

Open-Weight-Modelle sind heute leistungsfähig genug für echte Produktionsworkloads – agentisches Codieren, Long-Context-Workflows und toolnutzende Assistenten, ohne dass Sie sich an einen einzelnen Anbieter binden. Zwei Modelle, die in Diskussionen über „schnell + leistungsfähig“ häufig genannt werden, sind GLM-4.7-Flash und GPT-OSS-20B.
Dieser Blog vergleicht sie aus praktischer Sicht – Qualität (Benchmarks), Geschwindigkeit/Latenz und Kosten – und zeigt, wie Sie beide sofort über APIs auf Novita AI ausführen können.
Grundlegende Einführung
Beide sind MoE-Modelle, die für hohe Effizienz entwickelt wurden, aber mit unterschiedlichen Schwerpunkten:
- GLM-4.7-Flash: Ausgewogenes Verhältnis von Leistung und Effizienz der „30B-Klasse“ (ideal für Long-Context-Workflows).
- GPT-OSS-20B: Open-Weight-Modell von OpenAI, optimiert für geringere Latenz / Kompatibilität mit einzelnen GPUs und Tool-Nutzung.
| GLM-4.7-Flash | GPT-OSS-20B | |
| Entwickler | Z.ai | OpenAI |
| Veröffentlichungsdatum | 20. Jan. 2026 | 5. Aug. 2025 |
| Parameter (aktiv) | 30B-A3B (MoE) | 21B gesamt / 3,6B aktiv (MoE) |
| Novita-Kontext | 200.000 | 131.072 |
| Novita-Preisgestaltung | Eingang $0,07/M · Ausgang $0,40/M | Eingang $0,04/M · Ausgang $0,15/M |
Benchmark-Vergleich
Die Grafik zeigt Ergebnisse von 6 Benchmarks: SWE-bench Verified, τ²-Bench, BrowseComp, AIME 25, GPQA, HLE. Diese Werte sind auch auf der Hugging Face-Modellseite von GLM-4.7-Flash aufgeführt, die wir als maßgebliche Quelle verwenden.
| Benchmark | GLM-4.7-Flash | GPT-OSS-20B | Gewinner |
| SWE-bench Verified | 59,2 | 34 | GLM-4.7-Flash |
| τ²-Bench | 79,5 | 47,7 | GLM-4.7-Flash |
| BrowseComp | 42,8 | 28,3 | GLM-4.7-Flash |
| AIME 25 | 91,6 | 91,7 | GPT-OSS-20B (knapp) |
| GPQA | 75,2 | 71,5 | GLM-4.7-Flash |
| HLE | 14,4 | 10,9 | GLM-4.7-Flash |
💡Interpretation
Die Benchmarks sprechen größtenteils für GLM-4.7-Flash – es führt in fünf der sechs Auswertungen, bei AIME 25 ist es im Wesentlichen ein Unentschieden (91,6 vs 91,7).
- Agentische und toollastige Aufgaben: GLM-4.7-Flash führt deutlich bei SWE-bench Verified und τ²-Bench, die eng mit realen Agent-Workflows (Codieren/Terminal, mehrstufige Interaktionen) verbunden sind.
- Browserähnliche Aufgaben: GLM-4.7-Flash führt auch bei BrowseComp, was auf ein stärkeres Langzeit-Navigations-/Auswahlverhalten unter Evaluationsbedingungen hindeutet.
- Mathematik: AIME 25 ist im Wesentlichen ein Unentschieden (91,6 vs 91,7). Anders gesagt: Wählen Sie nicht allein aufgrund dieser Bewertung.
- Wissensintensive Q&A: GLM-4.7-Flash liegt in diesem Berichtsset bei GPQA und HLE vorn.
Geschwindigkeits- und Latenzvergleich
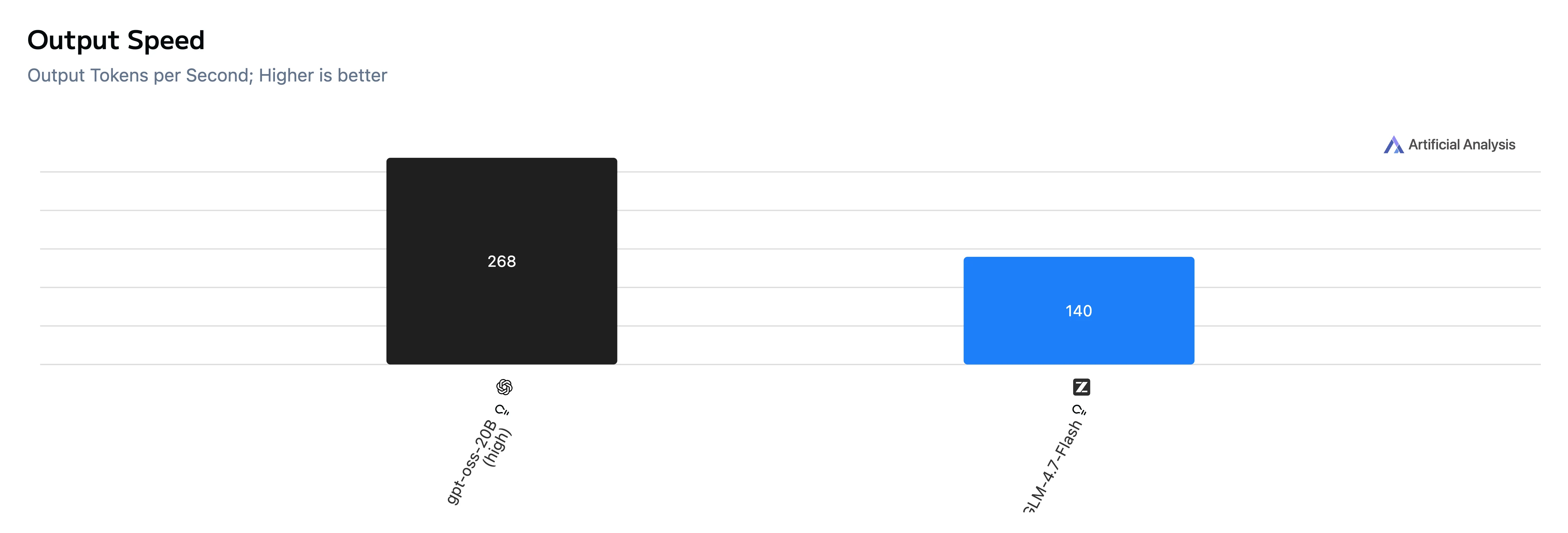
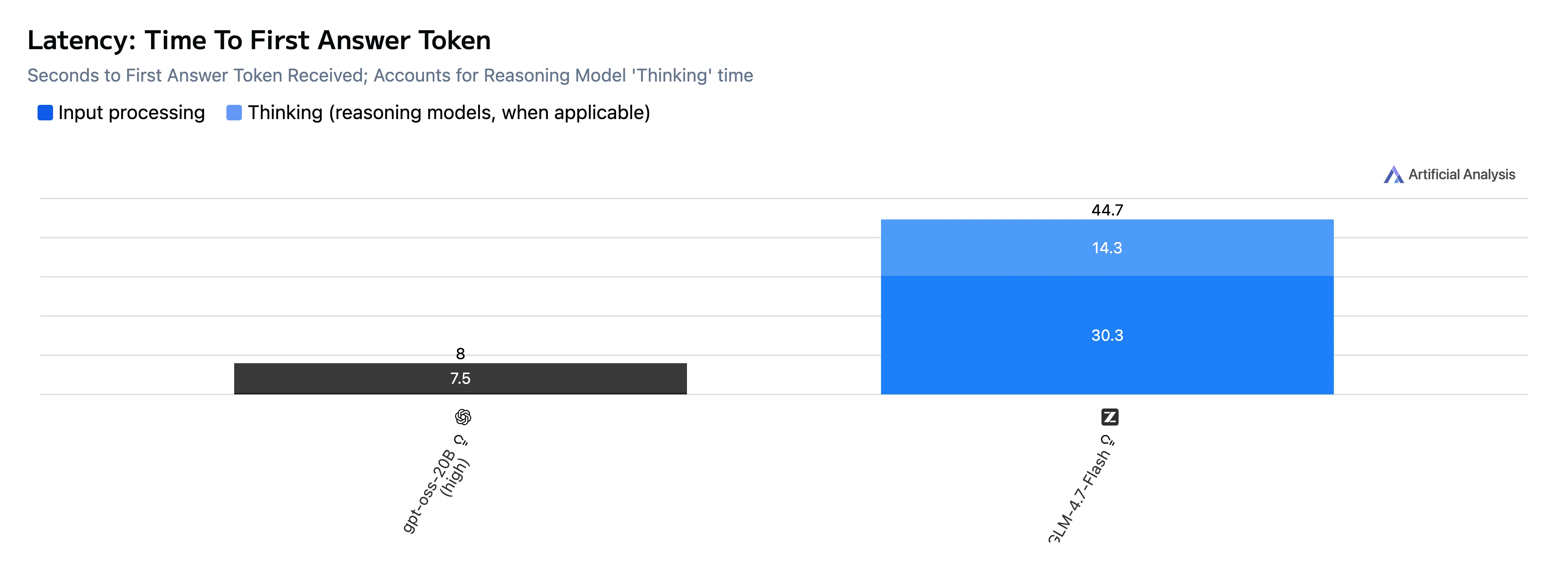
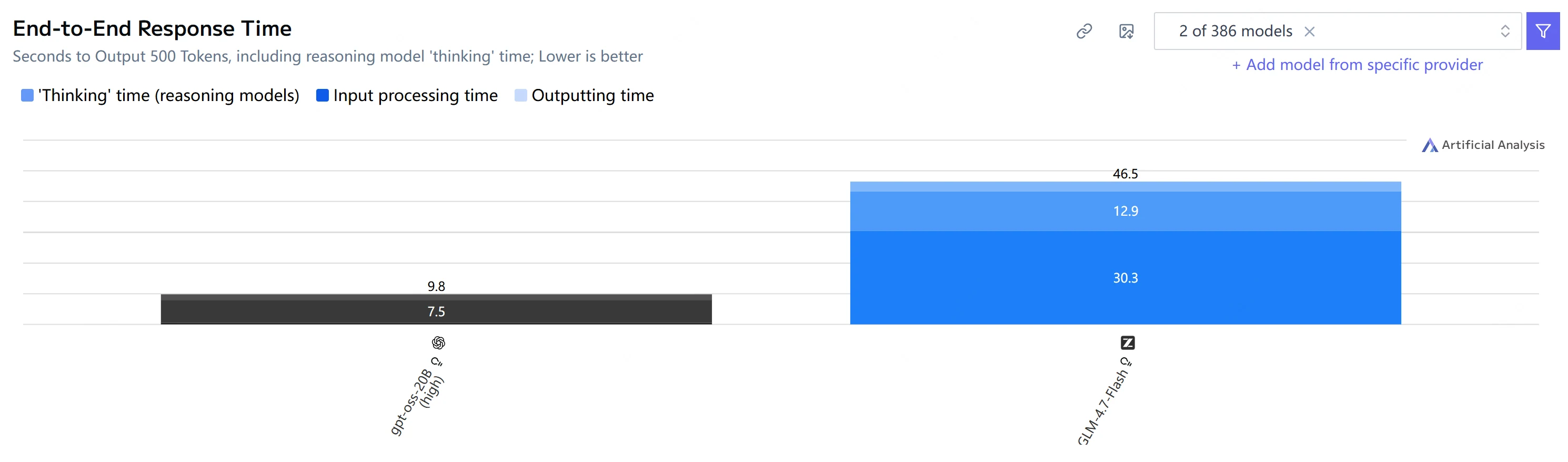
| Metrik | GPT-OSS-20B | GLM-4.7-Flash |
| Ausgabegeschwindigkeit | 268 Tok/s | 140 Tok/s |
| TTFT (erster Antwort-Token) | 8,0 s | 46,5 s |
| End-to-End-Zeit (500 Ausgabe-Tokens) |
9,8 s | 46,5 s |
Fazit: GPT-OSS-20B ist sowohl bei der Time-to-First-Token als auch bei der End-to-End-Generierung deutlich schneller und gibt in diesem Testset auch Tokens schneller aus.
Kostenvergleich
| Modell | Eingang (USD / 1M Tokens) | Ausgang (USD / 1M Tokens) | Cache-Lesen (USD / 1M Tokens) |
| GLM-4.7-Flash (zai-org/glm-4.7-flash) | $0,07 | $0,40 | $0,01 |
| GPT-OSS-20B (openai/gpt-oss-20b) | $0,04 | $0,15 | - |
GPT-OSS-20B ist die kosteneffizientere Wahl pro Token, während GLM-4.7-Flash mehr kostet, aber lohnenswert ist, wenn Sie stärkere Leistung und Long-Context-Fähigkeiten benötigen. Wenn Sie weitere Details wünschen, besuchen Sie die Modellbibliothek von Novita AI, um die aktuellsten Preise und Modellspezifikationen einzusehen.
Schnellstart: Probieren Sie beide Modelle sofort im Playground aus
Wenn Sie den Unterschied zwischen GLM-4.7-Flash und GPT-OSS-20B sofort selbst erleben möchten, ist der schnellste Weg die Nutzung des Novita AI Playground – kein Code, keine Einrichtung.
Im Playground können Sie:
- Modelle sofort wechseln zwischen GLM-4.7-Flash und GPT-OSS-20B
- Nutzen Sie denselben Prompt, um Ausgabequalität, Argumentationsstil und Antwortgeschwindigkeit zu vergleichen
Novita AI Playground
Bereitstellung: API, SDK und Integrationen von Drittanbietern
API
API-Schlüssel abrufen
-
Schritt 1: Konto erstellen oder anmelden Besuchen Sie
[**https://novita.ai**](https://novita.ai)und registrieren Sie sich oder melden Sie sich mit Ihrem bestehenden Konto an. -
Schritt 2: Zur Schlüsselverwaltung navigieren Nach der Anmeldung suchen Sie nach „API-Schlüsseln“

-
Schritt 3: Neuen Schlüssel erstellen Klicken Sie auf die Schaltfläche „Neuen Schlüssel hinzufügen“.

-
Schritt 4: Schlüssel sofort speichern Kopieren und speichern Sie den Schlüssel sofort nach der Generierung; er wird in der Regel nur einmal angezeigt und kann später nicht wiederhergestellt werden. Bewahren Sie den Schlüssel an einem sicheren Ort auf, z. B. in einem Passwort-Manager oder in verschlüsselten Notizen.
OpenAI-kompatible API (Python)
from openai import OpenAI
client = OpenAI(
api_key="<YOUR_NOVITA_API_KEY>",
base_url="https://api.novita.ai/openai",
)
resp = client.chat.completions.create(
model="zai-org/glm-4.7-flash",
messages=[
{"role": "system", "content": "You are a precise engineering assistant. Output valid JSON when asked."},
{"role": "user", "content": "Summarize the key risks of rolling out feature flags across 20 services."},
],
temperature=0.3,
max_tokens=4096,
)
print(resp.choices[0].message.content)
SDK
Wenn Sie agentische Workflows (Übergaben, Routing, Tool-/Funktionsaufrufe) erstellen, können Sie Novita-gehostete Modelle mit minimalen Änderungen im OpenAI Agents SDK ausführen:
- Drop-in-Kompatibilität: Novita bietet eine OpenAI-kompatible API, sodass Ihr Agents-Workflow gleich bleibt – nur die Basis-URL und das Modell müssen angepasst werden.
- Agent Orchestrierungsbereit: Nutzen Sie Routing und Tools, um Aufgaben zu delegieren, während die Inferenz auf Novita bleibt.
- Einrichtung: Zeigen Sie das SDK auf
https://api.novita.ai/openai, setzen SieNOVITA_API_KEY, wählen Siezai-org/glm-4.7-flash(oderopenai/gpt-oss-20b).
Plattformen von Drittanbietern
Sie können Novita-gehostete Modelle auch über beliebte Ökosysteme nutzen:
- Agent-Frameworks und App-Builder: Befolgen Sie die Schritt-für-Schritt-Integrationsanleitungen von Novita, um sich mit beliebten Tools wie Continue, AnythingLLM, LangChain und Langflow zu verbinden.
- Hugging Face Hub: Novita ist als Inferenzanbieter auf Hugging Face gelistet, sodass Sie unterstützte Modelle über den Anbieter-Workflow und das Ökosystem von Hugging Face ausführen können.
- OpenAI-kompatible API: Die LLM-Endpunkte von Novita sind kompatibel mit dem OpenAI-API-Standard, sodass Sie bestehende OpenAI-Apps einfach migrieren und viele OpenAI-kompatible Tools ( Cline, Cursor, Trae und Qwen Code) anschließen können.
- Anthropic-kompatible API: Novita bietet auch Anthropic SDK-kompatiblen Zugriff, sodass Sie Novita-unterstützte Modelle in agentische Codierungs-Workflows im Stil von Claude Code integrieren können.
- OpenCode: Novita AI ist jetzt direkt als unterstützter Anbieter in OpenCode integriert, sodass Benutzer Novita in OpenCode ohne manuelle Konfiguration auswählen können.
Fazit
- GLM-4.7-Flash ist die bessere Wahl, wenn Ihnen vor allem agentische/Codierungsqualität und sehr langer Kontext (200K) wichtig sind – es führt in 5 von 6 Benchmarks in der bereitgestellten Tabelle (AIME ist im Wesentlichen ein Unentschieden).
- GPT-OSS-20B ist die bessere Wahl, wenn Ihnen vor allem Geschwindigkeit und Kosten wichtig sind – es ist in den bereitgestellten Latenzdiagrammen deutlich schneller und günstiger bei der serverlosen Preisgestaltung von Novita.
Schnellster Weg: probieren Sie beide im Novita AI Playground aus, wechseln Sie dann je nach Ihrer Implementierung zu API / SDK / Integrationen von Drittanbietern.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud zum Erstellen und Skalieren bereitstellt.
Häufig gestellte Fragen
Was ist GLM-4.7-Flash?
GLM-4.7-Flash ist ein Large Language Model der 30B-Klasse mit Mixture-of-Experts (MoE)-Architektur, das von Zhipu AI entwickelt wurde. Es wurde entwickelt, um starke Reasoning-, Codierungs- und agentische Leistung bei hoher Effizienz und geringer Latenz zu liefern.
Wie viel kostet GLM-4.7-Flash?
Auf Novita AI (serverlos) ist GLM-4.7-Flash mit $0,07/M Eingabe-Tokens, $0,01/M gelesenen Cache-Tokens und $0,40/M Ausgabe-Tokens preisgestaltet, was es kosteneffizient für Workloads mit großem Kontext und hohem Durchsatz macht.
Was ist besser, GLM-4.7-Flash oder GPT-OSS-20B?
Das hängt vom Anwendungsfall ab: GLM-4.7-Flash schneidet im Allgemeinen bei agentischen, toollastigen und realen Benchmarks besser ab, während GPT-OSS-20B für leichtgewichtige, latenzarme oder Single-GPU-Bereitstellungen bevorzugt werden kann.



