

Les modèles à poids ouverts sont désormais suffisamment performants pour des charges de travail de production réelles — codage agentique, workflows de contexte long et assistants utilisant des outils, sans vous enfermer dans un seul fournisseur. Deux modèles qui reviennent souvent dans les discussions sur les modèles « rapides et performants » sont GLM-4.7-Flash et GPT-OSS-20B.
Ce blog les compare sous un angle pratique — qualité (benchmarks), vitesse/latence et coût, et montre comment exécuter les deux immédiatement sur Novita AI via des API.
Introduction générale
Les deux sont des modèles MoE conçus pour une haute efficacité, mais avec des emphases différentes :
- GLM-4.7-Flash : Équilibre de capacité et d’efficacité de « classe 30B » (parfait pour les workflows de contexte long).
- GPT-OSS-20B : Modèle open-weight d’OpenAI optimisé pour une latence réduite / compatibilité avec un seul GPU et l’utilisation d’outils.
| GLM-4.7-Flash | GPT-OSS-20B | |
| Développeur | Z.ai | OpenAI |
| Date de publication | 20 janv. 2026 | 5 août 2025 |
| Paramètres (actifs) | 30B-A3B (MoE) | 21B total / 3,6B actifs (MoE) |
| Contexte Novita | 200 000 | 131 072 |
| Tarification Novita | Entrée 0,07 $/M · Sortie 0,40 $/M | Entrée 0,04 $/M · Sortie 0,15 $/M |
Comparaison des benchmarks
La figure présente les résultats sur 6 benchmarks : SWE-bench Verified, τ²-Bench, BrowseComp, AIME 25, GPQA, HLE. Ces mêmes chiffres sont listés sur la page Hugging Face du modèle GLM-4.7-Flash, que nous utilisons comme source faisant autorité.
| Benchmark | GLM-4.7-Flash | GPT-OSS-20B | Gagnant |
| SWE-bench Verified | 59,2 | 34 | GLM-4.7-Flash |
| τ²-Bench | 79,5 | 47,7 | GLM-4.7-Flash |
| BrowseComp | 42,8 | 28,3 | GLM-4.7-Flash |
| AIME 25 | 91,6 | 91,7 | GPT-OSS-20B (légèrement) |
| GPQA | 75,2 | 71,5 | GLM-4.7-Flash |
| HLE | 14,4 | 10,9 | GLM-4.7-Flash |
💡Interprétation
Les benchmarks sont majoritairement favorables à GLM-4.7-Flash — il est en tête sur cinq évaluations, AIME 25 étant quasiment à égalité (91,6 contre 91,7).
- Tâches agentiques et lourdes en outils : GLM-4.7-Flash est clairement en tête sur SWE-bench Verified et τ²-Bench, qui sont étroitement liés aux workflows agentiques réels (codage/terminal, interactions multi-étapes).
- Tâches de navigation : GLM-4.7-Flash est également en tête sur BrowseComp, ce qui suggère un comportement de navigation/sélection à long terme plus fort dans les paramètres d’évaluation.
- Mathématiques : AIME 25 est quasiment à égalité (91,6 contre 91,7). En d’autres termes : ne vous basez pas uniquement sur ce critère pour choisir.
- QA riche en connaissances : GLM-4.7-Flash est en tête sur GPQA et HLE dans ce jeu de données.
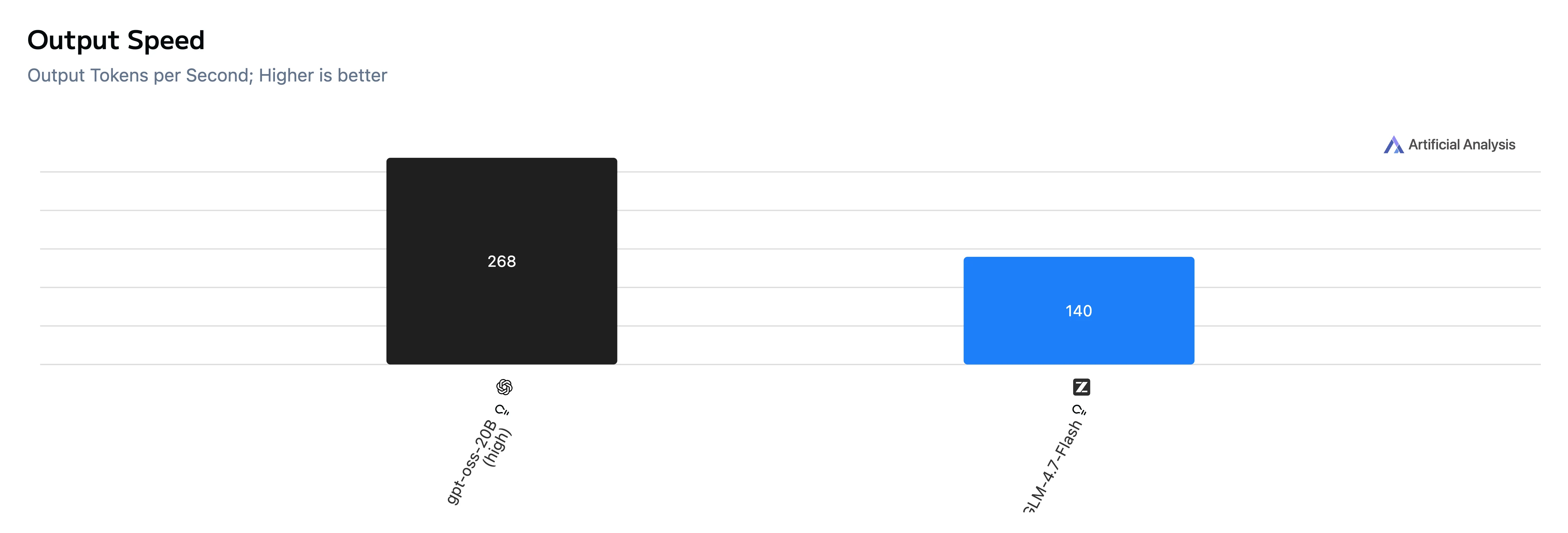
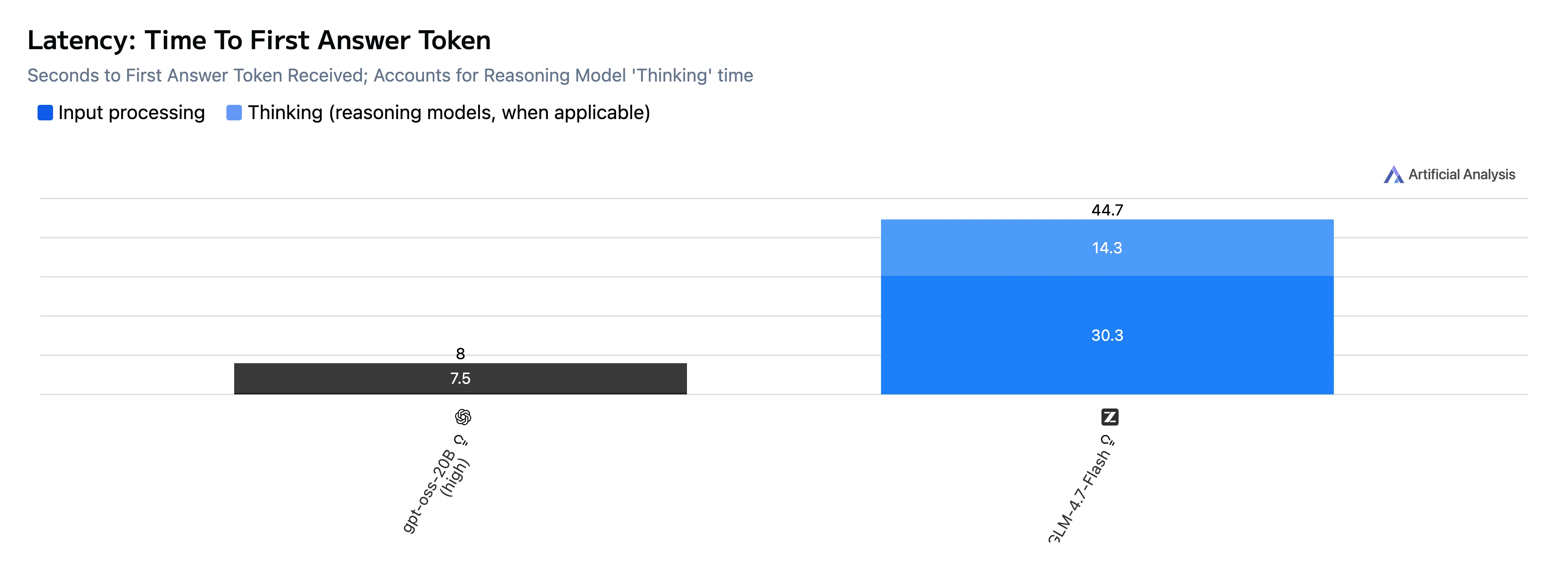
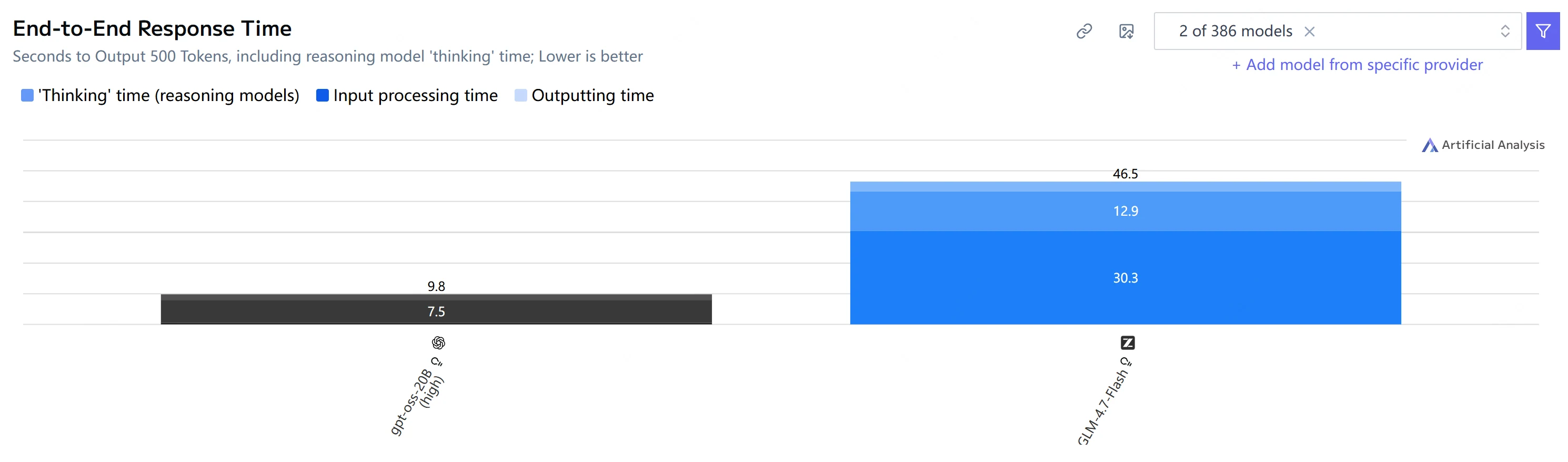
Comparaison de la vitesse et de la latence
| Métrique | GPT-OSS-20B | GLM-4.7-Flash |
| Vitesse de sortie | 268 tok/s | 140 tok/s |
| TTFT (premier jeton de réponse) | 8,0 s | 46,5 s |
| Temps de bout en bout (500 jetons de sortie) |
9,8 s | 46,5 s |
Point clé : GPT-OSS-20B est beaucoup plus rapide tant sur le temps jusqu’au premier jeton que sur la génération de bout en bout, et produit également des jetons plus rapidement dans ce jeu de tests.
Comparaison des coûts
| Modèle | Entrée (USD / 1M jetons) | Sortie (USD / 1M jetons) | Lecture de cache (USD / 1M jetons) |
| GLM-4.7-Flash (zai-org/glm-4.7-flash) | 0,07 $ | 0,40 $ | 0,01 $ |
| GPT-OSS-20B (openai/gpt-oss-20b) | 0,04 $ | 0,15 $ | - |
GPT-OSS-20B est le choix le plus rentable par jeton, tandis que GLM-4.7-Flash coûte plus cher mais peut en valoir la peine si vous avez besoin de performances supérieures et de capacités de contexte long. Si vous souhaitez plus de détails, rendez-vous sur la Bibliothèque de modèles de Novita AI pour consulter les derniers tarifs et spécifications des modèles.
Démarrage rapide : Essayez les deux modèles instantanément sur le Playground
Si vous souhaitez découvrir immédiatement la différence entre GLM-4.7-Flash et GPT-OSS-20B, la méthode la plus rapide est d’utiliser le Novita AI Playground — pas de code, pas de configuration.
Dans le Playground, vous pouvez :
- Basculez instantanément entre les modèles GLM-4.7-Flash et GPT-OSS-20B
- Utilisez le même prompt pour comparer la qualité des sorties, le style de raisonnement et la vitesse de réponse
Novita AI Playground
Comment déployer : API, SDK et intégrations tierces
API
Obtenir une clé API
-
Étape 1 : Créer un compte ou se connecter Visitez
[**https://novita.ai**](https://novita.ai)et inscrivez-vous ou connectez-vous à votre compte existant -
Étape 2 : Accéder à la gestion des clés Après connexion, recherchez « Clés API »

- Étape 3 : Créer une nouvelle clé Cliquez sur le bouton « Ajouter une nouvelle clé ».

- Étape 4 : Enregistrez votre clé immédiatement Copiez et stockez la clé dès qu’elle est générée ; elle n’est généralement affichée qu’une seule fois et ne peut pas être récupérée ultérieurement. Conservez la clé dans un endroit sécurisé comme un gestionnaire de mots de passe ou des notes chiffrées
API compatible OpenAI (Python)
from openai import OpenAI
client = OpenAI(
api_key="<YOUR_NOVITA_API_KEY>",
base_url="https://api.novita.ai/openai",
)
resp = client.chat.completions.create(
model="zai-org/glm-4.7-flash",
messages=[
{"role": "system", "content": "You are a precise engineering assistant. Output valid JSON when asked."},
{"role": "user", "content": "Summarize the key risks of rolling out feature flags across 20 services."},
],
temperature=0.3,
max_tokens=4096,
)
print(resp.choices[0].message.content)
SDK
Si vous développez des workflows agentiques (transferts, routage, appels d’outils/fonctions), vous pouvez exécuter les modèles hébergés par Novita dans le SDK Agents d’OpenAI avec des modifications minimales :
- Compatibilité immédiate : Novita expose une API compatible OpenAI, donc votre workflow Agents reste identique — seul l’URL de base et le modèle changent.
- Prêt pour l’orchestration agentique : Utilisez le routage et les outils pour déléguer des tâches tout en gardant l’inférence sur Novita.
- Configuration : pointez le SDK vers
https://api.novita.ai/openai, définissezNOVITA_API_KEY, sélectionnezzai-org/glm-4.7-flash(ouopenai/gpt-oss-20b).
Plateformes tierces
Vous pouvez également utiliser les modèles hébergés par Novita via des écosystèmes populaires :
- Frameworks agentiques et outils de création d’applications : Suivez les guides d’intégration étape par étape de Novita pour vous connecter à des outils populaires comme Continue, AnythingLLM, LangChain et Langflow.
- Hugging Face Hub : Novita est répertorié comme Fournisseur d’inférence sur Hugging Face, vous pouvez donc exécuter les modèles pris en charge via le workflow et l’écosystème de Hugging Face.
- API compatible OpenAI : Les endpoints LLM de Novita sont compatibles avec la norme d’API d’OpenAI, ce qui facilite la migration d’applications existantes basées sur OpenAI et la connexion à de nombreux outils compatibles OpenAI ( Cline, Cursor **, Trae et Qwen Code ) .
- API compatible Anthropic : Novita propose également un accès compatible avec le SDK Anthropic pour que vous puissiez intégrer des modèles hébergés par Novita dans des workflows de codage agentique de type Claude Code.
- OpenCode : Novita AI est désormais intégré directement à OpenCode en tant que fournisseur pris en charge, donc les utilisateurs peuvent sélectionner Novita dans OpenCode sans configuration manuelle.
Conclusion
- GLM-4.7-Flash est le meilleur choix si vous accordez la priorité à la qualité agentique/codage et au contexte très long (200K) — il est en tête sur 5/6 benchmarks dans le graphique fourni (AIME est quasiment à égalité).
- GPT-OSS-20B est le meilleur choix si vous accordez la priorité à la vitesse et au coût — il est beaucoup plus rapide sur les graphiques de latence fournis et moins cher avec la tarification serverless de Novita.
La méthode la plus rapide : essayez les deux dans le Novita AI Playground, puis passez aux intégrations API / SDK / tierces en fonction de votre méthode de développement.
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles IA via notre API simple, tout en fournissant un cloud GPU abordable et fiable pour créer et mettre à l’échelle.
Foire aux questions
Qu’est-ce que GLM-4.7-Flash ?
GLM-4.7-Flash est un modèle de langage large de type Mixture-of-Experts (MoE) de classe 30B développé par Zhipu AI, conçu pour offrir des performances élevées en raisonnement, codage et tâches agentiques, avec une grande efficacité et une faible latence.
Combien coûte GLM-4.7-Flash ?
Sur Novita AI (serverless), GLM-4.7-Flash est tarifé à 0,07 $ par million de jetons d’entrée, 0,01 $ par million de jetons de cache lus et 0,40 $ par million de jetons de sortie, ce qui le rend rentable pour les charges de travail à grand contexte et haut débit.
Lequel est le meilleur, GLM-4.7-Flash ou GPT-OSS-20B ?
Cela dépend du cas d’usage : GLM-4.7-Flash obtient généralement de meilleures performances sur les benchmarks agentiques, lourds en outils et du monde réel, tandis que GPT-OSS-20B peut être préféré pour les déploiements légers, à faible latence ou sur un seul GPU.



