

Exécuter des assistants de codage IA localement est devenu une priorité pour les développeurs qui recherchent confidentialité, contrôle des coûts et utilisation illimitée. Mais trouver un modèle qui équilibre puissance et accessibilité sur du matériel grand public reste un défi. Qwen3-Coder-Next, publié en 2026, promet de résoudre ce problème avec 80 milliards de paramètres au total, mais seulement 3 milliards activés par jeton : il est donc exécutable sur des GPU grand public haut de gamme, tout en offrant des résultats de benchmark qui rivalisent avec des modèles dotés de 10 à 20 fois plus de paramètres actifs.
Ce guide présente les trois méthodes principales pour accéder à Qwen3-Coder-Next : déploiement local via Hugging Face/Transformers, inférence quantifiée avec llama.cpp/Unsloth, et accès via API grâce à Novita AI. Nous explorerons les retours d’expérience concrets de développeurs qui ont testé le modèle, les exigences matérielles selon les différents niveaux de quantification, ainsi que les configurations spécifiques qui offrent des performances optimales pour les tâches de codage agentiques.
Spécifications du modèle : ce qui rend Qwen3-Coder-Next différent
| Spécification | Détails |
|---|---|
| Paramètres totaux | 80B |
| Paramètres activés | 3B par jeton/inférence |
| Longueur de contexte | 256K jetons natif |
| Architecture | Hybride MoE |
| Licence | Poids ouverts |
| Focus d’entraînement | Codage agentique (raisonnement à long terme, utilisation d’outils, récupération des échecs d’exécution) |
Performance aux benchmarks : comment Qwen3-Coder-Next se compare
Essayez Qwen 3 Coder Next dès maintenant !
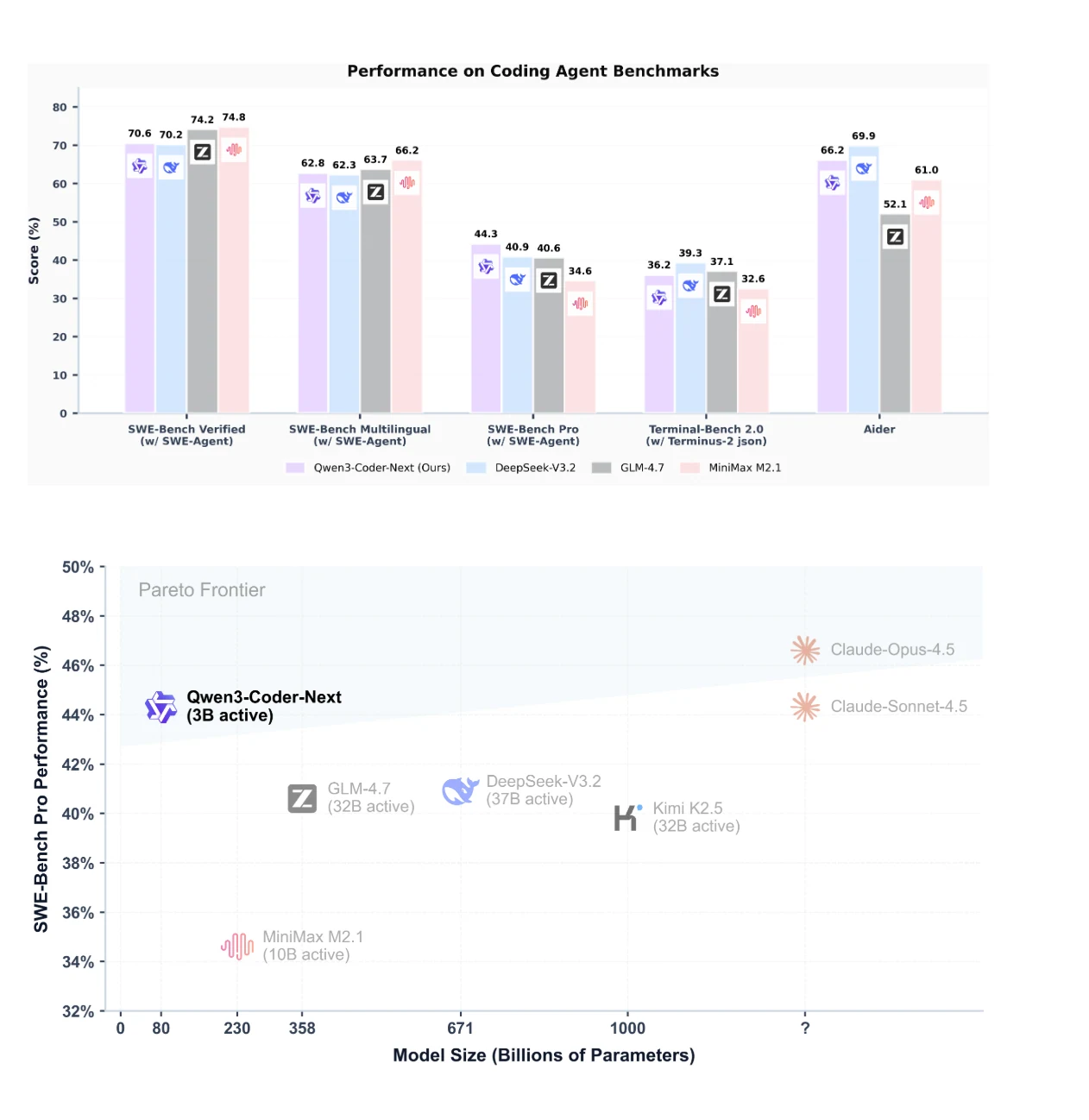
Qwen3-Coder-Next obtient des performances de premier plan sur SWE-Bench Pro et démontre un excellent compromis entre performance et efficacité des paramètres.
Méthode 1 : API efficace via l’API Novita
L’accès via API est pertinent lorsque :
- Vous ne disposez pas de matériel avec plus de 35 Go de VRAM
- Vous avez besoin d’une disponibilité immédiate sans temps de configuration
- Votre utilisation est sporadique plutôt que continue
- Vous souhaitez éviter la maintenance d’infrastructure
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Bibliothèque de modèles.

Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.

Étape 3 : Démarrez votre essai gratuit
Commencez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Essayez Qwen 3 Coder Next dès maintenant !
Étape 4 : Récupérez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. En accédant à la page « Paramètres », vous pouvez copier la clé API comme indiqué sur l’image.

Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.
Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec le LLM Novita AI. Voici un exemple d’utilisation de l’API de complétion de chat pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3-coder-next",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].message.content)
Méthode 2 : Déploiement local via Hugging Face Transformers
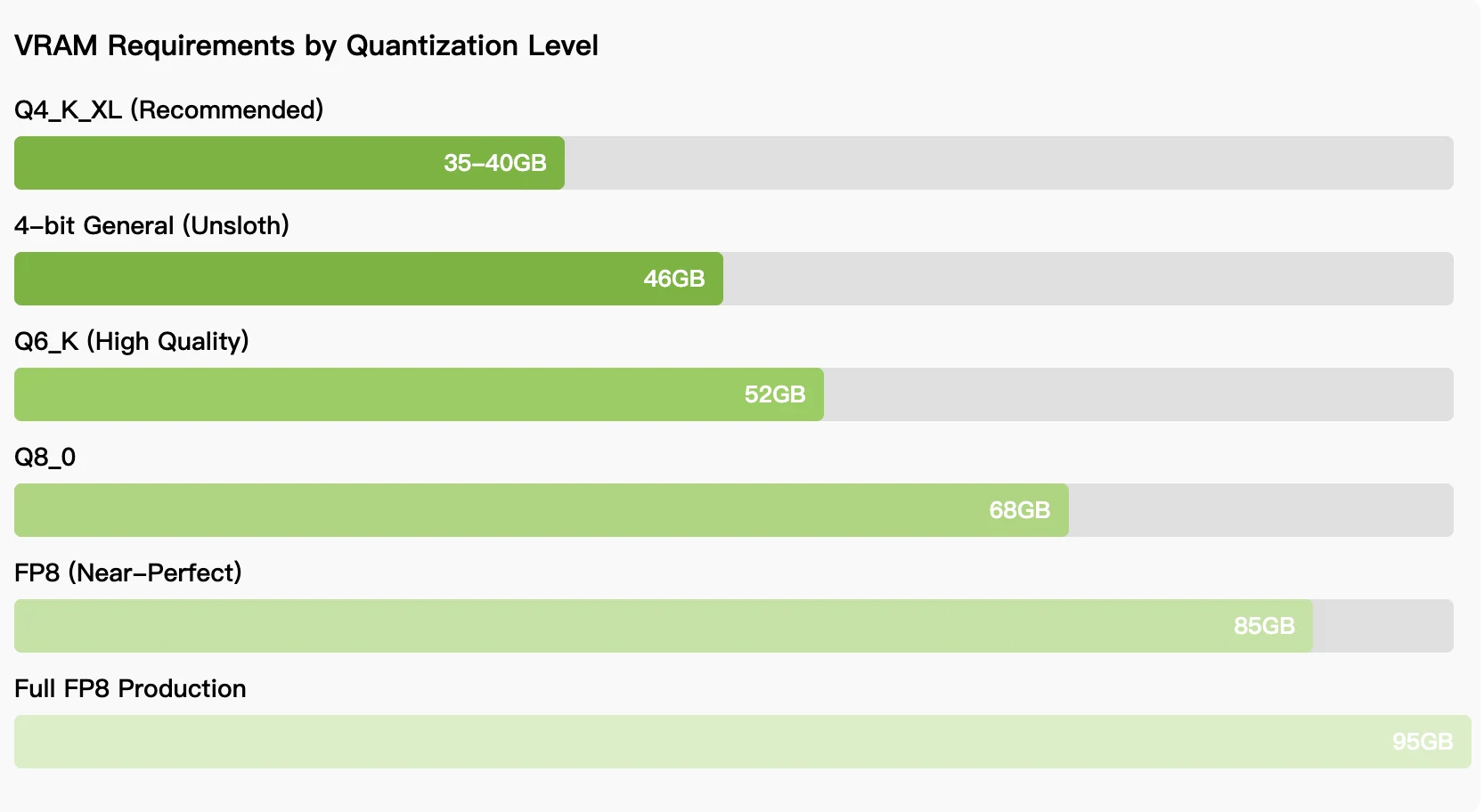
Exigences matérielles requises :
- Téléchargez les poids du modèle depuis HuggingFace ou ModelScope
- Choisissez le framework d’inférence : vLLM ou SGLang sont pris en charge
- Suivez le guide de déploiement dans le dépôt GitHub officiel
Vous choisirez un endpoint dédié lorsque vous avez besoin d’une inférence stable et haute performance, d’un contrôle personnalisé du modèle et d’un coût réduit pour des charges de travail continues ou importantes, plutôt que de maintenir des GPU et une infrastructure locaux.
Essayez l’endpoint dédié dès maintenant !
Paramètres de génération recommandés
Les paramètres optimaux pour Qwen3-Coder-Next diffèrent de ceux des modèles de codage classiques :
- Température : 1,0 (plus élevée que pour les modèles de codage classiques)
- Top_P : 0,95
- Top_K : 40
- Min_P : 0,01
Ces paramètres activent le mode non-raisonnement du modèle pour des réponses de code rapides tout en maintenant la qualité.
Méthode 3 : Frameworks d’inférence LLM
llama.cpp est un framework d’inférence LLM léger en C/C++ principalement conçu pour exécuter efficacement des modèles quantifiés GGUF sur des processeurs ou des appareils à faible VRAM. Ses principaux avantages sont une configuration facile, de bonnes performances sur CPU, une excellente prise en charge des puces Apple Silicon macOS et des options de quantification flexibles, tandis que ses points faibles sont un débit plus faible sous forte concurrence et une mise à l’échelle GPU moins performante que les frameworks modernes de service sur GPU.
# macOS avec Homebrew
brew install llama.cpp
# Ou compiler depuis les sources
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
make
# Utilisation de la CLI Hugging Face (recommandé)
llama-cli -hf unsloth/Qwen3-Coder-Next-GGUF:UD-Q4_K_XL
# Ou téléchargement manuel depuis :
# https://huggingface.co/unsloth/Qwen3-Coder-Next-GGUF
llama-server \
-hf unsloth/Qwen3-Coder-Next-GGUF:UD-Q4_K_XL \
--fit on \
--seed 3407 \
--temp 1.0 \
--top-p 0.95 \
--min-p 0.01 \
--top-k 40 \
--jinja \
--port 8080
Ollama est un runtime et framework de service LLM convivial pour les débutants, qui encapsule les backends d’inférence (souvent llama.cpp) dans un workflow simple de « téléchargement et exécution ». Ses points forts sont une installation extrêmement simple, une gestion automatique des modèles et un serveur API local prêt à l’emploi, tandis que ses limites sont un contrôle réduit sur les paramètres d’inférence bas niveau, moins de flexibilité pour le réglage et une dépendance à l’écosystème de packaging de modèles Ollama.
# Installer Ollama
curl -fsSL https://ollama.com/install.sh | sh
# Télécharger et exécuter le modèle
ollama pull qwen3-coder-next
ollama run qwen3-coder-next
vLLM est un framework d’inférence et de service GPU de qualité production, optimisé pour un débit élevé et la concurrence multi-utilisateurs, largement alimenté par une gestion efficace du cache KV (PagedAttention). Ses avantages sont d’excellentes performances de service, une forte évolutivité sur plusieurs GPU et des capacités de déploiement matures, tandis que ses inconvénients sont une complexité système plus élevée, des exigences plus importantes en termes de GPU/VRAM et une moins bonne adaptabilité aux environnements sans GPU.
# Installer vLLM
pip install 'vllm>=0.15.0'
# Démarrer le serveur
vllm serve Qwen/Qwen3-Coder-Next \
--port 8000 \
--tensor-parallel-size 2 \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder
SGLang est un framework d’inférence et de service LLM haute performance, optimisé pour un décodage rapide et des pipelines d’exécution complexes, notamment pour les appels d’outils et les workflows de type agent. Ses points forts sont une optimisation agressive des performances et une forte prise en charge des pipelines de génération multi-étapes avancés, tandis que ses inconvénients incluent une complexité de configuration plus élevée, un écosystème moins mature que vLLM et une dépendance plus forte à l’infrastructure GPU pour obtenir les meilleurs résultats.
# Installer SGLang
pip install 'sglang[all]>=v0.5.8'
# Lancer le serveur
python -m sglang.launch_server \
--model Qwen/Qwen3-Coder-Next \
--port 30000 \
--tp-size 2 \
--tool-call-parser qwen3_coder
Méthode 4 : Intégration avec les outils d’agent de codage
Récupérez votre clé API dès maintenant !
Connectez facilement Novita AI à des plateformes partenaires comme Claude code,Cursor,Trae,Continue, Codex, OpenCode, AnythingLLM,LangChain, Dify et Langflow grâce à des connecteurs officiels et des guides d’intégration étape par étape.
Pour les équipes qui privilégient le contrôle des coûts et l’utilisation illimitée, l’exigence de 35 à 46 Go de VRAM pour l’inférence quantifiée rend le modèle accessible aux RTX 5090, aux GPU AMD Instinct ou aux MacBook de 64 Go. Le choix entre déploiement local et accès via API dépend des modes d’utilisation : le travail de développement continu favorise le déploiement local malgré la complexité de la configuration, tandis que les cas d’utilisation sporadiques bénéficient de l’accès serverless. À mesure que le modèle mûrit et que les techniques de quantification s’améliorent, l’écart de performance entre les déploiements locaux et hébergés continue de se réduire, faisant de Qwen3-Coder-Next une option viable pour les développeurs qui recherchent des alternatives aux assistants de codage propriétaires.
Questions fréquemment posées
Quel matériel est nécessaire pour exécuter Qwen3-Coder-Next localement ?
Vous avez besoin de 35 à 46 Go de VRAM pour une quantification 4 bits, ce qui est possible avec une RTX 5090, un AMD Radeon 7900 XTX, des GPU AMD Instinct ou des MacBook de 64 Go dotés de mémoire unifiée. La pleine précision nécessite 85 à 95 Go de VRAM.
Comment la performance de Qwen3-Coder-Next se compare-t-elle à celle de modèles plus grands ?
Il surpasse des modèles dotés de 10 à 20 fois plus de paramètres actifs comme DeepSeek-V3.2 sur les benchmarks de codage agentique, avec un score de 74,2 % sur SWE-Bench Verified et 69,9 % sur Aider.
Quels sont les paramètres de génération recommandés pour Qwen3-Coder-Next ?
Utilisez temperature=1.0, top_p=0,95, top_k=40 et min_p=0,01 pour une génération de code optimale. Ces paramètres activent le mode non-raisonnement pour des réponses rapides tout en maintenant la qualité.
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles IA grâce à notre API intuitive, tout en fournissant un cloud GPU abordable et fiable pour la construction et la mise à l’échelle.
Lectures recommandées



