

MiniMax M2.5 es un modelo Mixture-of-Experts disperso de 229 mil millones de parámetros, que permite inferencia eficiente a pesar de su escala. Publicado por la empresa china de IA MiniMax, se encuentra entre los mejores modelos de código abierto para tareas de codificación autónoma y navegación web, alcanzando un 80.2% en SWE-Bench Verified y un 76.3% en BrowseComp.
Novita ofrece un modelo acelerado que mantiene el sólido rendimiento de la versión anterior mientras mejora significativamente la velocidad.
Comparación de Métodos de Acceso
| Método | Tiempo de Configuración | Costo (1M tokens/día) | Mejor para |
|---|---|---|---|
| Web Playground | 0 minutos | Gratis (con límite de tasa) | Evaluación inicial, tareas puntuales |
| API de Novita AI | 2 minutos | Entrada: $0.3 /Mt Lectura de caché: $0.03 /Mt Salida: $1.2 /Mt |
Aplicaciones en producción, volumen moderado, prototipado rápido |
| NovitaClaw | 5 minutos | Entrada: $0.3 /Mt Lectura de caché: $0.03 /Mt Salida: $1.2 /Mt |
Automatización de terminal, flujos de trabajo DevOps |
| Claude Code | 5 minutos | Entrada: $0.3 /Mt Lectura de caché: $0.03 /Mt Salida: $1.2 /Mt |
Exploración de bases de código, integración con IDE |
| Local (Q4_K_M) | 30-60 minutos | Inversión única: $60,000–$90,000 | Alto volumen de producción, requisitos de privacidad de datos |
| GPU en la nube | 5 minutos | 8x GPU $11.60/hora | Experimentos a corto plazo, cargas de trabajo ráfaga, pruebas de modelos grandes |
1. Web Playground
El punto de entrada más rápido y sin barreras es el web playground de Novita AI: sin registro, sin claves API, evaluación instantánea. Funciona mejor para pruebas rápidas de capacidad antes de comprometerse con la integración API o el despliegue local.
Casos de uso típicos: Ingeniería de prompts, evaluación de calidad, pruebas de tareas de codificación, comparación de resultados con otros modelos lado a lado. El web playground es ideal para evaluación inicial y tareas puntuales, sin necesidad de configuración técnica.
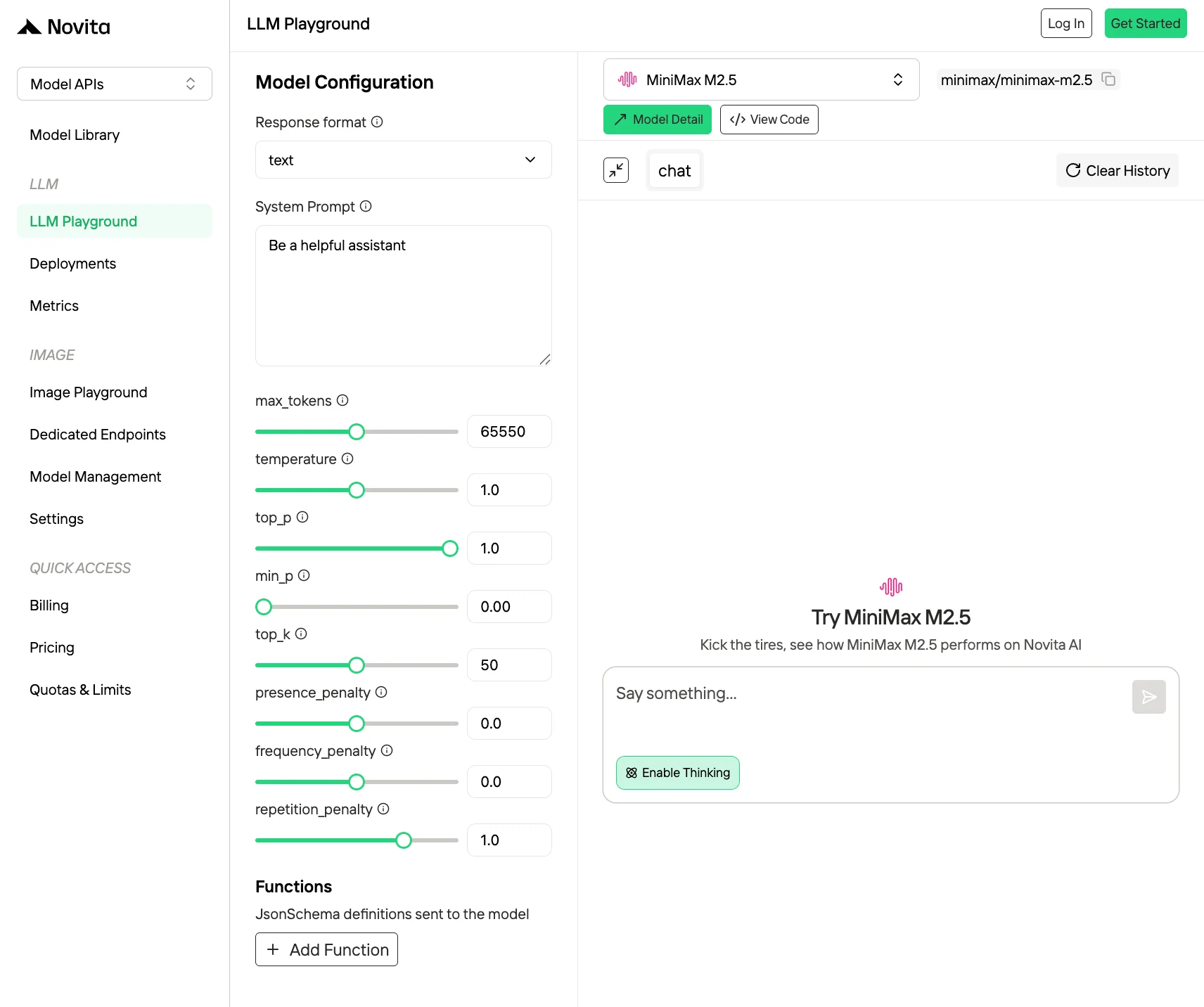
2. API de Novita AI (Recomendada para la mayoría de desarrolladores)
¿Por qué elegir la API de Novita AI?
- Compatible con OpenAI y Anthropic
- Precios competitivos: $0.30/$1.20 por 1M tokens.
- Soporte de precios de caché: Los precios de caché permiten reutilizar prompts guardados anteriormente, ayudando a reducir cálculos repetidos y disminuir costos generales.
Guía de configuración
Paso 1: Inicia sesión y accede a la Biblioteca de Modelos
Inicia sesión en tu cuenta y haz clic en el botón Model Library.

Paso 2: Elige tu modelo
Explora las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.

Paso 3: Comienza tu prueba gratuita
Inicia tu prueba gratuita para explorar las capacidades del modelo seleccionado.
¡Prueba MiniMax M2.5 económico ahora!
Paso 4: Obtén tu clave API
Para autenticarte en la API, te proporcionaremos una nueva clave API. Ingresa a la página “Settings”, puedes copiar la clave API como se indica en la imagen.

Paso 5: Instala la API
Instala la API usando el gestor de paquetes específico de tu lenguaje de programación.
Después de la instalación, importa las bibliotecas necesarias en tu entorno de desarrollo. Inicializa la API con tu clave API para comenzar a interactuar con Novita AI LLM. Este es un ejemplo de uso de chat completions API para usuarios de Python.
from openai import OpenAI
client = OpenAI(
api_key="<Tu Clave API>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="minimax/minimax-m2.5",
messages=[
{"role": "system", "content": "Eres un asistente útil."},
{"role": "user", "content": "Hola, ¿cómo estás?"}
],
max_tokens=131100,
temperature=0.7
)
print(response.choices[0].message.content)
3. Acceso mediante Herramientas de Código
NovitaClaw
NovitaClaw es una herramienta de línea de comandos para desplegar y gestionar agentes OpenClaw persistentes en Novita Agent Sandbox. Con un solo comando, puedes lanzar una instancia de agente completamente alojada que se ejecuta de forma continua, sin límites de sesión ni necesidad de reinicios manuales. Una vez desplegado, el agente puede ser accedido y controlado a través de múltiples interfaces, incluyendo la CLI, una interfaz web o scripts de automatización externos.
Primeros pasos
Requisitos previos
Antes de comenzar, asegúrate de tener:
- Python instalado
- Una clave API de Novita (crea o gestiona claves en Key Management)
Paso 1: Instalar NovitaClaw
macOS / Linux:
sudo pip3 install novitaclaw
Windows PowerShell:
pip install novitaclaw
Verifica: ejecuta novitaclaw --help. Si ves una lista de comandos, la instalación fue exitosa.
Paso 2: Configurar tu clave API
macOS / Linux:
export NOVITA_API_KEY=sk_tu_clave_api
Windows PowerShell:
$env:NOVITA_API_KEY = "sk_tu_clave_api"
Paso 3: Lanzar tu instancia
novitaclaw launch
En caso de éxito, la CLI devuelve:
- Web UI URL — Chatea con tu agente
- Gateway WebSocket URL & Token — Para acceso programático
- Web Terminal URL — Acceso a terminal basado en navegador
- File Manager URL — Gestiona archivos del espacio de trabajo
- Credenciales de inicio de sesión — Para Web Terminal y File Manager
Abre la Web UI URL, ve a la pestaña Chat y comienza a usar tu agente.
Configuración de modelos
Tu instancia viene preconfigurada con un modelo alojado en Novita por defecto. Para personalizarlo:
Ve a:
Settings → Config → Raw (JSON5 view)
Haz clic en “secrets redacted” para revelar la configuración completa.
Paso 1: Registrar un modelo
Añade una nueva entrada debajo de models.providers.novita.models:
{
"models": {
"providers": {
"novita": {
"models": [
{
"id": "model-id",
"name": "nombre visible",
"reasoning": true,
"input": ["text"],
"contextWindow": 200000,
"maxTokens": 50000
}
]
}
}
}
}
Paso 2: Establecer como principal o respaldo
Actualiza agents.defaults:
{
"agents": {
"defaults": {
"model": {
"primary": "novita/model-id",
"fallbacks": ["novita/fallback-model-id"]
}
}
}
}
Claude Code
Claude Code es el agente CLI oficial de Anthropic, diseñado principalmente para modelos Claude pero compatible con endpoints compatibles con la API de Anthropic, como Novita AI. Destaca en el análisis de repositorios completos, depuración compleja y bucles de codificación agéntica.
Configuración:
1. Instala Claude Code:
# macOS, Linux, WSL:
curl -fsSL https://claude.ai/install.sh | bash
# Windows PowerShell:
irm https://claude.ai/install.ps1 | iex
# Windows CMD:
curl -fsSL https://claude.ai/install.cmd -o install.cmd && install.cmd && del install.cmd
# Windows requiere Git para Windows. Instálalo primero si no lo tienes.
2. Configura las variables de entorno:
# Establece el endpoint API compatible con Anthropic SDK proporcionado por Novita.
export ANTHROPIC_BASE_URL="https://api.novita.ai/anthropic"
export ANTHROPIC_AUTH_TOKEN="<Clave API de Novita>"
# Establece el modelo proporcionado por Novita.
export ANTHROPIC_MODEL="minimax/minimax-m2.5"
export ANTHROPIC_SMALL_FAST_MODEL="minimax/minimax-m2.5"
3. Inicia Claude Code en tu proyecto:
cd /ruta/al/proyecto
claude .
Mejor para: Exploración de bases de código, depuración de múltiples pasos, implementación autónoma de características, integración con VSCode/Cursor mediante plugins de terminal.
4. Despliegue Local
La arquitectura MoE dispersa de MiniMax M2.5 (229B total, 10B activos) hace que el despliegue local sea viable en hardware de consumo de gama alta o configuraciones multi-GPU. El modelo requiere 457GB en precisión BF16 completa, pero la cuantización mediante las cuantizaciones GGUF de Unsloth reduce esto a 101GB (Dynamic 3-bit) o 138GB (Q4_K_M).
Requisitos de hardware
| Cuantización | VRAM necesaria | Ejemplo de hardware |
|---|---|---|
| BF16 (precisión completa) | 457GB | 6× H100 80GB |
| Q8_0 | 243GB | 4× H100 80GB |
| Q6_K | 188GB | 3× H100 80GB |
| Q4_K_M (recomendada) | 138GB | 2× H100 80GB |
| Q3_K_M | 109GB | 2× H100 80GB |
| UD-IQ2_XXS (mínimo) | 74GB | H100 80GB único |
Instalación (llama.cpp)
git clone https://github.com/ggml-org/llama.cpp.git
cd llama.cpp
cmake -B build -DCMAKE_BUILD_TYPE=Release
cmake --build build -j"$(nproc)"
# Instalar HF CLI si es necesario
pip install -U "huggingface_hub[cli]"
# Descargar una cuantización específica (ejemplo: Q3_K_M)
hf download unsloth/MiniMax-M2.5-GGUF \
--include "Q3_K_M/*" \
--local-dir ./models
# Verificar archivos
find ./models -name "*.gguf"
# Ejecutar (usar el PRIMER shard)
./build/bin/llama-cli \
-m ./models/Q3_K_M/MiniMax-M2.5-Q3_K_M-00001-of-00004.gguf \
-p "Escribe una función en Python para verificar si un número es primo"
Instalación de GPU en la nube (rentable)
Paso 1: Registrar una cuenta
Crea tu cuenta de Novita AI a través de nuestro sitio web. Después del registro, navega a la sección “Explore” en la barra lateral izquierda para ver nuestras ofertas de GPU y comenzar tu viaje de desarrollo de IA.

Paso 2: Explorar plantillas y servidores GPU
Elige entre plantillas como PyTorch, TensorFlow o CUDA que se ajusten a las necesidades de tu proyecto. Luego selecciona la configuración de GPU que prefieras: las opciones incluyen la potente L40S, RTX 4090 o A100 SXM4, cada una con diferentes especificaciones de VRAM, RAM y almacenamiento.
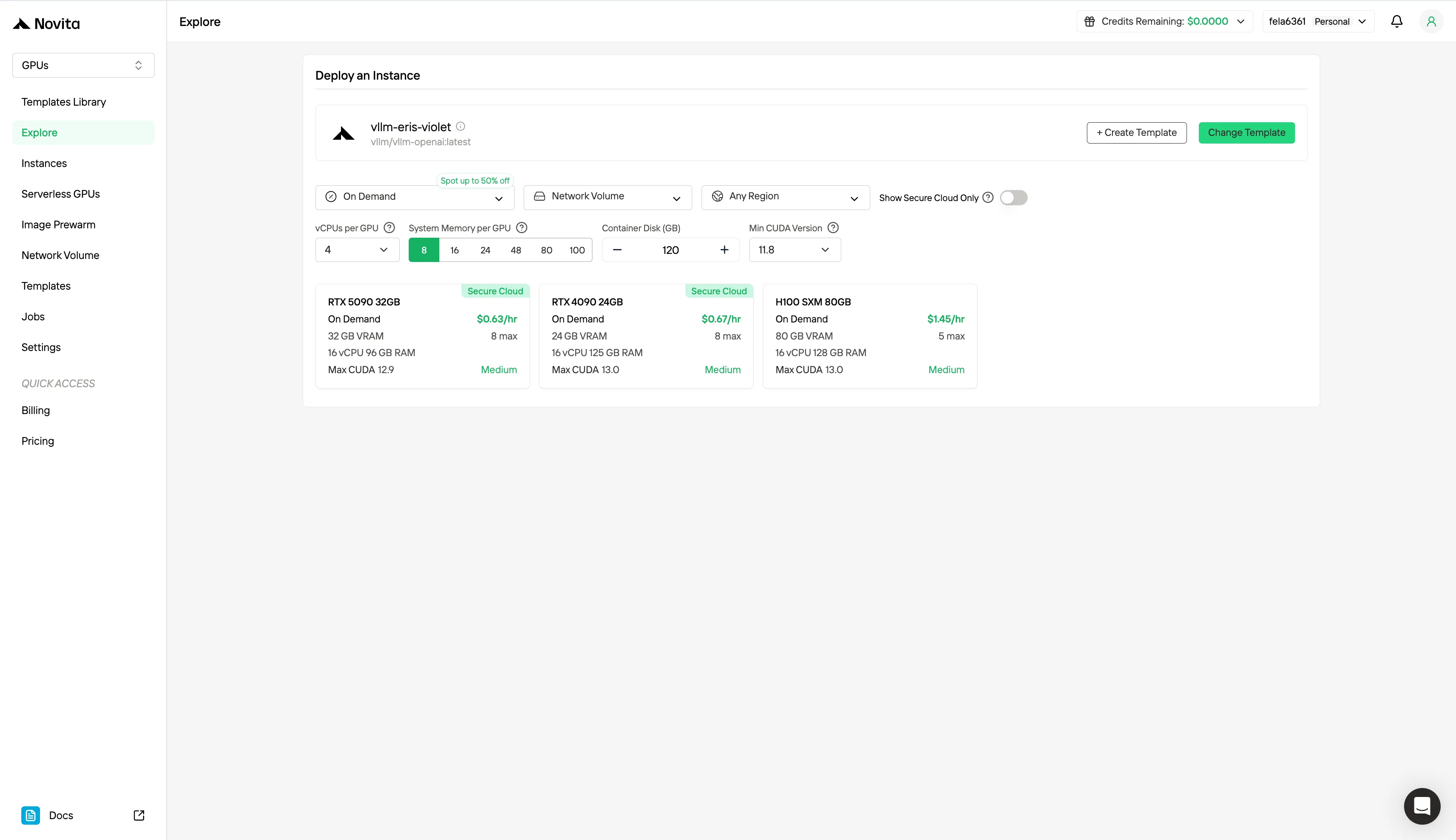
Paso 3: Personaliza tu despliegue
Personaliza tu entorno seleccionando tu sistema operativo preferido y opciones de configuración para asegurar un rendimiento óptimo para tus cargas de trabajo de IA específicas y necesidades de desarrollo.
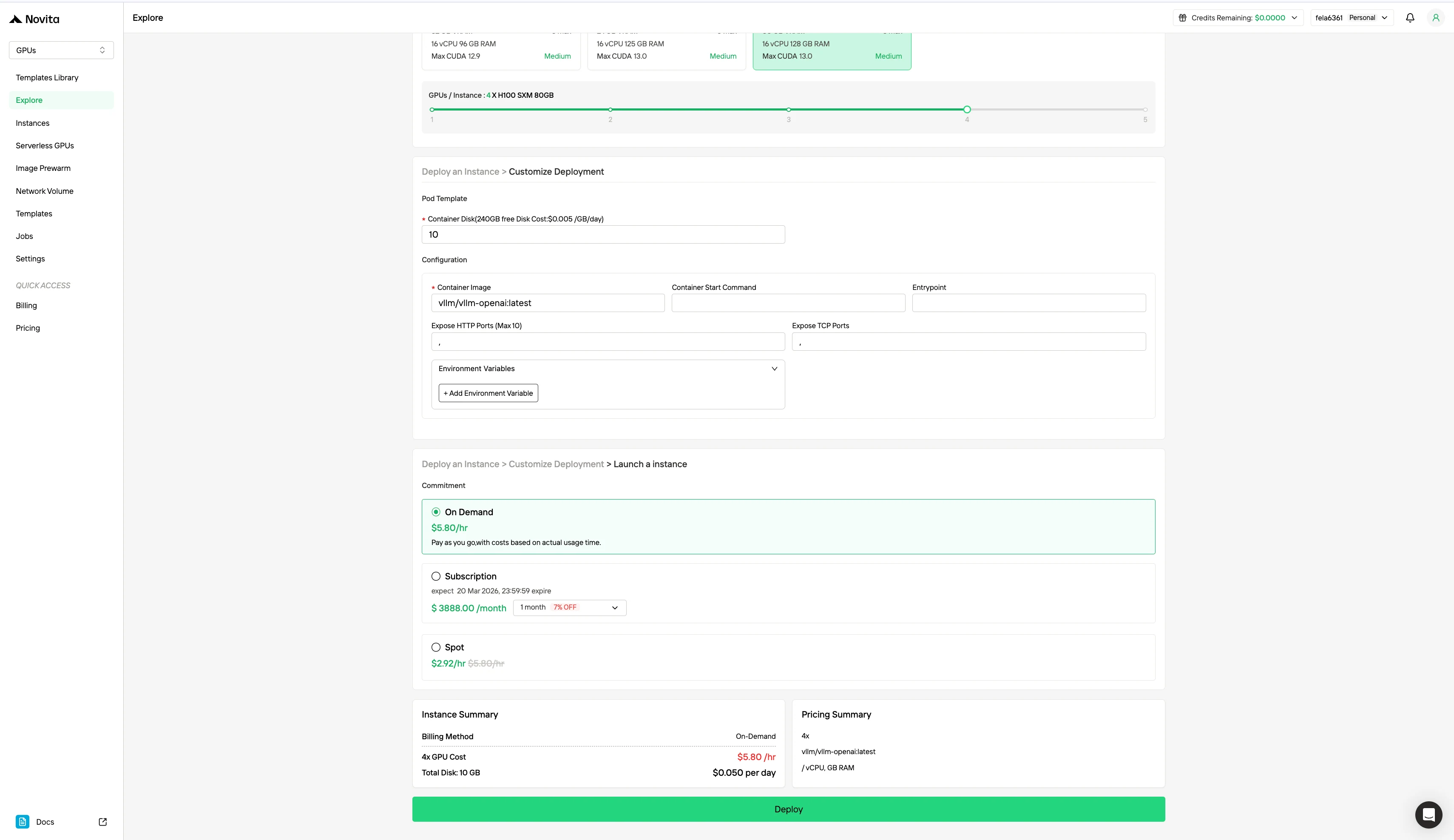
| Especificación | Método de facturación | GPU | Precio |
|---|---|---|---|
| H100 80 GB VRAM | On-Demand | 1x GPU | $1.45/hora |
| 8x GPU | $11.60/hora | ||
| Spot | 1x GPU | $0.73/hora | |
| 8x GPU | $5.84/hora |
La instancia Spot de Novita AI es un sistema de alquiler de GPU optimizado en costos que aprovecha la capacidad GPU inactiva o no utilizada de la plataforma. A diferencia de las instancias on-demand, que reservan hardware dedicado para un uso estable y continuo, las instancias Spot son interrumpibles: tu trabajo puede ser pausado o terminado si la GPU es reclamada por el sistema. Debido a que el modo Spot reasigna recursos GPU que de otro modo estarían inactivos, suele ser entre un 40 y 60% más barato que el precio on-demand.
MiniMax M2.5 ofrece cuatro rutas de acceso prácticas, cada una optimizada para diferentes escenarios. Para la mayoría de los desarrolladores, la API de Novita AI a $0.30/$1.20 por millón de tokens proporciona el camino más rápido a producción: la configuración toma 2 minutos con compatibilidad con el SDK de OpenAI. El web playground sirve para evaluación inicial, mientras que OpenClaw CLI y Claude Code habilitan flujos de trabajo agénticos integrados en terminal para usuarios avanzados. El auto-hospedaje tiene sentido económico solo por encima de 10 millones de tokens por día o cuando requisitos estrictos de privacidad de datos prohíben las API en la nube; en ese caso, la cuantización Q4_K_M en 2× H100 80GB ofrece un rendimiento listo para producción.
Preguntas Frecuentes
¿Qué hace que MiniMax M2.5 sea diferente de otros modelos de codificación?
MiniMax M2.5 utiliza arquitectura MoE dispersa con 229B parámetros totales pero solo 10B activos por token, alcanzando un 80.2% en SWE-Bench Verified a un 8% del costo de Claude Sonnet 4.5.
¿Puedo ejecutar MiniMax M2.5 en una sola GPU de consumo?
No: el requisito mínimo de VRAM es de 74GB incluso con cuantización agresiva.
¿MiniMax M2.5 admite llamadas a funciones y salidas estructuradas?
Sí: MiniMax M2.5 admite llamadas a funciones a través del formato de API compatible con OpenAI.
Novita AI es una plataforma en la nube de IA y agentes que ayuda a desarrolladores y startups a construir, desplegar y escalar modelos y aplicaciones agénticas con alto rendimiento, confiabilidad y eficiencia de costos.
Lectura Recomendada



