

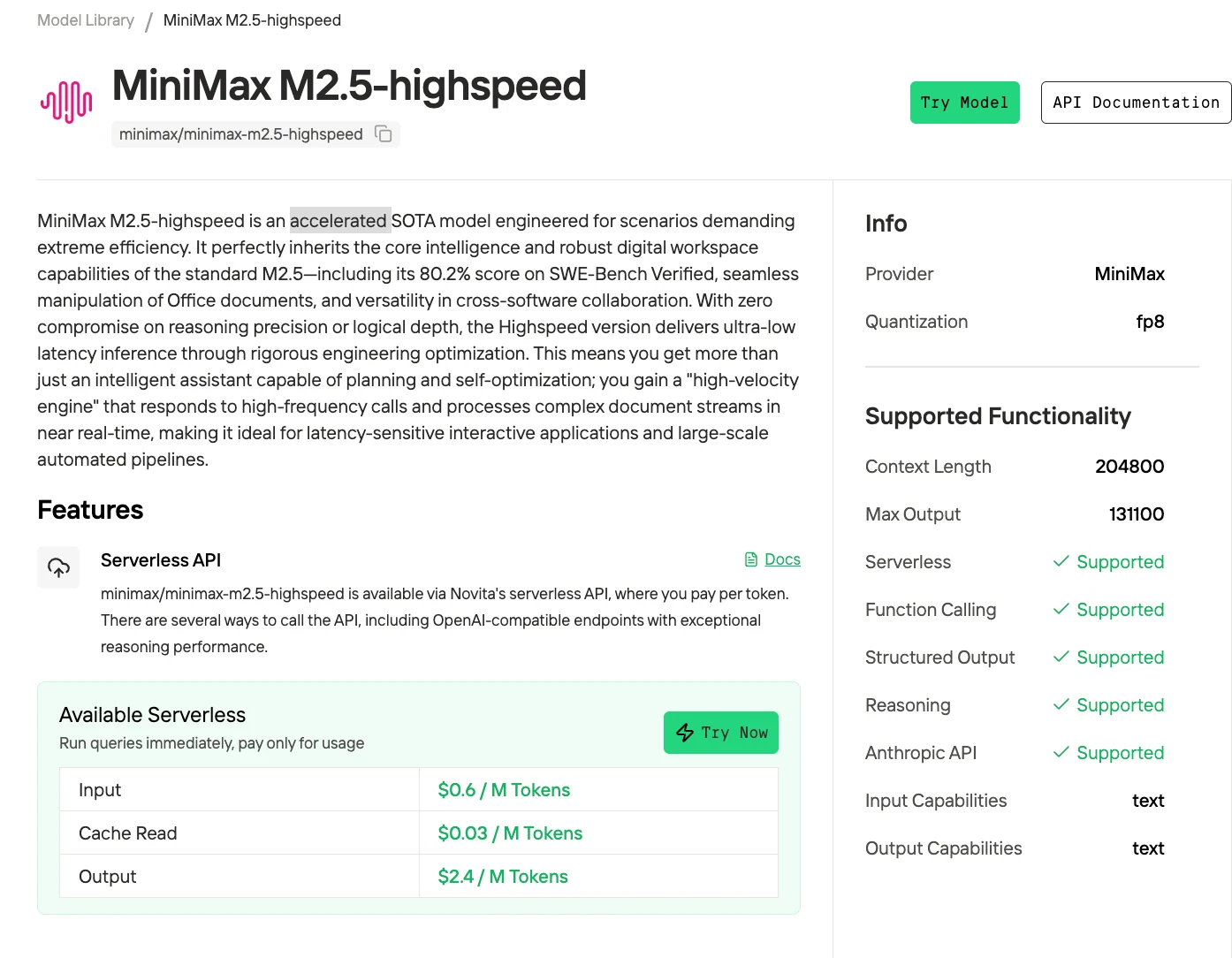
MiniMax M2.5는 2,290억 개의 파라미터를 가진 희소 혼합 전문가(Sparse Mixture-of-Experts) 모델로, 대규모임에도 불구하고 효율적인 추론이 가능합니다. 중국 AI 기업 MiniMax에서 출시한 이 모델은 자율 코딩 및 웹 탐색 작업에서 오픈소스 모델 중 최상위권을 차지하며, SWE-Bench Verified에서 80.2%, BrowseComp에서 76.3%를 달성했습니다.
Novita는 이전 버전의 강력한 성능을 유지하면서 속도를 크게 향상시킨 가속 모델을 제공합니다.
접근 방식 비교
| 방식 | 설정 시간 | 비용 (일 1M 토큰 기준) | 적합한 용도 |
|---|---|---|---|
| 웹 플레이그라운드 | 0분 | 무료 (속도 제한 있음) | 첫 평가, 일회성 작업 |
| Novita AI API | 2분 | 입력: $0.3 /Mt 캐시 읽기: $0.03 /Mt 출력: $1.2 /Mt |
프로덕션 앱, 중간 규모, 빠른 프로토타이핑 |
| NovitaClaw | 5분 | 입력: $0.3 /Mt 캐시 읽기: $0.03 /Mt 출력: $1.2 /Mt |
터미널 자동화, DevOps 워크플로우 |
| Claude Code | 5분 | 입력: $0.3 /Mt 캐시 읽기: $0.03 /Mt 출력: $1.2 /Mt |
코드베이스 탐색, IDE 통합 |
| 로컬 (Q4_K_M) | 30~60분 | 일회성 투자: $60,000~$90,000 | 대량 프로덕션, 데이터 프라이버시 요구 사항 |
| 클라우드 GPU | 5분 | 8x GPU $11.60/시간 | 단기 실험, 버스트 워크로드, 대규모 모델 테스트 |
1. 웹 플레이그라운드
가장 빠른 진입 장벽 없는 방법은 Novita AI의 웹 플레이그라운드입니다. 회원가입, API 키, 즉시 평가가 필요 없습니다. API 통합이나 로컬 배포에 투자하기 전에 빠른 기능 테스트에 가장 적합합니다.
일반적인 사용 사례: 프롬프트 엔지니어링, 품질 평가, 코딩 작업 테스트, 다른 모델과의 출력 비교. 웹 플레이그라운드는 첫 평가와 일회성 작업에 이상적입니다. 기술 설정이 필요 없습니다.
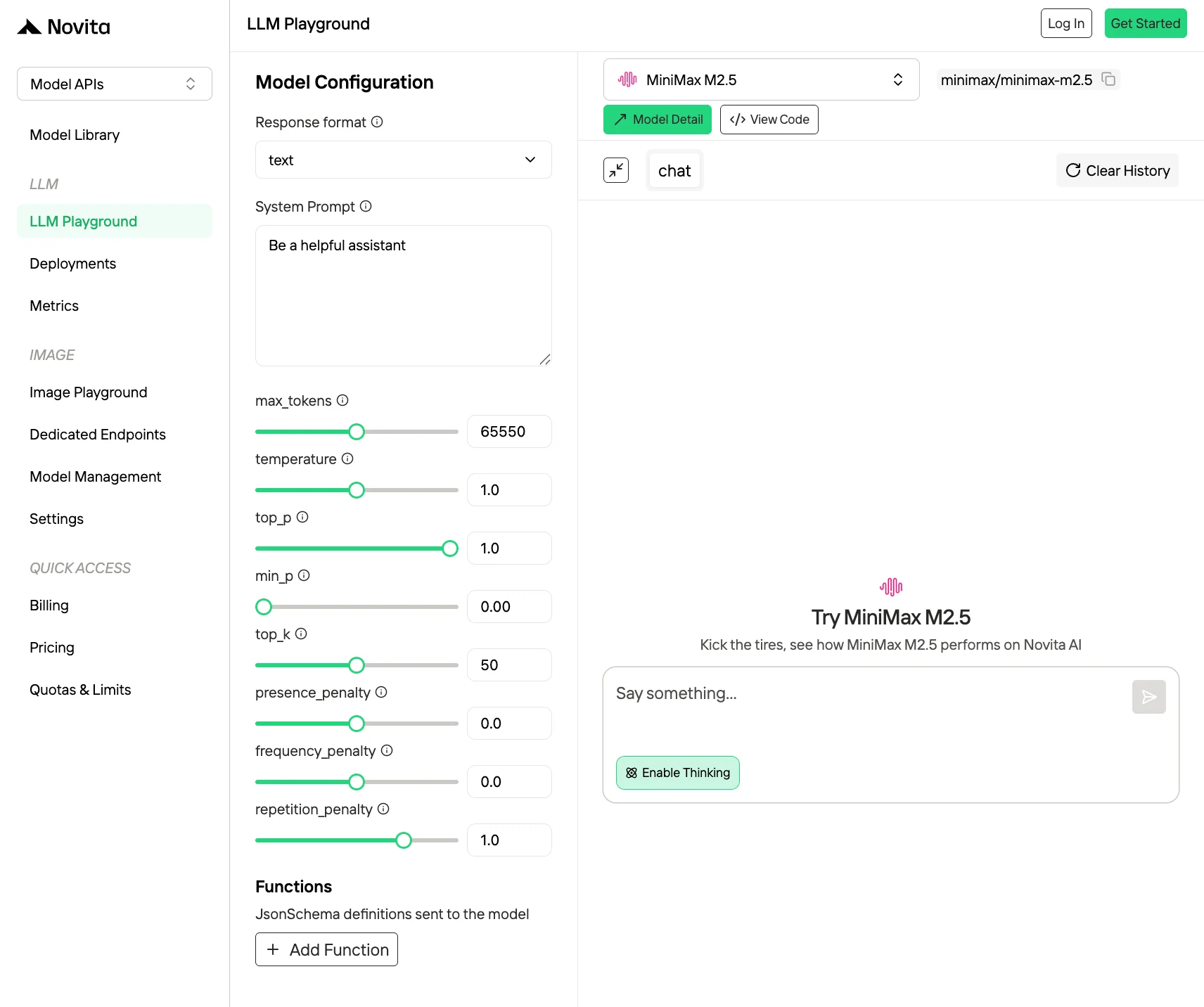
2. Novita AI API (대부분의 개발자에게 권장)
Novita AI API를 선택해야 하는 이유
- OpenAI 호환 및 Anthropic 호환
- 경쟁력 있는 가격: 1M 토큰당 $0.30/$1.20.
- 캐시 가격 지원: 캐시 가격을 통해 이전에 저장한 프롬프트를 재사용하여 반복 계산을 줄이고 전체 비용을 낮출 수 있습니다.
설정 가이드
1단계: 로그인 및 모델 라이브러리 접근
계정에 로그인하고 모델 라이브러리 버튼을 클릭합니다.

2단계: 모델 선택
사용 가능한 옵션 중 필요에 맞는 모델을 선택합니다.

3단계: 무료 체험 시작
선택한 모델의 기능을 탐색하려면 무료 체험을 시작하세요.
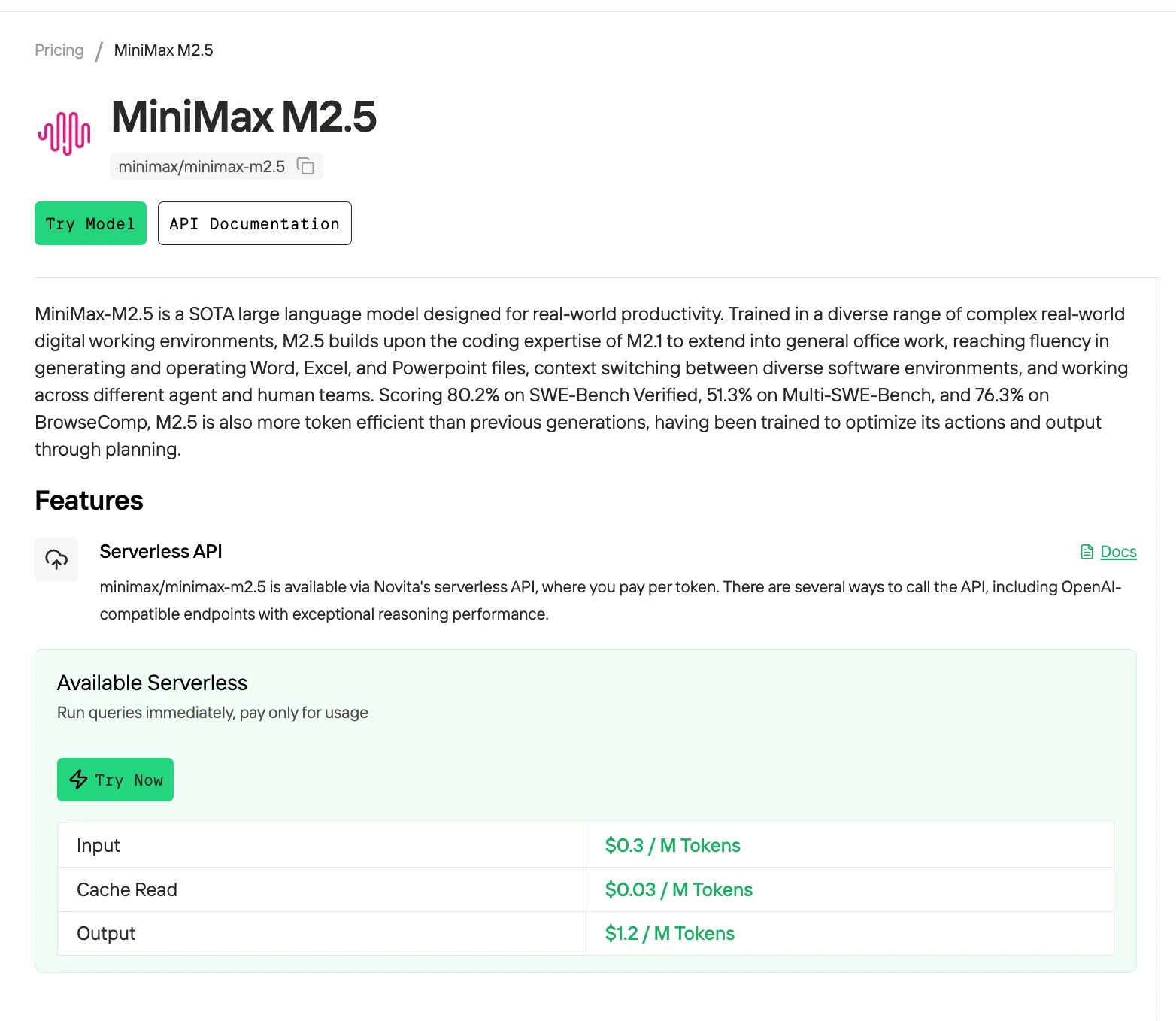
4단계: API 키 받기
API 인증을 위해 새로운 API 키를 제공합니다. “설정” 페이지로 이동하여 이미지에 표시된 대로 API 키를 복사합니다.

5단계: API 설치
프로그래밍 언어에 맞는 패키지 매니저를 사용하여 API를 설치합니다.
설치 후 개발 환경에 필요한 라이브러리를 가져옵니다. API 키로 API를 초기화하여 Novita AI LLM과 상호작용을 시작합니다. 다음은 Python 사용자를 위한 채팅 완성 API 사용 예제입니다.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="minimax/minimax-m2.5",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131100,
temperature=0.7
)
print(response.choices[0].message.content)
3. 코드 도구 접근
NovitaClaw
NovitaClaw는 Novita Agent Sandbox에서 영구적인 OpenClaw 에이전트를 배포하고 관리하기 위한 명령줄 도구입니다. 단일 명령으로 지속적으로 실행되는 완전히 호스팅된 에이전트 인스턴스를 시작할 수 있습니다. 세션 제한이나 수동 재시작이 필요 없습니다. 배포 후에는 CLI, 웹 기반 UI 또는 외부 자동화 스크립트 등 여러 인터페이스를 통해 에이전트에 접근하고 제어할 수 있습니다.
시작하기
전제 조건
시작하기 전에 다음이 준비되어 있는지 확인하세요:
- Python 설치
- Novita API 키 (키 관리에서 생성 또는 관리)
1단계: NovitaClaw 설치
macOS / Linux:
sudo pip3 install novitaclaw
Windows PowerShell:
pip install novitaclaw
확인: novitaclaw --help를 실행합니다. 명령 목록이 나타나면 설치가 성공한 것입니다.
2단계: API 키 설정
macOS / Linux:
export NOVITA_API_KEY=sk_your_api_key
Windows PowerShell:
$env:NOVITA_API_KEY = "sk_your_api_key"
3단계: 인스턴스 시작
novitaclaw launch
성공하면 CLI가 다음을 반환합니다:
- Web UI URL — 에이전트와 채팅
- Gateway WebSocket URL 및 토큰 — 프로그래매틱 접근용
- Web Terminal URL — 브라우저 기반 터미널 접근
- File Manager URL — 작업 공간 파일 관리
- 로그인 자격 증명 — Web Terminal 및 File Manager용
Web UI URL을 열고 Chat 탭으로 이동하여 에이전트 사용을 시작합니다.
모델 구성
인스턴스는 기본적으로 Novita 호스팅 모델로 사전 구성되어 있습니다. 사용자 지정하려면:
**Settings → Config → Raw (JSON5 view)**로 이동합니다.
**“secrets redacted”**를 클릭하여 전체 구성을 확인합니다.
1단계: 모델 등록
models.providers.novita.models 아래에 새 항목을 추가합니다:
{
"models": {
"providers": {
"novita": {
"models": [
{
"id": "model-id",
"name": "display name",
"reasoning": true,
"input": ["text"],
"contextWindow": 200000,
"maxTokens": 50000
}
]
}
}
}
}
2단계: 기본 모델 또는 대체 모델로 설정
agents.defaults를 업데이트합니다:
{
"agents": {
"defaults": {
"model": {
"primary": "novita/model-id",
"fallbacks": ["novita/fallback-model-id"]
}
}
}
}
Claude Code
Claude Code는 Anthropic의 공식 CLI 에이전트로, 주로 Claude 모델용으로 설계되었지만 Novita AI와 같은 Anthropic API 호환 엔드포인트와도 호환됩니다. 전체 리포지토리 분석, 복잡한 디버깅 및 에이전틱 코딩 루프에 탁월합니다.
설정:
- Claude Code 설치:
#macOS, Linux, WSL:
curl -fsSL https://claude.ai/install.sh | bash
#Windows PowerShell:
irm https://claude.ai/install.ps1 | iex
#Windows CMD:
curl -fsSL https://claude.ai/install.cmd -o install.cmd && install.cmd && del install.cmd
#Windows requires Git for Windows. Install it first if you don’t have it.
- 환경 변수 설정:
# Set the Anthropic SDK compatible API endpoint provided by Novita.
export ANTHROPIC_BASE_URL="https://api.novita.ai/anthropic"
export ANTHROPIC_AUTH_TOKEN="<Novita API Key>"
# Set the model provided by Novita.
export ANTHROPIC_MODEL="minimax/minimax-m2.5"
export ANTHROPIC_SMALL_FAST_MODEL="minimax/minimax-m2.5"
- 프로젝트에서 Claude Code 시작:
cd /path/to/project
claude .
적합한 용도: 코드베이스 탐색, 다단계 디버깅, 자율 기능 구현, 터미널 플러그인을 통한 VSCode/Cursor 통합.
4. 로컬 배포
MiniMax M2.5의 희소 MoE 아키텍처(총 229B, 활성 10B)는 고급 소비자 하드웨어 또는 멀티 GPU 설정에서 로컬 배포를 가능하게 합니다. 이 모델은 전체 BF16 정밀도에서 457GB가 필요하지만 Unsloth의 GGUF 양자화를 통해 Dynamic 3비트는 101GB, Q4_K_M은 138GB로 줄일 수 있습니다.
하드웨어 요구 사항
| 양자화 | 필요 VRAM | 하드웨어 예시 |
|---|---|---|
| BF16 (전체 정밀도) | 457GB | 6× H100 80GB |
| Q8_0 | 243GB | 4× H100 80GB |
| Q6_K | 188GB | 3× H100 80GB |
| Q4_K_M (권장) | 138GB | 2× H100 80GB |
| Q3_K_M | 109GB | 2× H100 80GB |
| UD-IQ2_XXS (최소) | 74GB | 단일 H100 80GB |
설치 (llama.cpp)
git clone https://github.com/ggml-org/llama.cpp.git
cd llama.cpp
cmake -B build -DCMAKE_BUILD_TYPE=Release
cmake --build build -j"$(nproc)"
# Install HF CLI if needed
pip install -U "huggingface_hub[cli]"
# Download a specific quant (example: Q3_K_M)
hf download unsloth/MiniMax-M2.5-GGUF \
--include "Q3_K_M/*" \
--local-dir ./models
# Check files
find ./models -name "*.gguf"
# Run (use the FIRST shard)
./build/bin/llama-cli \
-m ./models/Q3_K_M/MiniMax-M2.5-Q3_K_M-00001-of-00004.gguf \
-p "Write a Python function to check if a number is prime"
클라우드 GPU 설치 (비용 효율적으로)
1단계: 계정 등록
웹사이트를 통해 Novita AI 계정을 만드세요. 등록 후 왼쪽 사이드바에서 “Explore” 섹션으로 이동하여 GPU 상품을 확인하고 AI 개발 여정을 시작하세요.

2단계: 템플릿 및 GPU 서버 탐색
프로젝트 요구 사항에 맞는 PyTorch, TensorFlow 또는 CUDA 템플릿을 선택하세요. 그런 다음 원하는 GPU 구성을 선택하세요. L40S, RTX 4090 또는 A100 SXM4 등 각각 다른 VRAM, RAM, 스토리지 사양을 제공합니다.
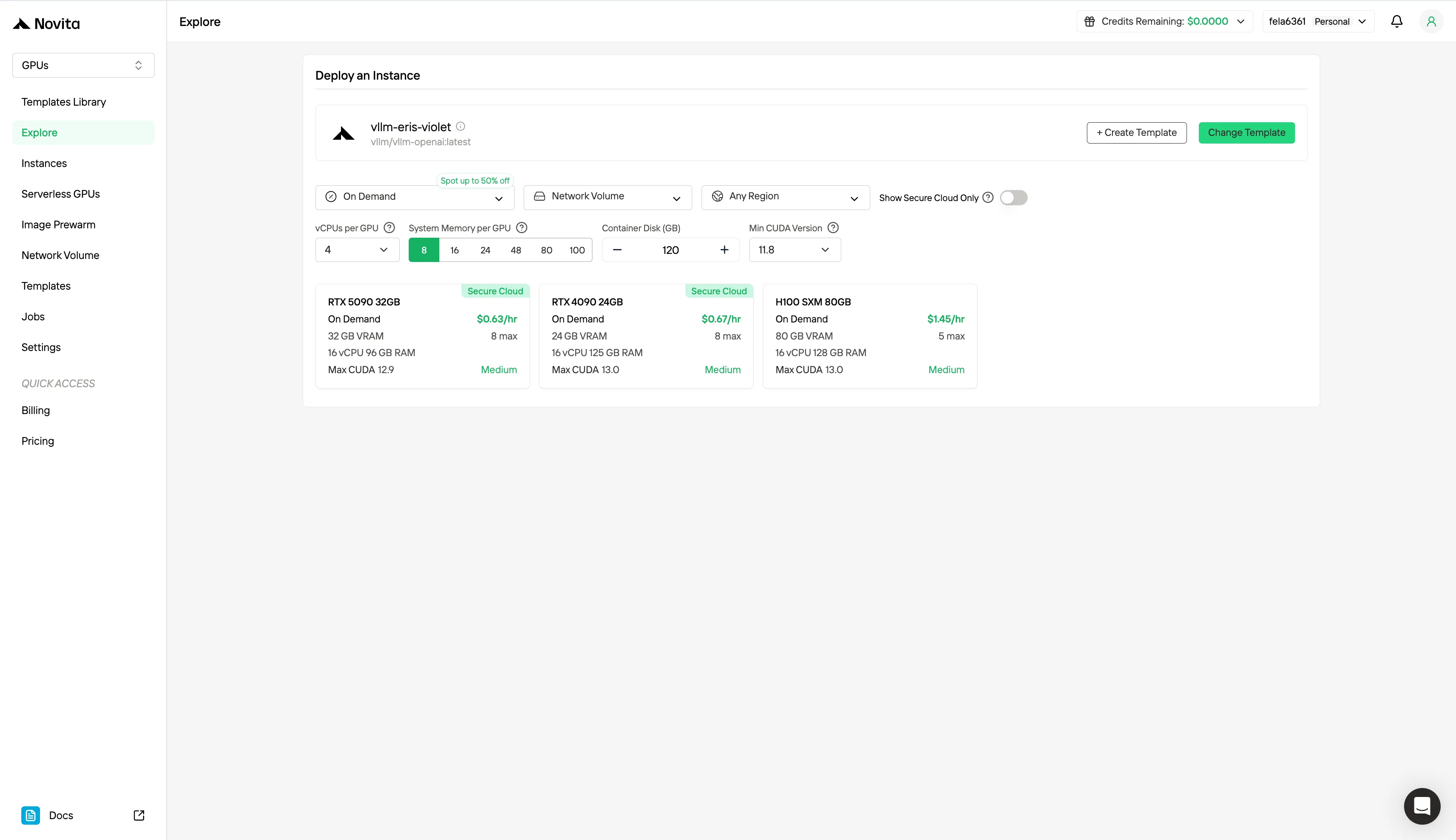
3단계: 배포 맞춤 설정
선호하는 운영 체제와 구성 옵션을 선택하여 특정 AI 워크로드 및 개발 요구 사항에 최적의 성능을 보장하도록 환경을 맞춤 설정하세요.
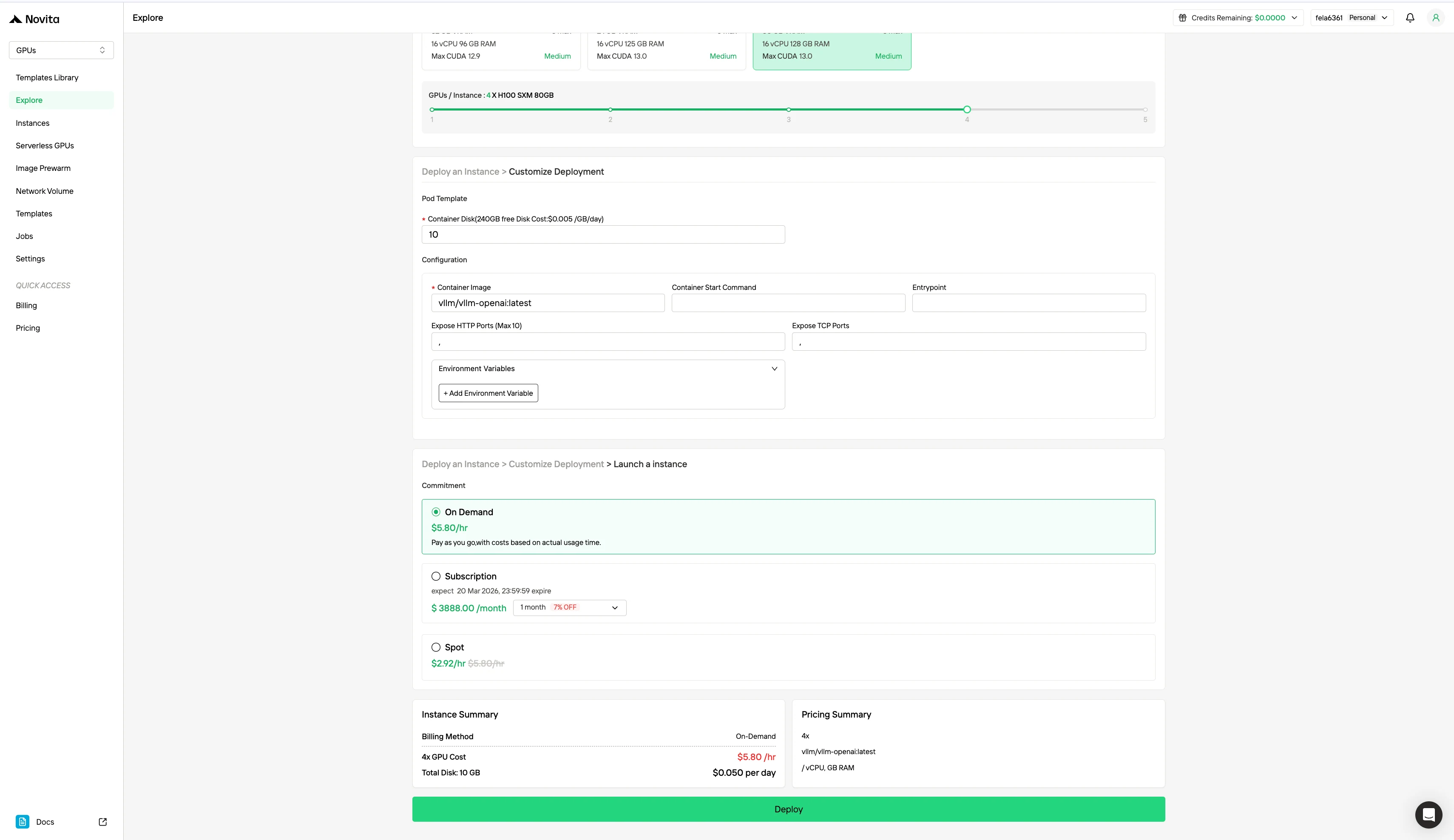
| 사양 | 청구 방식 | GPU | 가격 |
|---|---|---|---|
| H100 80 GB VRAM | 온디맨드 | 1x GPU | $1.45/시간 |
| 8x GPU | $11.60/시간 | ||
| 스팟 | 1x GPU | $0.73/시간 | |
| 8x GPU | $5.84/시간 |
Novita AI의 스팟 인스턴스는 플랫폼의 유휴 또는 미사용 GPU 용량을 활용하는 비용 최적화 GPU 임대 시스템입니다. 전용 하드웨어를 예약하여 안정적인 지속 사용을 제공하는 온디맨드 인스턴스와 달리 스팟 인스턴스는 중단 가능합니다. GPU가 시스템에 의해 회수되면 작업이 일시 중지되거나 종료될 수 있습니다. 스팟 모드는 유휴 GPU 리소스를 재할당하기 때문에 일반적으로 온디맨드 가격보다 40~60% 저렴합니다.
MiniMax M2.5는 각각 다른 시나리오에 최적화된 네 가지 실용적인 접근 경로를 제공합니다. 대부분의 개발자에게는 1백만 토큰당 $0.30/$1.20의 Novita AI API가 프로덕션으로 가는 가장 빠른 경로입니다. 설정 시간은 2분이며 OpenAI SDK 호환성을 제공합니다. 웹 플레이그라운드는 첫 평가에 적합하고, OpenClaw CLI와 Claude Code는 고급 사용자를 위한 터미널 통합 에이전틱 워크플로우를 제공합니다. 자체 호스팅은 하루 1천만 토큰 이상이거나 엄격한 데이터 프라이버시 요구 사항으로 클라우드 API를 사용할 수 없는 경우에 경제적 의미가 있습니다. 이 경우 2× H100 80GB에서 Q4_K_M 양자화로 프로덕션 수준 성능을 제공합니다.
자주 묻는 질문
MiniMax M2.5가 다른 코딩 모델과 다른 점은 무엇인가요?
MiniMax M2.5는 희소 MoE 아키텍처를 사용하여 총 2,290억 개의 파라미터 중 토큰당 10억 개만 활성화하며, SWE-Bench Verified에서 80.2%를 달성하면서 Claude Sonnet 4.5 비용의 8%에 불과합니다.
단일 소비자 GPU에서 MiniMax M2.5를 실행할 수 있나요?
아니요 — 공격적인 양자화를 적용해도 최소 VRAM 요구 사항은 74GB입니다.
MiniMax M2.5는 함수 호출과 구조화된 출력을 지원하나요?
예 — MiniMax M2.5는 OpenAI 호환 API 형식을 통해 함수 호출을 지원합니다.
Novita AI는 개발자와 스타트업이 고성능, 신뢰성, 비용 효율성으로 모델과 에이전트 애플리케이션을 구축, 배포, 확장할 수 있도록 지원하는 AI 및 에이전트 클라우드 플랫폼입니다.
추천 읽을거리



