

Open-weight models are now strong enough for real production workloads—agentic coding, long-context workflows, and tool-using assistants without locking you into a single vendor. Two models that come up a lot in “fast + capable” discussions are GLM-4.7-Flash and GPT-OSS-20B.
This blog compares them through a practical lens—quality (benchmarks), speed/latency, and cost, and shows how to run both immediately on Novita AI via APIs.
Basic Introduction
Both are MoE models built for high efficiency, but with different emphases:
- GLM-4.7-Flash: “30B-class” balance of capability and efficiency (great for long-context workflows).
- GPT-OSS-20B: OpenAI open-weight model optimized for lower latency / single-GPU friendliness and tool use.
| GLM-4.7-Flash | GPT-OSS-20B | |
| Developer | Z.ai | OpenAI |
| Release date | Jan 20, 2026 | Aug 5, 2025 |
| Params (active) | 30B-A3B (MoE) | 21B total / 3.6B active (MoE) |
| Novita context | 200,000 | 131,072 |
| Novita pricing | In $0.07/M · Out $0.40/M | In $0.04/M · Out $0.15/M |
Benchmark Comparison
The figure reports results on 6 benchmarks: SWE-bench Verified, τ²-Bench, BrowseComp, AIME 25, GPQA, HLE. These same numbers are listed in the GLM-4.7-Flash Hugging Face model page, which we use as the authoritative source.
| Benchmark | GLM-4.7-Flash | GPT-OSS-20B | Winner |
| SWE-bench Verified | 59.2 | 34 | GLM-4.7-Flash |
| τ²-Bench | 79.5 | 47.7 | GLM-4.7-Flash |
| BrowseComp | 42.8 | 28.3 | GLM-4.7-Flash |
| AIME 25 | 91.6 | 91.7 | GPT-OSS-20B (slightly) |
| GPQA | 75.2 | 71.5 | GLM-4.7-Flash |
| HLE | 14.4 | 10.9 | GLM-4.7-Flash |
💡Interpretation
The benchmarks mostly favor GLM-4.7-Flash—leading on five evaluations—with AIME 25 effectively a wash (91.6 vs 91.7).
- Agentic + tool-heavy tasks: GLM-4.7-Flash leads clearly on SWE-bench Verified and τ²-Bench, which are closely tied to real-world agent workflows (coding/terminal, multi-step interactions).
- Browsing-style tasks: GLM-4.7-Flash also leads on BrowseComp, suggesting stronger long-horizon navigation/selection behavior under evaluation settings.
- Math: AIME 25 is essentially a tie (91.6 vs 91.7). In other words: don’t choose purely on this one.
- Knowledge-heavy QA: GLM-4.7-Flash is ahead on GPQA and HLE in this report set.
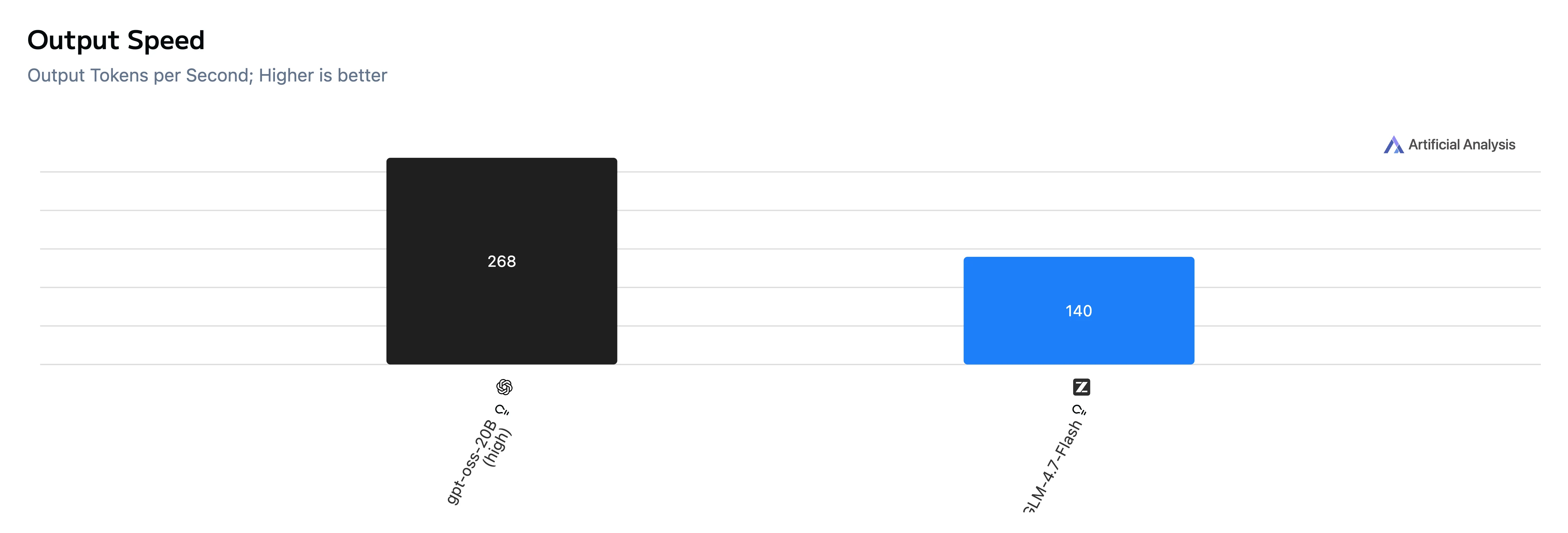
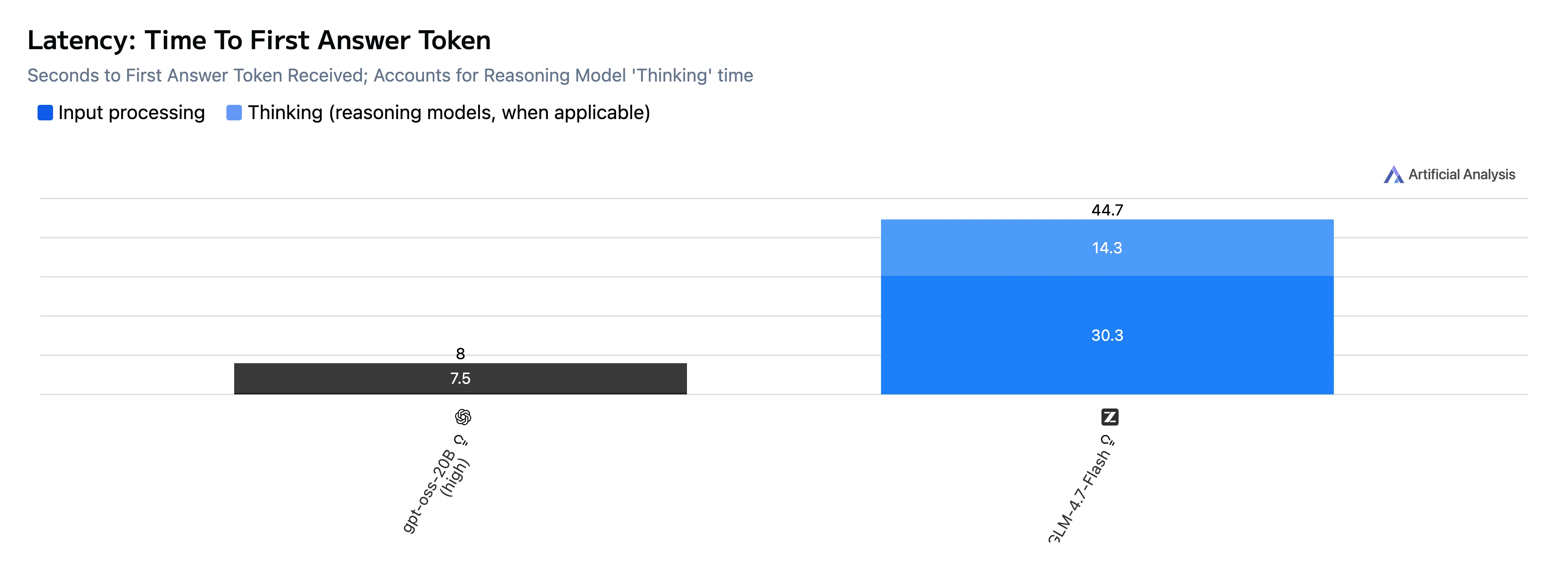
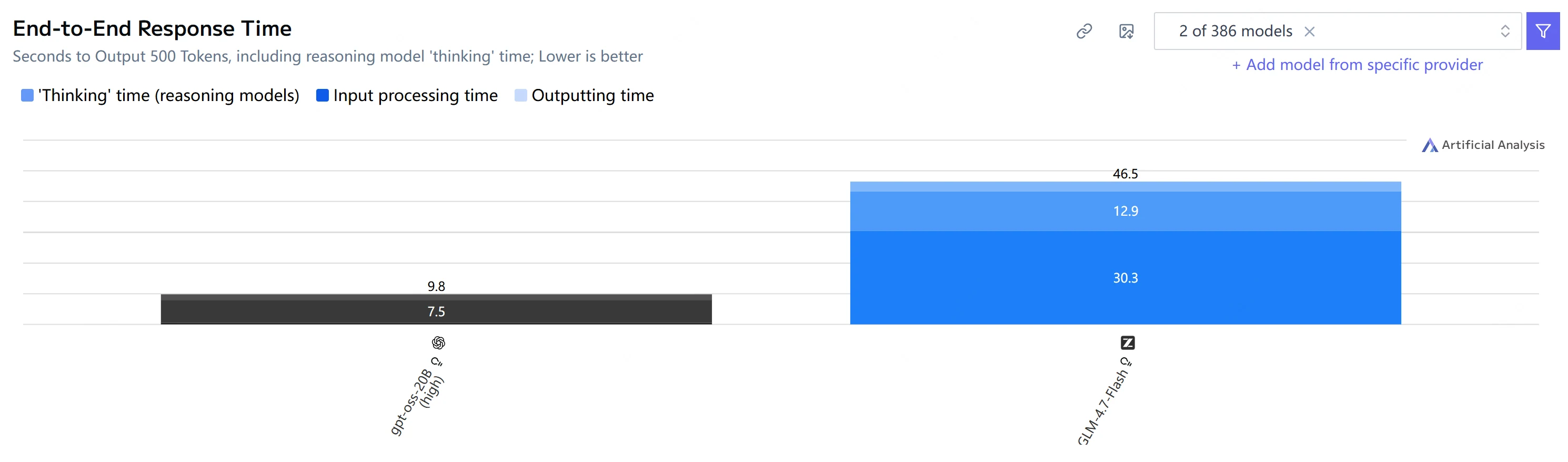
Speed & Latency Comparison
| Metric | GPT-OSS-20B | GLM-4.7-Flash |
| Output speed | 268 tok/s | 140 tok/s |
| TTFT (first answer token) | 8.0 s | 46.5 s |
| End-to-end time (500 output tokens) | 9.8 s | 46.5 s |
Takeaway: GPT-OSS-20B is much faster on both time-to-first-token and end-to-end generation, and also outputs tokens faster in this test set.
Cost Comparison
| Model | Input (USD / 1M tokens) | Output (USD / 1M tokens) | Cache read (USD / 1M tokens) |
| GLM-4.7-Flash (zai-org/glm-4.7-flash) | $0.07 | $0.40 | $0.01 |
| GPT-OSS-20B (openai/gpt-oss-20b) | $0.04 | $0.15 | - |
GPT-OSS-20B is the more cost-efficient choice per token, while GLM-4.7-Flash costs more but can be worth it when you need stronger performance and long-context capability. If you’d like more details, head to Novita AI’s Model Library to view the latest pricing and model specs.
Quickstart: Try Both Models Instantly on Playground
If you want to experience the difference between GLM-4.7-Flash and GPT-OSS-20B immediately, the fastest way is to use Novita AI Playground—no code, no setup.
In the Playground, you can:
- Switch models instantly between GLM-4.7-Flash and GPT-OSS-20B
- Use the same prompt to compare output quality, reasoning style, and response speed
Novita AI Playground
How to Deploy: API, SDK, and Third-Party Integrations
API
Get an API Key
- Step 1: Create or Login to Your Account
Visit [**https://novita.ai**](https://novita.ai) and sign up or log in to your existing account
- Step 2: Navigate to Key Management
After logging in, find “API Keys”

- Step 3: Create a New Key
Click the “Add New Key” button.

- Step 4: Save Your Key Immediately
Copy and store the key as soon as it is generated; it is usually shown only once and cannot be retrieved later. Keep the key in a secure location such as a password manager or encrypted notes
OpenAI-compatible API (Python)
from openai import OpenAI
client = OpenAI(
api_key="<YOUR_NOVITA_API_KEY>",
base_url="https://api.novita.ai/openai",
)
resp = client.chat.completions.create(
model="zai-org/glm-4.7-flash",
messages=[
{"role": "system", "content": "You are a precise engineering assistant. Output valid JSON when asked."},
{"role": "user", "content": "Summarize the key risks of rolling out feature flags across 20 services."},
],
temperature=0.3,
max_tokens=4096,
)
print(resp.choices[0].message.content)SDK
If you’re building agentic workflows (handoffs, routing, tool/function calls), you can run Novita-hosted models inside the OpenAI Agents SDK with minimal changes:
- Drop-in compatibility: Novita exposes an OpenAI-compatible API, so your Agents workflow stays the same—only the base URL/model changes.
- Agent orchestration-read y: Use routing + tools to delegate tasks while keeping inference on Novita.
- Setup: point the SDK to
https://api.novita.ai/openai, setNOVITA_API_KEY, selectzai-org/glm-4.7-flash(oropenai/gpt-oss-20b).
Third-Party Platforms
You can also use Novita-hosted models through popular ecosystems:
- Agent frameworks & app builders: Follow Novita’s step-by-step integration guides to connect with popular tooling such as Continue, AnythingLLM, LangChain, and Langflow.
- Hugging Face Hub: Novita is listed as an Inference Provider on Hugging Face, so you can run supported models through Hugging Face’s provider workflow and ecosystem.
- OpenAI-compatible API: Novita’s LLM endpoints are compatible with the OpenAI API standard, making it easy to migrate existing OpenAI-style apps and connect many OpenAI-compatible tools ( Cline, Cursor , Trae and Qwen Code) .
- Anthropic-compatible API: Novita also provides Anthropic SDK–compatible access so you can integrate Novita-backed models into Claude Code style agentic coding workflows.
- OpenCode: Novita AI is now integrated directly into OpenCode as a supported provider, so users can select Novita in OpenCode without manual configuration.
Conclusion
- GLM-4.7-Flash is the better pick when you care most about agentic/coding quality and very long context (200K)—it leads on 5/6 benchmarks in the provided chart (AIME is essentially tied).
- GPT-OSS-20B is the better pick when you care most about speed and cost—it’s much faster on the provided latency charts and cheaper on Novita’s serverless pricing.
Fastest path: try both in Novita AI Playground, then move to API / SDK / third-party integrations based on how you’re building.
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing the affordable and reliable GPU cloud for building and scaling.
Frequently Asked Questions
What is GLM-4.7-Flash?
GLM-4.7-Flash is a 30B-class Mixture-of-Experts (MoE) large language model developed by Zhipu AI, designed to deliver strong reasoning, coding, and agentic performance with high efficiency and low latency.
How much does GLM-4.7-Flash cost?
On Novita AI (serverless), GLM-4.7-Flash is priced at $0.07/M input tokens, $0.01/M cached read tokens, and $0.40/M output tokens, making it cost-effective for large-context and high-throughput workloads.
Which is better, GLM-4.7-Flash or GPT-OSS-20B?
It depends on the use case: GLM-4.7-Flash generally performs better on agentic, tool-heavy, and real-world benchmarks, while GPT-OSS-20B may be preferred for lightweight, low-latency, or single-GPU deployments.



