

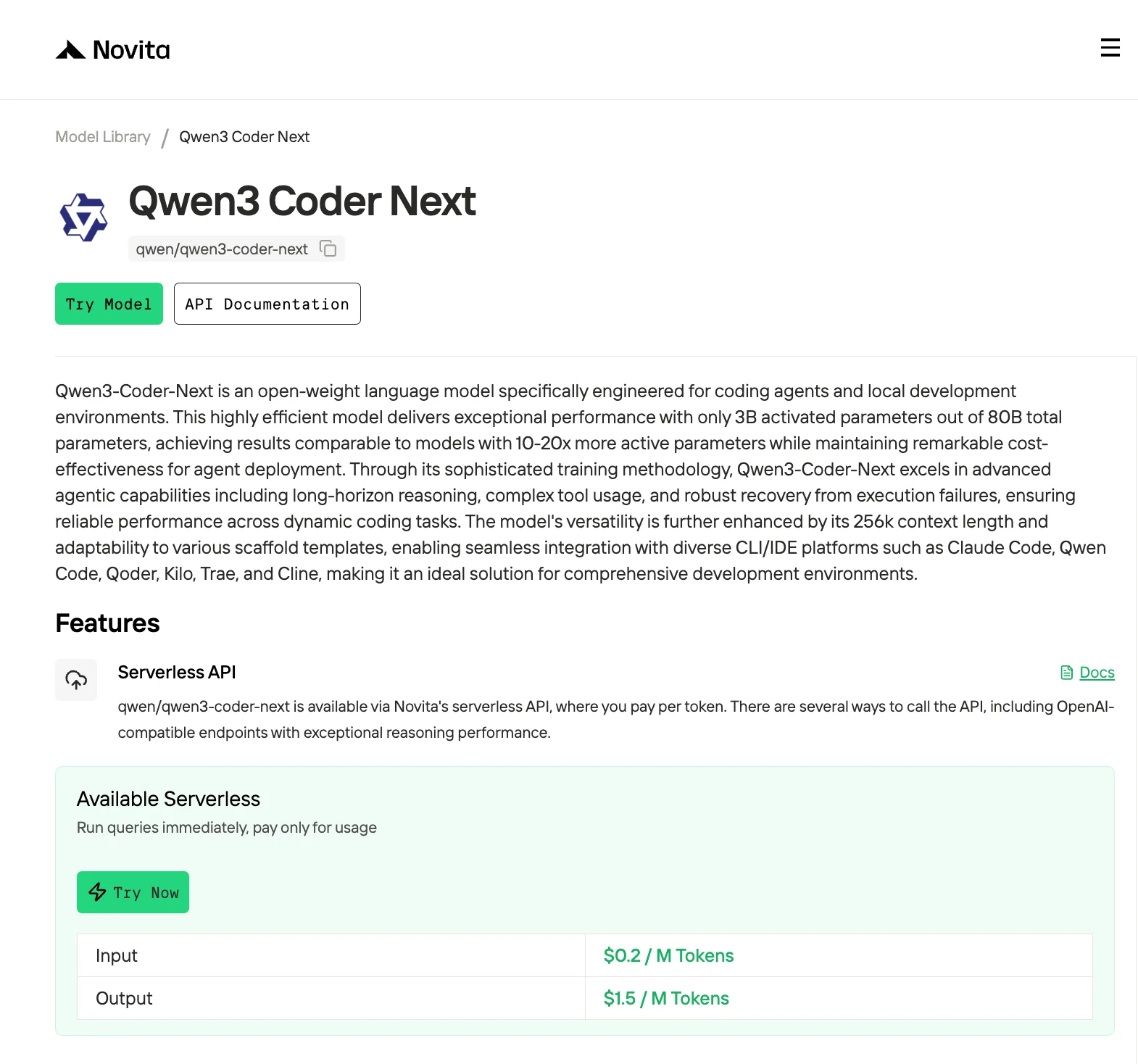
Запуск ИИ-ассистентов для программирования локально стал приоритетом для разработчиков, которые ценят конфиденциальность, контроль над затратами и неограниченное использование. Но найти модель, которая сочетает в себе мощность и доступность для потребительского оборудования, по-прежнему сложно. Qwen3-Coder-Next, выпущенная в 2026 году, обещает решить эту проблему: у неё 80 млрд общих параметров, но только 3 млрд активированных на токен — это позволяет запускать её на высокопроизводительных потребительских GPU, при этом результаты бенчмарков сопоставимы с показателями моделей с активными параметрами в 10–20 раз больше.
В этом руководстве рассматриваются три основных способа получить доступ к Qwen3-Coder-Next: локальное развёртывание через Hugging Face/Transformers, квантованное инференсирование с помощью llama.cpp/Unsloth и доступ через API от Novita AI. Мы рассмотрим реальный опыт разработчиков, которые тестировали эту модель, требования к оборудованию для разных уровней квантования и конкретные конфигурации, обеспечивающие оптимальную производительность для задач агентного программирования.
Спецификации модели: что отличает Qwen3-Coder-Next
| Спецификация | Детали |
|---|---|
| Общее количество параметров | 80 млрд |
| Активированных параметров | 3 млрд на токен/инференсирование |
| Длина контекста | 256K токенов нативно |
| Архитектура | Гибридная MoE |
| Лицензия | Открытые веса модели |
| Направление обучения | Агентное программирование (долгосрочное рассуждение, использование инструментов, восстановление после ошибок выполнения) |
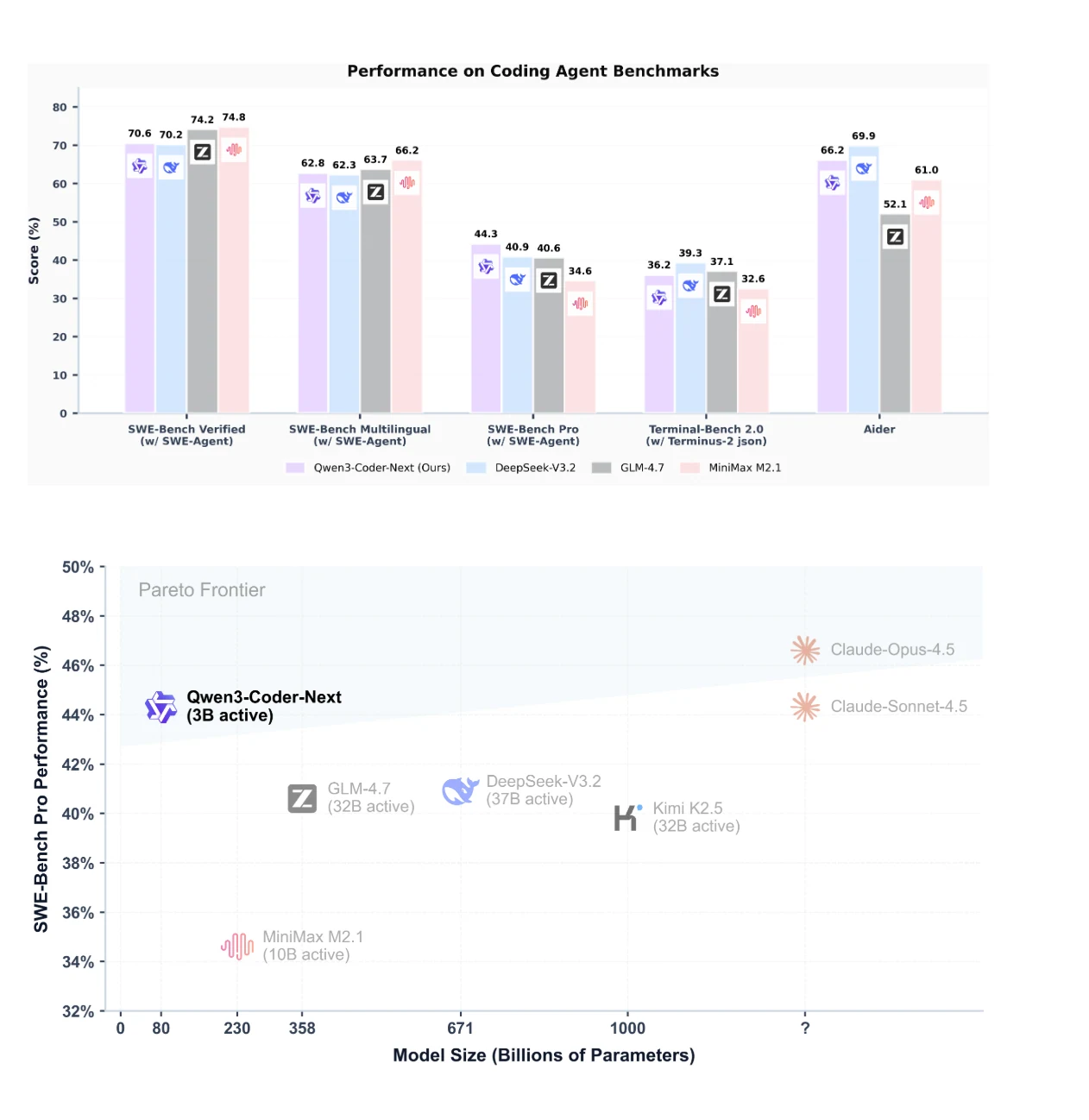
Производительность в бенчмарках: сравнение Qwen3-Coder-Next с другими моделями
Попробуйте Qwen 3 Coder Next прямо сейчас!
Qwen3-Coder-Next показывает ведущие результаты в SWE-Bench Pro и демонстрирует отличное соотношение производительности и эффективности использования параметров.
Метод 1: Эффективный доступ через API Novita API
Доступ через API имеет смысл, если:
- У вас нет оборудования с VRAM от 35 ГБ и выше
- Вам нужен мгновенный доступ без времени на настройку
- Ваше использование нерегулярное, а не постоянное
- Вы хотите избежать обслуживания инфраструктуры
Шаг 1: Войдите в аккаунт и перейдите в библиотеку моделей

Шаг 2: Выберите нужную модель

Шаг 3: Начните бесплатный пробный период
Попробуйте Qwen 3 Coder Next прямо сейчас!
Шаг 4: Получите ваш API-ключ
Для аутентификации через API мы предоставим вам новый API-ключ. Перейдя на страницу «Настройки», вы можете скопировать API-ключ, как показано на изображении.

Шаг 5: Установите API
Установите API с помощью менеджера пакетов, соответствующего вашему языку программирования.
После установки импортируйте необходимые библиотеки в вашу среду разработки. Инициализируйте API с вашим API-ключом, чтобы начать взаимодействие с LLM Novita AI. Ниже приведён пример использования API завершения чата для пользователей Python.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3-coder-next",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].message.content)
Метод 2: Локальное развёртывание через Hugging Face Transformers
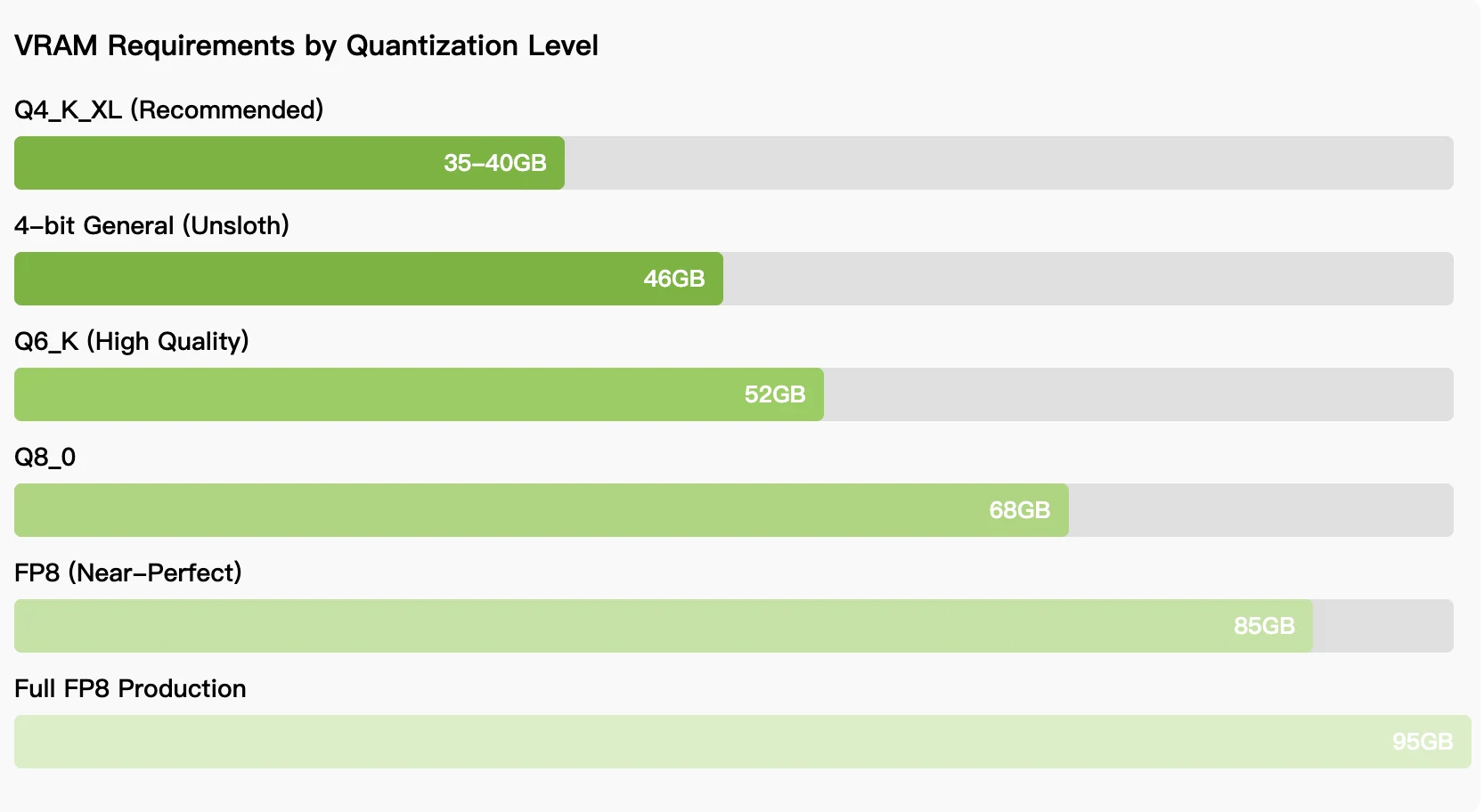
Требования к оборудованию:
- Скачайте веса модели с HuggingFace или ModelScope
- Выберите фреймворк для инференсирования: поддерживаются vLLM или SGLang
- Следуйте руководству по развёртыванию в официальном репозитории GitHub
Выбирайте выделенный endpoint, если вам нужен стабильный высокопроизводительный инференсирование, полный контроль над моделью и более низкая стоимость при постоянных или интенсивных рабочих нагрузках, вместо обслуживания локальных GPU и инфраструктуры.
Попробуйте выделенный endpoint прямо сейчас!
Рекомендуемые параметры генерации
Оптимальные настройки для Qwen3-Coder-Next отличаются от стандартных для моделей программирования:
- Temperature: 1.0 (выше, чем у стандартных моделей для программирования)
- Top_P: 0.95
- Top_K: 40
- Min_P: 0.01
Эти настройки активируют режим без рассуждений модели для быстрых ответов с кодом при сохранении качества.
Метод 3: Фреймворки для инференсирования LLM
llama.cpp — это лёгкий фреймворк для инференсирования LLM на C/C++, в основном предназначенный для эффективного запуска квантованных моделей GGUF на CPU или устройствах с малым объёмом VRAM. Его основные преимущества: простая настройка, высокая производительность на CPU, отличная поддержка Apple Silicon в macOS и гибкие опции квантования, а недостатки — более низкая пропускная способность при высокой конкурентности и слабое масштабирование на GPU по сравнению с современными фреймворками для обслуживания на GPU.
# macOS с Homebrew
brew install llama.cpp
# Или сборка из исходного кода
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
make
# Использование CLI Hugging Face (рекомендуется)
llama-cli -hf unsloth/Qwen3-Coder-Next-GGUF:UD-Q4_K_XL
# Или скачайте вручную по ссылке:
# https://huggingface.co/unsloth/Qwen3-Coder-Next-GGUF
llama-server \
-hf unsloth/Qwen3-Coder-Next-GGUF:UD-Q4_K_XL \
--fit on \
--seed 3407 \
--temp 1.0 \
--top-p 0.95 \
--min-p 0.01 \
--top-k 40 \
--jinja \
--port 8080
Ollama — это удобный для новичков рантайм и фреймворк для обслуживания LLM, который оборачивает бэкенды инференсирования (часто llama.cpp) в простой рабочий процесс «загрузи и запусти». Его сильные стороны — максимально простая установка, автоматическое управление моделями и готовый локальный API-сервер, а ограничения — сниженный контроль над низкоуровневыми параметрами инференсирования, меньшая гибкость для тонкой настройки и зависимость от экосистемы упаковки моделей Ollama.
# Установка Ollama
curl -fsSL https://ollama.com/install.sh | sh
# Загрузка и запуск модели
ollama pull qwen3-coder-next
ollama run qwen3-coder-next
vLLM — это фреймворк для инференсирования и обслуживания на GPU производственного уровня, оптимизированный для высокой пропускной способности и многопользовательской конкурентности, в основном за счёт эффективного управления KV-кэшем (PagedAttention). Его преимущества: отличная производительность обслуживания, сильная масштабируемость между GPU и зрелые возможности развёртывания, а недостатки — более высокая сложность системы, повышенные требования к GPU/VRAM и меньшая пригодность для сред только с CPU.
# Установка vLLM
pip install 'vllm>=0.15.0'
# Запуск сервера
vllm serve Qwen/Qwen3-Coder-Next \
--port 8000 \
--tensor-parallel-size 2 \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder
SGLang — это высокопроизводительный фреймворк для инференсирования и обслуживания LLM, оптимизированный для быстрого декодирования и сложных конвейеров выполнения, особенно для вызова инструментов и рабочих процессов в стиле агентов. Его сильные стороны — агрессивная оптимизация производительности и сильная поддержка продвинутых многошаговых конвейеров генерации, а недостатки — более высокая сложность настройки, менее зрелая экосистема по сравнению с vLLM и более сильная зависимость от GPU-инфраструктуры для достижения лучших результатов.
# Установка SGLang
pip install 'sglang[all]>=v0.5.8'
# Запуск сервера
python -m sglang.launch_server \
--model Qwen/Qwen3-Coder-Next \
--port 30000 \
--tp-size 2 \
--tool-call-parser qwen3_coder
Метод 4: Интеграция с инструментами для агентов программирования
Получите API-ключ прямо сейчас!
Легко подключите Novita AI к партнёрским платформам: Claude code, Cursor, Trae, Continue, Codex, OpenCode, AnythingLLM,LangChain, Dify и Langflow с помощью официальных коннекторов и пошаговых руководств по интеграции.
Для команд, для которых приоритетны контроль затрат и неограниченное использование, требование к 35–46 ГБ VRAM для квантованного инференсирования делает модель доступной на RTX 5090, GPU AMD Instinct или 64-гигабайтовых MacBook. Выбор между локальным развёртыванием и доступом через API зависит от паттернов использования: постоянная работа над разработкой выгоднее с локальным развёртыванием, несмотря на сложность настройки, а нерегулярные сценарии использования выигрывают от бессерверного доступа. По мере развития модели и улучшения техник квантования разрыв в производительности между локальным и хостинговым вариантами продолжает сокращаться, что делает Qwen3-Coder-Next жизнеспособным вариантом для разработчиков, ищущих альтернативы проприетарным ассистентам для программирования.
Часто задаваемые вопросы
Какое оборудование нужно для локального запуска Qwen3-Coder-Next?
Для 4-битного квантования требуется 35–46 ГБ VRAM, что достижимо на RTX 5090, AMD Radeon 7900 XTX, GPU AMD Instinct или 64-гигабайтовых MacBook с объединённой памятью. Для полной точности требуется 85–95 ГБ VRAM.
Как производительность Qwen3-Coder-Next сравнивается с более крупными моделями?
Она превосходит модели с активными параметрами в 10–20 раз больше, например DeepSeek-V3.2, в бенчмарках агентного программирования, достигая 74,2% в SWE-Bench Verified и 69,9% в Aider.
Какие параметры генерации рекомендуются для Qwen3-Coder-Next?
Используйте temperature=1.0, top_p=0.95, top_k=40 и min_p=0.01 для оптимальной генерации кода. Эти настройки активируют режим без рассуждений для быстрых ответов при сохранении качества.
Novita AI — это облачная ИИ-платформа, которая предлагает разработчикам простой способ развёртывания ИИ-моделей с помощью нашего простого API, а также доступное и надёжное облако GPU для построения и масштабирования решений.
Рекомендуемые материалы для чтения



