

Модели с открытыми весами теперь достаточно мощные для реальных рабочих нагрузок в продакшене: агентное программирование, рабочие процессы с длинным контекстом и ассистенты, использующие инструменты, без привязки к одному поставщику. Две модели, которые часто упоминаются в обсуждениях на тему «быстрые + производительные», — это GLM-4.7-Flash и GPT-OSS-20B.
В этом посте мы сравниваем их с практической точки зрения — качество (бенчмарки), скорость/задержка и стоимость, а также покажем, как запустить обе модели прямо сейчас через API на Novita AI.
Основное введение
Обе являются MoE-моделями (моделями смеси экспертов), созданными для высокой эффективности, но с разными акцентами:
- GLM-4.7-Flash: баланс производительности и эффективности класса «30B» (отлично подходит для рабочих процессов с длинным контекстом).
- GPT-OSS-20B: открытая модель от OpenAI, оптимизированная для низкой задержки / удобства использования на одном GPU и работы с инструментами.
| GLM-4.7-Flash | GPT-OSS-20B | |
| Разработчик | Z.ai | OpenAI |
| Дата релиза | 20 января 2026 г. | 5 августа 2025 г. |
| Параметры (активные) | 30B-A3B (MoE) | 21B всего / 3.6B активных (MoE) |
| Контекст Novita | 200 000 | 131 072 |
| Цена на Novita | Вход $0.07/М · Выход $0.40/М | Вход $0.04/М · Выход $0.15/М |
Сравнение по бенчмаркам
На рисунке представлены результаты по 6 бенчмаркам: SWE-bench Verified, τ²-Bench, BrowseComp, AIME 25, GPQA, HLE. Эти же цифры указаны на странице модели GLM-4.7-Flash на Hugging Face, которую мы используем как авторитетный источник.
| Бенчмарк | GLM-4.7-Flash | GPT-OSS-20B | Победитель |
| SWE-bench Verified | 59.2 | 34 | GLM-4.7-Flash |
| τ²-Bench | 79.5 | 47.7 | GLM-4.7-Flash |
| BrowseComp | 42.8 | 28.3 | GLM-4.7-Flash |
| AIME 25 | 91.6 | 91.7 | GPT-OSS-20B (незначительно) |
| GPQA | 75.2 | 71.5 | GLM-4.7-Flash |
| HLE | 14.4 | 10.9 | GLM-4.7-Flash |
💡Интерпретация
Большинство бенчмарков отдают предпочтение GLM-4.7-Flash — она лидирует в пяти оценках, а по AIME 25 результаты практически равны (91.6 против 91.7).
- Задачи с агентами и интенсивным использованием инструментов: GLM-4.7-Flash явно лидирует в SWE-bench Verified и τ²-Bench, которые тесно связаны с реальными рабочими процессами агентов (программирование/терминал, многошаговые взаимодействия).
- Задачи, связанные с браузингом: GLM-4.7-Flash также лидирует в BrowseComp, что говорит о более сильном поведении навигации/выбора на дальних горизонтах в условиях оценки.
- Математика: По AIME 25 результаты практически равны (91.6 против 91.7). Другими словами: не стоит выбирать модель только по этому показателю.
- Вопросы и ответы, требующие больших знаний: GLM-4.7-Flash опережает по GPQA и HLE в этом наборе отчетов.
Сравнение скорости и задержки
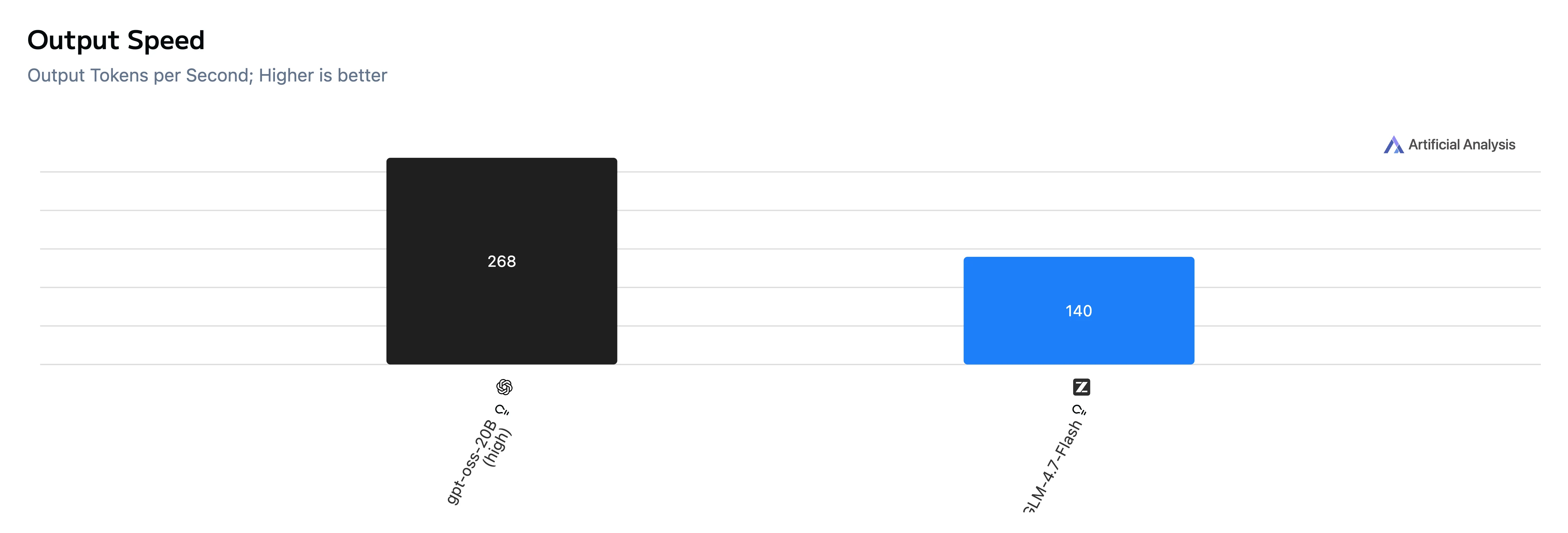
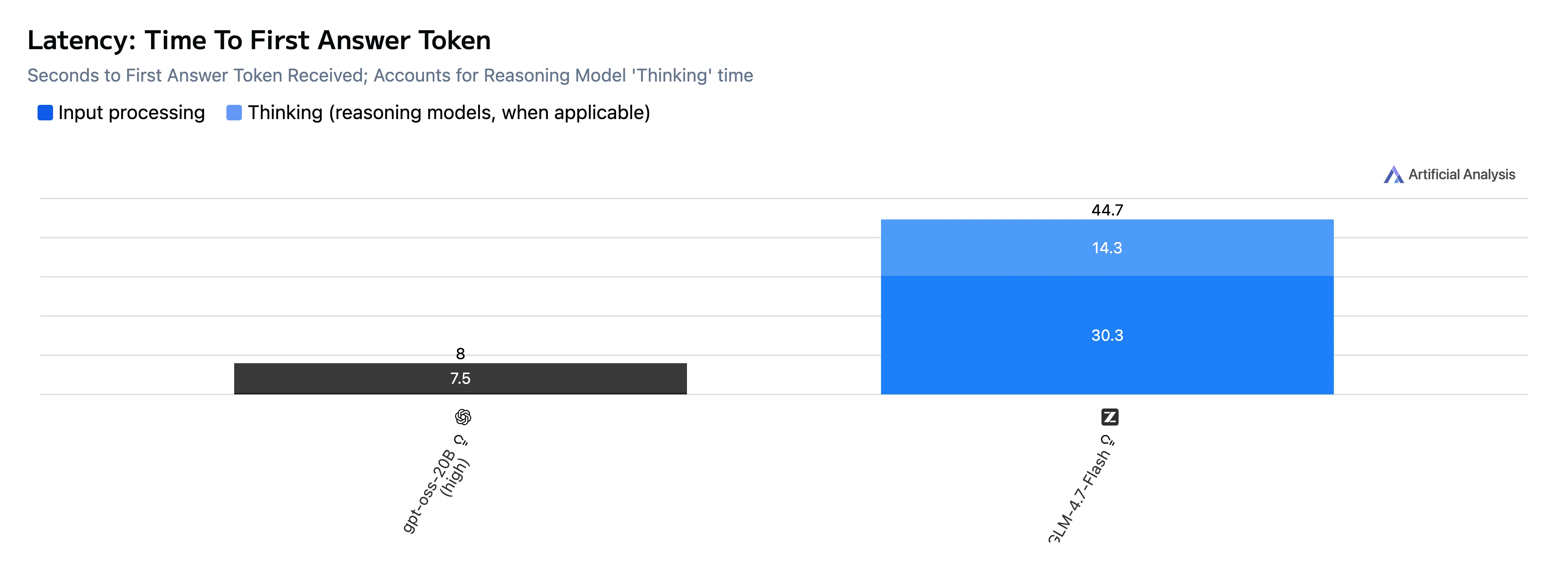
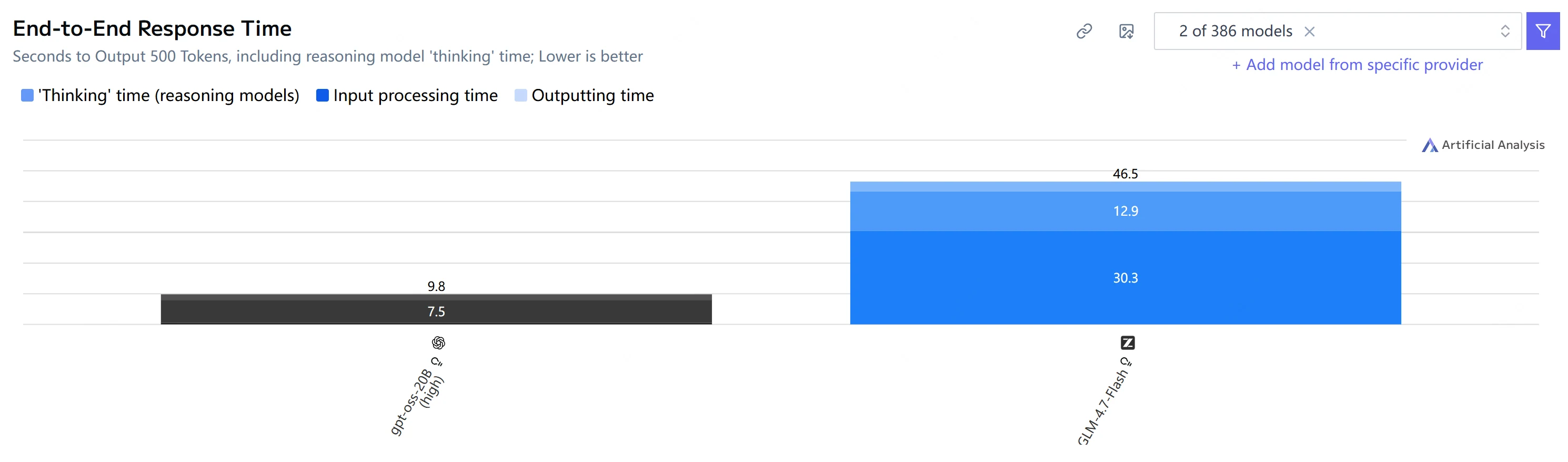
| Метрика | GPT-OSS-20B | GLM-4.7-Flash |
| Скорость вывода | 268 ток/с | 140 ток/с |
| TTFT (время до первого токена ответа) | 8,0 с | 46,5 с |
| Сквозное время ответа (500 токенов вывода) |
9,8 с | 46,5 с |
Вывод: GPT-OSS-20B значительно быстрее как по времени до первого токена (TTFT), так и по сквозному времени генерации, а также выводит токены быстрее в этом наборе тестов.
Сравнение стоимости
| Модель | Ввод (USD / 1M токенов) | Вывод (USD / 1M токенов) | Чтение из кэша (USD / 1M токенов) |
| GLM-4.7-Flash (zai-org/glm-4.7-flash) | $0.07 | $0.40 | $0.01 |
| GPT-OSS-20B (openai/gpt-oss-20b) | $0.04 | $0.15 | - |
GPT-OSS-20B является более экономичным выбором на токен, в то время как GLM-4.7-Flash стоит дороже, но может быть оправдан, если вам нужна более высокая производительность и возможность работы с длинным контекстом. Если вы хотите получить больше деталей, перейдите в Библиотеку моделей Novita AI, чтобы ознакомиться с актуальными ценами и характеристиками моделей.
Быстрый старт: Попробуйте обе модели мгновенно в Playground
Если вы хотите сразу ощутить разницу между GLM-4.7-Flash и GPT-OSS-20B, самый быстрый способ — использовать Novita AI Playground — без кода и настроек.
В Playground вы можете:
- Мгновенно переключайтесь между моделями GLM-4.7-Flash и GPT-OSS-20B
- Используйте один и тот же запрос, чтобы сравнить качество вывода, стиль рассуждений и скорость ответа
Novita AI Playground
Развертывание: API, SDK и интеграции со сторонними платформами
API
Получить API-ключ
- Шаг 1: Создайте учетную запись или войдите в существующую
Перейдите на [**https://novita.ai**](https://novita.ai) и зарегистрируйтесь или войдите в свою существующую учетную запись
- Шаг 2: Перейдите в раздел управления ключами
После входа в систему найдите раздел «API-ключи»

- Шаг 3: Создайте новый ключ
Нажмите кнопку «Добавить новый ключ».

- Шаг 4: Немедленно сохраните свой ключ
Скопируйте и сохраните ключ сразу после генерации: обычно он отображается только один раз и не может быть восстановлен позже. Храните ключ в безопасном месте, например в менеджере паролей или зашифрованных заметках
Совместимый с OpenAI API (Python)
from openai import OpenAI
client = OpenAI(
api_key="<YOUR_NOVITA_API_KEY>",
base_url="https://api.novita.ai/openai",
)
resp = client.chat.completions.create(
model="zai-org/glm-4.7-flash",
messages=[
{"role": "system", "content": "You are a precise engineering assistant. Output valid JSON when asked."},
{"role": "user", "content": "Summarize the key risks of rolling out feature flags across 20 services."},
],
temperature=0.3,
max_tokens=4096,
)
print(resp.choices[0].message.content)
SDK
Если вы создаете агентные рабочие процессы (передача задач, маршрутизация, вызовы инструментов/функций), вы можете запускать размещенные на Novita модели внутри OpenAI Agents SDK с минимальными изменениями:
- Полная совместимость: Novita предоставляет совместимый с OpenAI API, поэтому ваш рабочий процесс с агентами останется прежним — изменятся только базовый URL и модель.
- Готовность к оркестрации агентов: Используйте маршрутизацию и инструменты для делегирования задач, сохраняя инференс на Novita.
- Настройка: Укажите SDK адрес
https://api.novita.ai/openai, задайте переменнуюNOVITA_API_KEY, выберите модельzai-org/glm-4.7-flash(илиopenai/gpt-oss-20b).
Сторонние платформы
Вы также можете использовать размещенные на Novita модели через популярные экосистемы:
- Фреймворки для агентов и конструкторы приложений: Следуйте пошаговым руководствам по интеграции от Novita, чтобы подключиться к популярным инструментам, таким как Continue, AnythingLLM, LangChain и Langflow.
- Hugging Face Hub: Novita указана как Поставщик инференса на Hugging Face, поэтому вы можете запускать поддерживаемые модели через рабочий процесс и экосистему поставщика Hugging Face.
- Совместимый с OpenAI API: Эндпоинты LLM Novita совместимы со стандартом API OpenAI, что упрощает миграцию существующих приложений в стиле OpenAI и подключение многих совместимых с OpenAI инструментов ( Cline, Cursor, Trae и Qwen Code) .
- Совместимый с Anthropic API: Novita также предоставляет доступ, совместимый с SDK Anthropic, поэтому вы можете интегрировать модели на базе Novita в агентные рабочие процессы программирования в стиле Claude Code.
- OpenCode: Novita AI теперь напрямую интегрирована в OpenCode как поддерживаемый поставщик, поэтому пользователи могут выбрать Novita в OpenCode без ручной настройки.
Заключение
- GLM-4.7-Flash — лучший выбор, если для вас наиболее важны качество агентных задач/программирования и очень длинный контекст (200K) — она лидирует в 5 из 6 бенчмарков в представленной таблице (по AIME результаты практически равны).
- GPT-OSS-20B — лучший выбор, если для вас наиболее важны скорость и стоимость — она значительно быстрее по представленным графикам задержки и дешевле по бессерверным тарифам Novita.
Самый быстрый путь: попробуйте обе модели в Novita AI Playground, а затем переходите к API / SDK / интеграциям со сторонними платформами в зависимости от того, что вы строите.
Novita AI — это облачная платформа для ИИ, которая предлагает разработчикам простой способ развертывать модели ИИ с помощью нашего простого API, а также предоставляет доступное и надежное облако GPU для разработки и масштабирования.
Часто задаваемые вопросы
Что такое GLM-4.7-Flash?
GLM-4.7-Flash — это большая языковая модель (LLM) класса 30B с архитектурой смеси экспертов (MoE), разработанная Zhipu AI. Она создана для обеспечения высокой производительности в задачах рассуждений, программирования и агентных задач при высокой эффективности и низкой задержке.
Сколько стоит GLM-4.7-Flash?
На Novita AI (бессерверный режим) стоимость GLM-4.7-Flash составляет $0.07 за 1M входных токенов, $0.01 за 1M токенов чтения из кэша и $0.40 за 1M выходных токенов, что делает ее экономически выгодной для рабочих нагрузок с большим контекстом и высокой пропускной способностью.
Что лучше: GLM-4.7-Flash или GPT-OSS-20B?
Это зависит от сценария использования: GLM-4.7-Flash обычно показывает лучшие результаты в агентных задачах, задачах с интенсивным использованием инструментов и реальных бенчмарках, в то время как GPT-OSS-20B может быть предпочтительнее для легковесных, низкозадержочных развертываний на одном GPU.



