

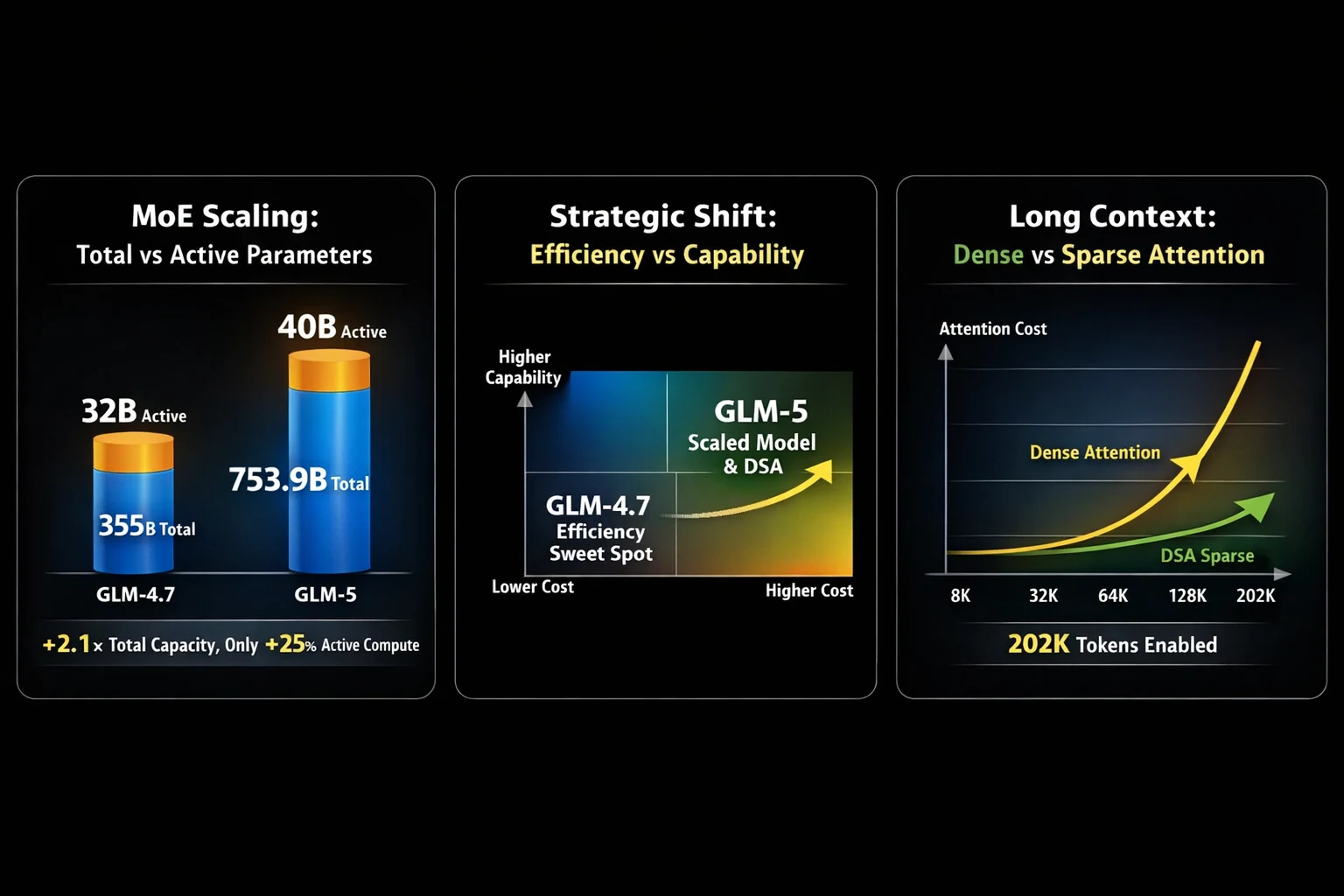
Choisir entre GLM-5 et GLM-4.7 revient souvent à un compromis crucial : une puissance agentique à grande échelle contre une polyvalence de codage éprouvée. GLM-5, publié par Z.ai, évolue considérablement par rapport à son prédécesseur — passant de 355B paramètres (32B actifs) sur GLM-4.7 à 753,9B paramètres (40B actifs). Cette expansion de paramètres de 2,1x apporte des améliorations substantielles dans l’ingénierie de systèmes complexes et les tâches agentiques à long terme, mais GLM-4.7 reste une puissance pour le codage multilingue, l’automatisation de terminaux et les flux de travail réels des développeurs.
Comparaison d’architecture de GLM-5 et GLM-4.7
| Spécification | GLM-5 | GLM-4.7 |
|---|---|---|
| Paramètres totaux | 753,9B | 355B |
| Paramètres actifs | 40B | 32B |
| Longueur de contexte | 202 752 tokens | 202 752 tokens |
| Données de pré-entraînement | 28,5T tokens | 23T tokens |
| Précision | BF16 (FP8 disponible) | BF16 (FP8 disponible) |
| Support multimodal | Texte uniquement | Texte uniquement |
| Date de publication | Janvier 2026 | Décembre 2025 |
L’une des mises à niveau les plus pratiques de GLM-5 est l’intégration de DeepSeek Sparse Attention (DSA), qui réduit considérablement le coût de l’attention sur de longs contextes tout en préservant de grandes fenêtres de contexte allant jusqu’à 202K tokens. Cela rend GLM-5 bien plus déployable pour le raisonnement sur de longs documents, les assistants multi-tours et les flux de travail de type agent.Du côté post-entraînement, GLM-5 bénéficie de slime, une nouvelle infrastructure d’apprentissage par renforcement asynchrone qui augmente le débit d’entraînement RL et permet des itérations d’alignement plus fréquentes et plus fines.
Comparaison des benchmarks de GLM-5 et GLM-4.7
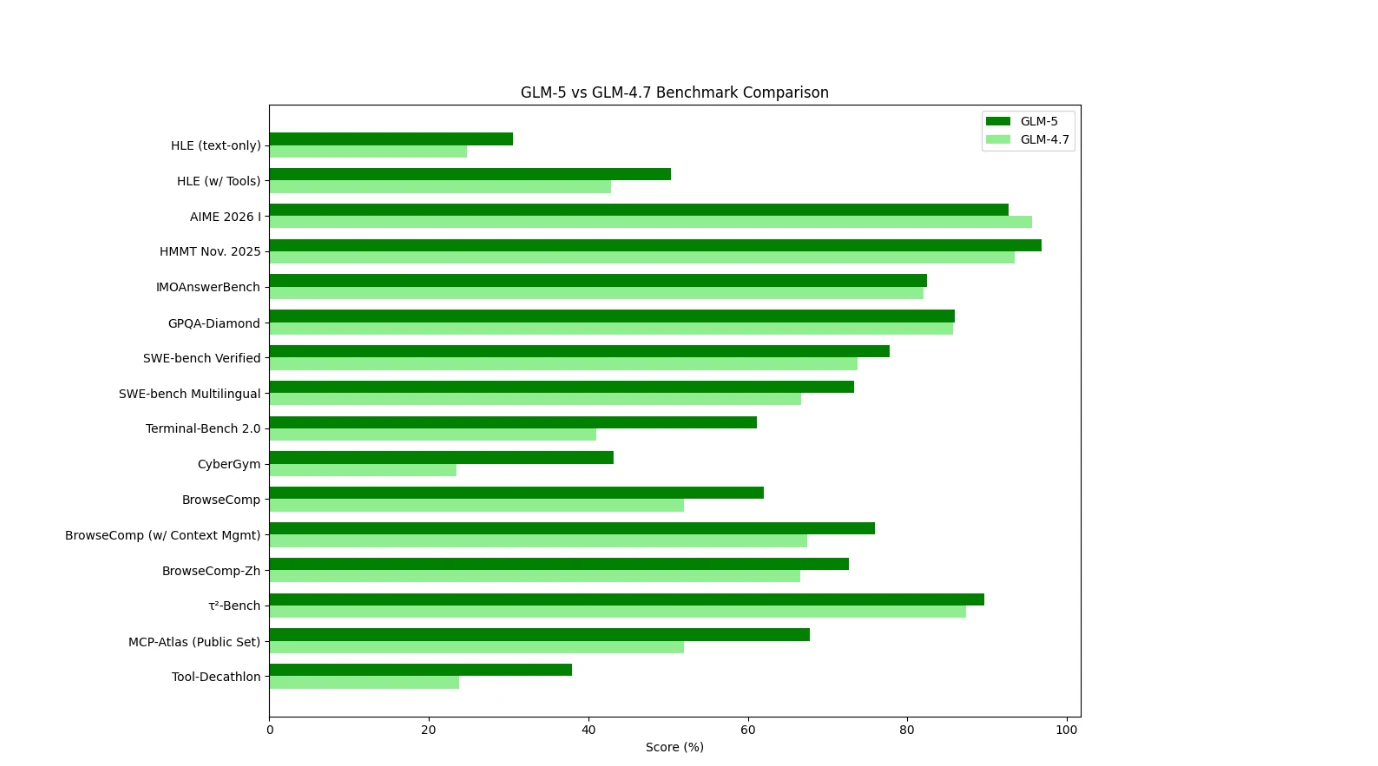
Du point de vue des benchmarks, GLM-5 montre une amélioration large et cohérente par rapport à GLM-4.7, en particulier dans l’utilisation d’outils, la navigation et les environnements agentiques. Les plus grands gains apparaissent dans les environnements nécessitant une planification multi-étapes, une gestion du contexte et une exécution réelle, ce qui suggère que GLM-5 est optimisé pour les flux de travail de type agent plutôt que pour des tâches de raisonnement isolées.
GLM-4.7 se comporte comme un modèle de raisonnement/codage optimisé pour l’efficacité, toujours très performant dans l’évaluation classique de type mathématique, mais moins dominant dans les tâches interactives pilotées par des outils.
Exigences VRAM de GLM-5 et GLM-4.7
L’augmentation de paramètres de 2,1x entre GLM-4.7 et GLM-5 entraîne des implications matérielles substantielles. Voici la répartition de la VRAM :
Configuration GPU recommandée pour GLM-5
| Précision | VRAM nécessaire | Configuration recommandée | Cas d’utilisation |
|---|---|---|---|
| BF16 | 1 508 GB | 19x NVIDIA H100 (80GB) | Recherche de qualité maximale |
| FP8 | Environ 800 GB | 10x NVIDIA H100 (80GB) | Déploiement en production |
| INT4 | Environ 400 GB | 5x H100 (80GB) | Inférence économique |
Configuration GPU recommandée pour GLM-4.7
| Précision | VRAM nécessaire | Configuration recommandée | Cas d’utilisation |
|---|---|---|---|
| BF16 | 717 GB | 9x NVIDIA H100 (80GB) | Qualité maximale |
| FP8 | 390 GB | 5x H100 (80GB) | Déploiement en production |
| INT4 | 200 GB | 3x H100 (80GB) | Inférence économique |
Essayez un GPU économique maintenant !
En déploiement FP8, GLM-5 nécessite généralement deux fois plus de GPU que GLM-4.7.
Pour les développeurs avec des budgets limités, GLM-4.7 offre un meilleur rapport performance/coût dans les charges de travail centrées sur le codage, atteignant 73,8 % sur SWE-bench Verified et 84,9 % sur LiveCodeBench-v6.
Pour la recherche de pointe et le développement de systèmes agentiques, les capacités d’utilisation d’outils et d’exécution à long terme de GLM-5 peuvent justifier l’investissement matériel supplémentaire.
Tarification et accès API de GLM-5 et GLM-4.7
| Modèle | Entrée ($/M tokens) | Lecture cache ($/M tokens) | Sortie ($/M tokens) |
|---|---|---|---|
| GLM-4.7 | 0,60 $ | 0,11 $ | 2,20 $ |
| GLM-5 | 1,00 $ | 0,20 $ | 3,20 $ |
Lecture cache fait référence au coût de lecture des tokens précédemment stockés dans le cache de prompt. Lorsque le même contenu de prompt est réutilisé entre plusieurs requêtes, le modèle récupère ces tokens directement depuis le cache au lieu de les traiter à nouveau depuis le début. Cela réduit à la fois la latence d’inférence et le coût.
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Bibliothèque de modèles.

Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.

Étape 3 : Démarrez votre essai gratuit
Commencez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Étape 4 : Obtenez votre clé API
Pour vous authentifier avec l’API, nous vous fournirons une nouvelle clé API. En entrant dans la page « Paramètres », vous pouvez copier la clé API comme indiqué dans l’image.

Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.
Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec Novita AI LLM. Voici un exemple d’utilisation de l’API chat completions pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
api_key="<Votre clé API>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="zai-org/glm-5 or zai-org/glm-4.7",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
Résumé du cadre de décision de GLM-5 et GLM-4.7
| Scénario | Modèle recommandé | Raison principale |
|---|---|---|
| Systèmes multi-agents avec orchestration d’outils | GLM-5 | +15,8pp sur MCP-Atlas, +14,2pp sur Tool-Decathlon |
| Flux de travail SWE-bench en production | GLM-4.7 | 73,8 % pour la moitié du coût matériel |
| Cybersécurité et tests d’intrusion | GLM-5 | 43,2 % CyberGym |
| Codage basé sur IDE (Claude Code, Cline) | GLM-4.7 | Thinking préservé + latence inférieure |
| Recherche de raisonnement de pointe (HLE) | GLM-5 | 50,4 % avec outils (meilleur open source) |
| Codage d’interface utilisateur « vibe coding » | GLM-4.7 | Entraînement spécialisé pour l’UI web moderne |
| Automatisation de terminal (long terme) | GLM-5 | +28,3pp sur Terminal-Bench 2.0 |
| Compétitions mathématiques (AIME, HMMT) | GLM-4.7 | Égal ou dépasse GLM-5 à moindre coût |
| Startups à budget limité | GLM-4.7 | Codage performant avec 4x H100 contre 8x H100 |
| Laboratoires de recherche repoussant les limites de l’AGI | GLM-5 | Pré-entraînement sur 28,5T tokens, infrastructure RL slime |
GLM-5 ne rend pas GLM-4.7 obsolète – il répond à des problèmes différents. Si votre travail implique des tâches agentiques à long terme nécessitant une utilisation intensive d’outils et un raisonnement multi-étapes, l’investissement matériel 2x de GLM-5 est rentabilisé par les taux d’achèvement des tâches. Si vous livrez des assistants de codage à des milliers de développeurs ou avez besoin de cycles d’itération rapides dans des environnements IDE, l’architecture plus légère et l’entraînement spécialisé de GLM-4.7 en font le meilleur choix. Les deux modèles représentent des réalisations significatives dans la modélisation du langage open source, comblant l’écart avec les modèles propriétaires de pointe tout en maintenant une transparence totale et une flexibilité de déploiement local.
Questions fréquentes
Quelle est la principale différence architecturale entre GLM-5 et GLM-4.7 ?
GLM-5 passe de 355B à 753,9B paramètres totaux (32B à 40B actifs) et intègre DeepSeek Sparse Attention (DSA) pour réduire les coûts de déploiement tout en conservant une longueur de contexte de 202K.
Puis-je exécuter GLM-5 sur du matériel grand public ?
Non. GLM-5 nécessite au moins 10x GPU H100 80GB en mode FP8 (800GB VRAM), ce qui dépasse largement les capacités du matériel grand public.
Quel modèle est le meilleur pour les tâches de codage SWE-bench ?
GLM-5 devance légèrement GLM-4.7 avec 77,8 % sur SWE-bench Verified (+4pp), mais les 73,8 % de GLM-4.7 pour la moitié du coût matériel le rendent plus pratique pour la production.
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles IA via notre API, tout en fournissant un cloud GPU abordable et fiable pour construire et passer à l’échelle.
Lectures recommandées



