

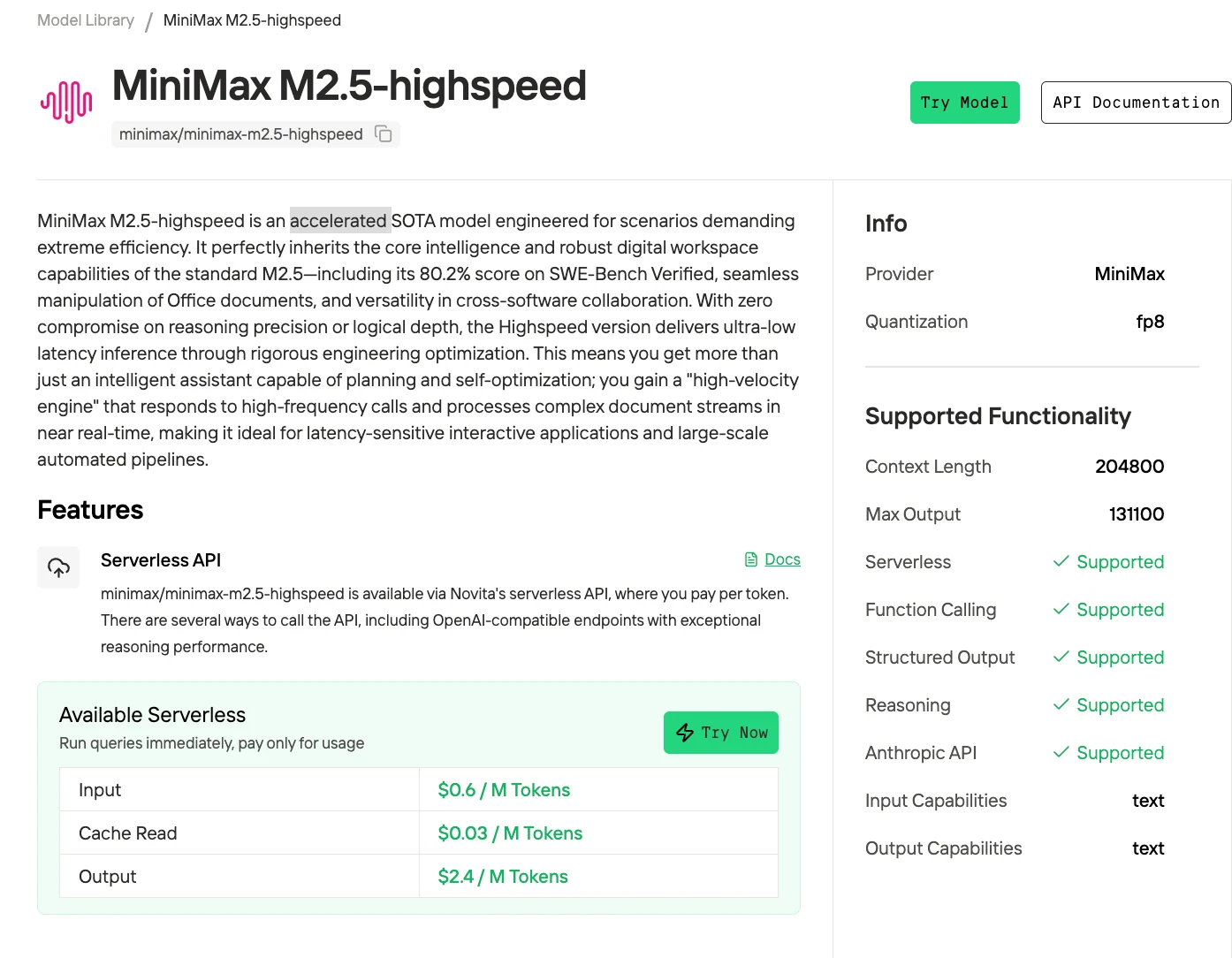
MiniMax M2.5 est un modèle sparse de mélange d’experts (MoE) de 229 milliards de paramètres, permettant une inférence efficace malgré sa taille. Développé par l’entreprise chinoise d’IA MiniMax, il figure parmi les meilleurs modèles open source pour les tâches de codage autonome et de navigation web, atteignant 80,2 % sur SWE-Bench Verified et 76,3 % sur BrowseComp.
Novita propose un modèle accéléré qui conserve les performances élevées de la version précédente tout en améliorant significativement la vitesse.
Comparaison des méthodes d’accès
| Méthode | Temps de configuration | Coût (1M tokens/jour) | Idéal pour |
|---|---|---|---|
| Terrain de jeu Web | 0 minute | Gratuit (limité en débit) | Évaluation initiale, tâches ponctuelles |
| API Novita AI | 2 minutes | Entrée : 0,3 $ /Mt Lecture de cache : 0,03 $ /Mt Sortie : 1,2 $ /Mt |
Applications en production, volume modéré, prototypage rapide |
| NovitaClaw | 5 minutes | Entrée : 0,3 $ /Mt Lecture de cache : 0,03 $ /Mt Sortie : 1,2 $ /Mt |
Automatisation terminal, workflows DevOps |
| Claude Code | 5 minutes | Entrée : 0,3 $ /Mt Lecture de cache : 0,03 $ /Mt Sortie : 1,2 $ /Mt |
Exploration de base de code, intégration IDE |
| Local (Q4_K_M) | 30 à 60 minutes | Investissement unique : 60 000 à 90 000 $ | Production à haut volume, exigences de confidentialité des données |
| GPU Cloud | 5 minutes | 8x GPU 11,60 $/h | Expériences à court terme, charges de travail en rafale, test de grands modèles |
1. Terrain de jeu Web
Le point d’entrée le plus rapide et sans barrière est le terrain de jeu Web de Novita AI : pas d’inscription, pas de clés API, évaluation instantanée. Il est idéal pour tester rapidement les capacités du modèle avant de s’engager dans une intégration API ou un déploiement local.
Cas d’usage typiques : Ingénierie de prompts, évaluation de la qualité, test de tâches de codage, comparaison des sorties avec d’autres modèles côte à côte. Le terrain de jeu Web est idéal pour une première évaluation et des tâches ponctuelles, aucune configuration technique n’est requise.
Essayez MiniMax M2.5 dès maintenant !
2. API Novita AI (Recommandée pour la plupart des développeurs)
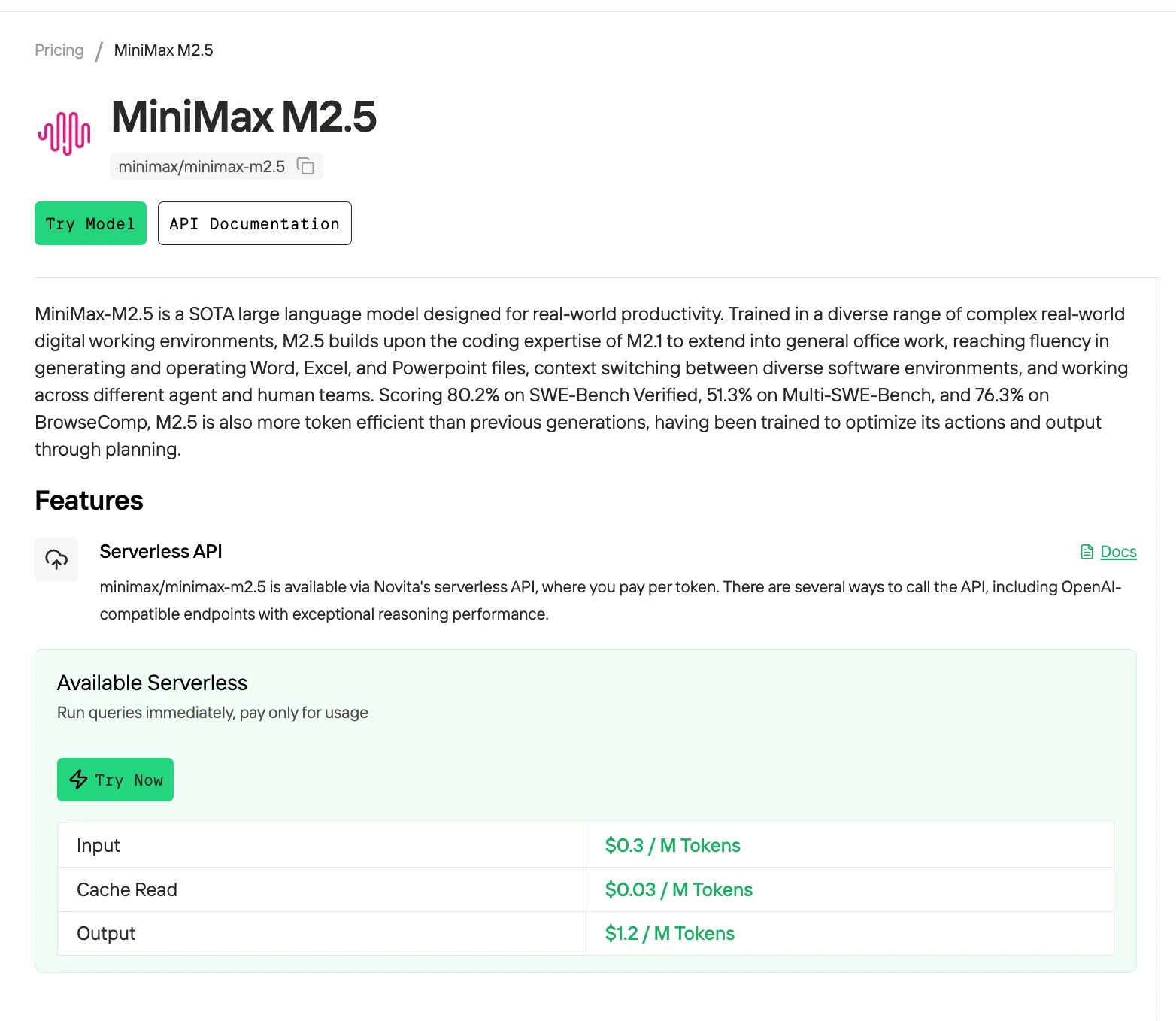
Pourquoi choisir l’API Novita AI ?
- Compatible OpenAI et Anthropic
- Tarification compétitive : 0,30 $ / 1,2 $ par million de tokens.
- Prise en charge de la tarification de cache : La tarification de cache vous permet de réutiliser des prompts précédemment enregistrés, ce qui réduit les calculs répétés et abaisse les coûts globaux.
Guide de configuration
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Bibliothèque de modèles.

Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.

Étape 3 : Démarrez votre essai gratuit
Commencez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Essayez MiniMax M2.5 à prix abordable dès maintenant !
Étape 4 : Récupérez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. En accédant à la page « Paramètres », vous pouvez copier la clé API comme indiqué sur l’image.

Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.
Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec le LLM de Novita AI. Voici un exemple d’utilisation de l’API de complétion de chat pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="minimax/minimax-m2.5",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131100,
temperature=0.7
)
print(response.choices[0].message.content)
3. Accès aux outils de code
NovitaClaw
NovitaClaw est un outil en ligne de commande permettant de déployer et de gérer des agents OpenClaw persistants sur le bac à sable d’agents Novita. Avec une seule commande, vous pouvez lancer une instance d’agent entièrement hébergée qui fonctionne en continu, sans limites de session ni redémarrages manuels nécessaires. Une fois déployé, l’agent est accessible et contrôlable via plusieurs interfaces, notamment le CLI, une interface Web ou des scripts d’automatisation externes.
Prise en main
Prérequis
Avant de commencer, assurez-vous de disposer de :
- Python installé
- Une clé API Novita (créez ou gérez vos clés dans la section Gestion des clés)
Étape 1 : Installez NovitaClaw
macOS / Linux :
sudo pip3 install novitaclaw
PowerShell Windows :
pip install novitaclaw
Vérification : exécutez novitaclaw --help. Si vous voyez une liste de commandes, l’installation a réussi.
Étape 2 : Définissez votre clé API
macOS / Linux :
export NOVITA_API_KEY=sk_your_api_key
PowerShell Windows :
$env:NOVITA_API_KEY = "sk_your_api_key"
Étape 3 : Lancez votre instance
novitaclaw launch
En cas de succès, le CLI renvoie :
- URL de l’interface Web — Discutez avec votre agent
- URL et jeton de la passerelle WebSocket — Pour un accès programmatique
- URL du terminal Web — Accès au terminal depuis le navigateur
- URL du gestionnaire de fichiers — Gérez les fichiers de l’espace de travail
- Identifiants de connexion — Pour le terminal Web et le gestionnaire de fichiers
Ouvrez l’URL de l’interface Web, allez dans l’onglet Chat et commencez à utiliser votre agent.
Configuration des modèles
Votre instance est préconfigurée par défaut avec un modèle hébergé par Novita. Pour la personnaliser :
Accédez à :
Paramètres → Config → Vue brute (JSON5)
Cliquez sur « secrets redacted » pour afficher la configuration complète.
Étape 1 : Enregistrez un modèle
Ajoutez une nouvelle entrée sous models.providers.novita.models :
{
"models": {
"providers": {
"novita": {
"models": [
{
"id": "model-id",
"name": "display name",
"reasoning": true,
"input": ["text"],
"contextWindow": 200000,
"maxTokens": 50000
}
]
}
}
}
}
Étape 2 : Définissez comme principal ou de secours
Mettez à jour agents.defaults :
{
"agents": {
"defaults": {
"model": {
"primary": "novita/model-id",
"fallbacks": ["novita/fallback-model-id"]
}
}
}
}
Claude Code
Claude Code est l’agent CLI officiel d’Anthropic, principalement conçu pour les modèles Claude mais compatible avec des endpoints compatibles avec l’API Anthropic comme Novita AI. Il excelle dans l’analyse de dépôts entiers, le débogage complexe et les boucles de codage agentiques.
Configuration :
- Installez Claude Code :
#macOS, Linux, WSL:
curl -fsSL https://claude.ai/install.sh | bash
#Windows PowerShell:
irm https://claude.ai/install.ps1 | iex
#Windows CMD:
curl -fsSL https://claude.ai/install.cmd -o install.cmd && install.cmd && del install.cmd
#Windows requires Git for Windows. Install it first if you don’t have it.
- Définissez les variables d’environnement :
# Set the Anthropic SDK compatible API endpoint provided by Novita.
export ANTHROPIC_BASE_URL="https://api.novita.ai/anthropic"
export ANTHROPIC_AUTH_TOKEN="<Novita API Key>"
# Set the model provided by Novita.
export ANTHROPIC_MODEL="minimax/minimax-m2.5"
export ANTHROPIC_SMALL_FAST_MODEL="minimax/minimax-m2.5"
- Démarrez Claude Code dans votre projet :
cd /path/to/project
claude .
Idéal pour : Exploration de base de code, débogage multi-étapes, implémentation autonome de fonctionnalités, intégration avec VSCode/Cursor via des plugins de terminal.
4. Déploiement local
L’architecture MoE sparse de MiniMax M2.5 (229 milliards de paramètres au total, 10 milliards actifs) rend le déploiement local viable sur du matériel grand public haut de gamme ou des configurations multi-GPU. Le modèle nécessite 457 Go en précision BF16 complète, mais la quantification via les quantifications GGUF d’Unsloth réduit cette taille à 101 Go (3 bits dynamiques) ou 138 Go (Q4_K_M).
Exigences matérielles
| Quantification | VRAM nécessaire | Exemple de matériel |
|---|---|---|
| BF16 (précision complète) | 457 Go | 6× H100 80 Go |
| Q8_0 | 243 Go | 4× H100 80 Go |
| Q6_K | 188 Go | 3× H100 80 Go |
| Q4_K_M (recommandé) | 138 Go | 2× H100 80 Go |
| Q3_K_M | 109 Go | 2× H100 80 Go |
| UD-IQ2_XXS (minimum) | 74 Go | 1× H100 80 Go |
Installation (llama.cpp)
git clone https://github.com/ggml-org/llama.cpp.git
cd llama.cpp
cmake -B build -DCMAKE_BUILD_TYPE=Release
cmake --build build -j"$(nproc)"
# Install HF CLI if needed
pip install -U "huggingface_hub[cli]"
# Download a specific quant (example: Q3_K_M)
hf download unsloth/MiniMax-M2.5-GGUF \
--include "Q3_K_M/*" \
--local-dir ./models
# Check files
find ./models -name "*.gguf"
# Run (use the FIRST shard)
./build/bin/llama-cli \
-m ./models/Q3_K_M/MiniMax-M2.5-Q3_K_M-00001-of-00004.gguf \
-p "Write a Python function to check if a number is prime"
Installation sur GPU cloud (rentable)
Étape 1 : Créez un compte
Créez votre compte Novita AI via notre site web. Après l’inscription, accédez à la section « Explorer » dans la barre latérale gauche pour consulter nos offres de GPU et commencer votre parcours de développement IA.

Étape 2 : Exploration des modèles et des serveurs GPU
Choisissez parmi des modèles comme PyTorch, TensorFlow ou CUDA qui correspondent aux besoins de votre projet. Sélectionnez ensuite votre configuration GPU préférée : les options incluent les puissants L40S, RTX 4090 ou A100 SXM4, chacun avec des spécifications de VRAM, RAM et stockage différentes.
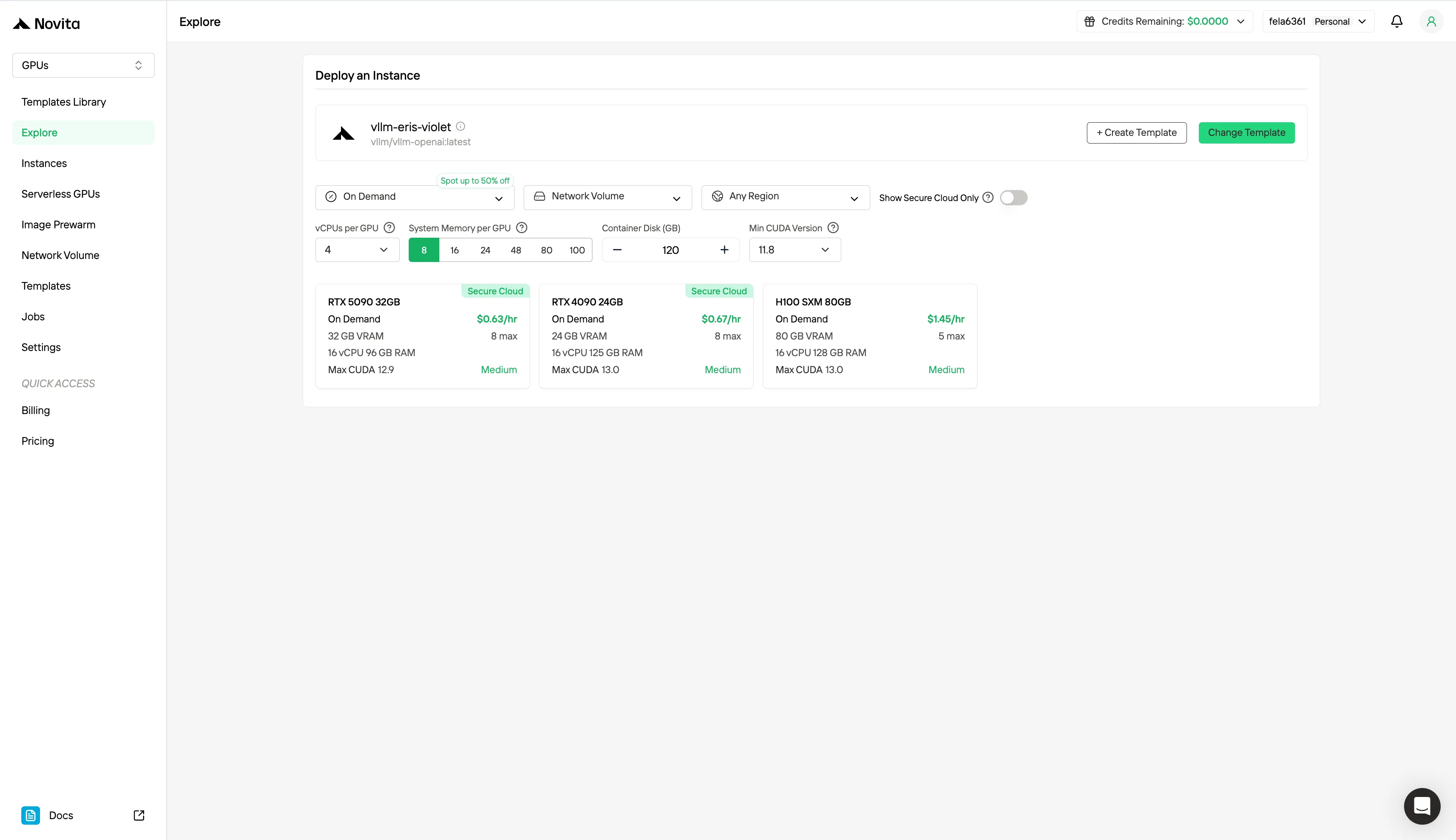
Étape 3 : Personnalisez votre déploiement
Personnalisez votre environnement en sélectionnant votre système d’exploitation préféré et les options de configuration pour garantir des performances optimales pour vos charges de travail IA spécifiques et vos besoins de développement.
| Spécification | Mode de facturation | GPU | Tarification |
|---|---|---|---|
| VRAM H100 80 Go | À la demande | 1x GPU | 1,45 $/h |
| 8x GPU | 11,60 $/h | ||
| Spot | 1x GPU | 0,73 $/h | |
| 8x GPU | 5,84 $/h |
Les instances Spot de Novita AI sont un système de location de GPU optimisé pour les coûts, qui exploite la capacité GPU inactive ou inutilisée de la plateforme. Contrairement aux instances à la demande, qui réservent du matériel dédié pour une utilisation stable et continue, les instances Spot sont interruptibles : votre tâche peut être mise en pause ou terminée si le GPU est récupéré par le système. Comme le mode Spot réalloue des ressources GPU autrement inactives, il est généralement 40 à 60 % moins cher que la tarification à la demande.
MiniMax M2.5 propose quatre voies d’accès pratiques, chacune optimisée pour des scénarios différents. Pour la plupart des développeurs, l’API Novita AI à 0,30 $ / 1,2 $ par million de tokens offre le chemin le plus rapide vers la production : la configuration ne prend que 2 minutes avec la compatibilité du SDK OpenAI. Le terrain de jeu Web est destiné à une première évaluation, tandis que le CLI OpenClaw et Claude Code permettent des workflows agentiques intégrés au terminal pour les utilisateurs avancés. L’auto-hébergement n’est économiquement pertinent qu’au-delà de 10 millions de tokens par jour ou lorsque des exigences strictes de confidentialité des données interdisent les API cloud : dans ce cas, la quantification Q4_K_M sur 2× H100 80 Go offre des performances prêtes pour la production.
Questions fréquemment posées
Qu’est-ce qui distingue MiniMax M2.5 des autres modèles de codage ?
MiniMax M2.5 utilise une architecture MoE sparse avec 229 milliards de paramètres au total mais seulement 10 milliards actifs par token, atteignant 80,2 % sur SWE-Bench Verified pour seulement 8 % du coût de Claude Sonnet 4.5.
Puis-je exécuter MiniMax M2.5 sur un seul GPU grand public ?
Non — l’exigence minimale de VRAM est de 74 Go même avec une quantification agressive.
MiniMax M2.5 prend-il en charge l’appel de fonctions et les sorties structurées ?
Oui — MiniMax M2.5 prend en charge l’appel de fonctions via le format d’API compatible OpenAI.
Novita AI est une plateforme cloud d’IA et d’agents qui aide les développeurs et les startups à créer, déployer et dimensionner des modèles et des applications agentiques avec des performances élevées, une fiabilité et une efficacité des coûts.
Lectures recommandées



