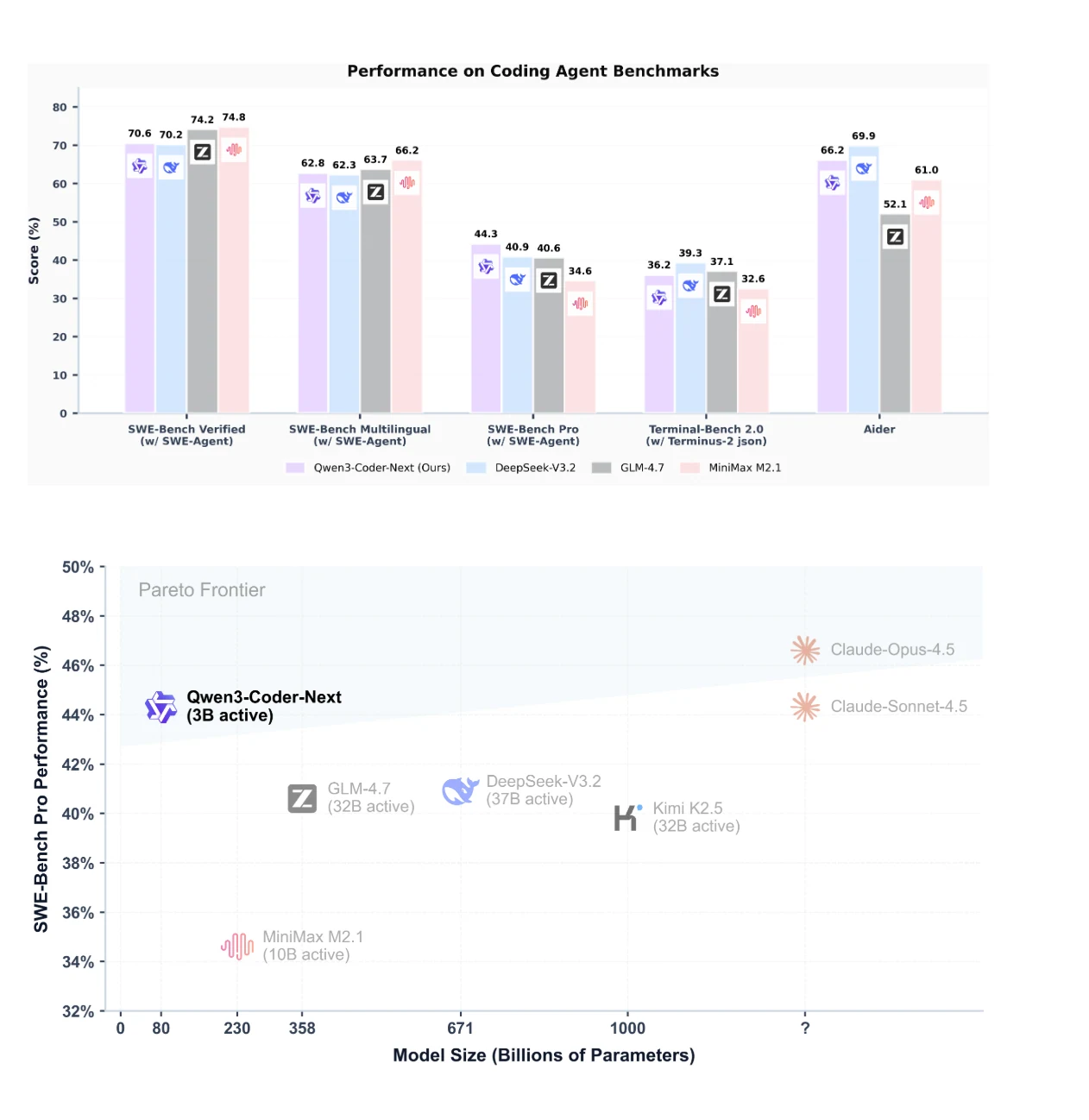
يحقق Qwen3-Coder-Next أداءً رائدًا في اختبار SWE-Bench Pro ويظهر توازنًا ممتازًا بين الأداء وكفاءة المعاملات.
الطريقة 1: الوصول الفعال عبر واجهة برمجة تطبيقات Novita API
يعد الوصول عبر واجهة برمجة التطبيقات خيارًا مناسبًا عندما:
- لا تملك أجهزة تحتوي على 35 جيجابايت أو أكثر من ذاكرة الوصول العشوائي للرسومات (VRAM)
- تحتاج إلى توفر فوري دون وقت إعداد
- استخدامك متقطع بدلاً من مستمر
- تريد تجنب صيانة البنية التحتية
الخطوة 1: تسجيل الدخول والوصول إلى مكتبة النماذج
سجل الدخول إلى حسابك وانقر على زر مكتبة النماذج.

الخطوة 2: اختر النموذج الخاص بك
تصفح الخيارات المتاحة واختر النموذج الذي يناسب احتياجاتك.

الخطوة 3: ابدأ تجربتك المجانية
ابدأ تجربتك المجانية لاستكشاف قدرات النموذج المحدد.
الخطوة 4: احصل على مفتاح واجهة برمجة التطبيقات الخاص بك
للمصادقة مع واجهة برمجة التطبيقات، سنزودك بمفتاح API جديد. عند الدخول إلى صفحة “الإعدادات”، يمكنك نسخ مفتاح API كما هو موضح في الصورة.

الخطوة 5: تثبيت واجهة برمجة التطبيقات
قم بتثبيت واجهة برمجة التطبيقات باستخدام مدير الحزم الخاص بلغة البرمجة التي تستخدمها.
بعد التثبيت، قم باستيراد المكتبات الضرورية إلى بيئة التطوير الخاصة بك. قم بتهيئة واجهة برمجة التطبيقات باستخدام مفتاح API الخاص بك لبدء التفاعل مع نماذج اللغات الكبيرة من Novita AI. هذا مثال على استخدام واجهة برمجة تطبيقات إكمال الدردشة لمستخدمي بايثون.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3-coder-next",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].message.content)
الطريقة 2: النشر المحلي عبر Hugging Face Transformers
متطلبات الأجهزة المطلوبة:
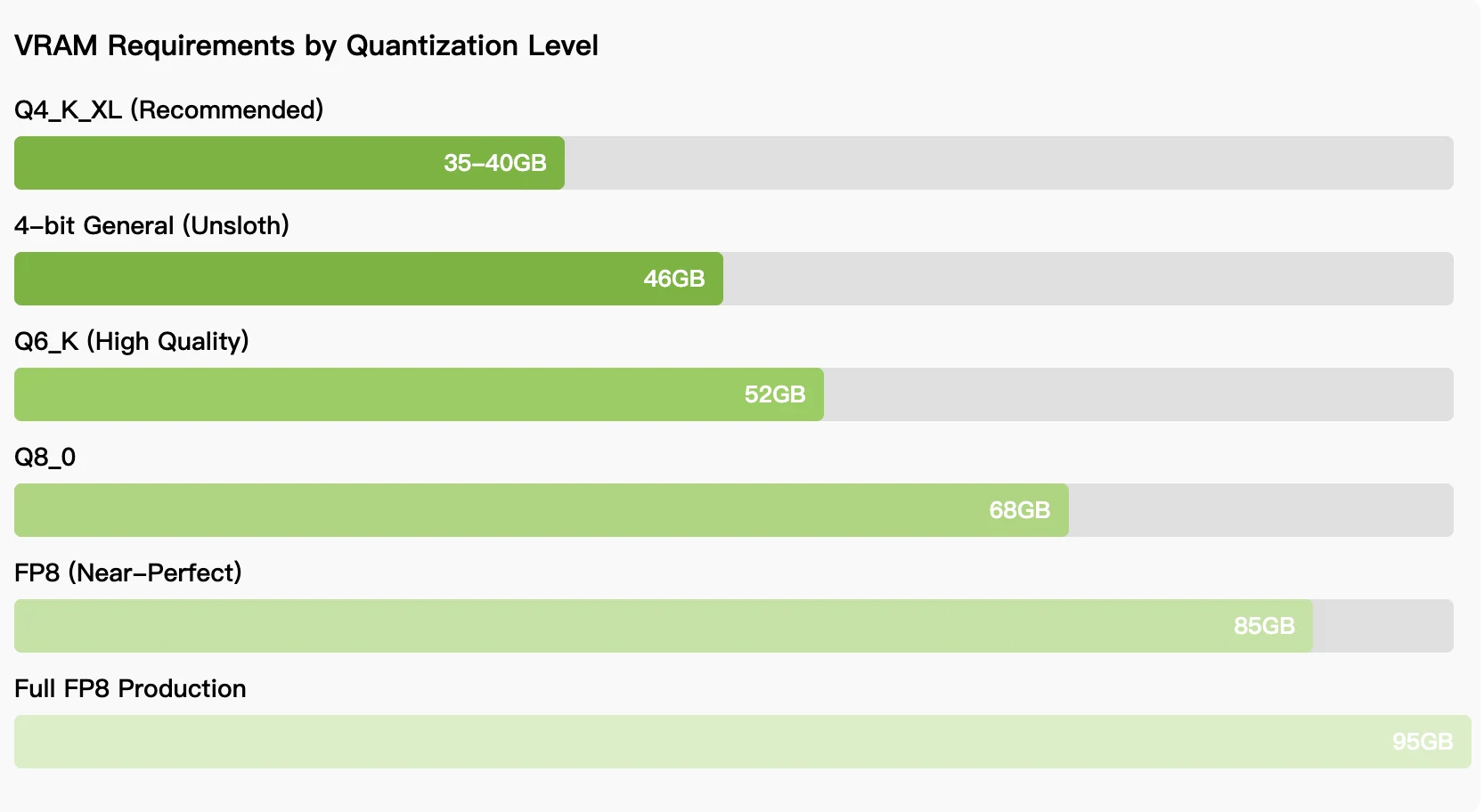
- تنزيل أوزان النموذج من HuggingFace أو ModelScope
- اختر إطار عمل الاستدلال: مدعوم من vLLM أو SGLang
- اتبع دليل النشر في مستودع GitHub الرسمي
ستختار نقطة نهاية مخصصة عندما تحتاج إلى استدلال مستقر عالي الأداء، والتحكم المخصص في النموذج، وتكاليف أقل تحت أحمال عمل مستمرة أو ثقيلة، بدلاً من صيانة وحدات معالجة الرسومات المحلية والبنية التحتية.
جرب نقطة النهاية المخصصة الآن!
معلمات التوليد الموصى بها
تختلف الإعدادات المثلى لنموذج Qwen3-Coder-Next عن النماذج البرمجية النموذجية:
- درجة الحرارة: 1.0 (أعلى من النماذج البرمجية النموذجية)
- Top_P: 0.95
- Top_K: 40
- Min_P: 0.01
تتيح هذه الإعدادات وضع عدم الاستدلال للنموذج للحصول على استجابات برمجية سريعة مع الحفاظ على الجودة.
الطريقة 3: أطر عمل استدلال نماذج اللغات الكبيرة (LLM)
يعد llama.cpp إطار عمل استدلال خفيف الوزن للغات الكبيرة مكتوب بلغة C/C++ مصمم بشكل أساسي لتشغيل النماذج الكمية من نوع GGUF بكفاءة على وحدات المعالجة المركزية (CPU) أو الأجهزة ذات ذاكرة الوصول العشوائي للرسومات (VRAM) المنخفضة. من مزاياه الرئيسية سهولة الإعداد، وأداء قوي على وحدات المعالجة المركزية، ودعم ممتاز لشريحة Apple Silicon في أنظمة macOS، وخيارات كمية مرنة، بينما تشمل نقاط ضعفه انخفاض الإنتاجية تحت أحمال العمل ذات الاتصال العالي، وضعف توسيع نطاق وحدات معالجة الرسومات مقارنة بأطر عمل الخدمة الحديثة على وحدات معالجة الرسومات.
# macOS with Homebrew
brew install llama.cpp
# Or build from source
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
make
# Using Hugging Face CLI (recommended)
llama-cli -hf unsloth/Qwen3-Coder-Next-GGUF:UD-Q4_K_XL
# Or download manually from:
# https://huggingface.co/unsloth/Qwen3-Coder-Next-GGUF
llama-server \
-hf unsloth/Qwen3-Coder-Next-GGUF:UD-Q4_K_XL \
--fit on \
--seed 3407 \
--temp 1.0 \
--top-p 0.95 \
--min-p 0.01 \
--top-k 40 \
--jinja \
--port 8080
يعد Ollama إطار عمل تشغيل وخدمة للغات الكبيرة سهل الاستخدام للمبتدئين، حيث يغلف واجهات الاستدلال الخلفية (غالبًا llama.cpp) في سير عمل بسيط “اسحب واشغل”. من نقاط قوته سهولة التثبيت للغاية، وإدارة النماذج تلقائيًا، وخادم واجهة برمجة تطبيقات محلي جاهز للاستخدام فورًا، بينما تشمل قيوده انخفاض التحكم في معاملات الاستدلال منخفضة المستوى، ومرونة أقل في الضبط، والاعتماد على نظام بيئة تغليف النماذج الخاص بـ Ollama.
# Install Ollama
curl -fsSL https://ollama.com/install.sh | sh
# Pull and run the model
ollama pull qwen3-coder-next
ollama run qwen3-coder-next
يعد vLLM إطار عمل استدلال وخدمة لوحدات معالجة الرسومات من الدرجة الإنتاجية، محسّن للإنتاجية العالية والتزامن متعدد المستخدمين، مدعوم بشكل كبير بإدارة ذاكرة التخزين المؤقت KV الفعالة (PagedAttention). من مزاياه أداء خدمة ممتاز، وقابلية توسع قوية عبر وحدات معالجة الرسومات، وقدرات نشر ناضجة، بينما تشمل عيوبه تعقيد نظام أعلى، ومتطلبات أعلى لوحدات معالجة الرسومات/ذاكرة الوصول العشوائي للرسومات، وعدم ملاءمته للبيئات التي تعتمد فقط على وحدات المعالجة المركزية.
# Install vLLM
pip install 'vllm>=0.15.0'
# Start server
vllm serve Qwen/Qwen3-Coder-Next \
--port 8000 \
--tensor-parallel-size 2 \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder
يعد SGLang إطار عمل استدلال وخدمة عالي الأداء للغات الكبيرة، محسّن لفك التشفير السريع وخطوط أنابيب التنفيذ المعقدة، خاصة مكالمات الأدوات وسير عمل النماذج الوكيلية. من نقاط قوته التحسين العدواني للأداء، والدعم القوي لخطوط أنابيب التوليد متعددة الخطوات المتقدمة، بينما تشمل سلبياته تعقيد إعداد أعلى، ونظام بيئة أقل نضجًا من vLLM، واعتماد أقوى على بنية تحتية لوحدات معالجة الرسومات للحصول على أفضل النتائج.
# Install SGLang
pip install 'sglang[all]>=v0.5.8'
# Launch server
python -m sglang.launch_server \
--model Qwen/Qwen3-Coder-Next \
--port 30000 \
--tp-size 2 \
--tool-call-parser qwen3_coder
الطريقة 4: التكامل مع أدوات وكلاء البرمجة
اربط Novita AI بسهولة بالمنصات الشريكة مثل Claude code، Cursor، Trae، Continue، Codex، OpenCode، AnythingLLM،LangChain، Dify و Langflow عبر موصلات رسمية وأدلة تكامل خطوة بخطوة.
بالنسبة للفرق التي تعطي الأولوية للتحكم في التكاليف والاستخدام غير المحدود، فإن متطلب ذاكرة الوصول العشوائي للرسومات (VRAM) البالغ 35-46 جيجابايت للاستدلال الكمي يجعل النموذج في متناول وحدات معالجة الرسومات RTX 5090، أو وحدات معالجة الرسومات AMD Instinct، أو أجهزة MacBooks ذات ذاكرة موحدة سعة 64 جيجابايت. يعتمد الاختيار بين النشر المحلي والنشر عبر واجهة برمجة التطبيقات على أنماط الاستخدام: حيث يفضل العمل التطويري المستمر النشر المحلي على الرغم من تعقيد الإعداد، بينما تستفيد حالات الاستخدام المتقطع من الوصول بدون خادم. مع نضوج النموذج وتحسين تقنيات الكمية، يستمر الفجوة بين الأداء المحلي والأداء المستضاف في الانخفاض، مما يجعل Qwen3-Coder-Next خيارًا عمليًا للمطورين الذين يبحثون عن بدائل لمساعدي البرمجة الاحتكاريين.
الأسئلة الشائعة
ما هي الأجهزة المطلوبة لتشغيل Qwen3-Coder-Next محليًا؟ تحتاج إلى 35-46 جيجابايت من ذاكرة الوصول العشوائي للرسومات (VRAM) للكمية 4 بت، وهو ما يمكن تحقيقه باستخدام RTX 5090، أو AMD Radeon 7900 XTX، أو وحدات معالجة الرسومات AMD Instinct، أو أجهزة MacBooks ذات ذاكرة موحدة سعة 64 جيجابايت. تتطلب الدقة الكاملة 85-95 جيجابايت من ذاكرة الوصول العشوائي للرسومات.
كيف يقارن أداء Qwen3-Coder-Next بالنماذج الأكبر حجمًا؟ يتفوق على النماذج التي تحتوي على 10 إلى 20 ضعفًا من المعاملات المفعلة مثل DeepSeek-V3.2 في اختبارات البرمجة الوكيلية، حيث يحقق 74.2% في اختبار SWE-Bench Verified و 69.9% في أداة Aider.
ما هي إعدادات التوليد الموصى بها لنموذج Qwen3-Coder-Next؟ استخدم درجة الحرارة = 1.0، و top_p = 0.95، و top_k = 40، و min_p = 0.01 للحصول على توليد برمجي مثالي. تتيح هذه الإعدادات وضع عدم الاستدلال للحصول على استجابات سريعة مع الحفاظ على الجودة.
Novita AI هي منصة سحابية للذكاء الاصطناعي توفر للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام واجهة برمجة التطبيقات البسيطة الخاصة بنا، بالإضافة إلى توفير سحابة لوحدات معالجة الرسومات بأسعار معقولة وموثوقة للبناء والتوسع.
موصى بالقراءة



