

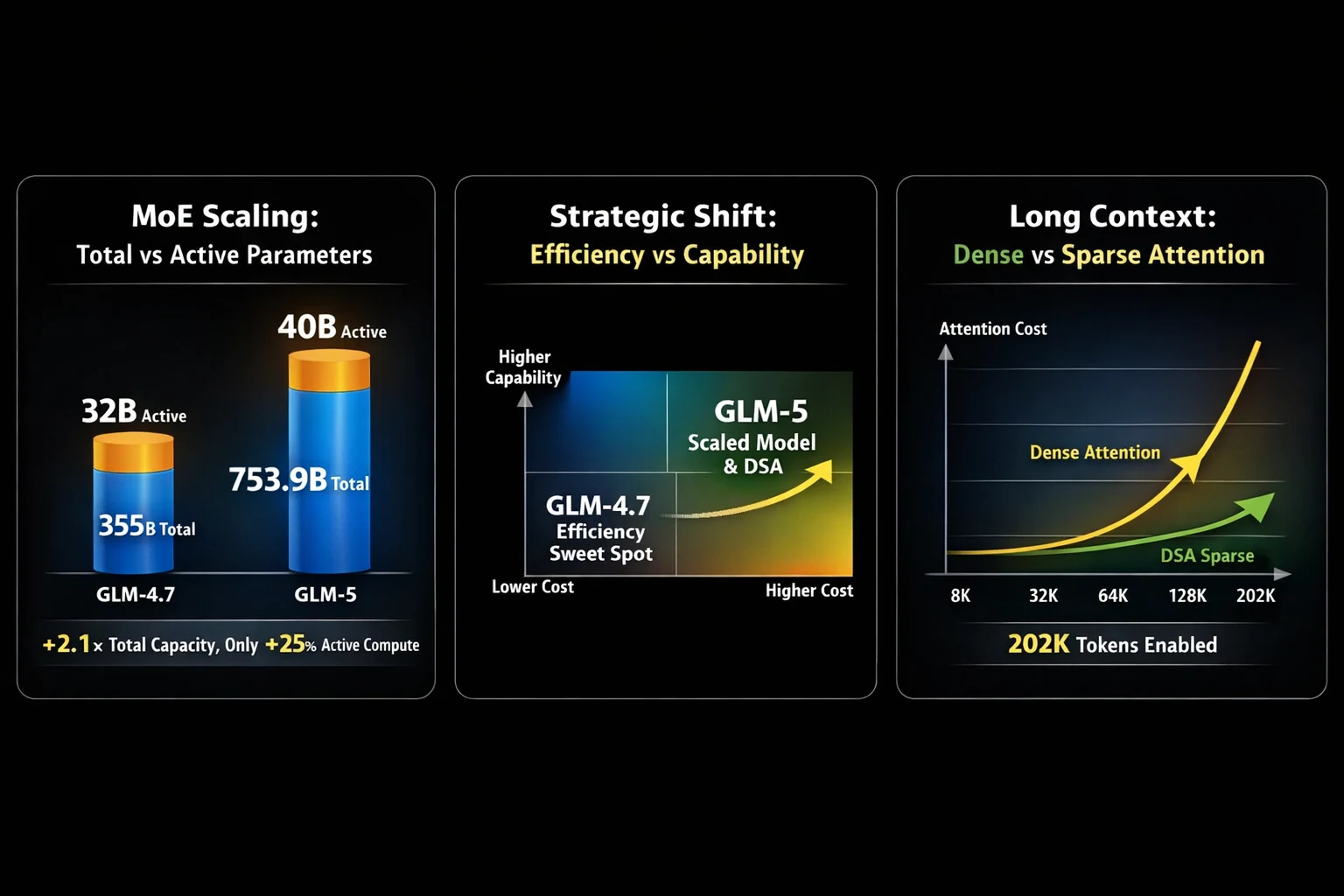
Die Wahl zwischen GLM-5 und GLM-4.7 hängt oft von einem entscheidenden Kompromiss ab: massiv skalierte agentische Stärke versus bewährte Coding-Vielseitigkeit. GLM-5, das von Z.ai veröffentlicht wurde, skaliert deutlich gegenüber seinem Vorgänger: Es springt von 355B Parametern (32B aktiv) bei GLM-4.7 auf 753,9B Parameter (40B aktiv). Diese 2,1-fache Parametererweiterung bringt erhebliche Verbesserungen bei komplexer Systemtechnik und langfristigen agentischen Aufgaben, aber GLM-4.7 bleibt ein Spitzenmodell für mehrsprachiges Coding, Terminalautomatisierung und praktische Entwickler-Workflows.
Architekturvergleich von GLM-5 und GLM-4.7
| Spezifikation | GLM-5 | GLM-4.7 |
|---|---|---|
| Gesamtzahl der Parameter | 753,9B | 355B |
| Aktive Parameter | 40B | 32B |
| Kontextlänge | 202.752 Tokens | 202.752 Tokens |
| Vortrainingsdaten | 28,5T Tokens | 23T Tokens |
| Präzision | BF16 (FP8 verfügbar) | BF16 (FP8 verfügbar) |
| Multimodale Unterstützung | Nur Text | Nur Text |
| Veröffentlichungsdatum | Januar 2026 | Dezember 2025 |
Eine der praktischsten Upgrades von GLM-5 ist die Integration der DeepSeek Sparse Attention (DSA), die die Kosten für Long-Context-Attention deutlich senkt und gleichzeitig große Kontextfenster von bis zu 202K Tokens beibehält. Dadurch ist GLM-5 deutlich einfacher für den Einsatz in realen Anwendungsfällen wie Langdokument-Recherche, Multi-Turn-Assistenten und agentischen Workflows einsetzbar. Auf der Post-Training-Seite profitiert GLM-5 von slime, einer neuen asynchronen Reinforcement-Learning-Infrastruktur, die den RL-Trainingsdurchsatz erhöht und häufigere, feinere Ausrichtungsschleifen ermöglicht.
Benchmark-Vergleich von GLM-5 und GLM-4.7
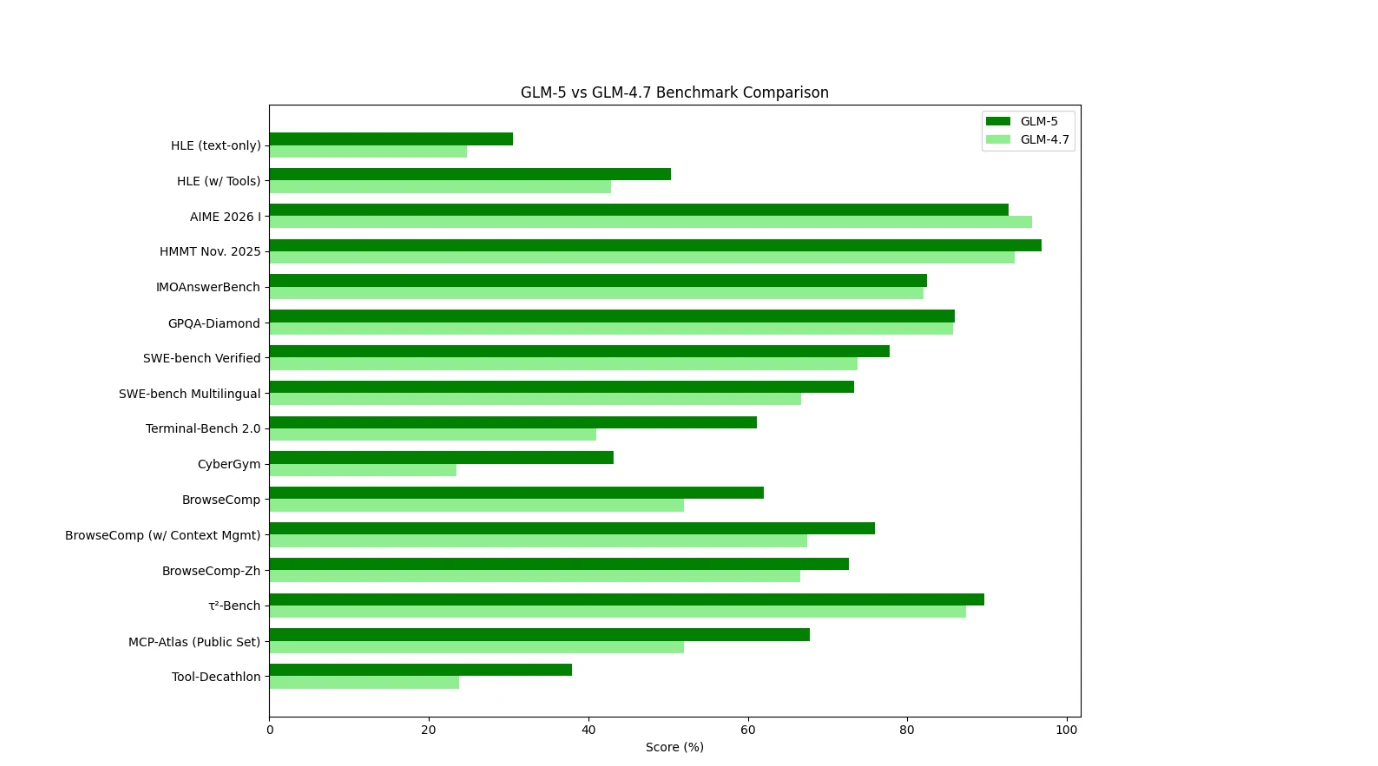
Aus Benchmark-Sicht zeigt GLM-5 eine breite und konsistente Verbesserung gegenüber GLM-4.7, insbesondere bei Tool-Nutzung, Browsing und agentischen Einstellungen. Die größten Zuwächse treten in Umgebungen auf, die mehrstufige Planung, Kontextverwaltung und reale Ausführung erfordern, was darauf hindeutet, dass GLM-5 für agentische Workflows optimiert ist, statt für isolierte Reasoning-Aufgaben.
GLM-4.7 schneidet bei Benchmarks wie ein effizienzoptimiertes Reasoning-/Coding-Modell ab, ist immer noch sehr stark bei klassischen mathematischen Auswertungen, aber weniger dominant bei interaktiven, toolgesteuerten Aufgaben.
VRAM-Anforderungen von GLM-5 und GLM-4.7
Die 2,1-fache Parametererhöhung von GLM-4.7 zu GLM-5 hat erhebliche Hardware-Auswirkungen. Hier ist die Aufschlüsselung des VRAM-Bedarfs:
Empfohlene GPU-Konfiguration für GLM-5
| Präzision | Erforderlicher VRAM | Empfohlene Konfiguration | Anwendungsfall |
|---|---|---|---|
| BF16 | 1508 GB | 19x NVIDIA H100 (80GB) | Maximale Qualitätsforschung |
| FP8 | Ca. 800 GB | 10x NVIDIA H100 (80GB) | Produktionseinsatz |
| INT4 | Ca. 400 GB | 5x H100 (80GB) | Kosteneffiziente Inferenz |
Empfohlene GPU-Konfiguration für GLM-4.7
| Präzision | Erforderlicher VRAM | Empfohlene Konfiguration | Anwendungsfall |
|---|---|---|---|
| BF16 | 717 GB | 9x NVIDIA H100 (80GB) | Maximale Qualität |
| FP8 | 390 GB | 5x H100 (80GB) | Produktionseinsatz |
| INT4 | 200 GB | 3x H100 (80GB) | Kosteneffiziente Inferenz |
Teste kosteneffektive GPUs jetzt!
Bei FP8-Einsatz benötigt GLM-5 in der Regel doppelt so viele GPUs wie GLM-4.7.
Für Entwickler mit begrenztem Budget bietet GLM-4.7 ein besseres Preis-Leistungs-Verhältnis bei coding-lastigen Workflows, mit 73,8 % bei SWE-bench Verified und 84,9 % bei LiveCodeBench-v6.
Für Spitzenforschung und die Entwicklung agentischer Systeme können die stärkeren Tool-Fähigkeiten und die langfristigen Ausführungsmöglichkeiten von GLM-5 die zusätzliche Hardware-Investition rechtfertigen.
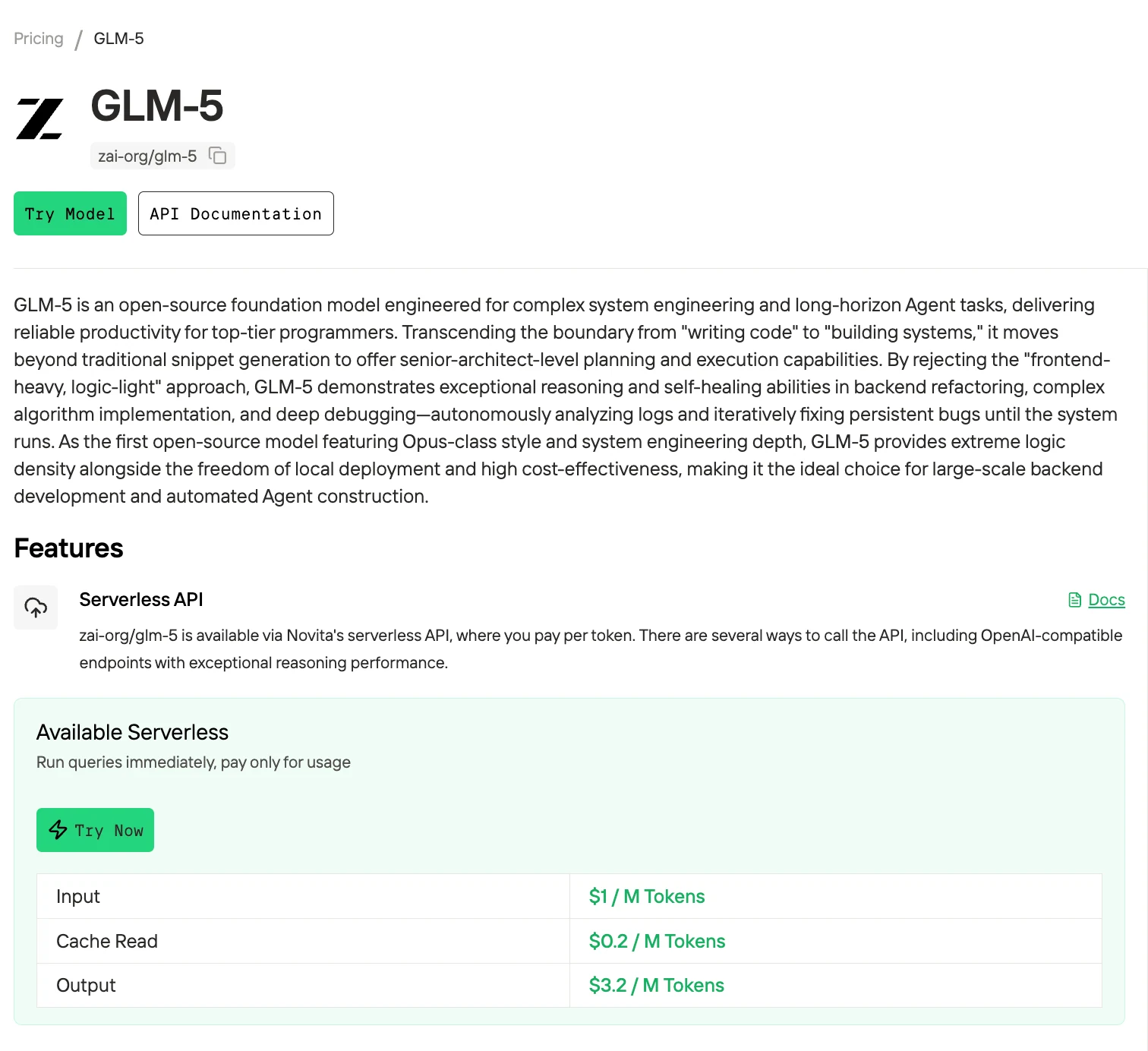
Preise & API-Zugriff von GLM-5 und GLM-4.7
| Modell | Eingabe ($ / M Tokens) | Cache-Lesen ($ / M Tokens) | Ausgabe ($ / M Tokens) |
|---|---|---|---|
| GLM-4.7 | $0,60 | $0,11 | $2,20 |
| GLM-5 | $1,00 | $0,20 | $3,20 |
Cache-Lesen bezieht sich auf die Kosten für das Lesen von Tokens, die zuvor im Prompt-Cache gespeichert wurden. Wenn derselbe Prompt-Inhalt über mehrere Anfragen hinweg wiederverwendet wird, ruft das Modell diese Tokens direkt aus dem Cache ab, statt sie von Grund auf neu zu verarbeiten. Dies reduziert sowohl die Inferenzlatenz als auch die Kosten.
Schritt 1: Einloggen und Zugriff auf die Modellbibliothek
Logge dich in deinem Konto ein und klicke auf die Schaltfläche Modellbibliothek.

Schritt 2: Wähle dein Modell
Durchstöbere die verfügbaren Optionen und wähle das Modell, das deinen Anforderungen entspricht.

Schritt 3: Starte deine kostenlose Testphase
Starte deine kostenlose Testphase, um die Fähigkeiten des ausgewählten Modells kennenzulernen.
Schritt 4: Hol dir deinen API-Schlüssel
Um dich gegenüber der API zu authentifizieren, stellen wir dir einen neuen API-Schlüssel zur Verfügung. Auf der Seite „Einstellungen“ kannst du den API-Schlüssel wie in der Abbildung gezeigt kopieren.

Schritt 5: Installiere die API
Installiere die API über den Paketmanager deiner Programmiersprache.
Nach der Installation importierst du die benötigten Bibliotheken in deine Entwicklungsumgebung. Initialisiere die API mit deinem API-Schlüssel, um mit dem Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Nutzung der Chat-Completions-API für Python-Nutzer.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="zai-org/glm-5 or zai-org/glm-4.7",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
Entscheidungsrahmenübersicht von GLM-5 und GLM-4.7
| Szenario | Empfohlenes Modell | Hauptgrund |
|---|---|---|
| Multi-Agenten-Systeme mit Tool-Orchestrierung | GLM-5 | +15,8 pp bei MCP-Atlas, +14,2 pp bei Tool-Decathlon |
| Produktive SWE-bench-Workflows | GLM-4.7 | 73,8 % bei halben Hardware-Kosten |
| Cybersicherheit & Pentesting | GLM-5 | 43,2 % bei CyberGym |
| IDE-basiertes Coding (Claude Code, Cline) | GLM-4.7 | Erhaltenes Denken + geringere Latenz |
| Spitzen-Reasoning-Forschung (HLE) | GLM-5 | 50,4 % mit Tools (bestes Open-Source-Modell) |
| UI/Frontend-„Vibe Coding“ | GLM-4.7 | Spezialisiertes Training für moderne Web-UI |
| Terminalautomatisierung (langfristig) | GLM-5 | +28,3 pp bei Terminal-Bench 2.0 |
| Mathewettbewerbe (AIME, HMMT) | GLM-4.7 | Erreicht/übertrifft GLM-5 bei geringeren Kosten |
| Budget-beschränkte Startups | GLM-4.7 | Starkes Coding-Leistung bei 4x H100 im Vergleich zu 8x H100 |
| Forschungslabore, die AGI-Grenzen verschieben | GLM-5 | 28,5T Token Vortraining, slime RL-Infrastruktur |
GLM-5 löst GLM-4.7 nicht ab — es adressiert unterschiedliche Problemstellungen. Wenn deine Arbeit langfristige agentische Aufgaben umfasst, die umfangreiche Tool-Nutzung und mehrstufiges Reasoning erfordern, zahlt sich die 2-fache Hardware-Investition in GLM-5 durch höhere Aufgabenabschlussraten aus. Wenn du Coding-Assistenten an Tausende von Entwickler auslieferst oder schnelle Iterationszyklen in IDE-Umgebungen benötigst, ist die schlankere Architektur und das spezialisierte Training von GLM-4.7 die bessere Wahl. Beide Modelle stellen bedeutende Errungenschaften im Bereich des Open-Source-Sprachmodellierens dar, schließen die Lücke zu proprietären Spitzenmodellen und behalten dabei volle Transparenz sowie Flexibilität für lokale Einsätze.
Häufig gestellte Fragen
Was ist der Hauptunterschied in der Architektur zwischen GLM-5 und GLM-4.7?
GLM-5 skaliert von 355B auf 753,9B Gesamtparameter (32B auf 40B aktiv) und integriert die DeepSeek Sparse Attention (DSA), um Einsatzkosten zu senken und gleichzeitig eine Kontextlänge von 202K Tokens beizubehalten.
Kann ich GLM-5 auf Consumer-Hardware betreiben?
Nein. GLM-5 benötigt mindestens 10x H100 80GB GPUs im FP8-Modus (800 GB VRAM), was die Fähigkeiten von Consumer-GPUs bei weitem übersteigt.
Welches Modell eignet sich besser für SWE-bench-Coding-Aufgaben?
GLM-5 liegt mit 77,8 % bei SWE-bench Verified knapp vor GLM-4.7 (+4 pp), aber die 73,8 % von GLM-4.7 bei halben Hardware-Kosten machen es praktischer für den Produktionseinsatz.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API einzusetzen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud für Aufbau und Skalierung bereitstellt.
Empfohlene Lektüre



