

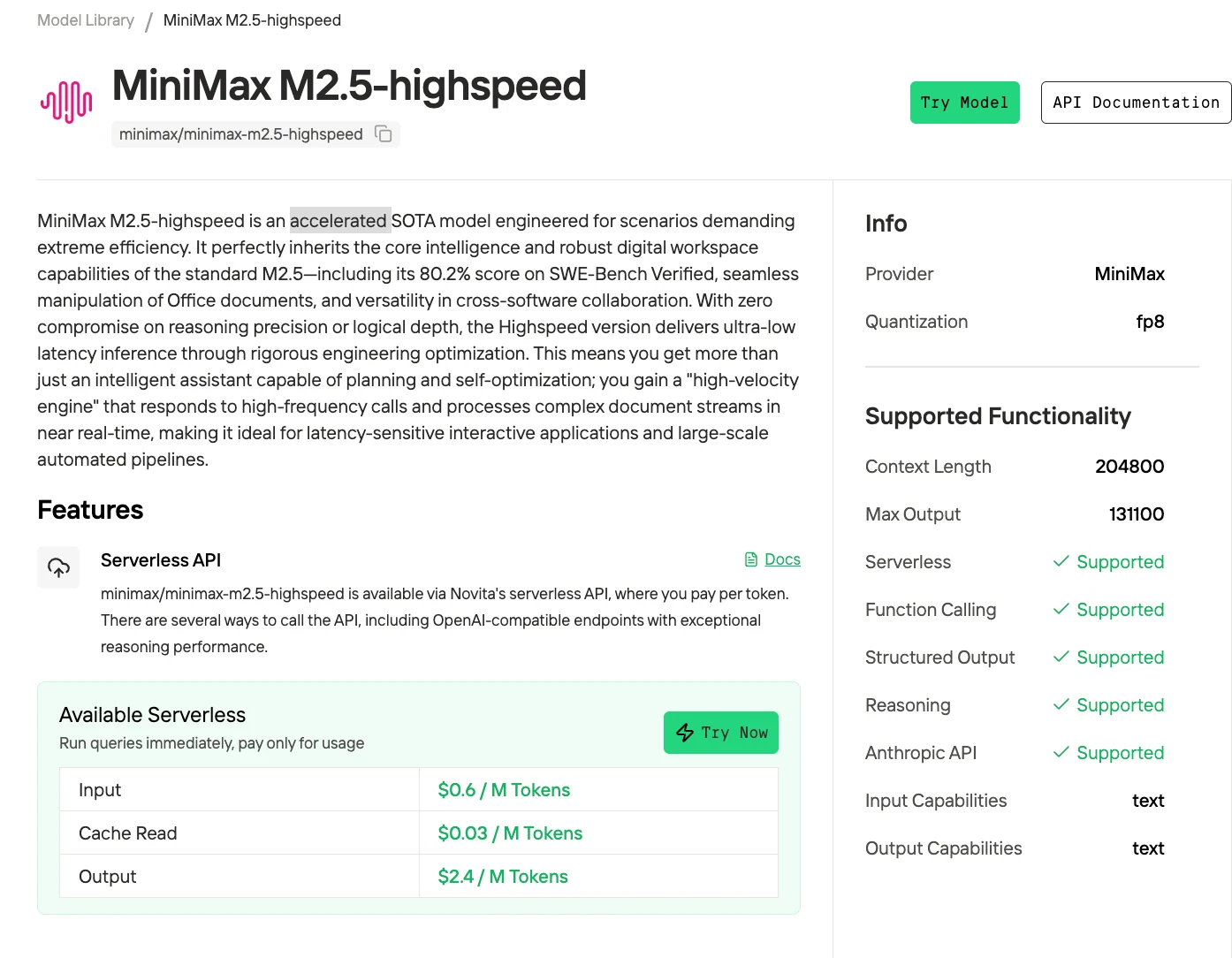
MiniMax M2.5 は 2290億パラメータのスパース Mixture-of-Experts モデルであり、その規模にもかかわらず効率的な推論を実現します。中国の AI 企業 MiniMax によってリリースされ、自律的なコーディングや Web ナビゲーションタスクにおいてトップクラスのオープンソースモデルにランクインし、SWE-Bench Verified で 80.2%、BrowseComp で 76.3% を達成しています。
Novita は、以前のバージョンの強力なパフォーマンスを維持しながら、速度を大幅に向上させた高速モデルを提供しています。
アクセス方法の比較
| 方法 | セットアップ時間 | コスト (1日100万トークン) | 最適な用途 |
|---|---|---|---|
| Web プレイグラウンド | 0 分 | 無料 (レート制限あり) | 初回評価、単発タスク |
| Novita AI API | 2 分 | 入力: $0.3 /Mt キャッシュ読み取り: $0.03 /Mt 出力: $1.2 /Mt |
本番アプリ、中程度のボリューム、迅速なプロトタイピング |
| NovitaClaw | 5 分 | 入力: $0.3 /Mt キャッシュ読み取り: $0.03 /Mt 出力: $1.2 /Mt |
ターミナル自動化、DevOps ワークフロー |
| Claude Code | 5 分 | 入力: $0.3 /Mt キャッシュ読み取り: $0.03 /Mt 出力: $1.2 /Mt |
コードベース探索、IDE 統合 |
| ローカル (Q4_K_M) | 30~60 分 | 初期投資: $60,000~$90,000 | 高ボリューム本番、データプライバシー要件 |
| クラウド GPU | 5 分 | 8x GPU $11.60/時間 | 短期実験、バーストワークロード、大規模モデルテスト |
1. Web プレイグラウンド
最も速いゼロバリアのエントリーポイントは Novita AI の Web プレイグラウンドです。サインアップ不要、API キー不要、即時評価が可能です。API 統合やローカルデプロイにコミットする前に、迅速な機能テストに最適です。
典型的なユースケース: プロンプトエンジニアリング、品質評価、コーディングタスクのテスト、他のモデルとの出力の比較。Web プレイグラウンドは初回評価や単発タスクに最適で、技術的なセットアップは不要です。
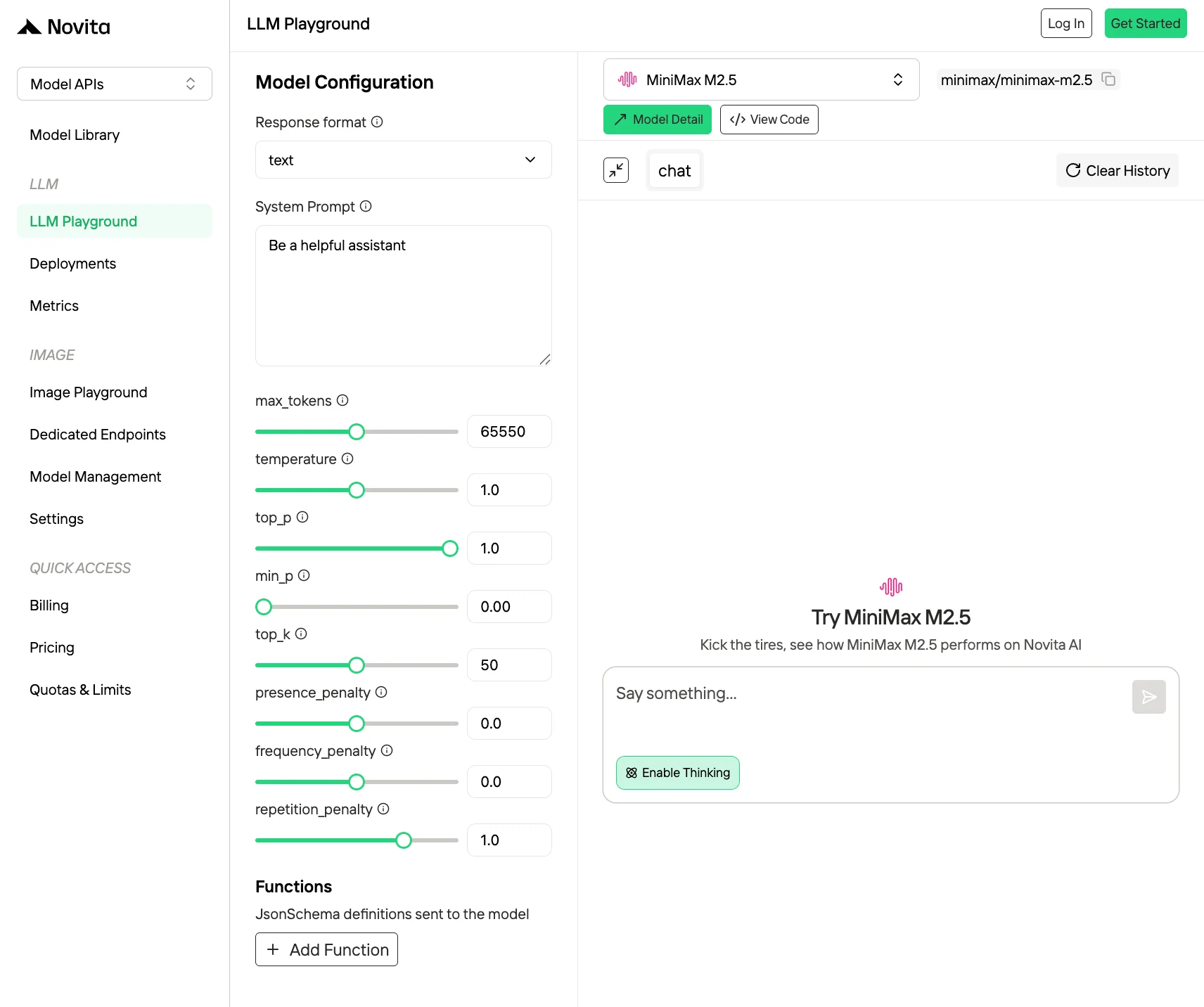
2. Novita AI API (ほとんどの開発者におすすめ)
Novita AI API を選ぶ理由
- OpenAI 互換および Anthropic 互換
- 競争力のある価格: 100万トークンあたり $0.30/$1.20。
- キャッシュ価格をサポート: キャッシュ価格により、以前に保存したプロンプトを再利用でき、繰り返しの計算を減らし、全体的なコストを削減できます。
セットアップガイド
ステップ 1: ログインしてモデルライブラリにアクセス
アカウントにログインし、モデルライブラリ ボタンをクリックします。

ステップ 2: モデルを選択
利用可能なオプションから、ニーズに合ったモデルを選択します。

ステップ 3: 無料トライアルを開始
選択したモデルの機能を試すために、無料トライアルを開始します。
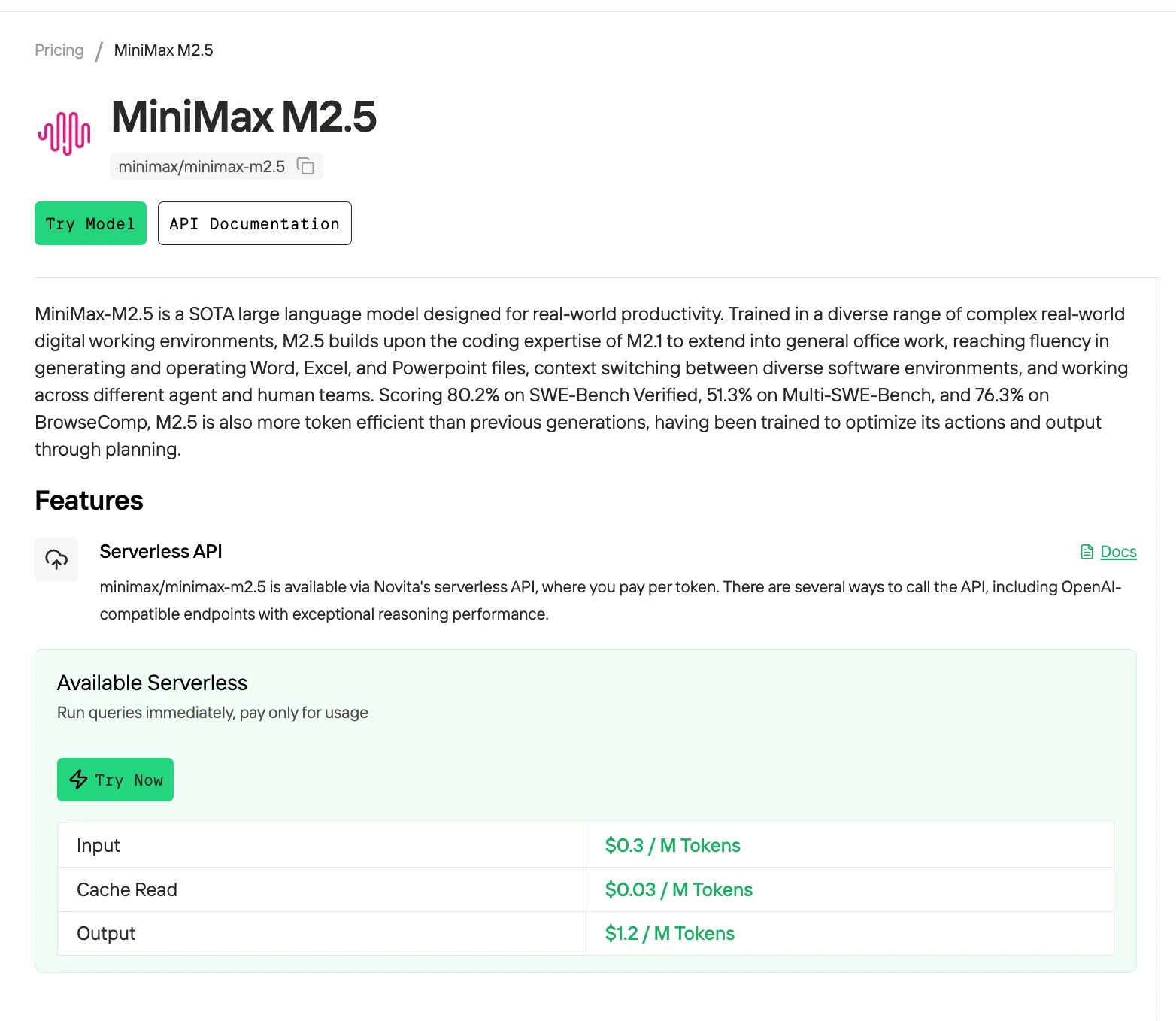
ステップ 4: API キーを取得
API で認証するために、新しい API キーを提供します。「設定」ページに移動し、画像のように API キーをコピーします。

ステップ 5: API をインストール
プログラミング言語に応じたパッケージマネージャーを使用して API をインストールします。
インストール後、開発環境に必要なライブラリをインポートします。API キーを使用して API を初期化し、Novita AI LLM との対話を開始します。これは Python ユーザー向けのチャット補完 API の使用例です。
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="minimax/minimax-m2.5",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131100,
temperature=0.7
)
print(response.choices[0].message.content)
3. コードツールアクセス
NovitaClaw
NovitaClaw は、Novita Agent Sandbox 上で永続的な OpenClaw エージェントをデプロイおよび管理するためのコマンドラインツールです。単一のコマンドで、セッション制限や手動再起動なしで継続的に実行される完全ホスト型のエージェントインスタンスを起動できます。デプロイ後、エージェントは CLI、Web ベースの UI、または外部自動化スクリプトを含む複数のインターフェースからアクセスおよび制御できます。
はじめに
前提条件
始める前に、以下がインストールされていることを確認してください。
- Python がインストールされていること
- Novita API キー (キー管理 で作成または管理)
ステップ 1: NovitaClaw のインストール
macOS / Linux:
sudo pip3 install novitaclaw
Windows PowerShell:
pip install novitaclaw
確認: novitaclaw --help を実行します。コマンドのリストが表示されれば、インストール成功です。
ステップ 2: API キーの設定
macOS / Linux:
export NOVITA_API_KEY=sk_your_api_key
Windows PowerShell:
$env:NOVITA_API_KEY = "sk_your_api_key"
ステップ 3: インスタンスの起動
novitaclaw launch
成功すると、CLI は以下を返します。
- Web UI URL — エージェントとチャット
- Gateway WebSocket URL & Token — プログラムによるアクセス用
- Web Terminal URL — ブラウザベースのターミナルアクセス
- File Manager URL — ワークスペースファイルの管理
- ログイン認証情報 — Web Terminal および File Manager 用
Web UI URL を開き、Chat タブに移動してエージェントの使用を開始します。
モデルの設定
インスタンスはデフォルトで Novita ホストのモデルが事前設定されています。カスタマイズするには:
Settings → Config → Raw (JSON5 view) に移動します。
「secrets redacted」 をクリックして完全な設定を表示します。
ステップ 1: モデルの登録
models.providers.novita.models の下に新しいエントリを追加します。
{
"models": {
"providers": {
"novita": {
"models": [
{
"id": "model-id",
"name": "display name",
"reasoning": true,
"input": ["text"],
"contextWindow": 200000,
"maxTokens": 50000
}
]
}
}
}
}
ステップ 2: プライマリまたはフォールバックとして設定
agents.defaults を更新します。
{
"agents": {
"defaults": {
"model": {
"primary": "novita/model-id",
"fallbacks": ["novita/fallback-model-id"]
}
}
}
}
Claude Code
Claude Code は Anthropic の公式 CLI エージェントで、主に Claude モデル向けに設計されていますが、Novita AI のような Anthropic API 互換エンドポイントでも動作します。リポジトリ全体の分析、複雑なデバッグ、エージェンティックなコーディングループに優れています。
セットアップ:
- Claude Code をインストール:
#macOS, Linux, WSL:
curl -fsSL https://claude.ai/install.sh | bash
#Windows PowerShell:
irm https://claude.ai/install.ps1 | iex
#Windows CMD:
curl -fsSL https://claude.ai/install.cmd -o install.cmd && install.cmd && del install.cmd
#Windows には Git for Windows が必要です。まだインストールしていない場合は先にインストールしてください。
- 環境変数を設定:
# Novita が提供する Anthropic SDK 互換の API エンドポイントを設定
export ANTHROPIC_BASE_URL="https://api.novita.ai/anthropic"
export ANTHROPIC_AUTH_TOKEN="<Novita API Key>"
# Novita が提供するモデルを設定
export ANTHROPIC_MODEL="minimax/minimax-m2.5"
export ANTHROPIC_SMALL_FAST_MODEL="minimax/minimax-m2.5"
- プロジェクトで Claude Code を起動:
cd /path/to/project
claude .
最適な用途: コードベース探索、マルチステップデバッグ、自律的な機能実装、ターミナルプラグインを介した VSCode/Cursor との統合。
4. ローカルデプロイ
MiniMax M2.5 のスパース MoE アーキテクチャ(合計 229B、アクティブ 10B)により、ハイエンドのコンシューマーハードウェアまたはマルチ GPU セットアップでのローカルデプロイが可能です。モデルは完全な BF16 精度で 457GB を必要としますが、Unsloth の GGUF 量子化により、101GB(Dynamic 3-bit)または 138GB(Q4_K_M)に縮小されます。
ハードウェア要件
| 量子化 | 必要な VRAM | ハードウェア例 |
|---|---|---|
| BF16 (完全精度) | 457GB | 6× H100 80GB |
| Q8_0 | 243GB | 4× H100 80GB |
| Q6_K | 188GB | 3× H100 80GB |
| Q4_K_M (推奨) | 138GB | 2× H100 80GB |
| Q3_K_M | 109GB | 2× H100 80GB |
| UD-IQ2_XXS (最小) | 74GB | 単一 H100 80GB |
インストール (llama.cpp)
git clone https://github.com/ggml-org/llama.cpp.git
cd llama.cpp
cmake -B build -DCMAKE_BUILD_TYPE=Release
cmake --build build -j"$(nproc)"
# 必要に応じて HF CLI をインストール
pip install -U "huggingface_hub[cli]"
# 特定の量子化をダウンロード (例: Q3_K_M)
hf download unsloth/MiniMax-M2.5-GGUF \
--include "Q3_K_M/*" \
--local-dir ./models
# ファイルを確認
find ./models -name "*.gguf"
# 実行 (最初のシャードを使用)
./build/bin/llama-cli \
-m ./models/Q3_K_M/MiniMax-M2.5-Q3_K_M-00001-of-00004.gguf \
-p "Write a Python function to check if a number is prime"
クラウド GPU のインストール (コスト効率よく)
ステップ 1: アカウント登録
Web サイトから Novita AI アカウントを作成します。登録後、左サイドバーの「Explore」セクションに移動して GPU の提供内容を確認し、AI 開発の旅を始めましょう。

ステップ 2: テンプレートと GPU サーバーの探索
プロジェクトのニーズに合った PyTorch、TensorFlow、CUDA などのテンプレートを選択します。次に、希望する GPU 構成を選択します。オプションには、強力な L40S、RTX 4090、A100 SXM4 などがあり、それぞれ異なる VRAM、RAM、ストレージ仕様があります。
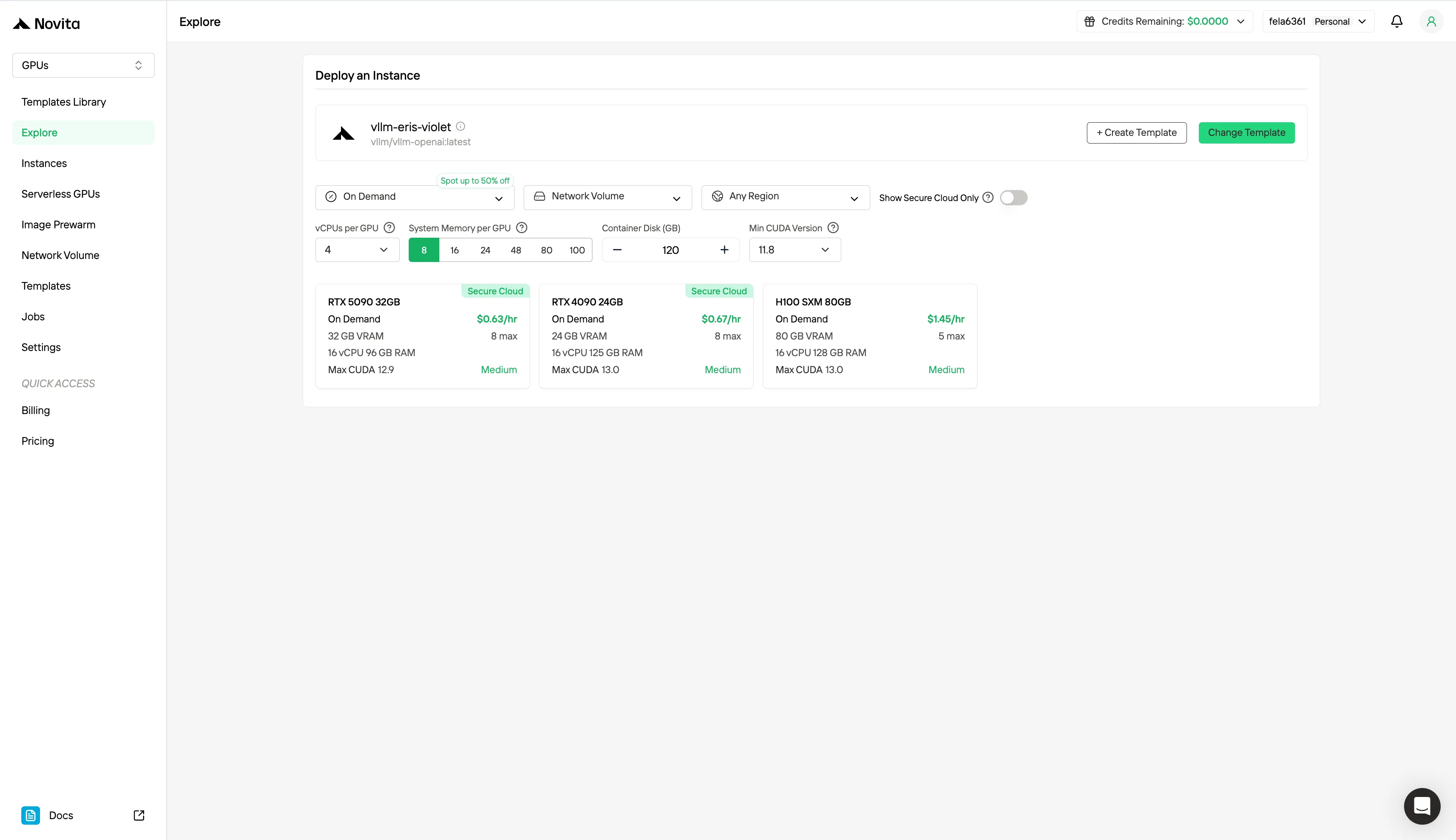
ステップ 3: デプロイのカスタマイズ
好みのオペレーティングシステムと構成オプションを選択して環境をカスタマイズし、特定の AI ワークロードと開発ニーズに最適なパフォーマンスを確保します。
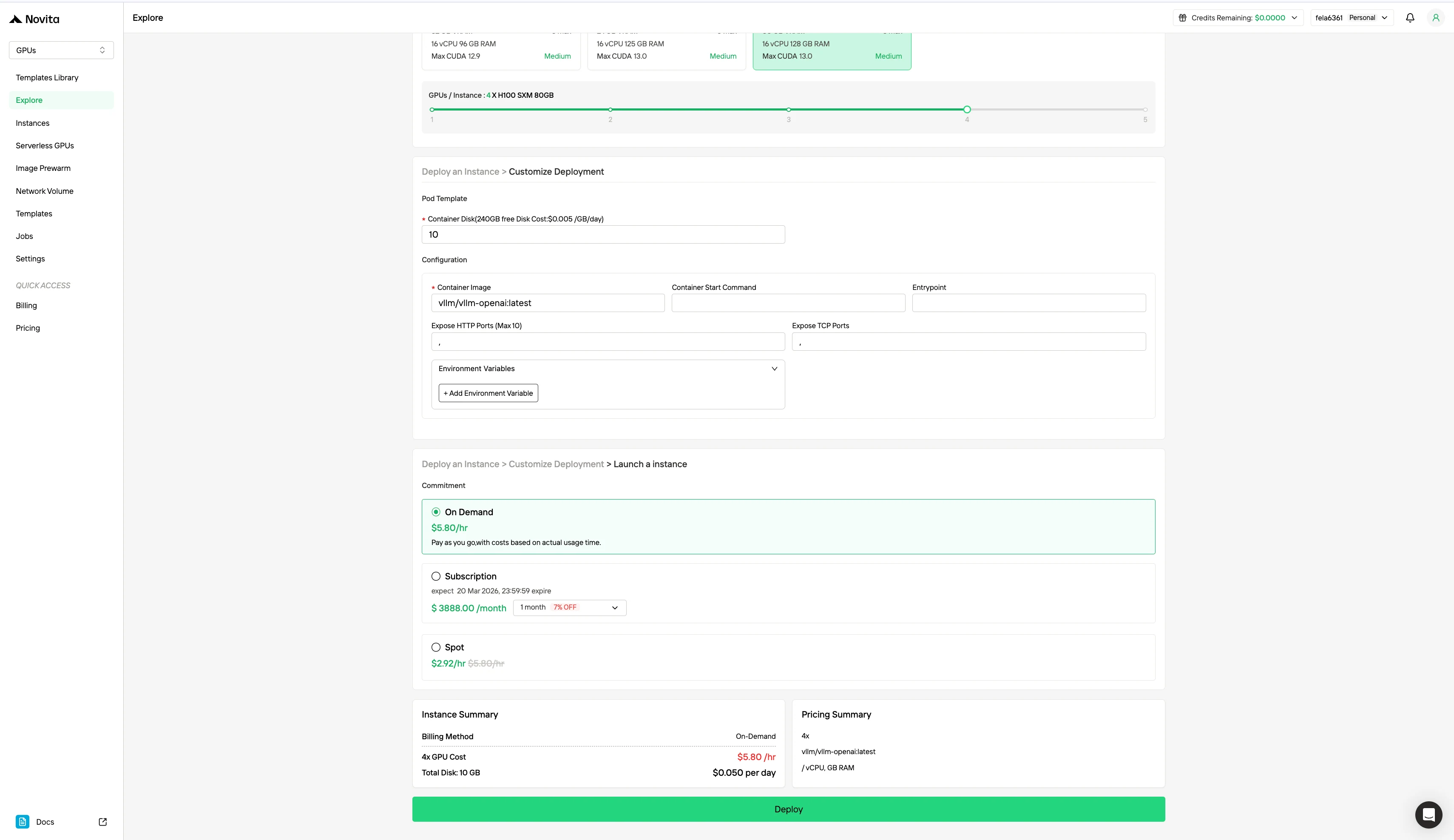
| 仕様 | 課金方法 | GPU | 価格 |
|---|---|---|---|
| H100 80 GB VRAM | オンデマンド | 1x GPU | $1.45/時間 |
| 8x GPU | $11.60/時間 | ||
| スポット | 1x GPU | $0.73/時間 | |
| 8x GPU | $5.84/時間 |
Novita AI のスポットインスタンスは、プラットフォームのアイドル状態または未使用の GPU 容量を活用するコスト最適化された GPU レンタルシステムです。専用ハードウェアを予約して安定した継続的使用を提供するオンデマンドインスタンスとは異なり、スポットインスタンスは中断可能です。GPU がシステムによって再利用されると、ジョブが一時停止または終了される可能性があります。スポットモードはアイドル状態の GPU リソースを再割り当てするため、通常はオンデマンド価格よりも 40~60% 安くなります。
MiniMax M2.5 は、それぞれ異なるシナリオに最適化された 4 つの実用的なアクセスパスを提供します。ほとんどの開発者にとって、100万トークンあたり $0.30/$1.20 の Novita AI の API は、本番環境への最速のパスを提供します。セットアップは 2 分で、OpenAI SDK 互換性があります。Web プレイグラウンドは初回評価に、OpenClaw CLI と Claude Code はパワーユーザー向けのターミナル統合エージェンティックワークフローに適しています。セルフホスティングは、1 日あたり 1000 万トークン以上の場合、または厳格なデータプライバシー要件によりクラウド API が禁止されている場合にのみ経済的に意味を持ちます。その場合、2× H100 80GB での Q4_K_M 量子化が本番対応のパフォーマンスを提供します。
よくある質問
MiniMax M2.5 は他のコーディングモデルと何が違うのですか?
MiniMax M2.5 はスパース MoE アーキテクチャを使用し、合計 229B パラメータですが、トークンあたりアクティブなのはわずか 10B で、Claude Sonnet 4.5 のコストの 8% で SWE-Bench Verified で 80.2% を達成しています。
MiniMax M2.5 を単一のコンシューマー GPU で実行できますか?
いいえ。積極的な量子化を行っても、最小 VRAM 要件は 74GB です。
MiniMax M2.5 は関数呼び出しと構造化出力をサポートしていますか?
はい。MiniMax M2.5 は OpenAI 互換の API 形式を介して関数呼び出しをサポートしています。
Novita AI は、開発者やスタートアップが高性能、信頼性、コスト効率の高いモデルとエージェントアプリケーションを構築、デプロイ、スケーリングするための AI & エージェントクラウドプラットフォームです。
おすすめの記事



