

Die lokale Ausführung von KI-Coding-Assistenten ist für Entwickler, die Wert auf Datenschutz, Kostenkontrolle und unbegrenzte Nutzung legen, zur Priorität geworden. Die Suche nach einem Modell, das Leistung mit Zugänglichkeit für Consumer-Hardware verbindet, bleibt jedoch eine Herausforderung. Qwen3-Coder-Next, das 2026 veröffentlicht wurde, verspricht, dieses Problem mit 80B Gesamtparametern zu lösen, von denen pro Token nur 3B aktiviert sind – dadurch ist es auf High-End-Consumer-GPUs lauffähig und liefert Benchmark-Ergebnisse, die mit Modellen mit 10–20 Mal mehr aktiven Parametern mithalten können.
Dieser Leitfaden behandelt die drei wichtigsten Methoden für den Zugriff auf Qwen3-Coder-Next: lokale Bereitstellung über Hugging Face/Transformers, quantisierte Inferenz mit llama.cpp/Unsloth und API-Zugriff über Novita AI. Wir werfen einen Blick auf reale Nutzererfahrungen von Entwicklern, die das Modell getestet haben, die Hardwareanforderungen für verschiedene Quantisierungsstufen und die spezifischen Konfigurationen, die optimale Leistung für agentische Coding-Aufgaben liefern.
Modellspezifikationen: Was Qwen3-Coder-Next einzigartig macht
| Spezifikation | Details |
|---|---|
| Gesamtparameter | 80B |
| Aktivierte Parameter | 3B pro Token/Inferenz |
| Kontextlänge | 256K Token nativ |
| Architektur | Hybrides MoE |
| Lizenz | Offene Gewichte |
| Trainingsfokus | Agentisches Coding (langfristige Schlussfolgerung, Tool-Nutzung, Wiederherstellung nach Ausführungsfehlern) |
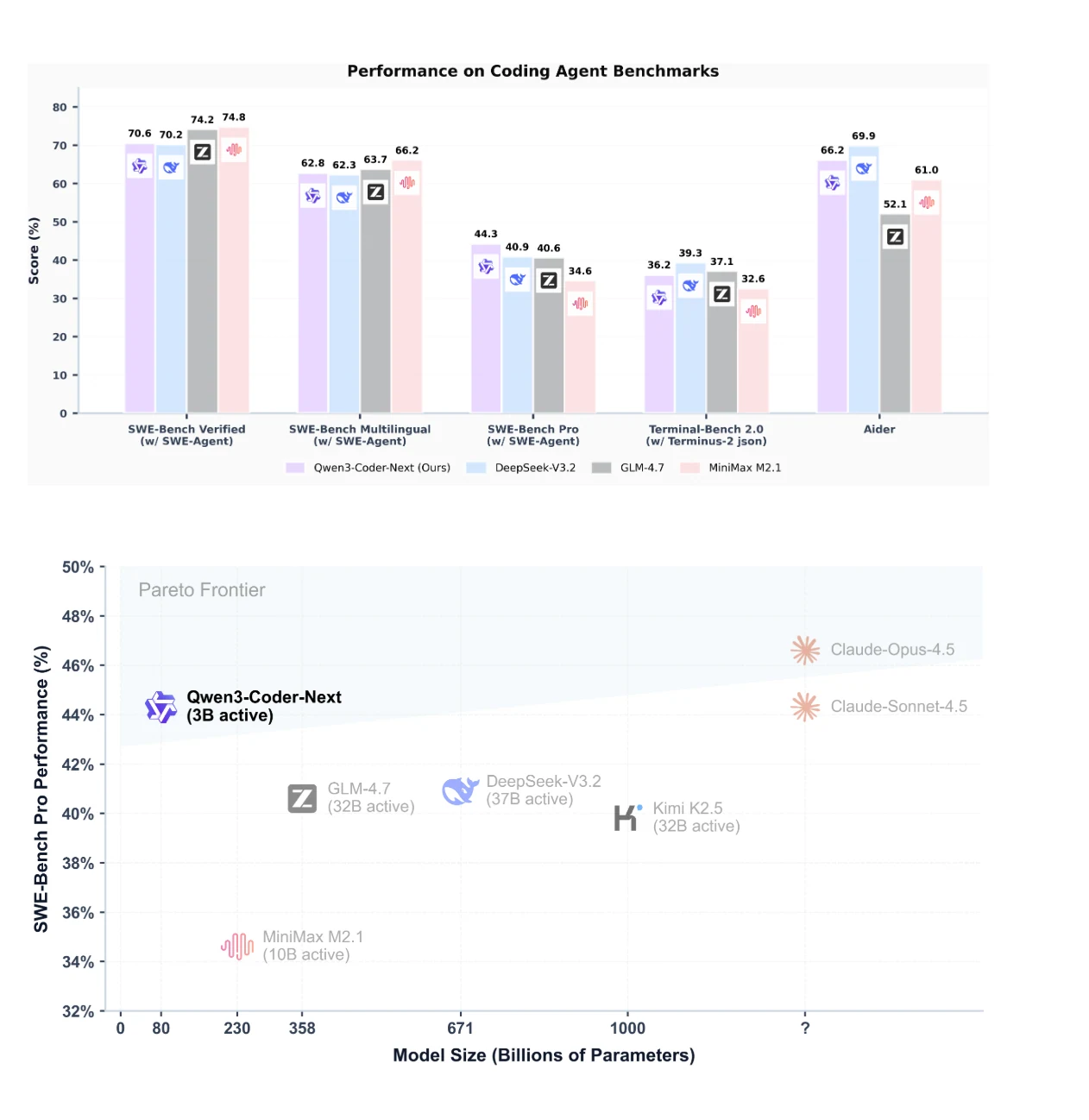
Benchmark-Leistung: Vergleich von Qwen3-Coder-Next mit anderen Modellen
Probieren Sie Qwen 3 Coder Next jetzt aus!
Qwen3-Coder-Next erreicht führende Leistung auf SWE-Bench Pro und zeigt ein exzellentes Verhältnis von Leistung zu Parameter-Effizienz.
Methode 1: Einfacher API-Zugriff über Novita API
API-Zugriff lohnt sich, wenn:
- Sie keine Hardware mit 35 GB+ VRAM besitzen
- Sie sofortige Verfügbarkeit ohne Einrichtungszeit benötigen
- Ihre Nutzung sporadisch statt kontinuierlich ist
- Sie Infrastrukturwartung vermeiden möchten
Schritt 1: Einloggen und Zugriff auf die Modellbibliothek
Loggen Sie sich in Ihrem Konto ein und klicken Sie auf die Schaltfläche Modellbibliothek.

Schritt 2: Wählen Sie Ihr Modell
Durchstöbern Sie die verfügbaren Optionen und wählen Sie das Modell, das Ihren Anforderungen entspricht.

Schritt 3: Starten Sie Ihre kostenlose Testversion
Starten Sie Ihre kostenlose Testversion, um die Funktionen des ausgewählten Modells kennenzulernen.
Probieren Sie Qwen 3 Coder Next jetzt aus!
Schritt 4: Holen Sie sich Ihren API-Schlüssel
Zur Authentifizierung über die API stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Auf der Seite „Einstellungen“ können Sie den API-Schlüssel wie in der Abbildung gezeigt kopieren.

Schritt 5: Installieren Sie die API
Installieren Sie die API über den für Ihre Programmiersprache spezifischen Paketmanager.
Nach der Installation importieren Sie die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit dem Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Nutzung der Chat-Completion-API für Python-Nutzer.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3-coder-next",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].message.content)
Methode 2: Lokale Bereitstellung über Hugging Face Transformers
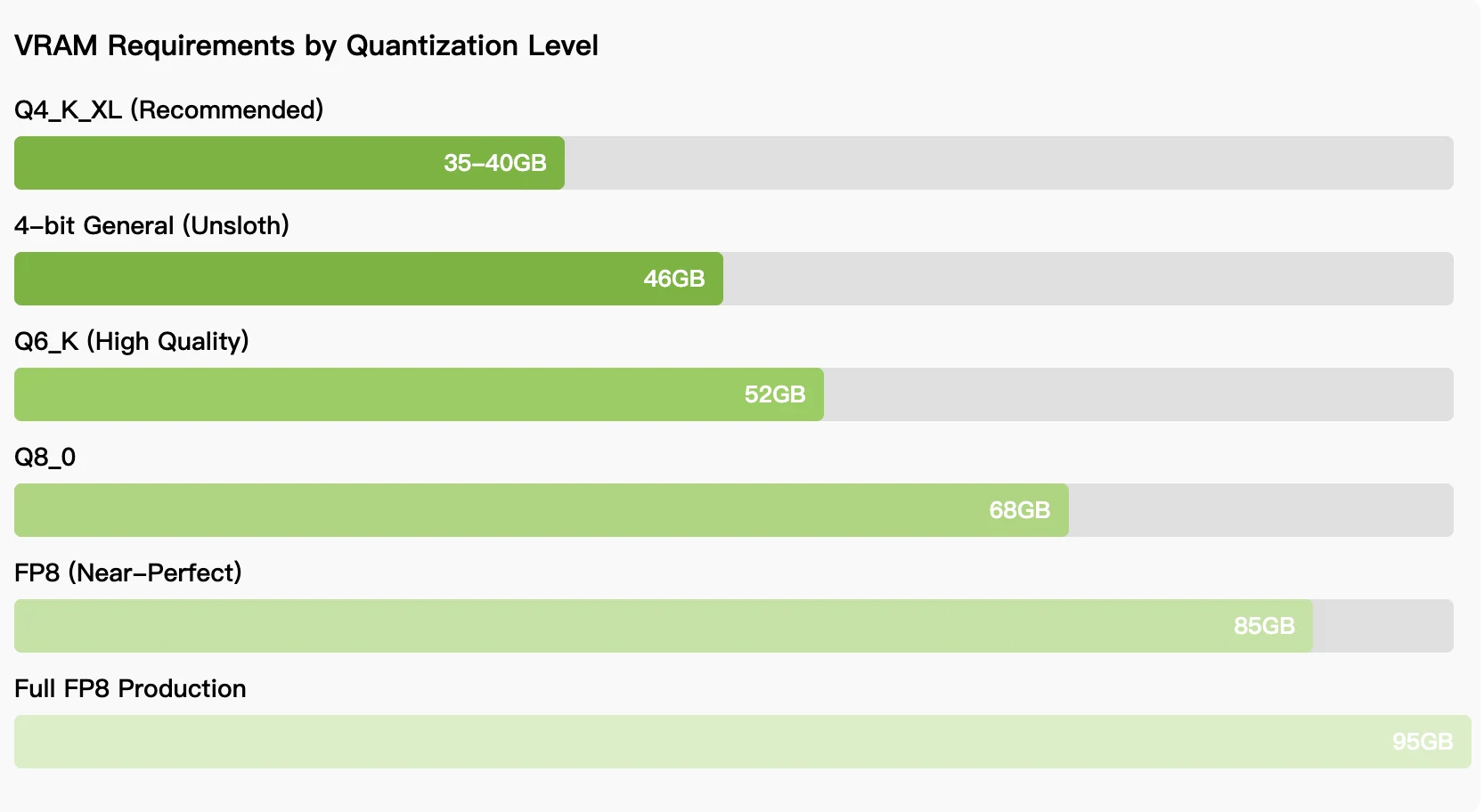
Hardware Anforderungen:
- Laden Sie die Modellgewichte von HuggingFace oder ModelScope herunter
- Wählen Sie das Inferenz-Framework: vLLM oder SGLang werden unterstützt
- Befolgen Sie den Bereitstellungsleitfaden im offiziellen GitHub-Repository
Sie sollten einen dedizierten Endpunkt wählen, wenn Sie stabile Hochleistungsinferenz, benutzerdefinierte Modellkontrolle und niedrigere Kosten bei kontinuierlichen oder schweren Arbeitslasten benötigen, anstatt lokale GPUs und Infrastruktur zu warten.
Probieren Sie den dedizierten Endpunkt jetzt aus!
Empfohlene Generierungsparameter
Die optimalen Einstellungen für Qwen3-Coder-Next unterscheiden sich von typischen Coding-Modellen:
- Temperatur: 1,0 (höher als bei typischen Coding-Modellen)
- Top_P: 0,95
- Top_K: 40
- Min_P: 0,01
Diese Einstellungen aktivieren den Nicht-Schlussfolgerungsmodus des Modells für schnelle Code-Antworten bei gleichbleibender Qualität.
Methode 3: LLM-Inferenz-Frameworks
llama.cpp ist ein leichtgewichtiges C/C+±LLM-Inferenz-Framework, das hauptsächlich für die effiziente Ausführung von GGUF-quantisierten Modellen auf CPUs oder Geräten mit geringem VRAM entwickelt wurde. Seine Hauptvorteile sind einfache Einrichtung, starke CPU-Leistung, exzellente Unterstützung für macOS Apple Silicon und flexible Quantisierungsoptionen, während seine Schwächen geringerer Durchsatz bei hoher Gleichzeitigkeit und schwächere GPU-Skalierung im Vergleich zu modernen GPU-Serving-Frameworks sind.
# macOS mit Homebrew
brew install llama.cpp
# Oder aus dem Quellcode erstellen
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
make
# Nutzung der Hugging Face CLI (empfohlen)
llama-cli -hf unsloth/Qwen3-Coder-Next-GGUF:UD-Q4_K_XL
# Oder manuell herunterladen von:
# https://huggingface.co/unsloth/Qwen3-Coder-Next-GGUF
llama-server \
-hf unsloth/Qwen3-Coder-Next-GGUF:UD-Q4_K_XL \
--fit on \
--seed 3407 \
--temp 1.0 \
--top-p 0.95 \
--min-p 0.01 \
--top-k 40 \
--jinja \
--port 8080
Ollama ist ein einsteigerfreundliches LLM-Laufzeit- und Serving-Framework, das Inferenz-Backends (häufig llama.cpp) in einen einfachen „Pull-and-Run“-Workflow einwickelt. Seine Stärken sind extrem einfache Installation, automatische Modellverwaltung und ein sofort betriebsbereiter lokaler API-Server, während seine Einschränkungen reduzierte Kontrolle über Low-Level-Inferenzparameter, weniger Flexibilität für die Feinabstimmung und Abhängigkeit vom Ollama-Modellverpackungsökosystem sind.
# Ollama installieren
curl -fsSL https://ollama.com/install.sh | sh
# Modell herunterladen und ausführen
ollama pull qwen3-coder-next
ollama run qwen3-coder-next
vLLM ist ein produktionsreifes GPU-Inferenz- und Serving-Framework, das für hohen Durchsatz und Multi-User-Gleichzeitigkeit optimiert ist und größtenteils durch effizientes KV-Cache-Management (PagedAttention) angetrieben wird. Seine Vorteile sind exzellente Serving-Leistung, starke Skalierbarkeit über GPUs hinweg und ausgereifte Bereitstellungsfunktionen, während seine Nachteile höhere Systemkomplexität, höhere GPU/VRAM-Anforderungen und geringere Eignung für CPU-only-Umgebungen sind.
# vLLM installieren
pip install 'vllm>=0.15.0'
# Server starten
vllm serve Qwen/Qwen3-Coder-Next \
--port 8000 \
--tensor-parallel-size 2 \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder
SGLang ist ein Hochleistungs-LLM-Inferenz- und Serving-Framework, das für schnelles Dekodieren und komplexe Ausführungspipelines optimiert ist, insbesondere für Tool-Aufrufe und agentische Workflows. Seine Stärken sind aggressive Leistungsoptimierung und starke Unterstützung für fortgeschrittene mehrstufige Generierungspipelines, während seine Nachteile höhere Einrichtungskomplexität, ein weniger ausgereiftes Ökosystem als vLLM und eine stärkere Abhängigkeit von GPU-Infrastruktur für beste Ergebnisse umfassen.
# SGLang installieren
pip install 'sglang[all]>=v0.5.8'
# Server starten
python -m sglang.launch_server \
--model Qwen/Qwen3-Coder-Next \
--port 30000 \
--tp-size 2 \
--tool-call-parser qwen3_coder
Methode 4: Integration mit Code-Agent-Tools
Holen Sie sich jetzt Ihren API-Schlüssel!
Verbinden Sie Novita AI einfach mit Partnerplattformen wie Claude code,Cursor,Trae,Continue, Codex, OpenCode, AnythingLLM,LangChain, Dify und Langflow über offizielle Connectors und Schritt-für-Schritt-Integrationsleitfäden.
Für Teams, die Wert auf Kostenkontrolle und unbegrenzte Nutzung legen, liegt die VRAM-Anforderung von 35–46 GB für quantisierte Inferenz im Bereich von RTX 5090, AMD Instinct GPUs oder 64 GB MacBooks. Die Wahl zwischen lokaler und API-Bereitstellung hängt von den Nutzungsmustern ab: kontinuierliche Entwicklungsarbeit bevorzugt trotz der Einrichtungskomplexität die lokale Bereitstellung, während sporadische Anwendungsfälle von serverlosem Zugriff profitieren. Da das Modell reift und Quantisierungstechniken verbessert werden, verringert sich die Leistungslücke zwischen lokaler und gehosteter Ausführung weiter, sodass Qwen3-Coder-Next eine praktikable Option für Entwickler ist, die nach Alternativen zu proprietären Coding-Assistenten suchen.
Häufig gestellte Fragen
Welche Hardware benötige ich, um Qwen3-Coder-Next lokal auszuführen?
Sie benötigen 35–46 GB VRAM für 4-Bit-Quantisierung, erreichbar mit RTX 5090, AMD Radeon 7900 XTX, AMD Instinct GPUs oder 64 GB MacBooks mit gemeinsamem Speicher. Volle Präzision erfordert 85–95 GB VRAM.
Wie vergleicht sich die Leistung von Qwen3-Coder-Next mit größeren Modellen?
Es übertrifft Modelle mit 10–20 Mal mehr aktiven Parametern wie DeepSeek-V3.2 bei agentischen Coding-Benchmarks und erreicht 74,2 % bei SWE-Bench Verified und 69,9 % bei Aider.
Welche Generierungseinstellungen werden für Qwen3-Coder-Next empfohlen?
Verwenden Sie für optimale Code-Generierung Temperatur=1,0, Top_P=0,95, Top_K=40 und Min_P=0,01. Diese Einstellungen aktivieren den Nicht-Schlussfolgerungsmodus für schnelle Antworten bei gleichbleibender Qualität.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud für die Entwicklung und Skalierung bereitstellt.
Empfohlene Lektüre



