

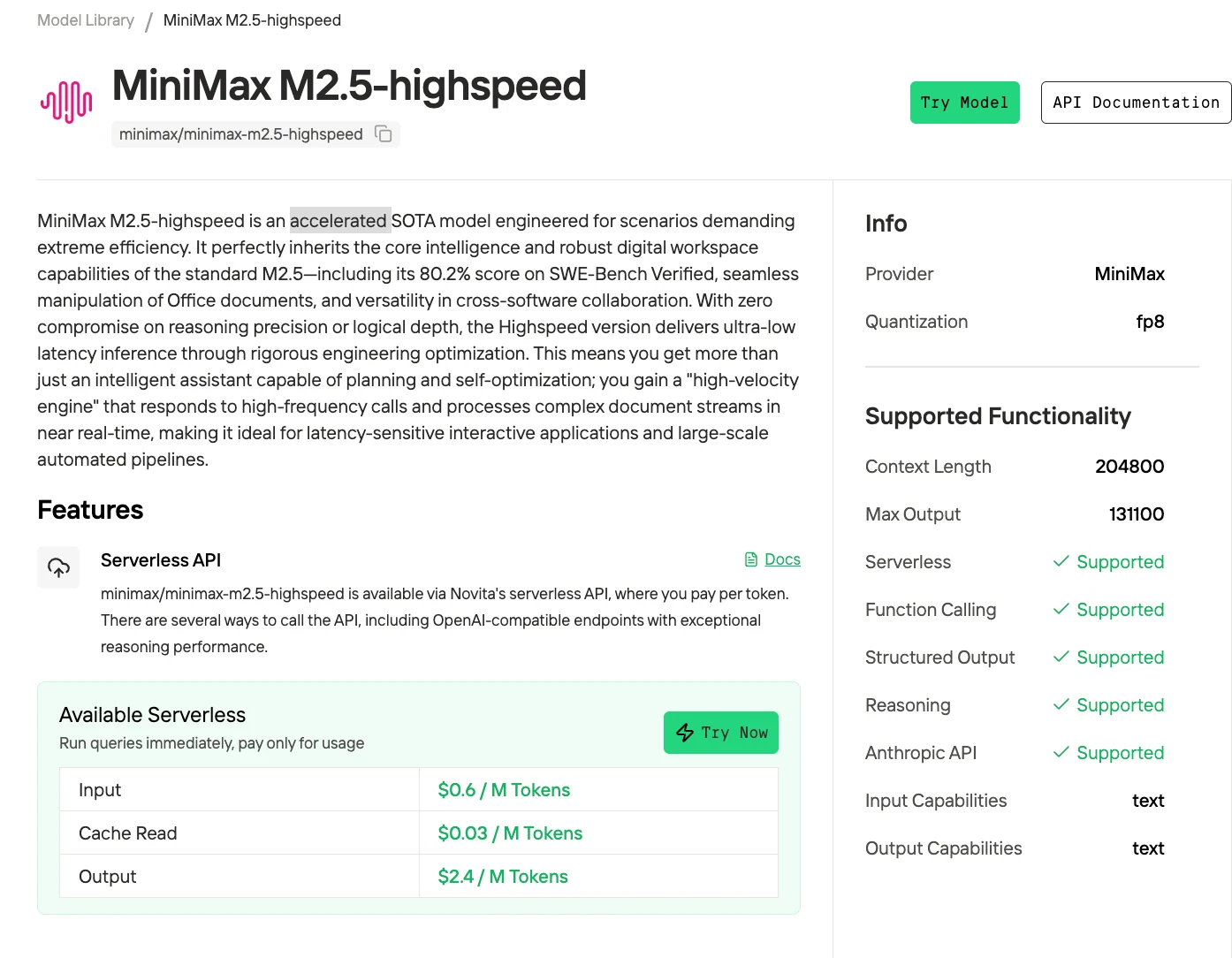
MiniMax M2.5 ist ein Sparse-Mixture-of-Experts-Modell mit 229 Milliarden Parametern, das trotz seiner Größe effiziente Inferenz ermöglicht. Es wurde vom chinesischen KI-Unternehmen MiniMax veröffentlicht und gehört zu den besten Open-Source-Modellen für autonome Programmier- und Web-Navigationsaufgaben, mit Ergebnissen von 80,2 % bei SWE-Bench Verified und 76,3 % bei BrowseComp.
Novita bietet ein beschleunigtes Modell, das die starke Leistung der vorherigen Version beibehält und gleichzeitig die Geschwindigkeit deutlich verbessert.
Vergleich der Zugriffsmethoden
| Methode | Einrichtungszeit | Kosten (1M Token/Tag) | Am besten geeignet für |
|---|---|---|---|
| Web-Playground | 0 Minuten | Kostenlos (ratenbegrenzt) | Erstbewertung, einmalige Aufgaben |
| Novita AI API | 2 Minuten | Eingabe: $0,3 /Mt Cache-Lesen: $0,03 /Mt Ausgabe: $1,2 /Mt |
Produktionsanwendungen, mittleres Volumen, schnelles Prototyping |
| NovitaClaw | 5 Minuten | Eingabe: $0,3 /Mt Cache-Lesen: $0,03 /Mt Ausgabe: $1,2 /Mt |
Terminal-Automatisierung, DevOps-Workflows |
| Claude Code | 5 Minuten | Eingabe: $0,3 /Mt Cache-Lesen: $0,03 /Mt Ausgabe: $1,2 /Mt |
Codebase-Exploration, IDE-Integration |
| Lokal (Q4_K_M) | 30–60 Minuten | Einmalige Investition: 60.000–90.000 $ | Hochvolumige Produktion, Datenschutzanforderungen |
| Cloud-GPU | 5 Minuten | 8x GPU $11,60/h | Kurzfristige Experimente, Burst-Workloads, Testen großer Modelle |
1. Web-Playground
Der schnellste, barrierefreie Einstiegspunkt ist der Web-Playground von Novita AI – keine Anmeldung, keine API-Schlüssel, sofortige Evaluierung. Dies eignet sich am besten für schnelle Funktionstests, bevor Sie sich für eine API-Integration oder lokale Bereitstellung entscheiden.
Typische Anwendungsfälle: Prompt-Engineering, Qualitätsbewertung, Testen von Programmieraufgaben, seitlicher Vergleich von Ausgaben mit anderen Modellen. Der Web-Playground ist ideal für Erstbewertungen und einmalige Aufgaben – keine technische Einrichtung erforderlich.
Probieren Sie MiniMax M2.5 jetzt aus!
2. Novita AI API (Für die meisten Entwickler empfohlen)
Warum sollten Sie die Novita AI API wählen?
- OpenAI- und Anthropic-kompatibel
- Wettbewerbsfähige Preise: 0,30 $/1,20 $ pro 1M Token.
- Unterstützung von Cache-Preisen: Die Cache-Preisgestaltung ermöglicht es Ihnen, zuvor gespeicherte Prompts wiederzuverwenden, was wiederholte Berechnungen reduziert und die Gesamtkosten senkt.
Einrichtungsanleitung
Schritt 1: Anmelden und auf die Modellbibliothek zugreifen
Melden Sie sich bei Ihrem Konto an und klicken Sie auf die Schaltfläche Modellbibliothek.

Schritt 2: Wählen Sie Ihr Modell
Durchstöbern Sie die verfügbaren Optionen und wählen Sie das Modell, das Ihren Anforderungen entspricht.

Schritt 3: Starten Sie Ihre kostenlose Testversion
Starten Sie Ihre kostenlose Testversion, um die Funktionen des ausgewählten Modells kennenzulernen.
Probieren Sie jetzt das günstige MiniMax M2.5 aus!
Schritt 4: Holen Sie sich Ihren API-Schlüssel
Zur Authentifizierung bei der API stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Wenn Sie die Seite „Einstellungen“ aufrufen, können Sie den API-Schlüssel wie in der Abbildung gezeigt kopieren.

Schritt 5: Installieren Sie die API
Installieren Sie die API über den für Ihre Programmiersprache spezifischen Paketmanager.
Nach der Installation importieren Sie die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit dem Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Nutzung der Chat-Completions-API für Python-Nutzer.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="minimax/minimax-m2.5",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131100,
temperature=0.7
)
print(response.choices[0].message.content)
3. Zugriff über Code-Tools
NovitaClaw
NovitaClaw ist ein Kommandozeilen-Tool zum Bereitstellen und Verwalten von persistenten OpenClaw-Agenten in der Novita Agent Sandbox. Mit einem einzigen Befehl können Sie eine vollständig gehostete Agenteninstanz starten, die kontinuierlich läuft – keine Sitzungslimits oder manuellen Neustarts erforderlich. Nach der Bereitstellung kann der Agent über mehrere Schnittstellen aufgerufen und gesteuert werden, darunter die CLI, eine webbasierte UI oder externe Automatisierungsskripte.
Erste Schritte
Voraussetzungen
Stellen Sie vor Beginn sicher, dass Sie über Folgendes verfügen:
- Python ist installiert
- Einen Novita API-Schlüssel (erstellen oder verwalten Sie Schlüssel im Schlüsselverwaltung)
Schritt 1: NovitaClaw installieren
macOS / Linux:
sudo pip3 install novitaclaw
Windows PowerShell:
pip install novitaclaw
Überprüfung: Führen Sie novitaclaw --help aus. Wenn Sie eine Liste von Befehlen sehen, war die Installation erfolgreich.
Schritt 2: Legen Sie Ihren API-Schlüssel fest
macOS / Linux:
export NOVITA_API_KEY=sk_your_api_key
Windows PowerShell:
$env:NOVITA_API_KEY = "sk_your_api_key"
Schritt 3: Starten Sie Ihre Instanz
novitaclaw launch
Bei Erfolg gibt die CLI folgendes zurück:
- Web-UI-URL – Chatten Sie mit Ihrem Agenten
- Gateway-WebSocket-URL & Token – Für programmatischen Zugriff
- Web-Terminal-URL – Browserbasierter Terminalzugriff
- Dateimanager-URL – Verwalten von Arbeitsbereichsdateien
- Anmeldedaten – Für Web-Terminal und Dateimanager
Öffnen Sie die Web-UI-URL, wechseln Sie zum Tab Chat und beginnen Sie, Ihren Agenten zu nutzen.
Modelle konfigurieren
Ihre Instanz ist standardmäßig mit einem von Novita gehosteten Modell vorkonfiguriert. Um es anzupassen:
Gehen Sie zu:
Einstellungen → Konfiguration → Raw (JSON5-Ansicht)
Klicken Sie auf „secrets redacted“, um die vollständige Konfiguration anzuzeigen.
Schritt 1: Ein Modell registrieren
Fügen Sie einen neuen Eintrag unter models.providers.novita.models hinzu:
{
"models": {
"providers": {
"novita": {
"models": [
{
"id": "model-id",
"name": "display name",
"reasoning": true,
"input": ["text"],
"contextWindow": 200000,
"maxTokens": 50000
}
]
}
}
}
}
Schritt 2: Als Primärmodell oder Fallback festlegen
Aktualisieren Sie agents.defaults:
{
"agents": {
"defaults": {
"model": {
"primary": "novita/model-id",
"fallbacks": ["novita/fallback-model-id"]
}
}
}
}
Claude Code
Claude Code ist der offizielle CLI-Agent von Anthropic, der primär für Claude-Modelle entwickelt wurde, aber mit Anthropic-API-kompatiblen Endpunkten wie Novita AI kompatibel ist. Er zeichnet sich durch gesamte Repository-Analysen, komplexes Debugging und agentische Programmierzyklen aus.
Einrichtung:
1. Claude Code installieren:
#macOS, Linux, WSL:
curl -fsSL https://claude.ai/install.sh | bash
#Windows PowerShell:
irm https://claude.ai/install.ps1 | iex
#Windows CMD:
curl -fsSL https://claude.ai/install.cmd -o install.cmd && install.cmd && del install.cmd
#Windows requires Git for Windows. Install it first if you don't have it.
2. Umgebungsvariablen festlegen:
# Set the Anthropic SDK compatible API endpoint provided by Novita.
export ANTHROPIC_BASE_URL="https://api.novita.ai/anthropic"
export ANTHROPIC_AUTH_TOKEN="<Novita API Key>"
# Set the model provided by Novita.
export ANTHROPIC_MODEL="minimax/minimax-m2.5"
export ANTHROPIC_SMALL_FAST_MODEL="minimax/minimax-m2.5"
3. Starten Sie Claude Code in Ihrem Projekt:
cd /path/to/project
claude .
Am besten geeignet für: Codebase-Exploration, mehrstufiges Debugging, autonome Implementierung von Funktionen, Integration mit VSCode/Cursor über Terminal-Plugins.
4. Lokale Bereitstellung
Die sparse MoE-Architektur von MiniMax M2.5 (229B insgesamt, 10B aktiv) macht die lokale Bereitstellung auf High-End-Consumer-Hardware oder Multi-GPU-Setups möglich. Das Modell benötigt 457 GB bei voller BF16-Präzision, aber Quantisierung über die GGUF-Quantisierungen von Unsloth reduziert dies auf 101 GB (Dynamische 3-Bit) oder 138 GB (Q4_K_M).
Hardware-Anforderungen
| Quantisierung | Benötigter VRAM | Hardware-Beispiel |
|---|---|---|
| BF16 (volle Präzision) | 457 GB | 6× H100 80 GB |
| Q8_0 | 243 GB | 4× H100 80 GB |
| Q6_K | 188 GB | 3× H100 80 GB |
| Q4_K_M (empfohlen) | 138 GB | 2× H100 80 GB |
| Q3_K_M | 109 GB | 2× H100 80 GB |
| UD-IQ2_XXS (Minimum) | 74 GB | Einzelne H100 80 GB |
Installation (llama.cpp)
git clone https://github.com/ggml-org/llama.cpp.git
cd llama.cpp
cmake -B build -DCMAKE_BUILD_TYPE=Release
cmake --build build -j"$(nproc)"
# Install HF CLI if needed
pip install -U "huggingface_hub[cli]"
# Download a specific quant (example: Q3_K_M)
hf download unsloth/MiniMax-M2.5-GGUF \
--include "Q3_K_M/*" \
--local-dir ./models
# Check files
find ./models -name "*.gguf"
# Run (use the FIRST shard)
./build/bin/llama-cli \
-m ./models/Q3_K_M/MiniMax-M2.5-Q3_K_M-00001-of-00004.gguf \
-p "Write a Python function to check if a number is prime"
Installation von Cloud-GPUs (kosteneffektiv)
Schritt 1: Konto erstellen
Erstellen Sie Ihr Novita AI Konto über unsere Website. Nach der Registrierung navigieren Sie zum Bereich „Entdecken“ in der linken Seitenleiste, um unsere GPU-Angebote einzusehen und Ihre KI-Entwicklungsreise zu beginnen.

Schritt 2: Vorlagen und GPU-Server erkunden
Wählen Sie aus Vorlagen wie PyTorch, TensorFlow oder CUDA, die zu Ihren Projektanforderungen passen. Wählen Sie anschließend Ihre bevorzugte GPU-Konfiguration – Optionen umfassen die leistungsstarken L40S, RTX 4090 oder A100 SXM4, jeweils mit unterschiedlichen VRAM-, RAM- und Spezifikationen.
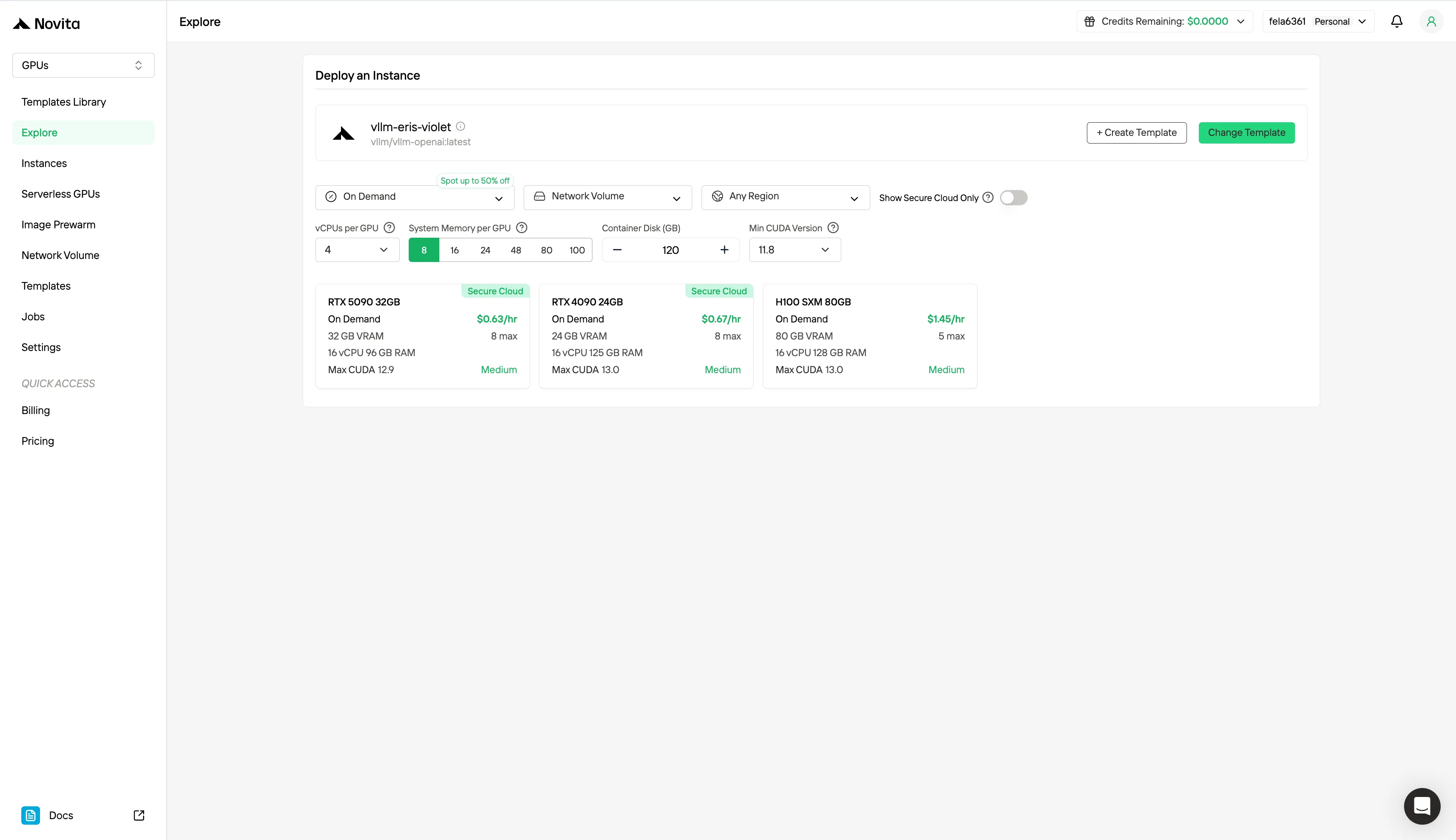
Schritt 3: Passen Sie Ihre Bereitstellung an
Passen Sie Ihre Umgebung an, indem Sie Ihr bevorzugtes Betriebssystem und Konfigurationsoptionen auswählen, um eine optimale Leistung für Ihre spezifischen KI-Workloads und Entwicklungsanforderungen zu gewährleisten.
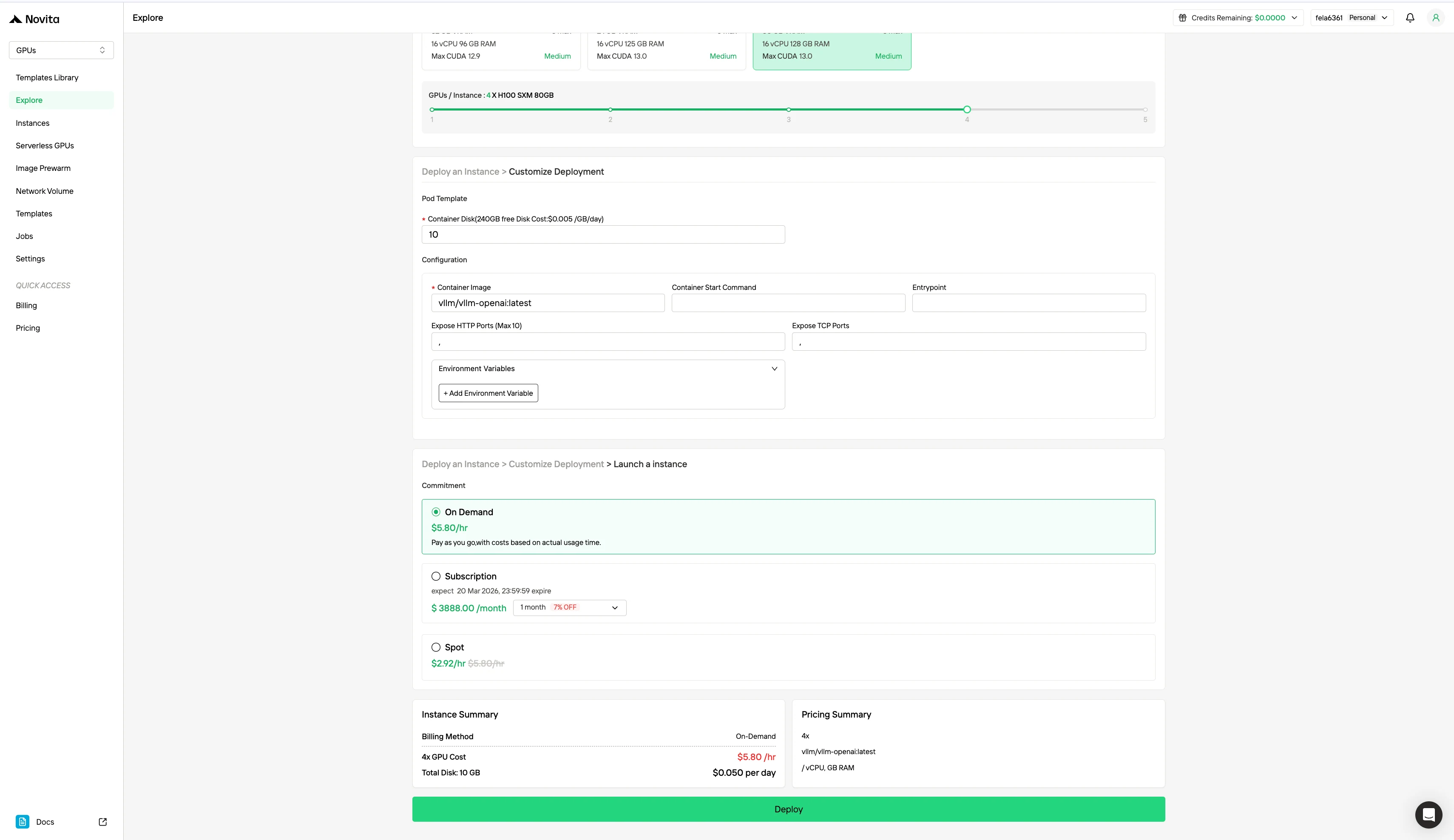
| Spezifikation | Abrechnungsmodell | GPU | Preis |
|---|---|---|---|
| H100 80 GB VRAM | On-Demand | 1x GPU | 1,45 $/h |
| 8x GPU | 11,60 $/h | ||
| Spot | 1x GPU | 0,73 $/h | |
| 8x GPU | 5,84 $/h |
Probieren Sie kosteneffektive GPUs aus!
Novita AI Spot-Instanzen sind ein kosteneffizientes GPU-Miet system, das die ungenutzte oder freie GPU-Kapazität der Plattform nutzt. Im Gegensatz zu On-Demand-Instanzen, die dedizierte Hardware für stabile, kontinuierliche Nutzung reservieren, sind Spot-Instanzen unterbrechbar – Ihr Auftrag kann angehalten oder beendet werden, wenn die GPU vom System zurückgefordert wird. Da der Spot-Modus ansonsten ungenutzte GPU-Ressourcen neu zuweist, ist er in der Regel 40–60 % günstiger als On-Demand-Preise.
MiniMax M2.5 bietet vier praktische Zugriffspfade, die jeweils für unterschiedliche Szenarien optimiert sind. Für die meisten Entwickler ist die Novita AI API zu 0,30 $/1,20 $ pro Million Token der schnellste Weg in die Produktion – die Einrichtung dauert nur 2 Minuten und ist mit dem OpenAI SDK kompatibel. Der Web-Playground dient der Erstbewertung, während die OpenClaw CLI und Claude Code terminalintegrierte agentische Workflows für Power-User ermöglichen. Self-Hosting ist erst ab 10 Millionen Token pro Tag wirtschaftlich sinnvoll oder wenn strenge Datenschutzanforderungen die Nutzung von Cloud-APIs verbieten – in diesem Fall liefert die Q4_K_M-Quantisierung auf 2× H100 80 GB produktionsreife Leistung.
Häufig gestellte Fragen
Was unterscheidet MiniMax M2.5 von anderen Programmiermodellen?
MiniMax M2.5 verwendet eine sparse MoE-Architektur mit 229B Gesamtparametern, aber nur 10B aktiven Parametern pro Token, und erreicht 80,2 % bei SWE-Bench Verified zu 8 % der Kosten von Claude Sonnet 4.5.
Kann ich MiniMax M2.5 auf einer einzelnen Consumer-GPU ausführen?
Nein – die minimale VRAM-Anforderung beträgt selbst bei aggressiver Quantisierung 74 GB.
Unterstützt MiniMax M2.5 Funktionsaufrufe und strukturierte Ausgaben?
Ja – MiniMax M2.5 unterstützt Funktionsaufrufe über das OpenAI-kompatible API-Format.
Novita AI ist eine KI- & Agenten-Cloud-Plattform, die Entwicklern und Startups hilft, Modelle und agentische Anwendungen mit hoher Leistung, Zuverlässigkeit und Kosteneffizienz zu entwickeln, bereitzustellen und zu skalieren.
Empfohlene Lektüre



