

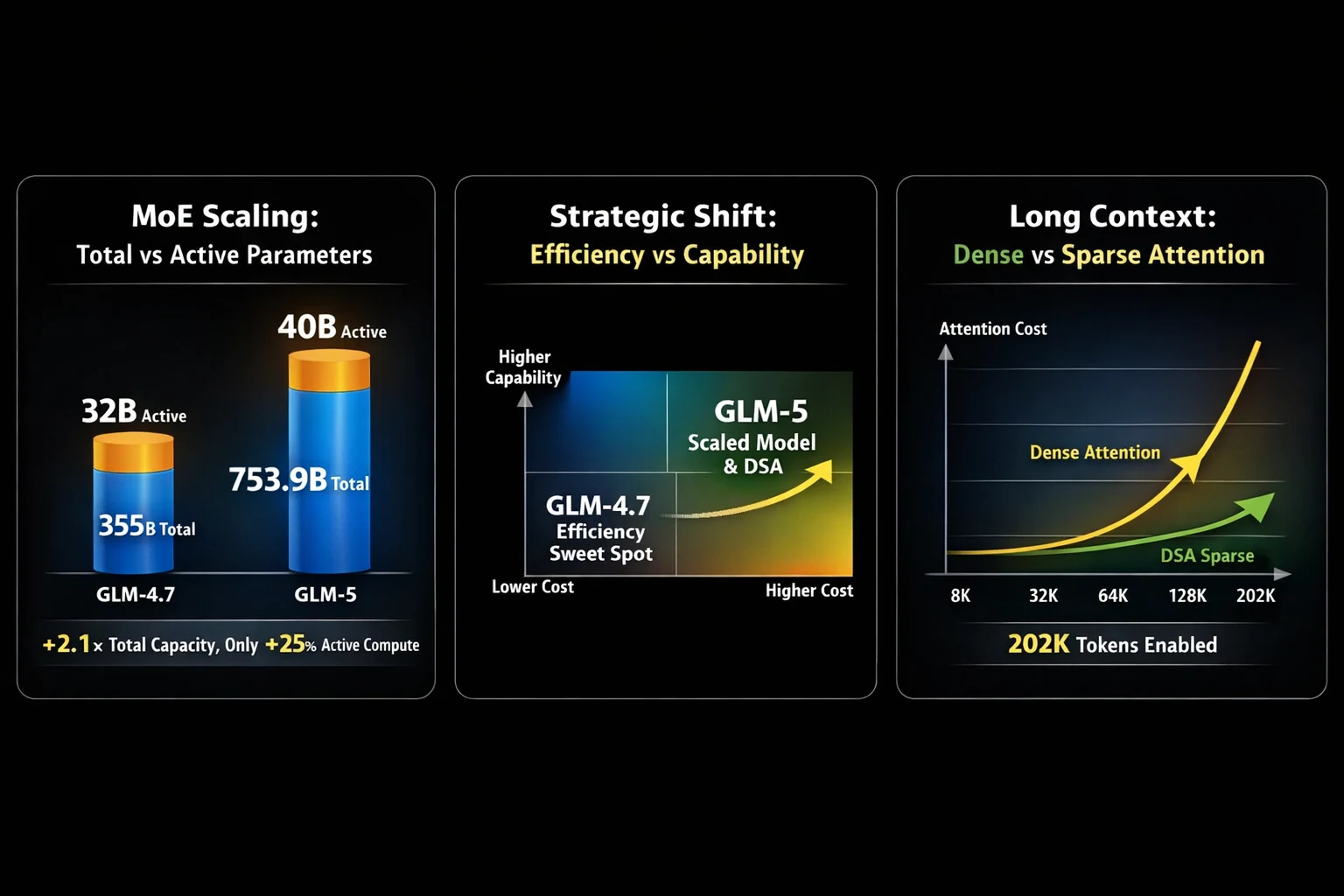
Escolher entre GLM-5 e GLM-4.7 geralmente se resume a uma troca crítica: poder de agente em escala massiva versus versatilidade comprovada em codificação. O GLM-5, lançado pela Z.ai, escala dramaticamente em relação ao seu predecessor — saltando de 355B parâmetros (32B ativos) no GLM-4.7 para 753,9B parâmetros (40B ativos). Essa expansão de parâmetros de 2,1x traz melhorias substanciais em engenharia de sistemas complexos e tarefas agentivas de longo horizonte, mas o GLM-4.7 continua sendo uma potência para codificação multilíngue, automação de terminal e fluxos de trabalho reais de desenvolvedores.
Comparação de Arquitetura entre GLM-5 e GLM-4.7
| Especificação | GLM-5 | GLM-4.7 |
|---|---|---|
| Parâmetros Totais | 753,9B | 355B |
| Parâmetros Ativos | 40B | 32B |
| Comprimento de Contexto | 202.752 tokens | 202.752 tokens |
| Dados de Pré-treinamento | 28,5T tokens | 23T tokens |
| Precisão | BF16 (FP8 disponível) | BF16 (FP8 disponível) |
| Suporte Multimodal | Apenas texto | Apenas texto |
| Data de Lançamento | Janeiro de 2026 | Dezembro de 2025 |
Uma das melhorias mais práticas do GLM-5 é sua integração da DeepSeek Sparse Attention (DSA), que reduz significativamente o custo da atenção de contexto longo, preservando grandes janelas de contexto de até 202K tokens. Isso torna o GLM-5 muito mais implantável para raciocínio em documentos longos, assistentes multi-turn e fluxos de trabalho do tipo agente. No lado pós-treinamento, o GLM-5 se beneficia do slime, uma nova infraestrutura de aprendizado por reforço assíncrono que aumenta o throughput do treinamento RL e permite iterações de alinhamento mais frequentes e refinadas.
Comparação de Benchmarks entre GLM-5 e GLM-4.7
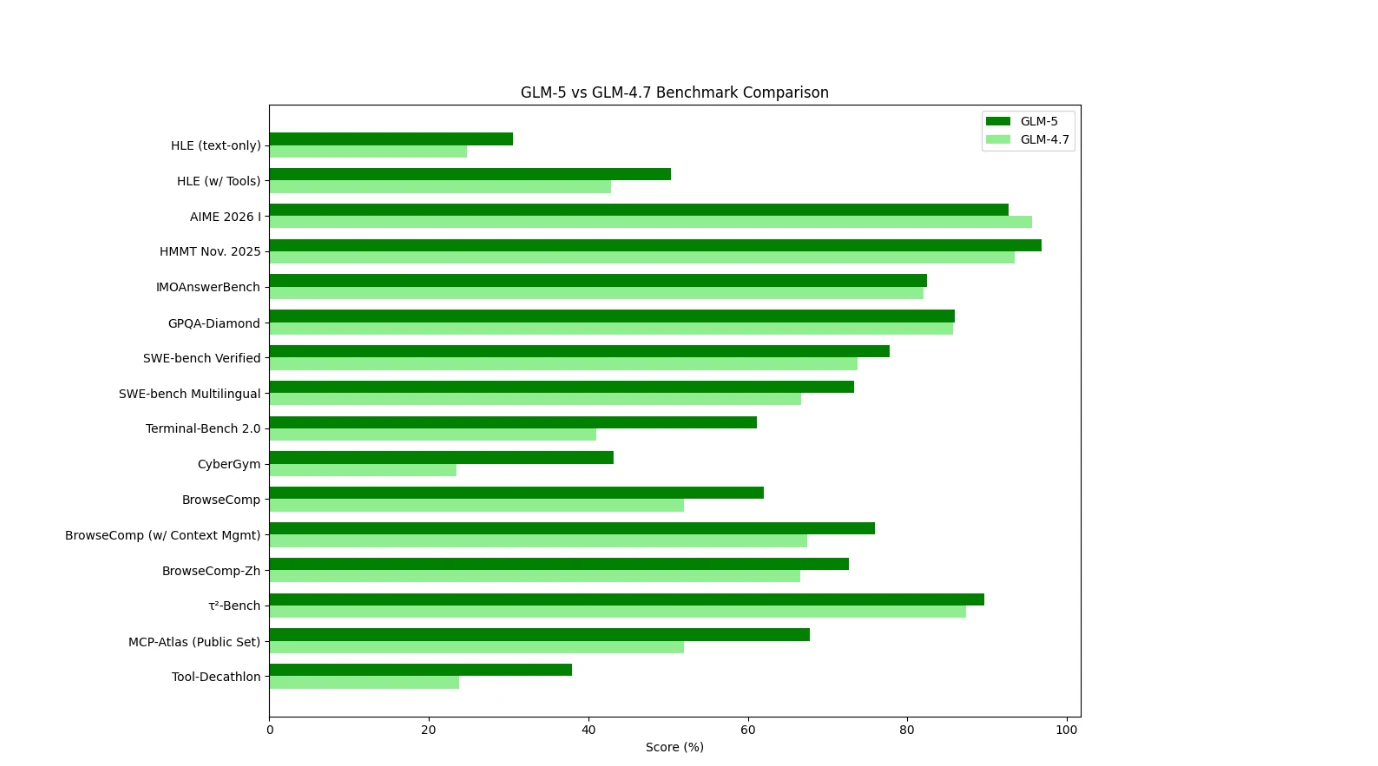
Do ponto de vista dos benchmarks, o GLM-5 mostra uma melhoria ampla e consistente em relação ao GLM-4.7, especialmente em uso de ferramentas, navegação e configurações agentivas. Os maiores ganhos aparecem em ambientes que exigem planejamento de múltiplas etapas, gerenciamento de contexto e execução no mundo real, sugerindo que o GLM-5 é otimizado para fluxos de trabalho do tipo agente em vez de tarefas isoladas de raciocínio.
O GLM-4.7 se comporta como um modelo de raciocínio/codificação otimizado para eficiência, ainda muito forte em avaliações clássicas de matemática, mas menos dominante em tarefas interativas orientadas a ferramentas.
Requisitos de VRAM do GLM-5 e GLM-4.7
O aumento de 2,1x nos parâmetros do GLM-4.7 para o GLM-5 traz implicações significativas de hardware. Aqui está a divisão de VRAM:
Configuração de GPU Recomendada para GLM-5
| Precisão | VRAM Necessária | Configuração Recomendada | Caso de Uso |
|---|---|---|---|
| BF16 | 1.508 GB | 19x NVIDIA H100 (80GB) | Pesquisa de máxima qualidade |
| FP8 | Cerca de 800 GB | 10x NVIDIA H100 (80GB) | Implantação em produção |
| INT4 | Cerca de 400 GB | 5x H100 (80GB) | Inferência de baixo custo |
Configuração de GPU Recomendada para GLM-4.7
| Precisão | VRAM Necessária | Configuração Recomendada | Caso de Uso |
|---|---|---|---|
| BF16 | 717 GB | 9x NVIDIA H100 (80GB) | Máxima qualidade |
| FP8 | 390 GB | 5x H100 (80GB) | Implantação em produção |
| INT4 | 200 GB | 3x H100 (80GB) | Inferência de baixo custo |
Experimente GPU com Custo-Benefício agora!
Na implantação FP8, o GLM-5 normalmente requer o dobro da contagem de GPUs em comparação com o GLM-4.7.
Para desenvolvedores com orçamentos limitados, o GLM-4.7 oferece um perfil de desempenho por dólar mais forte em cargas de trabalho focadas em codificação, alcançando 73,8% no SWE-bench Verified e 84,9% no LiveCodeBench-v6.
Para pesquisa de fronteira e desenvolvimento de sistemas agentivos, as capacidades mais fortes de uso de ferramentas e execução de longo horizonte do GLM-5 podem justificar o investimento adicional em hardware.
Preços e Acesso à API do GLM-5 e GLM-4.7
| Modelo | Entrada ($ / M tokens) | Leitura de Cache ($ / M tokens) | Saída ($ / M tokens) |
|---|---|---|---|
| GLM-4.7 | $0,60 | $0,11 | $2,20 |
| GLM-5 | $1,00 | $0,20 | $3,20 |
Leitura de Cache refere-se ao custo de ler tokens que foram armazenados anteriormente no cache de prompt. Quando o mesmo conteúdo de prompt é reutilizado em várias requisições, o modelo recupera esses tokens diretamente do cache, em vez de processá-los novamente do zero. Isso reduz tanto a latência de inferência quanto o custo.
Passo 1: Faça Login e Acesse a Biblioteca de Modelos
Faça login na sua conta e clique no botão Model Library.

Passo 2: Escolha seu Modelo
Navegue pelas opções disponíveis e selecione o modelo que atende às suas necessidades.

Passo 3: Inicie seu Teste Gratuito
Comece seu teste gratuito para explorar as capacidades do modelo selecionado.
Passo 4: Obtenha sua Chave de API
Para autenticar na API, forneceremos uma nova chave de API. Entrando na página de “Settings”, você pode copiar a chave de API conforme indicado na imagem.

Passo 5: Instale a API
Instale a API usando o gerenciador de pacotes específico da sua linguagem de programação.
Após a instalação, importe as bibliotecas necessárias para o seu ambiente de desenvolvimento. Inicialize a API com sua chave de API para começar a interagir com o Novita AI LLM. Este é um exemplo de uso da API de chat completions para usuários de Python.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="zai-org/glm-5 or zai-org/glm-4.7",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
Resumo da Estrutura de Decisão do GLM-5 e GLM-4.7
| Cenário | Modelo Recomendado | Motivo Principal |
|---|---|---|
| Sistemas multiagentes com orquestração de ferramentas | GLM-5 | +15,8pp no MCP-Atlas, +14,2pp no Tool-Decathlon |
| Fluxos de trabalho SWE-bench em produção | GLM-4.7 | 73,8% com metade do custo de hardware |
| Segurança cibernética e testes de penetração | GLM-5 | 43,2% no CyberGym |
| Codificação baseada em IDE (Claude Code, Cline) | GLM-4.7 | Thinking preservado + menor latência |
| Pesquisa de raciocínio de fronteira (HLE) | GLM-5 | 50,4% com ferramentas (melhor open-source) |
| Codificação de UI/frontend “vibe coding” | GLM-4.7 | Treinamento especializado para web UI moderna |
| Automação de terminal (longo horizonte) | GLM-5 | +28,3pp no Terminal-Bench 2.0 |
| Competições de matemática (AIME, HMMT) | GLM-4.7 | Iguala/supera o GLM-5 a menor custo |
| Startups com orçamento limitado | GLM-4.7 | Codificação robusta com 4x H100 vs 8x H100 |
| Laboratórios de pesquisa em limites da AGI | GLM-5 | Pré-treinamento com 28,5T tokens, infraestrutura RL slime |
O GLM-5 não torna o GLM-4.7 obsoleto — ele aborda problemas diferentes. Se o seu trabalho envolve tarefas agentivas de longo horizonte que exigem uso extensivo de ferramentas e raciocínio de múltiplas etapas, o investimento de 2x em hardware no GLM-5 compensa nas taxas de conclusão de tarefas. Se você está entregando assistentes de codificação para milhares de desenvolvedores ou precisa de ciclos de iteração rápidos em ambientes IDE, a arquitetura mais enxuta e o treinamento especializado do GLM-4.7 o tornam a escolha mais adequada. Ambos os modelos representam conquistas significativas em modelagem de linguagem open-source, fechando a lacuna com modelos proprietários de fronteira, mantendo total transparência e flexibilidade de implantação local.
Perguntas Frequentes
Qual é a principal diferença arquitetônica entre GLM-5 e GLM-4.7?
O GLM-5 escala de 355B para 753,9B parâmetros totais (32B para 40B ativos) e integra a DeepSeek Sparse Attention (DSA) para reduzir custos de implantação enquanto preserva o comprimento de contexto de 202K.
Posso executar o GLM-5 em hardware de consumo?
Não. O GLM-5 requer pelo menos 10 GPUs H100 80GB em modo FP8 (800GB VRAM), excedendo em muito as capacidades de GPUs de consumo.
Qual modelo é melhor para tarefas de codificação SWE-bench?
O GLM-5 supera o GLM-4.7 com 77,8% no SWE-bench Verified (+4pp), mas os 73,8% do GLM-4.7 com metade do custo de hardware o tornam mais prático para produção.
Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer uma nuvem de GPU acessível e confiável para construir e escalar.
Leitura Recomendada



