

Executar assistentes de codificação de IA localmente tornou-se uma prioridade para desenvolvedores que buscam privacidade, controle de custos e uso ilimitado. Mas encontrar um modelo que equilibre poder e acessibilidade em hardware de consumo continua sendo um desafio. O Qwen3-Coder-Next, lançado em 2026, promete resolver isso com 80B de parâmetros totais, mas apenas 3B ativados por token — tornando-o executável em GPUs de consumo de ponta, ao mesmo tempo que entrega resultados de benchmark que rivalizam com modelos com 10 a 20 vezes mais parâmetros ativos.
Este guia aborda os três métodos principais para acessar o Qwen3-Coder-Next: implantação local via Hugging Face/Transformers, inferência quantizada com llama.cpp/Unsloth e acesso via API pela Novita AI. Vamos explorar experiências reais de usuários de desenvolvedores que testaram o modelo, os requisitos de hardware para diferentes níveis de quantização e as configurações específicas que entregam desempenho ideal para tarefas de codificação autônoma.
Especificações do Modelo: O que Torna o Qwen3-Coder-Next Diferente
| Especificação | Detalhes |
|---|---|
| Total de Parâmetros | 80B |
| Parâmetros Ativados | 3B por token/inferência |
| Comprimento de Contexto | 256K tokens nativos |
| Arquitetura | MoE híbrido |
| Licença | Pesos abertos |
| Foco de Treinamento | Codificação autônoma (raciocínio de longo prazo, uso de ferramentas, recuperação de falhas de execução) |
Desempenho em Benchmark: Como o Qwen3-Coder-Next se Compara
Experimente o Qwen 3 Coder Next Agora!
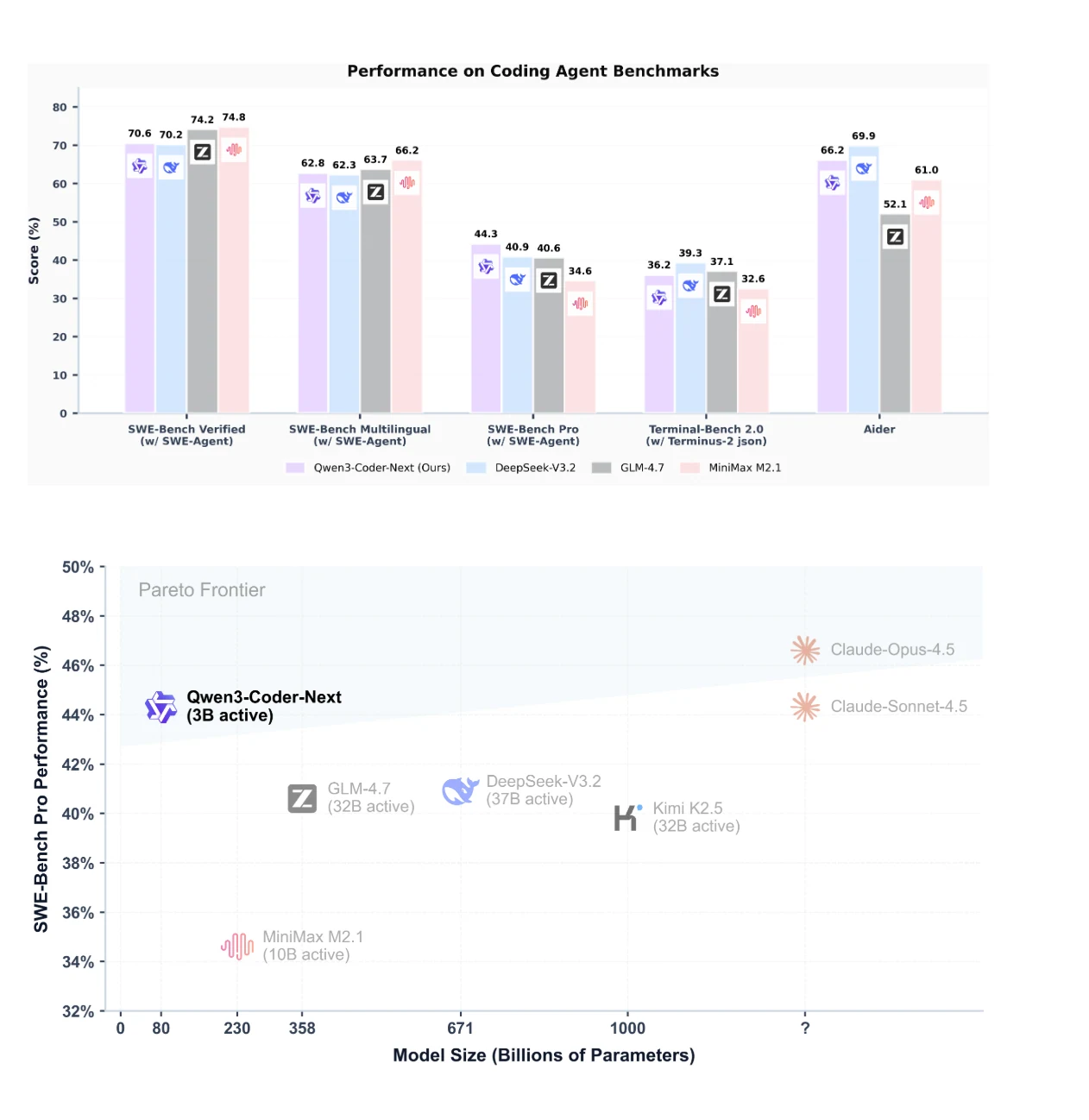
O Qwen3-Coder-Next alcança desempenho de liderança no SWE-Bench Pro e demonstra uma excelente relação desempenho-eficiência de parâmetros.
Método 1: API Eficaz via Novita API
O acesso via API faz sentido quando:
- Você não tem hardware com 35GB ou mais de VRAM
- Precisa de disponibilidade instantânea sem tempo de configuração
- Seu uso é esporádico, e não contínuo
- Deseja evitar manutenção de infraestrutura
Passo 1: Faça Login e Acesse a Biblioteca de Modelos
Faça login na sua conta e clique no botão Biblioteca de Modelos.

Passo 2: Escolha Seu Modelo
Navegue pelas opções disponíveis e selecione o modelo que atende às suas necessidades.

Passo 3: Inicie Seu Teste Gratuito
Inicie seu teste gratuito para explorar as capacidades do modelo selecionado.
Experimente o Qwen 3 Coder Next Agora!
Passo 4: Obtenha Sua Chave de API
Para autenticar com a API, forneceremos uma nova chave de API. Acessando a página de “Configurações“, você pode copiar a chave de API conforme indicado na imagem.

Passo 5: Instale a API
Instale a API usando o gerenciador de pacotes específico da sua linguagem de programação.
Após a instalação, importe as bibliotecas necessárias para o seu ambiente de desenvolvimento. Inicialize a API com sua chave de API para começar a interagir com o LLM da Novita AI. Este é um exemplo de uso da API de conclusões de chat para usuários de Python.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3-coder-next",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].message.content)
Método 2: Implantação Local via Hugging Face Transformers
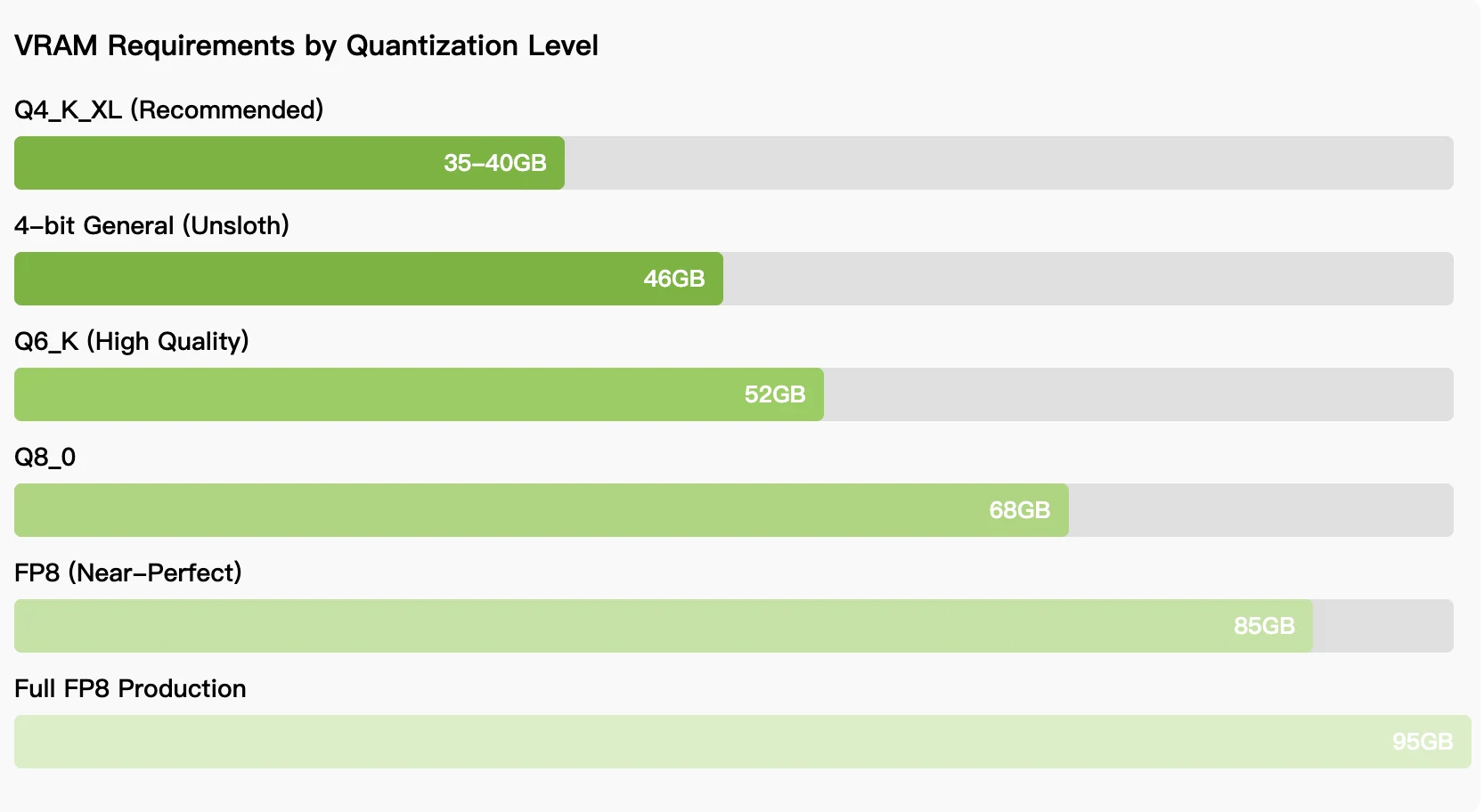
Requisitos de Hardware:
- Baixe os pesos do modelo no HuggingFace ou no ModelScope
- Escolha o framework de inferência: vLLM ou SGLang são suportados
- Siga o guia de implantação no repositório oficial do GitHub
Você escolheria um endpoint dedicado quando precisar de inferência de alto desempenho estável, controle personalizado do modelo e custo menor sob cargas de trabalho contínuas ou pesadas, em vez de manter GPUs e infraestrutura locais.
Experimente o Endpoint Dedicado Agora!
Parâmetros de Geração Recomendados
As configurações ideais para o Qwen3-Coder-Next diferem dos modelos de codificação típicos:
- Temperatura: 1.0 (maior que a de modelos de codificação típicos)
- Top_P: 0.95
- Top_K: 40
- Min_P: 0.01
Essas configurações ativam o modo de não raciocínio do modelo para respostas de código rápidas, mantendo a qualidade.
Método 3: Frameworks de Inferência de LLM
O llama.cpp é um framework de inferência de LLM leve em C/C++ projetado principalmente para executar modelos quantizados GGUF de forma eficiente em CPUs ou dispositivos com pouca VRAM. Suas principais vantagens são configuração fácil, desempenho forte em CPU, suporte excelente ao Apple Silicon do macOS e opções de quantização flexíveis, enquanto suas fraquezas são vazão menor sob alta concorrência e escalabilidade de GPU mais fraca em comparação com frameworks modernos de serviço de GPU.
# macOS com Homebrew
brew install llama.cpp
# Ou compile a partir do código fonte
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
make
# Usando a CLI do Hugging Face (recomendado)
llama-cli -hf unsloth/Qwen3-Coder-Next-GGUF:UD-Q4_K_XL
# Ou baixe manualmente em:
# https://huggingface.co/unsloth/Qwen3-Coder-Next-GGUF
llama-server \
-hf unsloth/Qwen3-Coder-Next-GGUF:UD-Q4_K_XL \
--fit on \
--seed 3407 \
--temp 1.0 \
--top-p 0.95 \
--min-p 0.01 \
--top-k 40 \
--jinja \
--port 8080
O Ollama é um runtime e framework de serviço de LLM amigável para iniciantes que envolve backends de inferência (geralmente llama.cpp) em um fluxo de trabalho simples de “puxar e executar“. Seus pontos fortes são instalação extremamente simples, gerenciamento automático de modelos e um servidor de API local pronto para uso, enquanto suas limitações são controle reduzido sobre parâmetros de inferência de baixo nível, menos flexibilidade para ajustes e dependência do ecossistema de empacotamento de modelos do Ollama.
# Instale o Ollama
curl -fsSL https://ollama.com/install.sh | sh
# Baixe e execute o modelo
ollama pull qwen3-coder-next
ollama run qwen3-coder-next
O vLLM é um framework de inferência e serviço de GPU de nível de produção otimizado para alto throughput e concorrência multiusuário, largamente alimentado por gerenciamento eficiente de cache KV (PagedAttention). Suas vantagens são desempenho de serviço excelente, escalabilidade forte entre GPUs e capacidades de implantação maduras, enquanto suas desvantagens são complexidade de sistema maior, requisitos mais pesados de GPU/VRAM e ser menos adequado para ambientes apenas com CPU.
# Instale o vLLM
pip install 'vllm>=0.15.0'
# Inicie o servidor
vllm serve Qwen/Qwen3-Coder-Next \
--port 8000 \
--tensor-parallel-size 2 \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder
O SGLang é um framework de inferência e serviço de LLM de alto desempenho otimizado para decodificação rápida e pipelines de execução complexos, especialmente fluxos de trabalho de chamada de ferramentas e estilo agente. Seus pontos fortes são otimização agressiva de desempenho e suporte forte a pipelines de geração multietapa avançados, enquanto suas desvantagens incluem complexidade de configuração maior, ecossistema menos maduro que o vLLM e dependência mais forte de infraestrutura de GPU para melhores resultados.
# Instale o SGLang
pip install 'sglang[all]>=v0.5.8'
# Inicie o servidor
python -m sglang.launch_server \
--model Qwen/Qwen3-Coder-Next \
--port 30000 \
--tp-size 2 \
--tool-call-parser qwen3_coder
Método 4: Integração com Ferramentas de Agente de Código
Obtenha Sua Chave de API Agora!
Conecte facilmente a Novita AI com plataformas parceiras como Claude code, Cursor, Trae, Continue, Codex, OpenCode, AnythingLLM,LangChain, Dify e Langflow por meio de conectores oficiais e guias de integração passo a passo.
Para equipes que priorizam controle de custos e uso ilimitado, o requisito de 35 a 46GB de VRAM para inferência quantizada coloca o modelo ao alcance de RTX 5090, GPUs AMD Instinct ou MacBooks de 64GB com memória unificada. A escolha entre implantação local e via API depende dos padrões de uso: trabalho de desenvolvimento contínuo favorece a implantação local, apesar da complexidade de configuração, enquanto casos de uso esporádicos se beneficiam do acesso sem servidor. À medida que o modelo amadurece e as técnicas de quantização melhoram, a lacuna entre o desempenho local e hospedado continua diminuindo, tornando o Qwen3-Coder-Next uma opção viável para desenvolvedores que buscam alternativas a assistentes de codificação proprietários.
Perguntas Frequentes
Qual hardware preciso para executar o Qwen3-Coder-Next localmente?
Você precisa de 35 a 46GB de VRAM para quantização de 4 bits, alcançável com RTX 5090, AMD Radeon 7900 XTX, GPUs AMD Instinct ou MacBooks de 64GB com memória unificada. Precisão total requer 85 a 95GB de VRAM.
Como o desempenho do Qwen3-Coder-Next se compara a modelos maiores?
Ele supera modelos com 10 a 20 vezes mais parâmetros ativos, como o DeepSeek-V3.2, em benchmarks de codificação autônoma, alcançando 74,2% no SWE-Bench Verified e 69,9% no Aider.
Quais são as configurações de geração recomendadas para o Qwen3-Coder-Next?
Use temperatura=1.0, top_p=0,95, top_k=40 e min_p=0,01 para geração de código ideal. Essas configurações ativam o modo de não raciocínio para respostas rápidas, mantendo a qualidade.
Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer uma nuvem de GPU acessível e confiável para construção e escalonamento.
Leitura Recomendada



