

O MiniMax M2.5 é um modelo esparso de Mistura de Especialistas (MoE) com 229 bilhões de parâmetros, que permite inferência eficiente apesar de sua escala. Lançado pela empresa chinesa de IA MiniMax, ele está entre os principais modelos de código aberto para tarefas de codificação autônoma e navegação na web, atingindo 80,2% no SWE-Bench Verified e 76,3% no BrowseComp.
A Novita oferece um modelo acelerado que mantém o forte desempenho da versão anterior, ao mesmo tempo que melhora significativamente a velocidade.
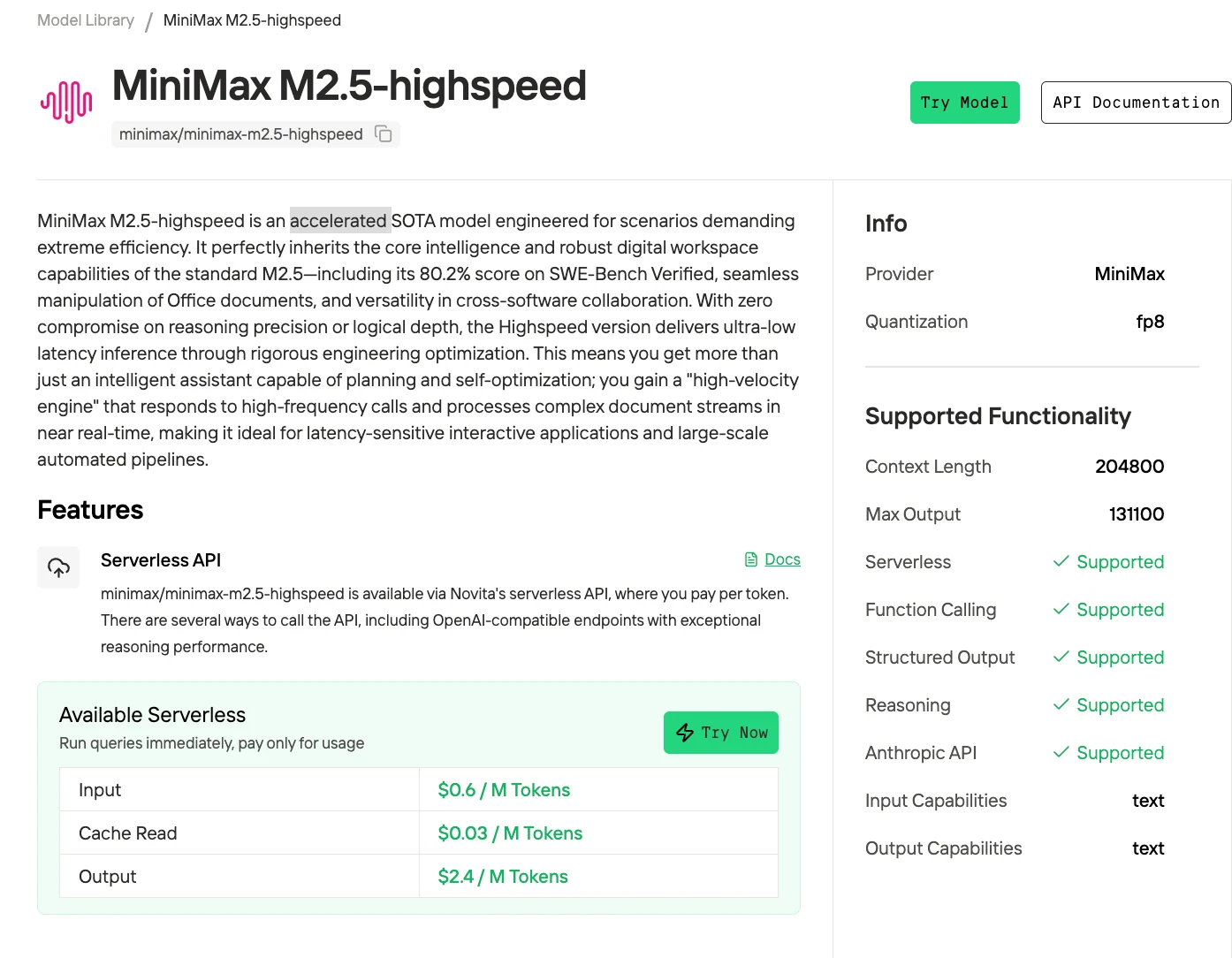
Comparação de Métodos de Acesso
| Método | Tempo de Configuração | Custo (1M tokens/dia) | Melhor Para |
|---|---|---|---|
| Playground Web | 0 minutos | Gratuito (com limite de taxa) | Avaliação inicial, tarefas pontuais |
| API Novita AI | 2 minutos | Entrada: $0,3 /Mt Leitura de Cache: $0,03 /Mt Saída: $1,2 /Mt |
Aplicativos de produção, volume moderado, prototipagem rápida |
| NovitaClaw | 5 minutos | Entrada: $0,3 /Mt Leitura de Cache: $0,03 /Mt Saída: $1,2 /Mt |
Automação de terminal, fluxos de trabalho DevOps |
| Claude Code | 5 minutos | Entrada: $0,3 /Mt Leitura de Cache: $0,03 /Mt Saída: $1,2 /Mt |
Exploração de base de código, integração com IDE |
| Local (Q4_K_M) | 30-60 minutos | Investimento único: $60.000–$90.000 | Produção de alto volume, requisitos de privacidade de dados |
| GPU em Nuvem | 5 minutos | 8x GPU $11,60/hora | Experimentos de curto prazo, cargas de trabalho em pico, testes de modelos grandes |
1. Playground Web
O ponto de entrada mais rápido e sem barreiras é o playground web da Novita AI: nenhum cadastro, nenhuma chave de API, avaliação instantânea. Ele funciona melhor para testes rápidos de capacidade antes de se comprometer com integração de API ou implantação local.
Casos de uso típicos: Engenharia de prompts, avaliação de qualidade, teste de tarefas de codificação, comparação de saídas com outros modelos lado a lado. O playground web é ideal para avaliação inicial e tarefas pontuais — nenhuma configuração técnica é necessária.
Experimente o MiniMax M2.5 Agora!
2. API Novita AI (Recomendada para a maioria dos desenvolvedores)
Por que escolher a API Novita AI?
- Compatível com OpenAI e com Anthropic
- Preços competitivos: $0,30/$1,20 por 1M de tokens.
- Suporte a Preços de Cache: O preço de cache permite reutilizar prompts salvos anteriormente, ajudando a reduzir computações repetidas e diminuir os custos gerais.
Guia de Configuração
Passo 1: Faça login e acesse a Biblioteca de Modelos
Faça login na sua conta e clique no botão Biblioteca de Modelos.

Passo 2: Escolha seu Modelo
Navegue pelas opções disponíveis e selecione o modelo que atende às suas necessidades.

Passo 3: Inicie seu Teste Gratuito
Comece seu teste gratuito para explorar as capacidades do modelo selecionado.
Experimente o MiniMax M2.5 Acessível Agora!
Passo 4: Obtenha sua Chave de API
Para autenticar com a API, forneceremos uma nova chave de API. Acessando a página “Configurações”, você pode copiar a chave de API conforme indicado na imagem.

Passo 5: Instale a API
Instale a API usando o gerenciador de pacotes específico da sua linguagem de programação.
Após a instalação, importe as bibliotecas necessárias para o seu ambiente de desenvolvimento. Inicialize a API com sua chave de API para começar a interagir com o LLM da Novita AI. Este é um exemplo de uso da API de conclusões de chat para usuários de Python.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="minimax/minimax-m2.5",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131100,
temperature=0.7
)
print(response.choices[0].message.content)
3. Acesso por Ferramentas de Código
NovitaClaw
O NovitaClaw é uma ferramenta de linha de comando para implantar e gerenciar agentes OpenClaw persistentes no Novita Agent Sandbox. Com um único comando, você pode iniciar uma instância de agente totalmente hospedada que roda continuamente — sem limites de sessão ou reinicializações manuais necessárias. Uma vez implantado, o agente pode ser acessado e controlado por meio de várias interfaces, incluindo CLI, interface web baseada em navegador ou scripts de automação externos.
Primeiros Passos
Pré-requisitos
Antes de começar, certifique-se de ter:
- Python instalado
- Uma chave de API Novita (crie ou gerencie chaves na Gestão de Chaves)
Passo 1: Instale o NovitaClaw
macOS / Linux:
sudo pip3 install novitaclaw
PowerShell do Windows:
pip install novitaclaw
Verificação: execute novitaclaw --help. Se você ver uma lista de comandos, a instalação foi bem-sucedida.
Passo 2: Defina sua Chave de API
macOS / Linux:
export NOVITA_API_KEY=sk_your_api_key
PowerShell do Windows:
$env:NOVITA_API_KEY = "sk_your_api_key"
Passo 3: Inicie sua Instância
novitaclaw launch
Em caso de sucesso, a CLI retorna:
- URL da Interface Web — Converse com seu agente
- URL e Token do WebSocket do Gateway — Para acesso programático
- URL do Terminal Web — Acesso a terminal baseado em navegador
- URL do Gerenciador de Arquivos — Gerencie arquivos do espaço de trabalho
- Credenciais de login — Para o Terminal Web e o Gerenciador de Arquivos
Abra a URL da Interface Web, vá para a aba Chat e comece a usar seu agente.
Configurando Modelos
Sua instância vem pré-configurada com um modelo hospedado na Novita por padrão. Para personalizá-la:
Acesse:
Configurações → Config → Visualização Raw (JSON5)
Clique em “secrets redacted” para revelar a configuração completa.
Passo 1: Registre um Modelo
Adicione uma nova entrada em models.providers.novita.models:
{
"models": {
"providers": {
"novita": {
"models": [
{
"id": "model-id",
"name": "display name",
"reasoning": true,
"input": ["text"],
"contextWindow": 200000,
"maxTokens": 50000
}
]
}
}
}
}
Passo 2: Defina como Primário ou Fallback
Atualize agents.defaults:
{
"agents": {
"defaults": {
"model": {
"primary": "novita/model-id",
"fallbacks": ["novita/fallback-model-id"]
}
}
}
}
Claude Code
O Claude Code é o agente CLI oficial da Anthropic, projetado principalmente para modelos Claude, mas compatível com endpoints compatíveis com a API Anthropic, como a Novita AI. Ele se destaca em análise de repositórios inteiros, depuração complexa e loops de codificação autônomos.
Configuração:
1. Instale o Claude Code:
#macOS, Linux, WSL:
curl -fsSL https://claude.ai/install.sh | bash
#Windows PowerShell:
irm https://claude.ai/install.ps1 | iex
#Windows CMD:
curl -fsSL https://claude.ai/install.cmd -o install.cmd && install.cmd && del install.cmd
#Windows requires Git for Windows. Install it first if you don’t have it.
2. Defina as variáveis de ambiente:
# Set the Anthropic SDK compatible API endpoint provided by Novita.
export ANTHROPIC_BASE_URL="https://api.novita.ai/anthropic"
export ANTHROPIC_AUTH_TOKEN="<Novita API Key>"
# Set the model provided by Novita.
export ANTHROPIC_MODEL="minimax/minimax-m2.5"
export ANTHROPIC_SMALL_FAST_MODEL="minimax/minimax-m2.5"
3. Inicie o Claude Code no seu projeto:
cd /path/to/project
claude .
Melhor para: Exploração de base de código, depuração de múltiplos passos, implementação autônoma de funcionalidades, integração com VSCode/Cursor por meio de plugins de terminal.
4. Implantação Local
A arquitetura esparsa de Mistura de Especialistas (MoE) do MiniMax M2.5 (229 bilhões de parâmetros no total, 10 bilhões ativos por token) torna a implantação local viável em hardware de consumidor de alto nível ou configurações com múltiplas GPUs. O modelo requer 457GB na precisão BF16 completa, mas a quantização por meio das quantizações GGUF do Unsloth reduz esse requisito para 101GB (3 bits dinâmicos) ou 138GB (Q4_K_M).
Requisitos de Hardware
| Quantização | VRAM Necessária | Exemplo de Hardware |
|---|---|---|
| BF16 (precisão completa) | 457GB | 6× H100 80GB |
| Q8_0 | 243GB | 4× H100 80GB |
| Q6_K | 188GB | 3× H100 80GB |
| Q4_K_M (recomendada) | 138GB | 2× H100 80GB |
| Q3_K_M | 109GB | 2× H100 80GB |
| UD-IQ2_XXS (mínimo) | 74GB | H100 80GB único |
Instalação (llama.cpp)
git clone https://github.com/ggml-org/llama.cpp.git
cd llama.cpp
cmake -B build -DCMAKE_BUILD_TYPE=Release
cmake --build build -j"$(nproc)"
# Install HF CLI if needed
pip install -U "huggingface_hub[cli]"
# Download a specific quant (example: Q3_K_M)
hf download unsloth/MiniMax-M2.5-GGUF \
--include "Q3_K_M/*" \
--local-dir ./models
# Check files
find ./models -name "*.gguf"
# Run (use the FIRST shard)
./build/bin/llama-cli \
-m ./models/Q3_K_M/MiniMax-M2.5-Q3_K_M-00001-of-00004.gguf \
-p "Write a Python function to check if a number is prime"
Instalação de GPU em Nuvem (de forma econômica)
Passo 1: Crie uma conta
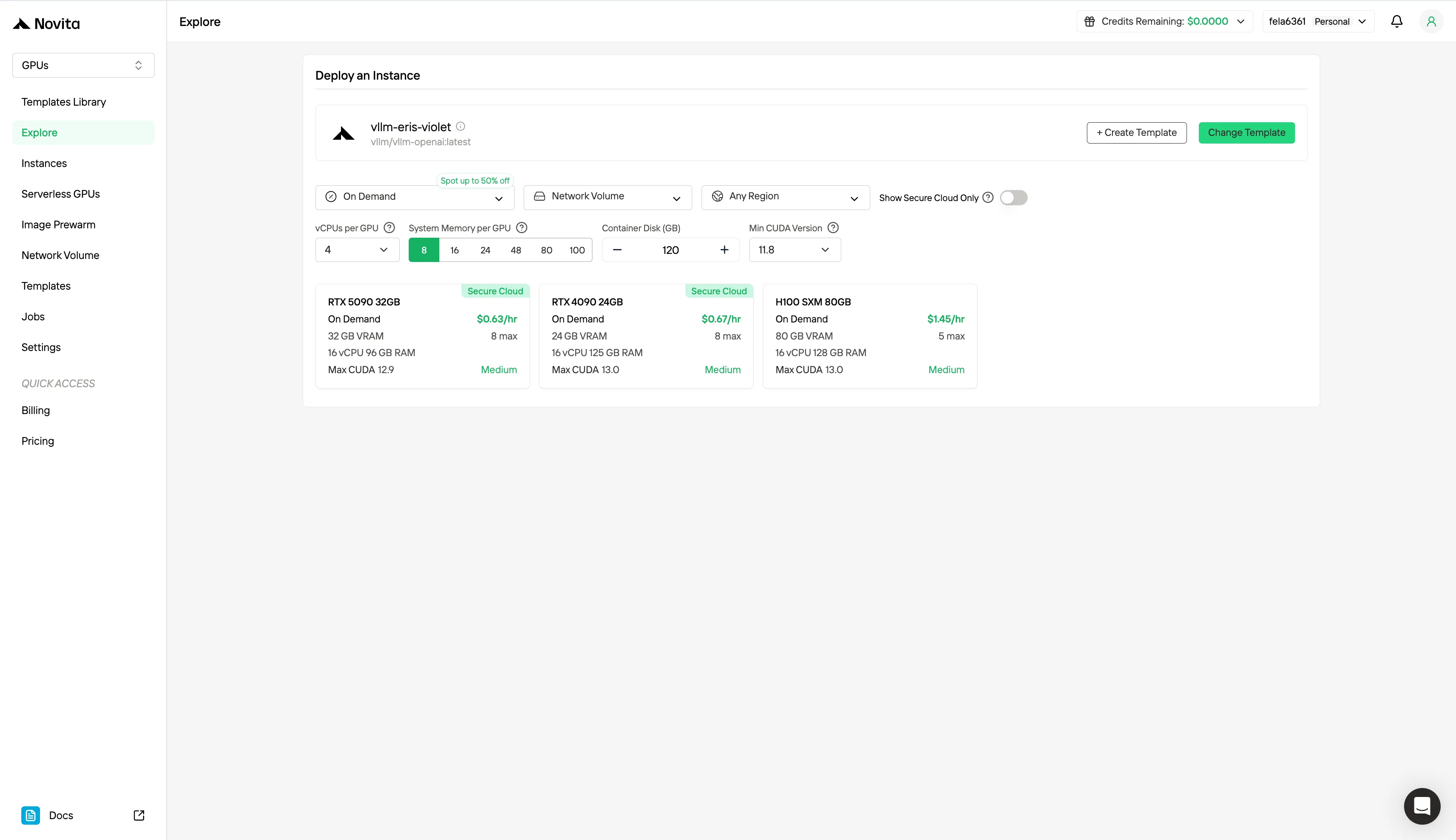
Crie sua conta Novita AI por meio do nosso site. Após o registro, navegue até a seção “Explorar” na barra lateral esquerda para ver nossas ofertas de GPU e começar sua jornada de desenvolvimento de IA.

Passo 2: Explorando Modelos e Servidores GPU
Escolha entre modelos como PyTorch, TensorFlow ou CUDA que correspondam às necessidades do seu projeto. Em seguida, selecione sua configuração de GPU preferida — as opções incluem as poderosas L40S, RTX 4090 ou A100 SXM4, cada uma com diferentes especificações de VRAM, RAM e armazenamento.
Passo 3: Personalize sua Implantação
Personalize seu ambiente selecionando seu sistema operacional preferido e opções de configuração para garantir o desempenho ideal para suas cargas de trabalho de IA específicas e necessidades de desenvolvimento.
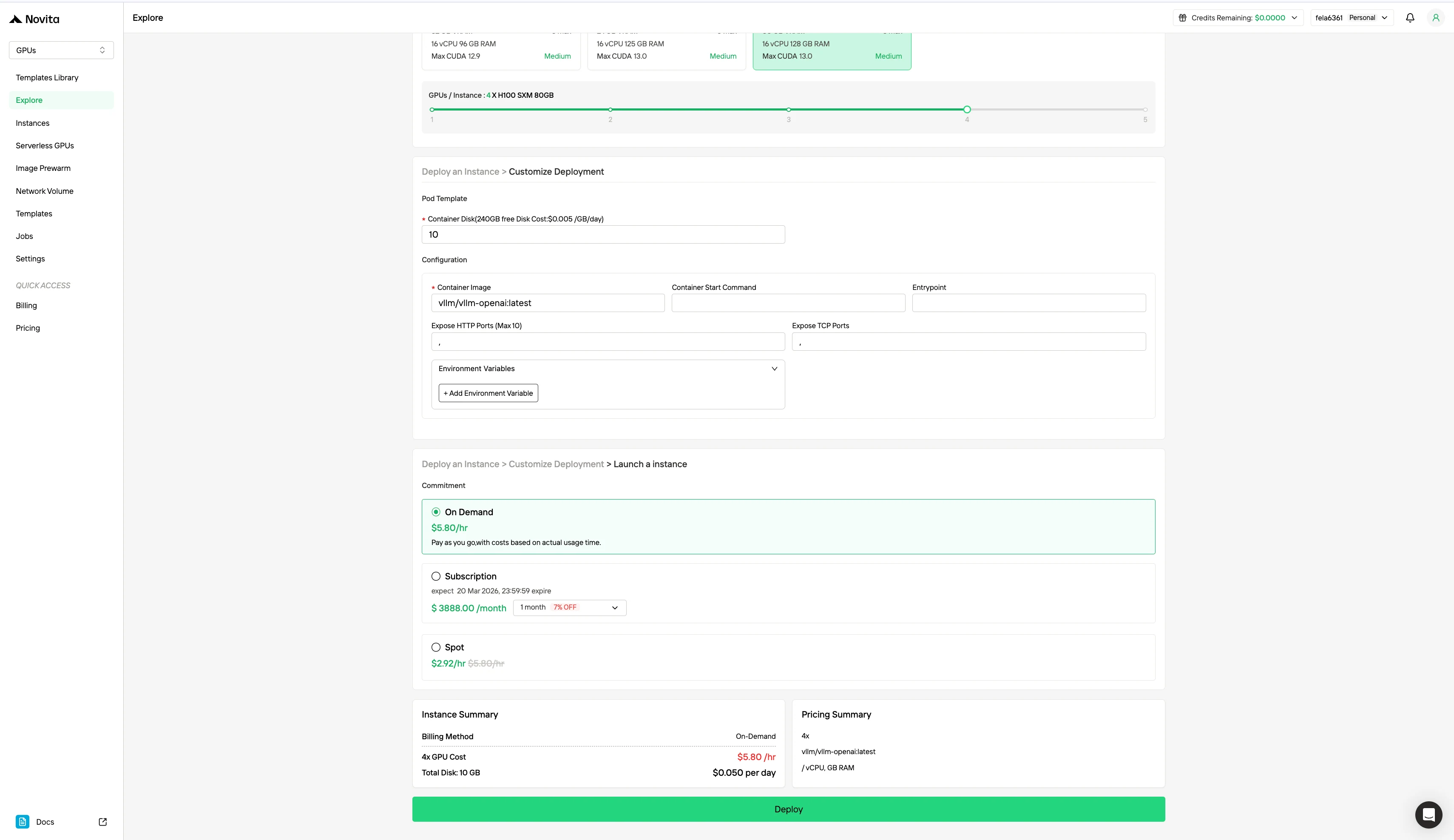
| Especificação | Método de Cobrança | GPU | Preço |
|---|---|---|---|
| H100 80 GB VRAM | Sob Demanda | 1x GPU | $1,45/hora |
| 8x GPU | $11,60/hora | ||
| Spot | 1x GPU | $0,73/hora | |
| 8x GPU | $5,84/hora |
A instância Spot da Novita AI é um sistema de aluguel de GPU otimizado para custos que aproveita a capacidade de GPU ociosa ou não utilizada da plataforma. Ao contrário das instâncias sob demanda, que reservam hardware dedicado para uso estável e contínuo, as instâncias Spot são interrompíveis — seu trabalho pode ser pausado ou encerrado se a GPU for recuperada pelo sistema. Como o modo Spot realoca recursos de GPU que de outra forma estariam ociosos, ele é geralmente 40–60% mais barato que os preços sob demanda.
O MiniMax M2.5 oferece quatro caminhos de acesso práticos, cada um otimizado para cenários diferentes. Para a maioria dos desenvolvedores, a API da Novita AI por $0,30/$1,20 por milhão de tokens oferece o caminho mais rápido para a produção — a configuração leva 2 minutos com compatibilidade com o SDK da OpenAI. O playground web serve para avaliação inicial, enquanto a CLI do OpenClaw e o Claude Code permitem fluxos de trabalho autônomos integrados ao terminal para usuários avançados. A auto-hospedagem faz sentido economicamente apenas acima de 10 milhões de tokens por dia ou quando requisitos rigorosos de privacidade de dados proíbem APIs em nuvem — nesse caso, a quantização Q4_K_M em 2× H100 80GB oferece desempenho pronto para produção.
Perguntas Frequentes
O que torna o MiniMax M2.5 diferente de outros modelos de codificação?
O MiniMax M2.5 usa arquitetura esparsa MoE com 229 bilhões de parâmetros no total, mas apenas 10 bilhões ativos por token, atingindo 80,2% no SWE-Bench Verified a 8% do custo do Claude Sonnet 4.5.
Posso executar o MiniMax M2.5 em uma única GPU de consumidor?
Não — o requisito mínimo de VRAM é de 74GB mesmo com quantização agressiva.
O MiniMax M2.5 suporta chamadas de função e saídas estruturadas?
Sim — o MiniMax M2.5 suporta chamadas de função por meio do formato de API compatível com OpenAI.
Novita AI é uma plataforma de nuvem de IA e agentes que ajuda desenvolvedores e startups a construir, implantar e escalar modelos e aplicações autônomas com alto desempenho, confiabilidade e eficiência de custos.
Leituras Recomendadas



