

AI 코딩 어시스턴트를 로컬에서 실행하는 것은 프라이버시, 비용 절감, 무제한 사용을 원하는 개발자에게 중요한 과제가 되었습니다. 하지만 소비자 하드웨어에서도 사용할 수 있으면서 강력한 성능을 제공하는 모델을 찾는 것은 여전히 어렵습니다. 2026년에 출시된 Qwen3-Coder-Next는 총 800억 개의 파라미터를 가지고 있지만 토큰당 30억 개만 활성화되어, 하이엔드 소비자 GPU에서 실행 가능하면서도 10~20배 더 많은 활성 파라미터를 가진 모델과 견줄 만한 벤치마크 결과를 제공합니다.
이 가이드는 Qwen3-Coder-Next에 접속하는 세 가지 주요 방법을 다룹니다: Hugging Face/Transformers를 통한 로컬 배포, llama.cpp/Unsloth를 통한 양자화 추론, 그리고 Novita AI를 통한 API 액세스. 모델을 테스트한 개발자들의 실제 사용 경험, 다양한 양자화 수준의 하드웨어 요구 사항, 에이전트 코딩 작업에 최적의 성능을 제공하는 특정 구성을 살펴보겠습니다.
모델 사양: Qwen3-Coder-Next의 차별점
| 사양 | 세부 내용 |
|---|---|
| 총 파라미터 | 800억 |
| 활성 파라미터 | 토큰/추론당 30억 |
| 컨텍스트 길이 | 기본 256K 토큰 |
| 아키텍처 | 하이브리드 MoE |
| 라이선스 | 오픈 가중치 |
| 훈련 초점 | 에이전트 코딩 (장기 추론, 도구 사용, 실행 실패 복구) |
벤치마크 성능: Qwen3-Coder-Next 비교
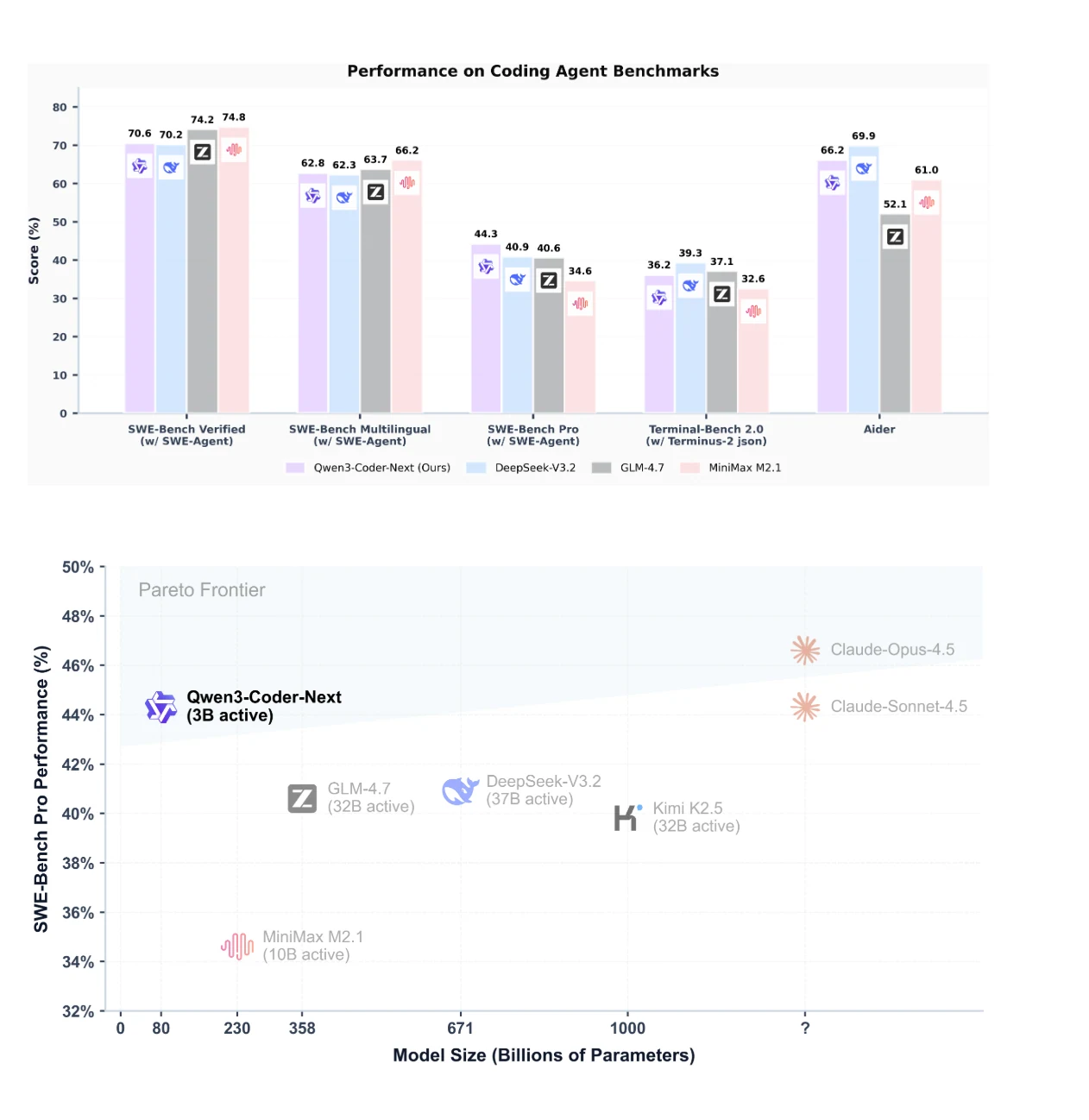
Qwen3-Coder-Next는 SWE-Bench Pro에서 최고 성능을 달성하며 우수한 성능-파라미터 효율 트레이드오프를 보여줍니다.
방법 1: Novita API를 통한 효율적인 API 사용
API 접근이 적합한 경우:
- 35GB 이상의 VRAM을 갖춘 하드웨어가 없는 경우
- 설정 시간 없이 즉시 사용 가능한 기능이 필요한 경우
- 사용량이 지속적이기보다 간헐적인 경우
- 인프라 유지 관리를 피하고 싶은 경우
1단계: 로그인 및 모델 라이브러리 접속
계정에 로그인하고 모델 라이브러리 버튼을 클릭하세요.

2단계: 모델 선택
사용 가능한 옵션을 살펴보고 필요에 맞는 모델을 선택하세요.

3단계: 무료 체험 시작
선택한 모델의 기능을 살펴보기 위해 무료 체험을 시작하세요.
4단계: API 키 발급
API 인증을 위해 새로운 API 키를 제공해 드립니다. “설정” 페이지로 이동하여 이미지에 표시된 대로 API 키를 복사하세요.

5단계: API 설치
프로그래밍 언어에 맞는 패키지 관리자를 사용하여 API를 설치하세요.
설치 후, 개발 환경에 필요한 라이브러리를 가져옵니다. API 키를 사용하여 API를 초기화하고 Novita AI LLM과 상호작용을 시작하세요. 다음은 Python 사용자를 위한 채팅 완성 API 사용 예시입니다.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3-coder-next",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].message.content)
방법 2: Hugging Face Transformers를 통한 로컬 배포
하드웨어 요구 사항:
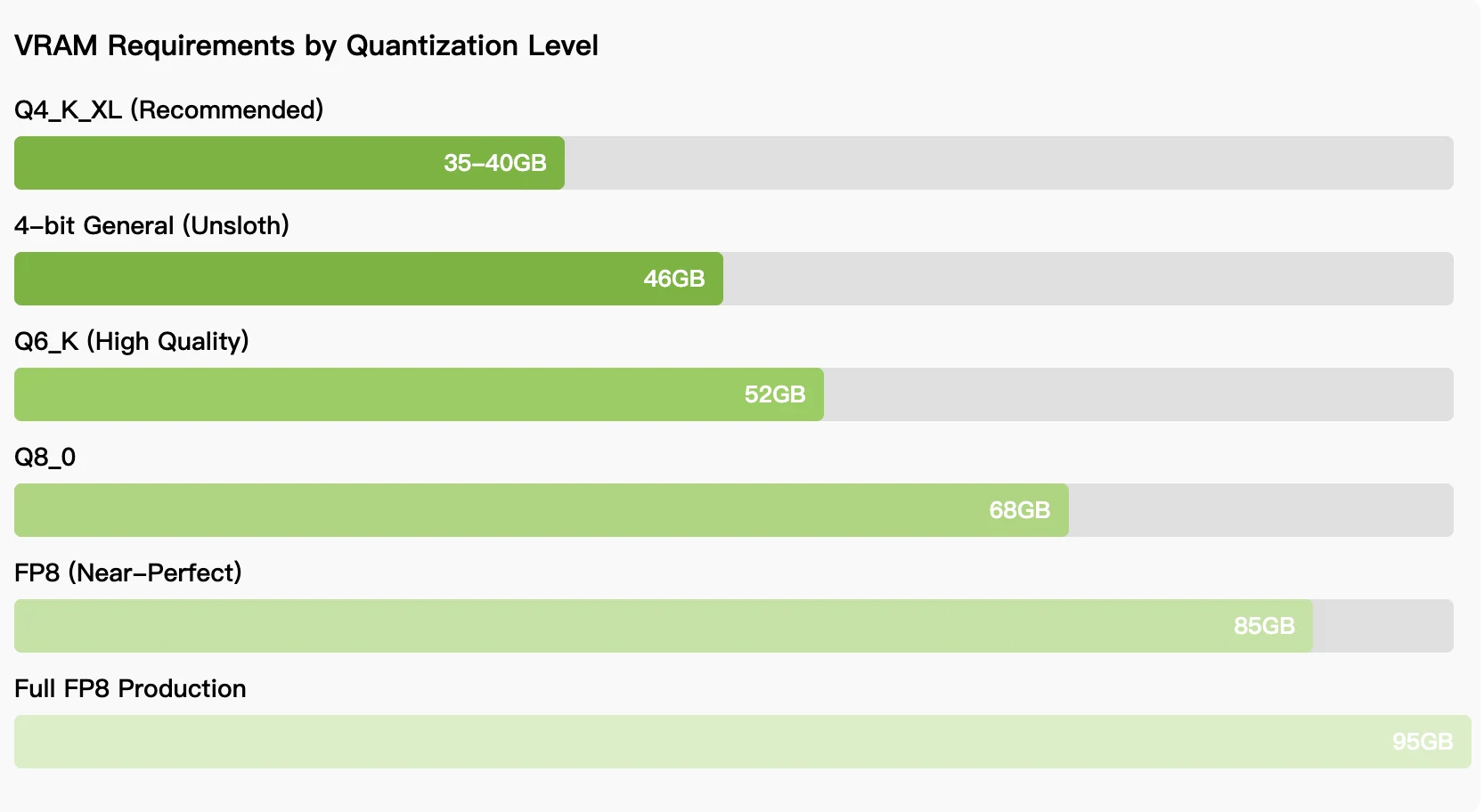
- 모델 가중치 다운로드: HuggingFace 또는 ModelScope에서 다운로드
- 추론 프레임워크 선택: vLLM 또는 SGLang 지원
- 공식 GitHub 저장소의 배포 가이드 참조
지속적이거나 대량의 워크로드에서 안정적인 고성능 추론, 맞춤형 모델 제어, 로컬 GPU 및 인프라 유지 관리보다 낮은 비용이 필요하다면 전용 엔드포인트를 선택하세요.
권장 생성 파라미터
Qwen3-Coder-Next의 최적 설정은 일반 코딩 모델과 다릅니다:
- Temperature: 1.0 (일반 코딩 모델보다 높음)
- Top_P: 0.95
- Top_K: 40
- Min_P: 0.01
이 설정은 품질을 유지하면서 빠른 코드 응답을 위한 모델의 비추론 모드를 활성화합니다.
방법 3: LLM 추론 프레임워크
llama.cpp는 주로 CPU 또는 저VRAM 장치에서 GGUF 양자화 모델을 효율적으로 실행하도록 설계된 경량 C/C++ LLM 추론 프레임워크입니다. 주요 장점은 간편한 설정, 강력한 CPU 성능, macOS Apple Silicon에 대한 우수한 지원, 유연한 양자화 옵션입니다. 단점은 높은 동시성에서 낮은 처리량과 현대 GPU 서빙 프레임워크에 비해 약한 GPU 확장성입니다.
# macOS with Homebrew
brew install llama.cpp
# Or build from source
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
make
# Using Hugging Face CLI (recommended)
llama-cli -hf unsloth/Qwen3-Coder-Next-GGUF:UD-Q4_K_XL
# Or download manually from:
# https://huggingface.co/unsloth/Qwen3-Coder-Next-GGUF
llama-server \
-hf unsloth/Qwen3-Coder-Next-GGUF:UD-Q4_K_XL \
--fit on \
--seed 3407 \
--temp 1.0 \
--top-p 0.95 \
--min-p 0.01 \
--top-k 40 \
--jinja \
--port 8080
Ollama는 추론 백엔드(종종 llama.cpp)를 간단한 “pull and run” 워크플로우로 감싸는 초보자 친화적인 LLM 런타임 및 서빙 프레임워크입니다. 장점은 매우 간단한 설치, 자동 모델 관리, 즉시 사용 가능한 로컬 API 서버입니다. 단점은 저수준 추론 파라미터에 대한 제어 감소, 튜닝의 유연성 부족, Ollama 모델 패키징 생태계에 대한 의존성입니다.
# Install Ollama
curl -fsSL https://ollama.com/install.sh | sh
# Pull and run the model
ollama pull qwen3-coder-next
ollama run qwen3-coder-next
vLLM은 효율적인 KV 캐시 관리(PagedAttention)를 기반으로 높은 처리량과 다중 사용자 동시성을 위해 최적화된 프로덕션 등급 GPU 추론 및 서빙 프레임워크입니다. 장점은 뛰어난 서빙 성능, GPU 간 강력한 확장성, 성숙한 배포 기능입니다. 단점은 높은 시스템 복잡성, 더 무거운 GPU/VRAM 요구 사항, CPU 전용 환경에 부적합함입니다.
# Install vLLM
pip install 'vllm>=0.15.0'
# Start server
vllm serve Qwen/Qwen3-Coder-Next \
--port 8000 \
--tensor-parallel-size 2 \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder
SGLang은 고속 디코딩과 복잡한 실행 파이프라인, 특히 도구 호출 및 에이전트 스타일 워크플로우에 최적화된 고성능 LLM 추론 및 서빙 프레임워크입니다. 장점은 적극적인 성능 최적화와 고급 다단계 생성 파이프라인에 대한 강력한 지원입니다. 단점은 더 높은 설정 복잡성, vLLM에 비해 덜 성숙한 생태계, 최상의 결과를 위한 GPU 인프라에 대한 더 높은 의존성입니다.
# Install SGLang
pip install 'sglang[all]>=v0.5.8'
# Launch server
python -m sglang.launch_server \
--model Qwen/Qwen3-Coder-Next \
--port 30000 \
--tp-size 2 \
--tool-call-parser qwen3_coder
방법 4: 코드 에이전트 도구와 통합
공식 커넥터와 단계별 통합 가이드를 통해 Claude code, Cursor, Trae, Continue, Codex, OpenCode, AnythingLLM, LangChain, Dify 및 Langflow와 같은 파트너 플랫폼에 Novita AI를 쉽게 연결하세요.
비용 제어와 무제한 사용을 우선시하는 팀의 경우, 양자화 추론을 위한 35-46GB VRAM 요구 사항으로 RTX 5090, AMD Instinct GPU 또는 64GB MacBook에서 모델을 실행할 수 있습니다. 로컬 배포와 API 배포 사이의 선택은 사용 패턴에 달려 있습니다: 지속적인 개발 작업은 설정 복잡성에도 불구하고 로컬 배포를 선호하는 반면, 간헐적 사용 사례는 서버리스 액세스의 이점을 누릴 수 있습니다. 모델이 성숙해지고 양자화 기술이 향상됨에 따라 로컬 및 호스팅 성능 간의 격차는 계속 좁혀지고 있어, Qwen3-Coder-Next는 독점 코딩 어시스턴트의 대안을 찾는 개발자에게 실행 가능한 옵션이 되고 있습니다.
자주 묻는 질문
Qwen3-Coder-Next를 로컬에서 실행하려면 어떤 하드웨어가 필요한가요?
4비트 양자화를 위해 35-46GB VRAM이 필요하며, 이는 RTX 5090, AMD Radeon 7900 XTX, AMD Instinct GPU 또는 통합 메모리가 있는 64GB MacBook으로 달성 가능합니다. 전체 정밀도에는 85-95GB VRAM이 필요합니다.
Qwen3-Coder-Next의 성능은 더 큰 모델과 비교하여 어떤가요?
에이전트 코딩 벤치마크에서 DeepSeek-V3.2와 같은 10-20배 더 많은 활성 파라미터를 가진 모델을 능가하며, SWE-Bench Verified에서 74.2%, Aider에서 69.9%를 달성합니다.
Qwen3-Coder-Next의 권장 생성 설정은 무엇인가요?
최적의 코드 생성을 위해 temperature=1.0, top_p=0.95, top_k=40, min_p=0.01을 사용하세요. 이 설정은 품질을 유지하면서 빠른 응답을 위한 비추론 모드를 활성화합니다.
Novita AI는 개발자가 간단한 API를 사용하여 AI 모델을 쉽게 배포할 수 있도록 하고, 구축 및 확장을 위한 저렴하고 안정적인 GPU 클라우드를 제공하는 AI 클라우드 플랫폼입니다.
추천 읽을거리



